⚓ Aiffel Exploration 17 을 참고하여 작성하였습니다.
조건없는 생성 모델 GAN(Unconditional Generative Model)
GAN 구조는 Generator 및 Discriminator라 불리는 두 신경망이 minimax game을 통해 서로 경쟁하며 발전합니다. 이를 아래와 같은 식으로 나타낼 수 있으며 Generator는 이 식을 최소화하려, Discriminator는 이 식을 최대화하려 학습합니다.
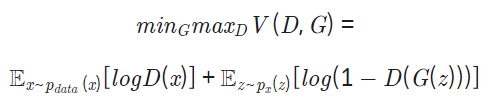
위 식에서 z는 임의 노이즈를, D와 G는 각각 Discriminator 및 Generator를 의미합니다.
먼저 D의 입장에서 식을 바라봅시다.
실제 이미지를 1, 가짜 이미지를 0으로 두었을 때, DD는 이 식을 최대화해야 하며, 우변의 + 를 기준으로 양쪽의 항(logD(x)) 및 log(1−D(G(z)))이 모두 최대가 되게 해야 합니다.
이를 위해서 두 개의 log가 1이 되게 해야 합니다. D(x)는 1이 되도록, D(G(z))는 0이 되도록 해야 합니다.
다시 말하면, 진짜 데이터(x)를 진짜로, 가짜 데이터(G(z))를 가짜로 정확히 예측하도록 학습한다는 뜻입니다.
이번엔 G의 입장에서 식을 바라봅시다.
D와 반대로 G는 위 식을 최소화해야 하고 위 수식에서는 마지막 항 log(1−D(G(z)))만을 최소화하면 됩니다 (우변의 첫 번째 항은 G와 관련이 없습니다).
이를 최소화한다는 것은 log 내부가 0이 되도록 해야 함을 뜻하며, D(G(z))가 1이 되도록 한다는 말과 같습니다.
즉, G는 z를 입력받아 생성한 데이터 G(z)를 D가 진짜 데이터라고 예측할 만큼 진짜 같은 가짜 데이터를 만들도록 학습한다는 뜻입니다.
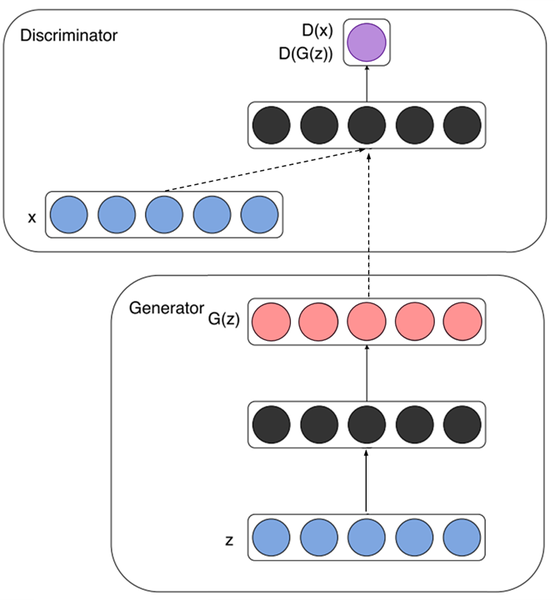
이미지로 이해해봅시다.
 ### - Generator
### - Generator
노이즈 zz(파란색)가 입력되고 특정 representation(검정색)으로 변환된 후 가짜 데이터 G(z)G(z) (빨간색)를 생성해 냅니다.
- Discriminator
실제 데이터 xx와 Generator가 생성한 가짜 데이터 G(z)G(z)를 각각 입력받아 D(x)D(x) 및 D(G(z))D(G(z)) (보라색)를 계산하여 진짜와 가짜를 식별해 냅니다.
Conditional Generative Adversarial Nets (cGAN)
GAN과 비교하며 알아볼 cGAN의 목적함수는 아래와 같습니다.
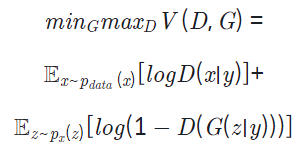
위에서 GAN의 목적함수를 이해했고, GAN의 목적함수와 비교해 위 식에서 달라진 부분을 잘 찾아내셨다면 크게 어렵지 않습니다.
위 식에서 바뀐 부분은 우변의 + 를 기준으로 양쪽 항에 y가 추가되었다는 것뿐입니다. G와 D의 입력에 특정 조건을 나타내는 정보인 y를 같이 입력한다는 것이죠.
이외에는 GAN의 목적함수와 동일하므로 각각 y를 추가로 입력받아 G의 입장에서 식을 최소화하고, D의 입장에서 식을 최대화하도록 학습합니다.
여기서 함께 입력하는 y는 어떠한 정보여도 상관없으며, MNIST 데이터셋을 학습시키는 경우 y는 0~9 까지의 label 정보가 됩니다.
Generator가 어떠한 노이즈 z를 입력받았을 때, 특정 조건 y가 함께 입력되기 때문에, y를 통해 z를 어떠한 이미지로 만들어야 할지에 대한 방향을 제어할 수 있게 됩니다.
조금 다르게 표현하면 y가 임의 노이즈 입력인 z의 가이드라고 할 수 있겠죠.
이미지로 이해해봅시다.
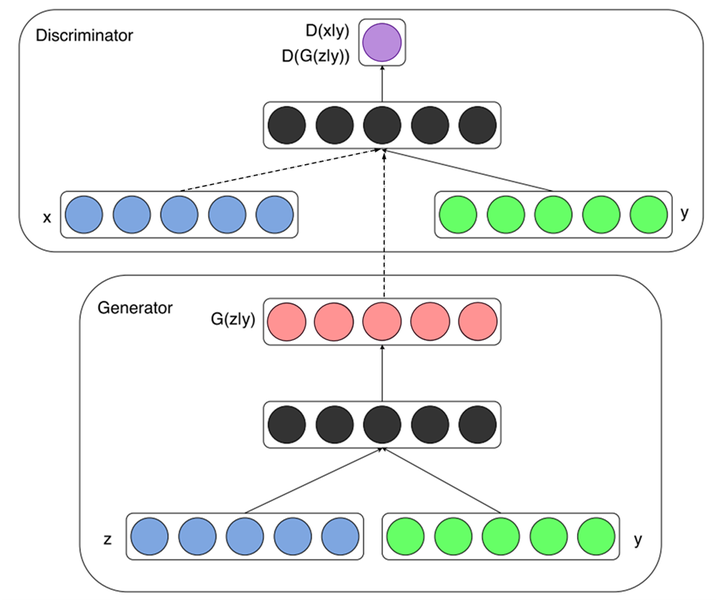
이전 목적함수에서 확인했듯이, cGAN에서 바뀐 부분은 y라는 정보가 함께 입력된다는 것입니다.
-
Generator 노이즈 z(파란색)와 추가 정보 y(녹색)을 함께 입력받아 Generator 내부에서 결합되어 representation(검정색)으로 변환되며 가짜 데이터 G(z∣y)를 생성합니다. MNIST나 CIFAR-10 등의 데이터셋에 대해 학습시키는 경우 y는 레이블 정보이며, 일반적으로 one-hot 벡터를 입력으로 넣습니다.
-
Discriminator 실제 데이터 x와 Generator가 생성한 가짜 데이터 G(z∣y)를 각각 입력받으며, 마찬가지로 yy정보가 각각 함께 입력되어 진짜와 가짜를 식별합니다. MNIST나 CIFAR-10 등의 데이터셋에 대해 학습시키는 경우 실제 데이터 x와 y는 알맞은 한 쌍("7"이라 쓰인 이미지의 경우 레이블도 7)을 이뤄야 하며, 마찬가지로 Generator에 입력된 y와 Discriminator에 입력되는 y는 동일한 레이블을 나타내야 합니다.
코드로 구현해보기
1. 데이터 준비하기
먼저, tensorflow-datasets 라이브러리에서 간단하게 MNIST 데이터셋을 불러와 확인해 봅시다.
⚓ tensorflow-dataset 라이브러리를 통해 데이터 불러오는 방법
버전을 확인하고 싶다면 아래 명령어를 Cloud Shell에서 실행하시면 됩니다.
$ pip list | grep tensorflow-dataset나중에 직접 라이브러리를 설치하고 싶을 땐 아래 명령어를 실행하시면 됩니다.
$ pip install tensorflow-dataset
import tensorflow_datasets as tfds
mnist, info = tfds.load(
"mnist", split="train", with_info=True
)
fig = tfds.show_examples(mnist, info)이어서, 학습 전에 필요한 몇 가지 처리를 수행하는 함수를 정의합니다.
import tensorflow as tf
BATCH_SIZE = 128
def gan_preprocessing(data):
image = data["image"]
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
def cgan_preprocessing(data):
image = data["image"]
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
label = tf.one_hot(data["label"], 10)
return image, label
gan_datasets = mnist.map(gan_preprocessing).shuffle(1000).batch(BATCH_SIZE)
cgan_datasets = mnist.map(cgan_preprocessing).shuffle(100).batch(BATCH_SIZE)이미지 픽셀 값을 -1~1 사이의 범위로 변경했고, 레이블 정보를 원-핫 인코딩(one-hot encoding)했습니다. GAN과 cGAN 각각을 실험해 보기 위해 label 정보 사용 유무에 따라 gan_preprocessing()과 cgan_preprocessing() 두 가지 함수를 구성해 놓았습니다.
이번에는 원하는 대로 정확히 처리되었는지 한 개 데이터셋만 선택해 확인해 봅시다. 이미지에 쓰인 숫자와 레이블이 일치해야 하고, 이미지 값의 범위가 -1~1 사이에 있어야 합니다.
import matplotlib.pyplot as plt
for i,j in cgan_datasets : break
# 이미지 i와 라벨 j가 일치하는지 확인해 봅니다.
print("Label :", j[0])
print("Image Min/Max :", i.numpy().min(), i.numpy().max())
plt.imshow(i.numpy()[0,...,0], plt.cm.gray)2. GAN Generator 구성하기
이번 구현은 Tensorflow2의 Subclassing 방법을 이용하겠습니다. Subclassing 방법은 tensorflow.keras.Model 을 상속받아 클래스를 만들며, 일반적으로 __init__() 메서드 안에서 레이어 구성을 정의하고, 구성된 레이어를 call() 메서드에서 사용해 forward propagation을 진행합니다. 이러한 Subclassing 방법은 Pytorch의 모델 구성 방법과도 매우 유사하므로 이에 익숙해진다면 Pytorch의 모델 구성 방법도 빠르게 습득할 수 있습니다.
먼저 GAN의 Generator를 아래와 같이 구현합니다.
from tensorflow.keras import layers, Input, Model
class GeneratorGAN(Model):
def __init__(self):
super(GeneratorGAN, self).__init__()
self.dense_1 = layers.Dense(128, activation='relu')
self.dense_2 = layers.Dense(256, activation='relu')
self.dense_3 = layers.Dense(512, activation='relu')
self.dense_4 = layers.Dense(28*28*1, activation='tanh')
self.reshape = layers.Reshape((28, 28, 1))
def call(self, noise):
out = self.dense_1(noise)
out = self.dense_2(out)
out = self.dense_3(out)
out = self.dense_4(out)
return self.reshape(out)__init__() 메서드 안에서 사용할 모든 레이어를 정의했습니다. 4개의 fully-connected 레이어 중 한 개를 제외하고 모두 ReLU 활성화를 사용하는 것으로 확인됩니다.
call() 메서드에서는 노이즈를 입력받아 __init__()에서 정의된 레이어들을 순서대로 통과합니다.
Generator는 숫자가 쓰인 이미지를 출력해야 하므로 마지막 출력은 layers.Reshape()을 이용해 (28,28,1) 크기로 변환됩니다.
cGAN Generator 구성하기
class GeneratorCGAN(Model):
def __init__(self):
super(GeneratorCGAN, self).__init__()
self.dense_z = layers.Dense(256, activation='relu')
self.dense_y = layers.Dense(256, activation='relu')
self.combined_dense = layers.Dense(512, activation='relu')
self.final_dense = layers.Dense(28 * 28 * 1, activation='tanh')
self.reshape = layers.Reshape((28, 28, 1))
def call(self, noise, label):
noise = self.dense_z(noise)
label = self.dense_y(label)
out = self.combined_dense(tf.concat([noise, label], axis=-1))
out = self.final_dense(out)
return self.reshape(out)cGAN의 입력은 2개(노이즈 및 레이블 정보)라는 점을 기억해 주세요.
- 노이즈 입력 및 레이블 입력은 각각 1개의 fully-connected 레이어와 ReLU 활성화를 통과합니다. (
dense_z,dense_y) - 1번 문항의 각 결과가 서로 연결되어 다시 한번 1개의 fully-connected 레이어와 ReLU 활성화를 통과합니다 (
tf.concat,conbined_dense) - 2번 문항의 결과가 1개의 fully-connected 레이어 및 Hyperbolic tangent 활성화를 거쳐 28x28 차원의 결과가 생성되고 (28,28,1) 크기의 이미지 형태로 변환되어 출력됩니다 (
final_dense,reshape)
GAN Discriminator 구성하기
class DiscriminatorGAN(Model):
def __init__(self):
super(DiscriminatorGAN, self).__init__()
self.flatten = layers.Flatten()
self.blocks = []
for f in [512, 256, 128, 1]:
self.blocks.append(
layers.Dense(f, activation=None if f==1 else "relu")
)
def call(self, x):
x = self.flatten(x)
for block in self.blocks:
x = block(x)
return x여기에서는 __init__()에 blocks라는 리스트를 하나 만들어 놓고, for loop를 이용하여 필요한 레이어들을 차곡차곡 쌓아놓았습니다. 이러한 방식을 이용하면 각각의 fully-connected 레이어를 매번 정의하지 않아도 되므로 많은 레이어가 필요할 때 편리합니다. Discriminator의 입력은 Generator가 생성한 (28,28,1) 크기의 이미지이며, 이를 fully-connected 레이어로 학습하기 위해 call()에서는 가장 먼저 layers.Flatten()이 적용됩니다. 이어서 레이어들이 쌓여있는 blocks에 대해 for loop를 이용하여 레이어들을 순서대로 하나씩 꺼내 입력 데이터를 통과시킵니다. 마지막 fully-connected 레이어를 통과하면 진짜 및 가짜 이미지를 나타내는 1개의 값이 출력됩니다.
cGAN Discriminator 구성하기
다음으로 구현할 cGAN의 Discriminator는 Maxout이라는 특별한 레이어가 사용됩니다. Maxout은 간단히 설명하면 두 레이어 사이를 연결할 때, 여러 개의 fully-connected 레이어를 통과시켜 그 중 가장 큰 값을 가져오도록 합니다. 만약 2개의 fully-connected 레이어를 사용할 때 Maxout을 식으로 표현하면 아래와 같습니다.
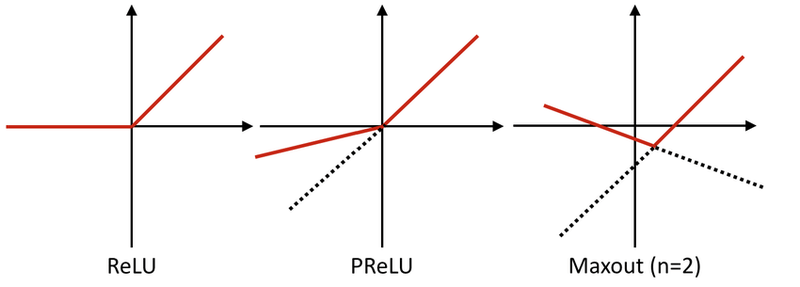
아래 코드와 같이 Maxout을 구성할 수 있습니다.
tensorflow.keras.layers.Layer 를 상속받아 레이어를 정의했습니다.
이전에 모델을 정의한 것과 비슷하게 __init__(), call() 메서드를 구성합니다.
class Maxout(layers.Layer):
def __init__(self, units, pieces):
super(Maxout, self).__init__()
self.dense = layers.Dense(units*pieces, activation="relu")
self.dropout = layers.Dropout(.5)
self.reshape = layers.Reshape((-1, pieces, units))
def call(self, x):
x = self.dense(x)
x = self.dropout(x)
x = self.reshape(x)
return tf.math.reduce_max(x, axis=2)
Maxout 레이어를 구성할 때 units과 pieces의 설정이 필요하며, units 차원 수를 가진 fully-connected 레이어를 pieces개만큼 만들고 그중 최댓값을 출력합니다. 예를 들어, 사용할 Maxout 레이어가 units=100, pieces=10으로 설정된다면 입력으로부터 100차원의 representation을 10개 만들고, 10개 중에서 최댓값을 가져와 최종 1개의 100차원 representation이 출력됩니다. 식으로 나타낸다면 아래와 같습니다. (위 예시에서는 각각의 wx+b가 모두 100차원입니다)
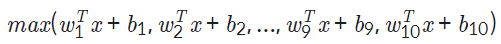
위에서 정의한 Maxout 레이어를 3번만 사용하면 아래와 같이 쉽게 cGAN의 Discriminator를 구성할 수 있습니다.
class DiscriminatorCGAN(Model):
def __init__(self):
super(DiscriminatorCGAN, self).__init__()
self.flatten = layers.Flatten()
self.image_block = Maxout(240, 5)
self.label_block = Maxout(50, 5)
self.combine_block = Maxout(240, 4)
self.dense = layers.Dense(1, activation=None)
def call(self, image, label):
image = self.flatten(image)
image = self.image_block(image)
label = self.label_block(label)
x = layers.Concatenate()([image, label])
x = self.combine_block(x)
return self.dense(x)GAN의 Discriminator와 마찬가지로 Generator가 생성한 (28,28,1) 크기의 이미지가 입력되므로, layers.Flatten()이 적용됩니다. 그리고 이미지 입력 및 레이블 입력 각각은 Maxout 레이어를 한 번씩 통과한 후 서로 결합되어 Maxout 레이어를 한 번 더 통과합니다. 마지막 fully-connected 레이어를 통과하면 진짜 및 가짜 이미지를 나타내는 1개의 값이 출력됩니다.
만약 위와 같은 cGAN의 Disciminator에 (28,28,1) 크기 이미지 및 (10,) 크기 레이블이 입력될 때, 연산의 순서를 다음과 같이 나타낼 수 있습니다.
- 이미지가 Maxout 레이어를 통과
- 레이블이 Maxout 레이어를 통과
- 1)과 2)결과로 나온 representation을 결합(concate) 후 Maxout 레이어를 통과
위 3개 과정의 각 결과 차원 수는 각각 240, 50, 240이다.
