생일 공격(Birthday Attack)의 수학적 결론

앞서 배운 생일 역설 공식을 통해 해커가 충돌을 찾아내는 데 필요한 연산 횟수(Steps)를 도출합니다.
- 공식: 확률이 50%()일 때, 시도해야 하는 횟수 는 다음과 같이 근사됩니다.
- 결론 (Security Rule of Thumb):
수식이 복잡해 보이지만, 핵심은 지수 부분인 입니다. 해시 함수의 출력 길이가 비트일 때, 해커는 다 찾아볼 필요 없이 대략 번만 계산하면 충돌을 찾아낼 수 있습니다. - 교수님의 예시 (Ex):
해시 길이가 80 비트()라면, 해커는 겨우 steps 만에 충돌을 찾습니다. 따라서 현대 암호학의 최소 안전 기준인 steps를 강제하려면, 해시 함수의 길이는 무조건 그 두 배인 최소 160 bits ()가 되어야 합니다.
해시 함수의 계보 (Hash Function Family)
그렇다면 이 해시 함수를 어떻게 만들까요? 크게 블록 암호를 재활용하는 방식과 해시 전용으로 새로 만드는 방식이 있습니다. 필기에서는 전용 해시 함수(Dedicated Hash Functions)의 역사를 짚어주십니다
- MD5: 완전히 깨져서 더 이상 쓰지 않습니다 (X 표시).
- SHA-1 (160 bits 출력):
원래대로라면 충돌을 찾는 데 번의 연산이 필요해야 정상입니다. 하지만 필기에 붉은색으로 적힌 Xiaoyun Wang 교수팀이 2005년에 수학적 취약점을 발견하여, 이를 번() 만에 깰 수 있음을 증명했습니다. 따라서 SHA-1도 현재는 폐기되었습니다. - SHA-2 / SHA-3:
SHA-1이 뚫린 이후 산업계의 표준이 된 안전한 해시 함수들입니다. 출력 길이에 따라 SHA-256, SHA-512 등으로 부르며, 숫자가 클수록 안전하지만 연산이 무겁습니다.
SHA-1의 내부 구조 (Merkle-Damgård Construction)
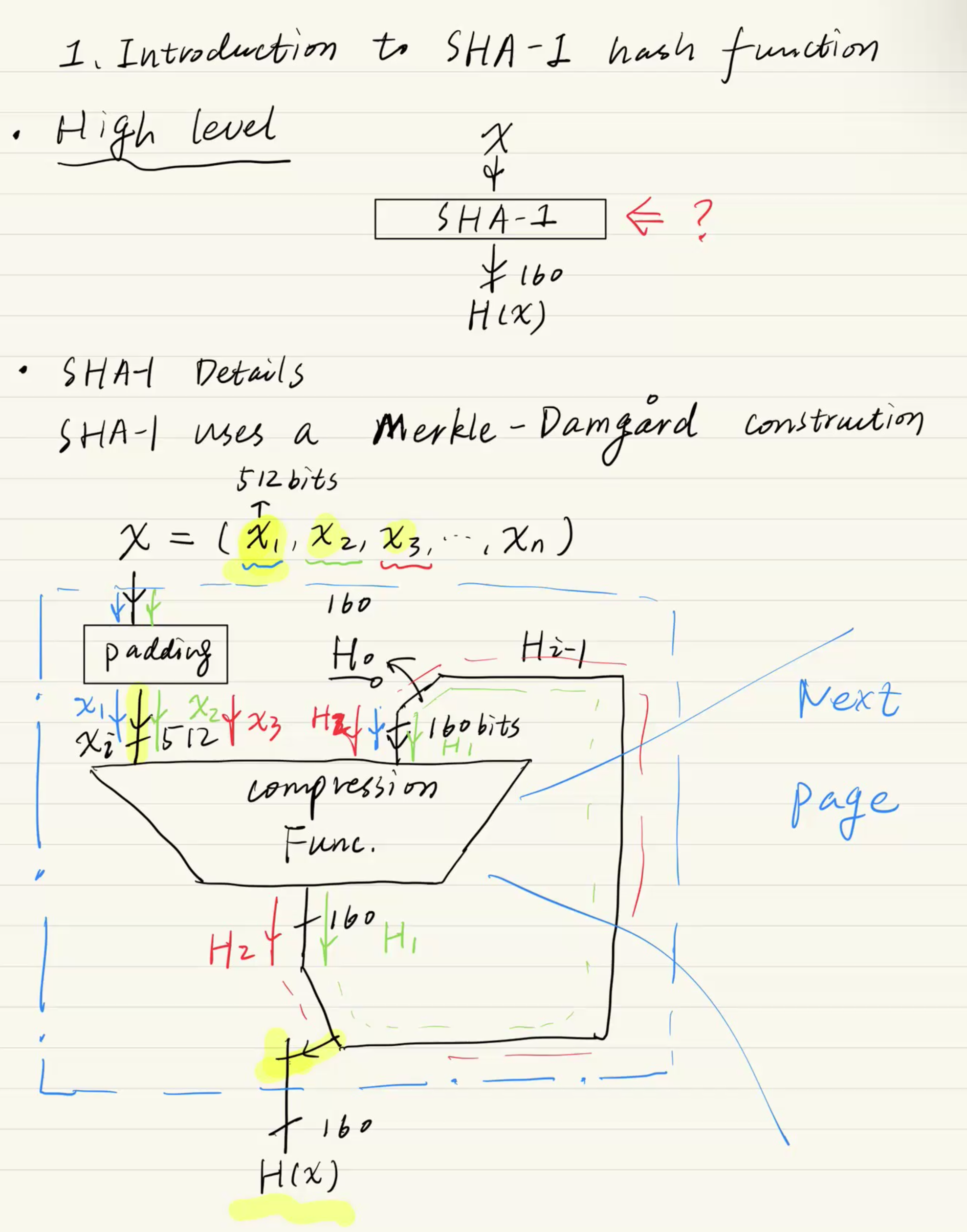
임의의 길이를 가진 거대한 파일(Arbitrary input length)을 어떻게 고정된 160 비트(Fixed output length)로 압축할까요? 그 비밀이 바로 Merkle-Damgård (머클-담고르) 구조입니다.
하드웨어의 Shift Register나 연속된 파이프라인 처리 구조를 상상하시면 이해하기 쉽습니다.
Step 1: Padding (패딩)
파일의 총길이가 512 bits의 배수가 되도록 끝에 의미 없는 비트들을 채워 넣습니다.
Step 2: Splitting (쪼개기)
패딩 된 전체 파일을 512 비트 단위의 블록 여러 개()로 쪼갭니다.
Step 3: Compression Function(압축 함수 - 핵심 파트)
- 초기화 벡터 (160 bits)와 첫 번째 데이터 블록 (512 bits)을 믹서기(압축 함수)에 같이 넣고 돌립니다.
- 결과물로 새로운 상태 값 (160 bits)이 튀어나옵니다.
- 이 을 다시 다음 데이터 블록 (512 bits)와 함께 믹서기에 넣습니다.
- 이 과정을 전체 파일이 끝날 때까지 꼬리에 꼬리를 물고 반복(Iterative)합니다.
Step 4: Final Output
마지막 블록 까지 처리하고 최종적으로 튀어나온 160 비트 값 가 바로 이 파일의 최종 해시값(지문)이 됩니다.
블록 암호와의 비교 & Feedforward 구조
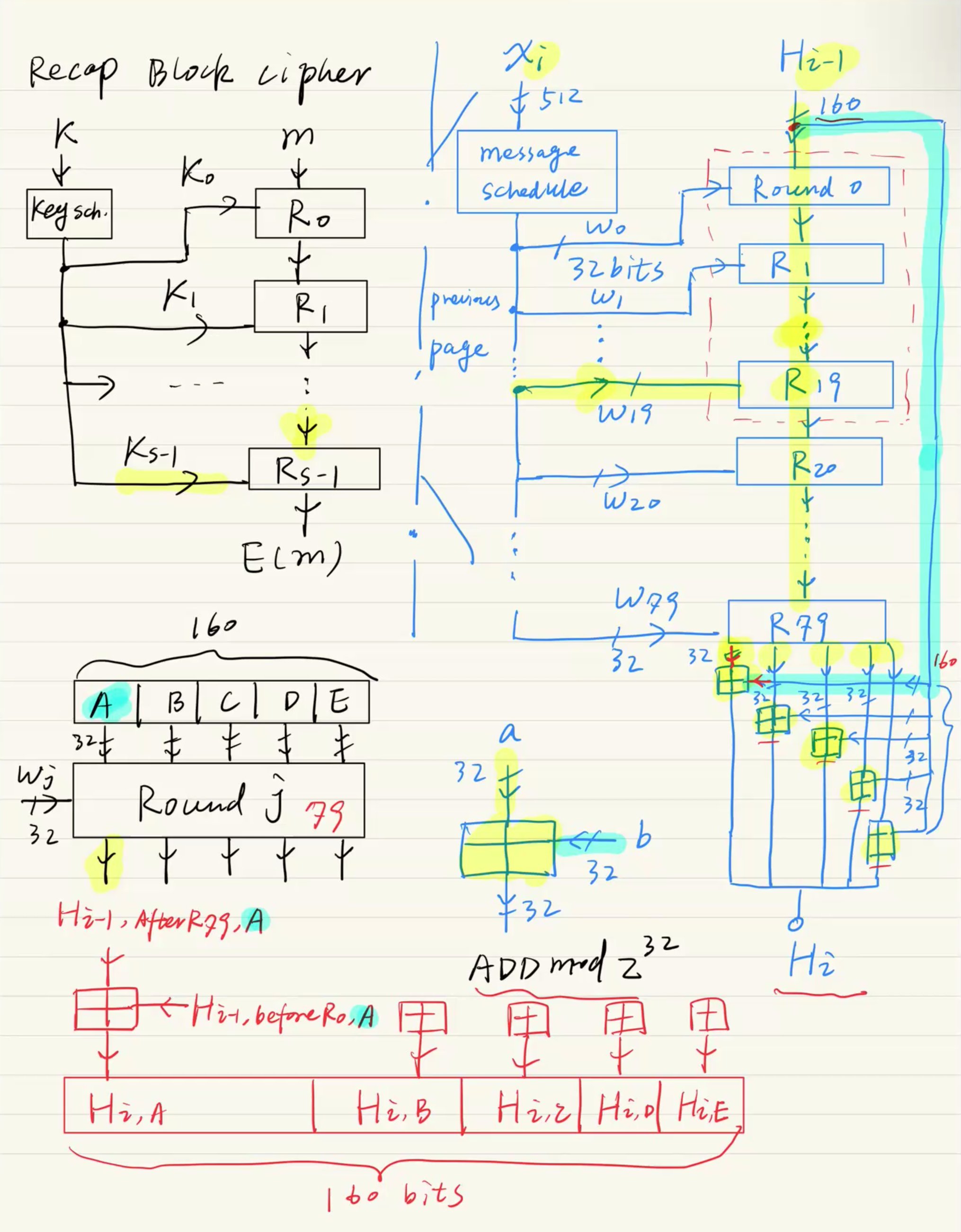
교수님이 블록 암호(Block cipher) 구조를 먼저 리뷰(Recap)하신 이유는, 해시 함수의 내부 로직이 사실상 블록 암호와 똑같이 생겼기 때문입니다.
구조적 유사성:
- 블록 암호는 암호화 키를 Key schedule을 통해 쪼개서 각 라운드()에 공급합니다.
- SHA-1은 512비트의 원본 메시지 블록 를 Message schedule을 통해 32비트짜리 워드 단위()로 쪼개서 각 라운드에 공급합니다.
5개의 레지스터 (A, B, C, D, E):
- 160비트의 상태값(State)은 32비트짜리 레지스터 5개로 쪼개져서 라운드를 통과합니다.
핵심 설계: Feedforward (초록색/파란색 형광펜)
- 80개의 라운드를 다 거치고 나온 결과값을 그대로 다음 블록으로 넘기지 않습니다. 라운드 진입 전의 원래 초기 상태값 을 맨 마지막 결과값과 각각 모듈러 덧셈(ADD mod )을 해줍니다.
보안적 의미: 이 덧셈 구조 덕분에, 출력값을 보고 입력값을 역추적하는 것(One-wayness)이 수학적으로 불가능해집니다.
80 Rounds & 4 Stages
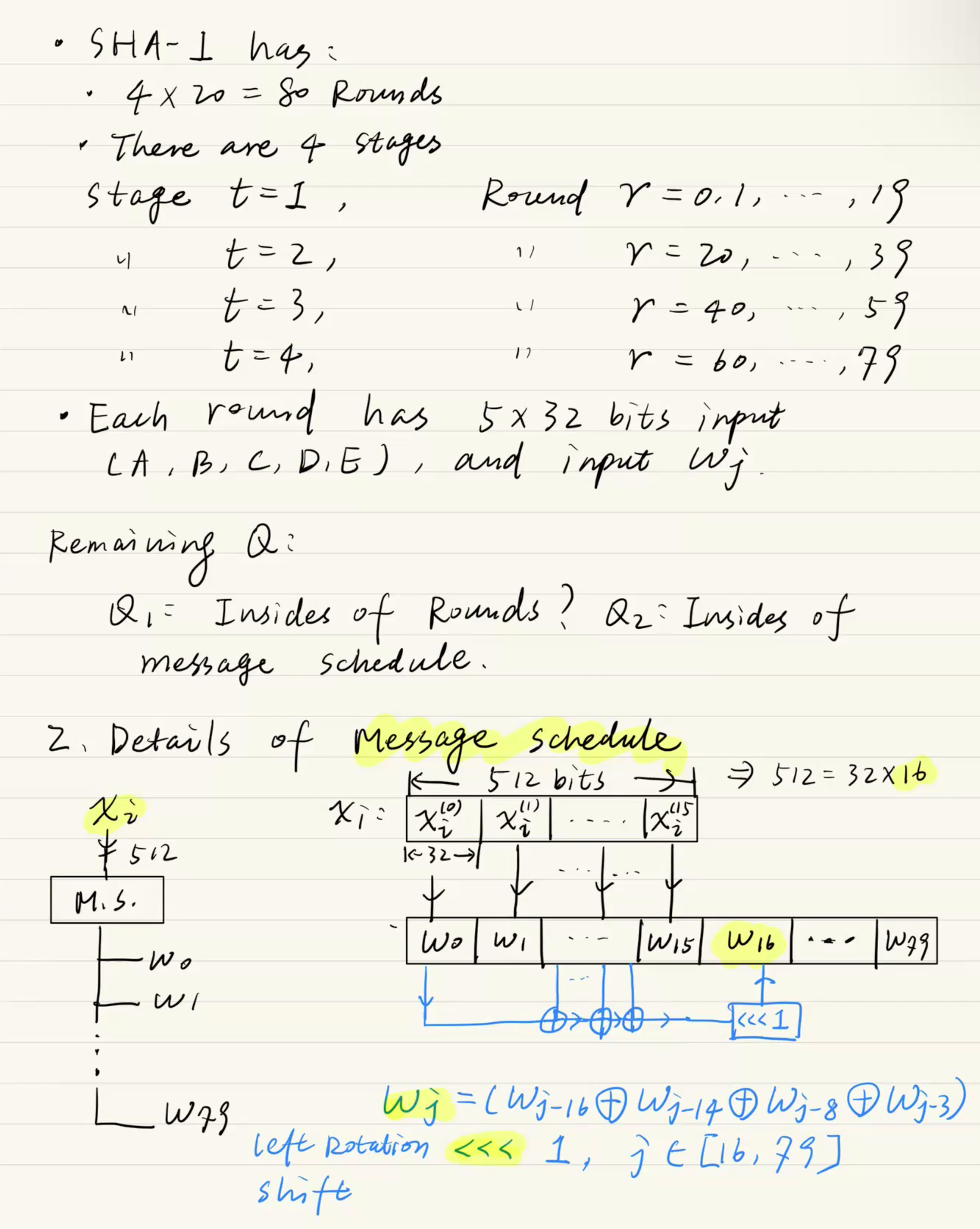
SHA-1의 전체 루프 구조입니다.
- 80 Rounds: 각 512비트 메시지 블록 하나를 처리하는 데 총 80번의 연산(Round)을 돕니다.
- 4 Stages: 이 80개의 라운드는 20개씩 묶여서 총 4개의 스테이지()로 나뉩니다. 각 스테이지를 넘어갈 때마다 내부에서 쓰는 논리 함수(AND, OR, XOR 조합)와 고정 상수(Constant)가 바뀝니다.
Message Schedule (메시지 스케줄링) ★서술형 단골 수식★
512비트의 메시지를 어떻게 80개의 라운드에 공급할 워드()로 뻥튀기하는지 보여주는 공식입니다. 하드웨어의 LFSR (Linear Feedback Shift Register) 동작과 완전히 똑같습니다.
- 초기 분할: 처음 들어온 512비트를 32비트씩 자르면 딱 16개()의 워드가 나옵니다.
- 확장 연산 (Expansion): 나머지 16번부터 79번까지의 워드는 이전 워드들의 값을 가져와 XOR () 연산을 한 뒤, 왼쪽으로 1비트 원형 시프트 (Circular Left Shift, )를 해서 끝없이 생성해 냅니다.
- 핵심 수식:
(단, )
SHA-1 Round Function 내부 로직
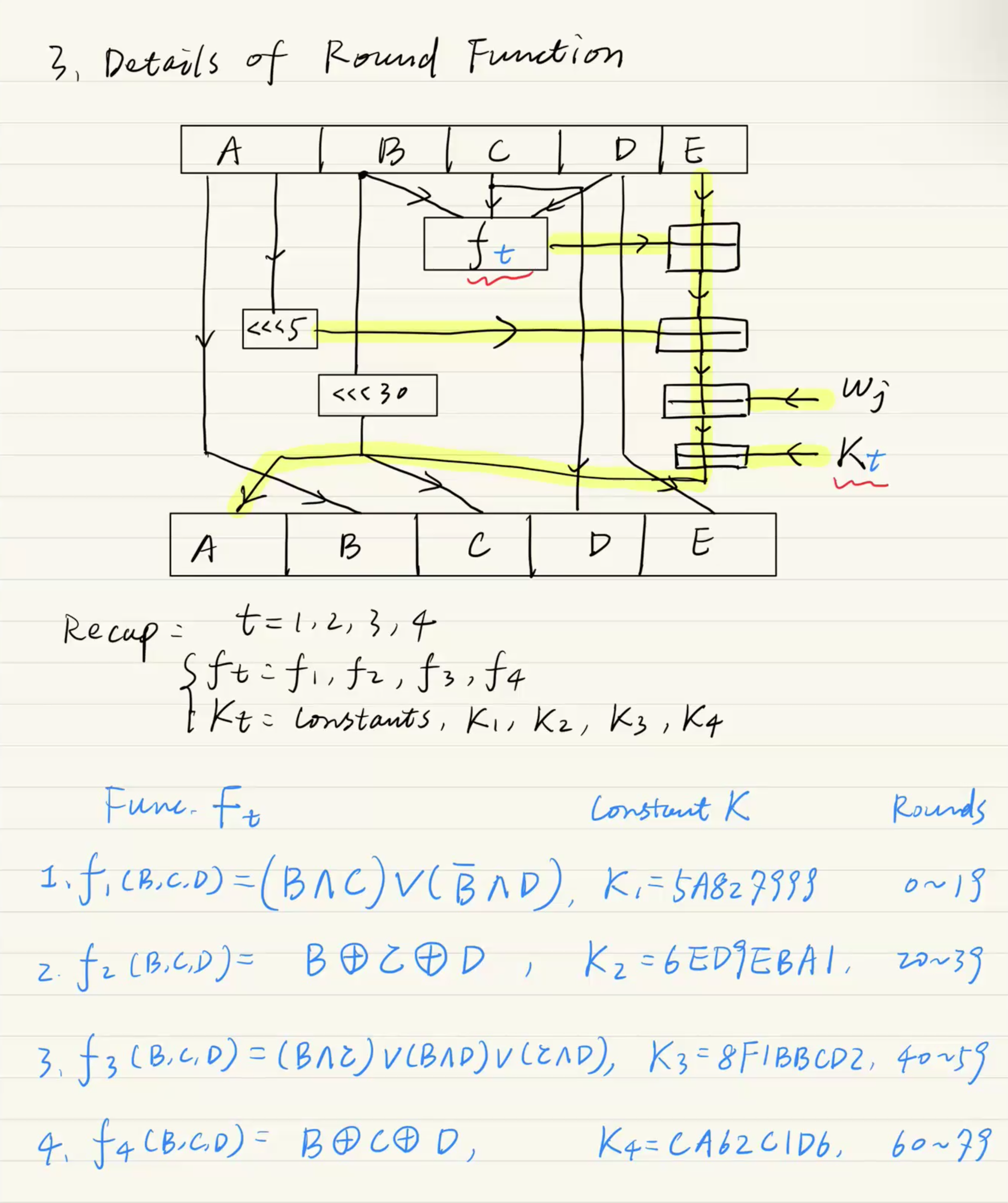
앞서 본 5개의 레지스터(A, B, C, D, E)가 1개의 라운드 박스 안에서 어떻게 뒤섞이는지 보여주는 다이어그램입니다. 하드웨어 스키매틱과 똑같이 생겼습니다.
-
이동 (Shift): 레지스터 B, C, D는 위치만 옆으로 밀리거나, 비트 시프트()를 거쳐 다음 레지스터로 들어갑니다.
-
논리 함수 (): 레지스터 B, C, D의 값은 스테이지마다 바뀌는 논리 함수 (AND, OR, XOR 조합)를 통과합니다.
-
핵심 연산 (노란색 하이라이트 라인):가장 극적인 변화가 일어나는 것은 레지스터 A와 E입니다. 이전 라운드의 A 값을 5비트 시프트()한 값, B/C/D를 논리 함수 로 섞은 값, 이전 라운드의 E 값, 현재 라운드의 워드 , 그리고 고정된 상수 까지 모두 한데 모여 모듈러 덧셈(Add mod )을 수행합니다.
이렇게 섞인 값이 다음 라운드의 새로운 A가 됩니다. 이 거대한 믹서기 구조 덕분에 해시 함수의 단방향성(One-wayness)이 철저하게 보장됩니다.
