1. 순환 신경망
말 그대로 뉴런의 출력이 순환되는 신경망을 말한다. 은닉층의 출력이 다시 은닉층의 입력으로 사용된다는 특징을 갖는다. 그 외에는 다른 신경망과 비슷하다.
텐서플로 IMDB 데이터 세트 불러오기
import numpy as np
from tensorflow.keras.datasets import imdbload_data()함수의 매개 변수 중 skip_tip에는 가장 많이 등장한 단어들 중 건너뛸 단어의 개수를 지정할 수 있다. num_words는 훈련에 사용할 단어의 개수를 지정한다.
(x_train_all, y_train_all), (x_test, y_test) = imdb.load_data(skip_top=20, num_words=100)훈련 세트 샘플 확인
print(x_train_all[0])imdb 데이터는 영단어를 고유한 정수에 일대일 대응한 것으로 BoW(Bag of Word) 혹은 어휘 사전이라고 부름. 가장 많이 보이는 숫자2 는 어휘 사전에 없는 단어를 의미.
[2, 2, 22, 2, 43, 2, 2, 2, 2, 65, 2, 2, 66, 2, 2, 2, 36, 2, 2, 25, 2, 43, 2, 2, 50, 2, 2, 2, 35, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 39, 2, 2, 2, 2, 2, 2, 38, 2, 2, 2, 2, 50, 2, 2, 2, 2, 2, 2, 22, 2, 2, 2, 2, 2, 22, 71, 87, 2, 2, 43, 2, 38, 76, 2, 2, 2, 2, 22, 2, 2, 2, 2, 2, 2, 2, 2, 2, 62, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 66, 2, 33, 2, 2, 2, 2, 38, 2, 2, 25, 2, 51, 36, 2, 48, 25, 2, 33, 2, 22, 2, 2, 28, 77, 52, 2, 2, 2, 2, 82, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 36, 71, 43, 2, 2, 26, 2, 2, 46, 2, 2, 2, 2, 2, 2, 88, 2, 2, 2, 2, 98, 32, 2, 56, 26, 2, 2, 2, 2, 2, 2, 2, 22, 21, 2, 2, 26, 2, 2, 2, 30, 2, 2, 51, 36, 28, 2, 92, 25, 2, 2, 2, 65, 2, 38, 2, 88, 2, 2, 2, 2, 2, 2, 2, 2, 32, 2, 2, 2, 2, 2, 32]
훈련 세트에서 2 제외
for i in range(len(x_train_all)):
x_train_all[i] = [w for w in x_train_all[i] if w > 2]
print(x_train_all[0])숫자 2는 어휘 사전에 없는 단어이고 0과 1은 각각 패딩과 글의 시작을 나타내는 데 사용하기 때문에 이 숫자들을 제외하고 훈련 세트 생성
[22, 43, 65, 66, 36, 25, 43, 50, 35, 39, 38, 50, 22, 22, 71, 87, 43, 38, 76, 22, 62, 66, 33, 38, 25, 51, 36, 48, 25, 33, 22, 28, 77, 52, 82, 36, 71, 43, 26, 46, 88, 98, 32, 56, 26, 22, 21, 26, 30, 51, 36, 28, 92, 25, 65, 38, 88, 32, 32]
어휘 사전 내려받기
word_to_index = imdb.get_word_index()
word_to_index['movie']get word index함수는 영단어와 정수로 구성된 딕셔너리를 반환한다. movie라는 영단어는 17이라는 정수에 대응되어 있음을 알 수 있다.
17
훈련 세트의 정수를 영단어로 변환하기
index_to_word = {word_to_index[k]: k for k in word_to_index}
for w in x_train_all[0]:
print(index_to_word[w - 3], end=' ')훈련 세트에 있는 정수는 3 이상부터 영단어를 의미하므로 0부터 시작하는 파이썬 특성상 3을 뺀 값으로 어휘 사전의 인덱스를 사용해야 한다.
film just story really they you just there an from so there film film were great just so much film would really at so you what they if you at film have been good also they were just are out because them all up are film but are be what they have don't you story so because all all
훈련 샘플의 길이 확인
print(len(x_train_all[0]), len(x_train_all[1]))길이에 차이가 있어서 조정 필요
59 32
텐서플로로 샘플의 길이 맞추기
from tensorflow.keras.preprocessing import sequence
maxlen=100
x_train_seq = sequence.pad_sequences(x_train, maxlen=maxlen)
x_val_seq = sequence.pad_sequences(x_val, maxlen=maxlen)원-핫 인코딩
from tensorflow.keras.utils import to_categorical
x_train_onehot = to_categorical(x_train_seq)
x_val_onehot = to_categorical(x_val_seq)순환 신경망 클래스 구현
class RecurrentNetwork:
def __init__(self, n_cells=10, batch_size=32, learning_rate=0.1):
self.n_cells = n_cells # 셀 개수
self.batch_size = batch_size # 배치 크기
self.w1h = None # 은닉 상태에 대한 가중치
self.w1x = None # 입력에 대한 가중치
self.b1 = None # 순환층의 절편
self.w2 = None # 출력층의 가중치
self.b2 = None # 출력층의 절편
self.h = None # 순환층의 활성화 출력
self.losses = [] # 훈련 손실
self.val_losses = [] # 검증 손실
self.lr = learning_rate # 학습률
def forpass(self, x):
self.h = [np.zeros((x.shape[0], self.n_cells))] # 은닉 상태를 초기화합니다.
# 배치 차원과 타임 스텝 차원을 바꿉니다.
seq = np.swapaxes(x, 0, 1)
# 순환 층의 선형 식을 계산합니다.
for x in seq:
z1 = np.dot(x, self.w1x) + np.dot(self.h[-1], self.w1h) + self.b1
h = np.tanh(z1) # 활성화 함수를 적용합니다.
self.h.append(h) # 역전파를 위해 은닉 상태 저장합니다.
z2 = np.dot(h, self.w2) + self.b2 # 출력층의 선형 식을 계산합니다.
return z2
def backprop(self, x, err):
m = len(x) # 샘플 개수
# 출력층의 가중치와 절편에 대한 그래디언트를 계산합니다.
w2_grad = np.dot(self.h[-1].T, err) / m
b2_grad = np.sum(err) / m
# 배치 차원과 타임 스텝 차원을 바꿉니다.
seq = np.swapaxes(x, 0, 1)
w1h_grad = w1x_grad = b1_grad = 0
# 셀 직전까지 그래디언트를 계산합니다.
err_to_cell = np.dot(err, self.w2.T) * (1 - self.h[-1] ** 2)
# 모든 타임 스텝을 거슬러가면서 그래디언트를 전파합니다.
for x, h in zip(seq[::-1][:10], self.h[:-1][::-1][:10]):
w1h_grad += np.dot(h.T, err_to_cell)
w1x_grad += np.dot(x.T, err_to_cell)
b1_grad += np.sum(err_to_cell, axis=0)
# 이전 타임 스텝의 셀 직전까지 그래디언트를 계산합니다.
err_to_cell = np.dot(err_to_cell, self.w1h) * (1 - h ** 2)
w1h_grad /= m
w1x_grad /= m
b1_grad /= m
return w1h_grad, w1x_grad, b1_grad, w2_grad, b2_grad
def sigmoid(self, z):
z = np.clip(z, -100, None) # 안전한 np.exp() 계산을 위해
a = 1 / (1 + np.exp(-z)) # 시그모이드 계산
return a
def init_weights(self, n_features, n_classes):
orth_init = tf.initializers.Orthogonal()
glorot_init = tf.initializers.GlorotUniform()
self.w1h = orth_init((self.n_cells, self.n_cells)).numpy() # (셀 개수, 셀 개수)
self.w1x = glorot_init((n_features, self.n_cells)).numpy() # (특성 개수, 셀 개수)
self.b1 = np.zeros(self.n_cells) # 은닉층의 크기
self.w2 = glorot_init((self.n_cells, n_classes)).numpy() # (셀 개수, 클래스 개수)
self.b2 = np.zeros(n_classes)
def fit(self, x, y, epochs=100, x_val=None, y_val=None):
y = y.reshape(-1, 1)
y_val = y_val.reshape(-1, 1)
np.random.seed(42)
self.init_weights(x.shape[2], y.shape[1]) # 은닉층과 출력층의 가중치를 초기화합니다.
# epochs만큼 반복합니다.
for i in range(epochs):
print('에포크', i, end=' ')
# 제너레이터 함수에서 반환한 미니배치를 순환합니다.
batch_losses = []
for x_batch, y_batch in self.gen_batch(x, y):
print('.', end='')
a = self.training(x_batch, y_batch)
# 안전한 로그 계산을 위해 클리핑합니다.
a = np.clip(a, 1e-10, 1-1e-10)
# 로그 손실과 규제 손실을 더하여 리스트에 추가합니다.
loss = np.mean(-(y_batch*np.log(a) + (1-y_batch)*np.log(1-a)))
batch_losses.append(loss)
print()
self.losses.append(np.mean(batch_losses))
# 검증 세트에 대한 손실을 계산합니다.
self.update_val_loss(x_val, y_val)
# 미니배치 제너레이터 함수
def gen_batch(self, x, y):
length = len(x)
bins = length // self.batch_size # 미니배치 횟수
if length % self.batch_size:
bins += 1 # 나누어 떨어지지 않을 때
indexes = np.random.permutation(np.arange(len(x))) # 인덱스를 섞습니다.
x = x[indexes]
y = y[indexes]
for i in range(bins):
start = self.batch_size * i
end = self.batch_size * (i + 1)
yield x[start:end], y[start:end] # batch_size만큼 슬라이싱하여 반환합니다.
def training(self, x, y):
m = len(x) # 샘플 개수를 저장합니다.
z = self.forpass(x) # 정방향 계산을 수행합니다.
a = self.sigmoid(z) # 활성화 함수를 적용합니다.
err = -(y - a) # 오차를 계산합니다.
# 오차를 역전파하여 그래디언트를 계산합니다.
w1h_grad, w1x_grad, b1_grad, w2_grad, b2_grad = self.backprop(x, err)
# 셀의 가중치와 절편을 업데이트합니다.
self.w1h -= self.lr * w1h_grad
self.w1x -= self.lr * w1x_grad
self.b1 -= self.lr * b1_grad
# 출력층의 가중치와 절편을 업데이트합니다.
self.w2 -= self.lr * w2_grad
self.b2 -= self.lr * b2_grad
return a
def predict(self, x):
z = self.forpass(x) # 정방향 계산을 수행합니다.
return z > 0 # 스텝 함수를 적용합니다.
def score(self, x, y):
# 예측과 타깃 열 벡터를 비교하여 True의 비율을 반환합니다.
return np.mean(self.predict(x) == y.reshape(-1, 1))
def update_val_loss(self, x_val, y_val):
z = self.forpass(x_val) # 정방향 계산을 수행합니다.
a = self.sigmoid(z) # 활성화 함수를 적용합니다.
a = np.clip(a, 1e-10, 1-1e-10) # 출력 값을 클리핑합니다.
val_loss = np.mean(-(y_val*np.log(a) + (1-y_val)*np.log(1-a)))
self.val_losses.append(val_loss)모델 훈련
rn = RecurrentNetwork(n_cells=32, batch_size=32, learning_rate=0.01)
rn.fit(x_train_onehot, y_train, epochs=20, x_val=x_val_onehot, y_val=y_val)훈련, 검증 세트 손실 그래프 확인
import matplotlib.pyplot as plt
plt.plot(rn.losses)
plt.plot(rn.val_losses)
plt.show()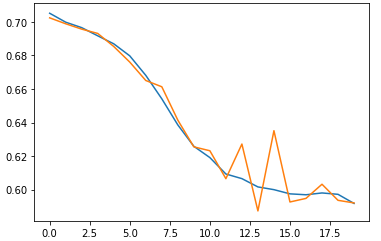
검증 세트 정확도 평가
rn.score(x_val_onehot, y_val)0.6816
2. 텐서플로 순환 신경망
텐서플로에서 가장 기본적인 순환층 -> SimpleRNN 클래스
클래스 임포트
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN모델 생성
model = Sequential()
model.add(SimpleRNN(32, input_shape=(100, 100)))
model.add(Dense(1, activation='sigmoid'))
model.summary()Dense 클래스와 다르지 않다.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn (SimpleRNN) (None, 32) 4256
_________________________________________________________________
dense (Dense) (None, 1) 33
=================================================================
Total params: 4,289
Trainable params: 4,289
Non-trainable params: 0
_________________________________________________________________모델 컴파일 및 훈련
model.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(x_train_onehot, y_train, epochs=20, batch_size=32,
validation_data=(x_val_onehot, y_val))훈련, 검증 세트 손실그래프, 정확도 그래프
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.show()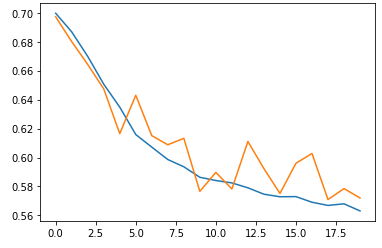
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.show()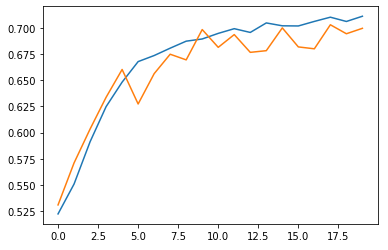
검증 세트 정확도 평가
loss, accuracy = model.evaluate(x_val_onehot, y_val, verbose=0)
print(accuracy)0.6998000144958496
3. 임베딩을 이용한 순환신경망
원-핫 인코딩을 사용할 경우 0과 1로 숫자가 바뀌기 때문에 밀접한 단어 사이의 관계를 표현할 수
없음. 이에 단어 임베딩을 사용.
Embedding 클래스 임포트
from tensorflow.keras.layers import Embedding훈련 데이터 준비
(x_train_all, y_train_all), (x_test, y_test) = imdb.load_data(skip_top=20, num_words=1000)
for i in range(len(x_train_all)):
x_train_all[i] = [w for w in x_train_all[i] if w > 2]
x_train = x_train_all[random_index[:20000]]
y_train = y_train_all[random_index[:20000]]
x_val = x_train_all[random_index[20000:]]
y_val = y_train_all[random_index[20000:]]샘플 길이 맞추기
maxlen=100
x_train_seq = sequence.pad_sequences(x_train, maxlen=maxlen)
x_val_seq = sequence.pad_sequences(x_val, maxlen=maxlen)모델 생성
model_ebd = Sequential()
model_ebd.add(Embedding(1000, 32))
model_ebd.add(SimpleRNN(8))
model_ebd.add(Dense(1, activation='sigmoid'))
model_ebd.summary()모델 훈련
model_ebd.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history = model_ebd.fit(x_train_seq, y_train, epochs=10, batch_size=32,
validation_data=(x_val_seq, y_val))손실그래프 및 정확도 그래프
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.show()
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.show()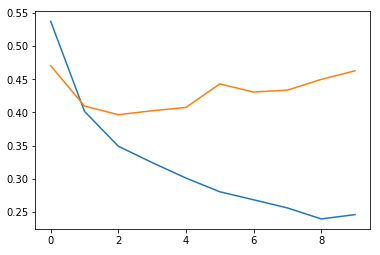
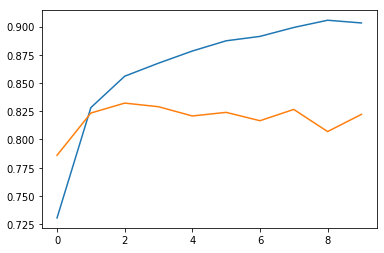
검증 세트 정확도
loss, accuracy = model_ebd.evaluate(x_val_seq, y_val, verbose=0)
print(accuracy)0.8222000002861023
4. 성능 향상을 위한 LSTM 순환 신경망
LSTM 순환 신경망 생성 및 학습
from tensorflow.keras.layers import LSTM
model_lstm = Sequential()
model_lstm.add(Embedding(1000, 32))
model_lstm.add(LSTM(8))
model_lstm.add(Dense(1, activation='sigmoid'))
model_lstm.summary()
model_lstm.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history = model_lstm.fit(x_train_seq, y_train, epochs=10, batch_size=32,
validation_data=(x_val_seq, y_val))정확도 측정
loss, accuracy = model_lstm.evaluate(x_val_seq, y_val, verbose=0)
print(accuracy)높아진 정확도 확인
0.8371999859809875
