N = 10000
X = 165.1
S = 2
low <- X -1.96 * S / sqrt(N)
high <- X + 1.96 * S / sqrt(N)
low; high
high - X
(low - X) * 100
(high - X) * 100
setwd("C:/Rwork/ ")
data <- read.csv("dataset2/one_sample.csv", header = TRUE)
head(data)
x <- data$survey
summary(x)
length(x)
table(x)
library(prettyR)
freq(x)
binom.test(14, 150, p = 0.2)
binom.test(14, 150, p = 0.2, alternative = "two.sided", conf.level = 0.95)
binom.test(c(14, 150), p = 0.2,
alternative = "greater", conf.level = 0.95)
binom.test(c(14, 150), p = 0.2,
alternative = "less", conf.level = 0.95)
setwd("C:/Rwork/")
data <- read.csv("one_sample.csv", header = TRUE)
str(data)
head(data)
x <- data$time
head(x)
summary(x)
mean(x)
mean(x, na.rm = T)
x1 <- na.omit(x)
mean(x1)
shapiro.test(x1)
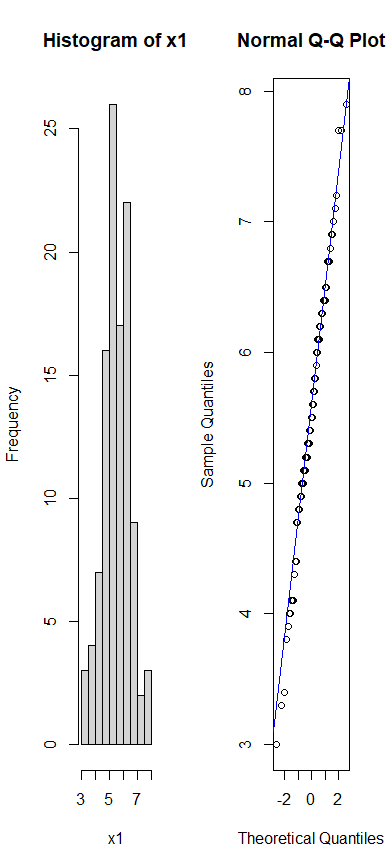
par(mfrow = c(1, 2))
hist(x1)
t.test(x1, mu = 5.2)
qqnorm(x1)
qqline(x1, lty = 1, col = "blue")
t.test(x1, mu = 5.2, alter = "two.side", conf.level = 0.95)
t.test(x1, mu = 5.2, alter= "greater", conf.level = 0.95)
qt(0.05, 108, lower.tail=F)
setwd("C:/Rwork/ ")
data <- read.csv("dataset2/two_sample.csv", header = TRUE)
head(data)
x <- data$method
y <- data$survey
table(x)
table(y)
table(x, y, useNA = "ifany")
prop.test(c(110, 135), c(150, 150),
alternative = "two.sided", conf.level = 0.95)
prop.test(c(110, 135), c(150, 150),
alter = "greater", conf.level = 0.95)
prop.test(c(110, 135), c(150, 150),
alter = "less", conf.level = 0.95)
data <- read.csv("C:/Rwork/two_sample.csv", header = TRUE)
head(data)
summary(data)
result <- subset(data, !is.na(score), c(method, score))
a <- subset(result, method == 1)
b <- subset(result, method == 2)
a1 <- a$score
b1 <- b$score
length(a1)
length(b1)
mean(a1)
mean(b1)
var.test(a1, b1)
t.test(a1, b1, altr = "two.sided",
conf.int = TRUE, conf.level = 0.95)
t.test(a1, b1, alter = "greater",
conf.int = TRUE, conf.level = 0.95)
t.test(a1, b1, alter = "less",
conf.int = TRUE, conf.level = 0.95)
