Deep Learning
Number of Layer : 5 ~ over 1000
• DNN (Deep Neural Networks)
• Visualizing CNN
• low-level features / higher level features
Perceptron
:다수의 신호를 입력으로 받아 하나의 신호를 출력하는 것
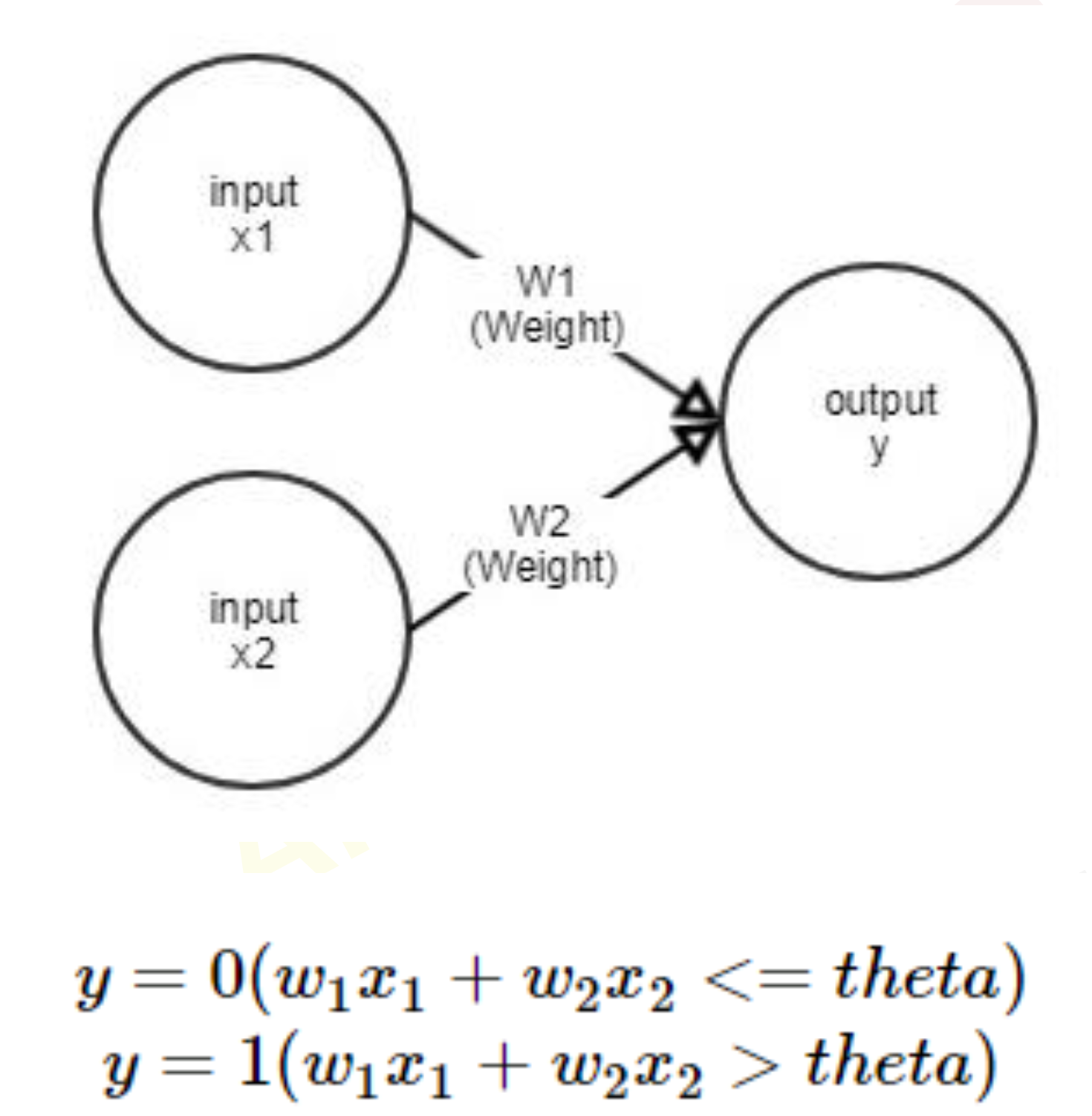
AND
(w1, w2, 세타) = (0.5, 0.5, 0.7), (0.5, 0.5, 0.8) 또는 (1.0, 1.0, 1.0)
NAND
(w1, w2, 세타) = (-0.5, -0.5, -0.7), (-0.5, -0.5, -0.8) 또는 (-1.0, -1.0, -1.0)
OR
(w1, w2, 세타) = (0.3, 0.3, 0.3)Activation Function
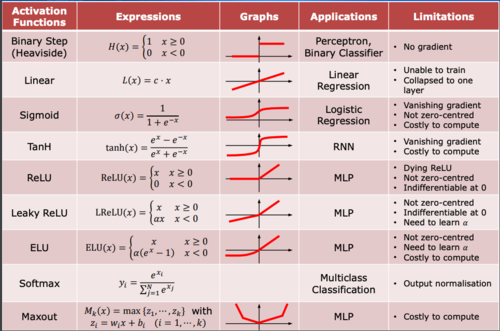
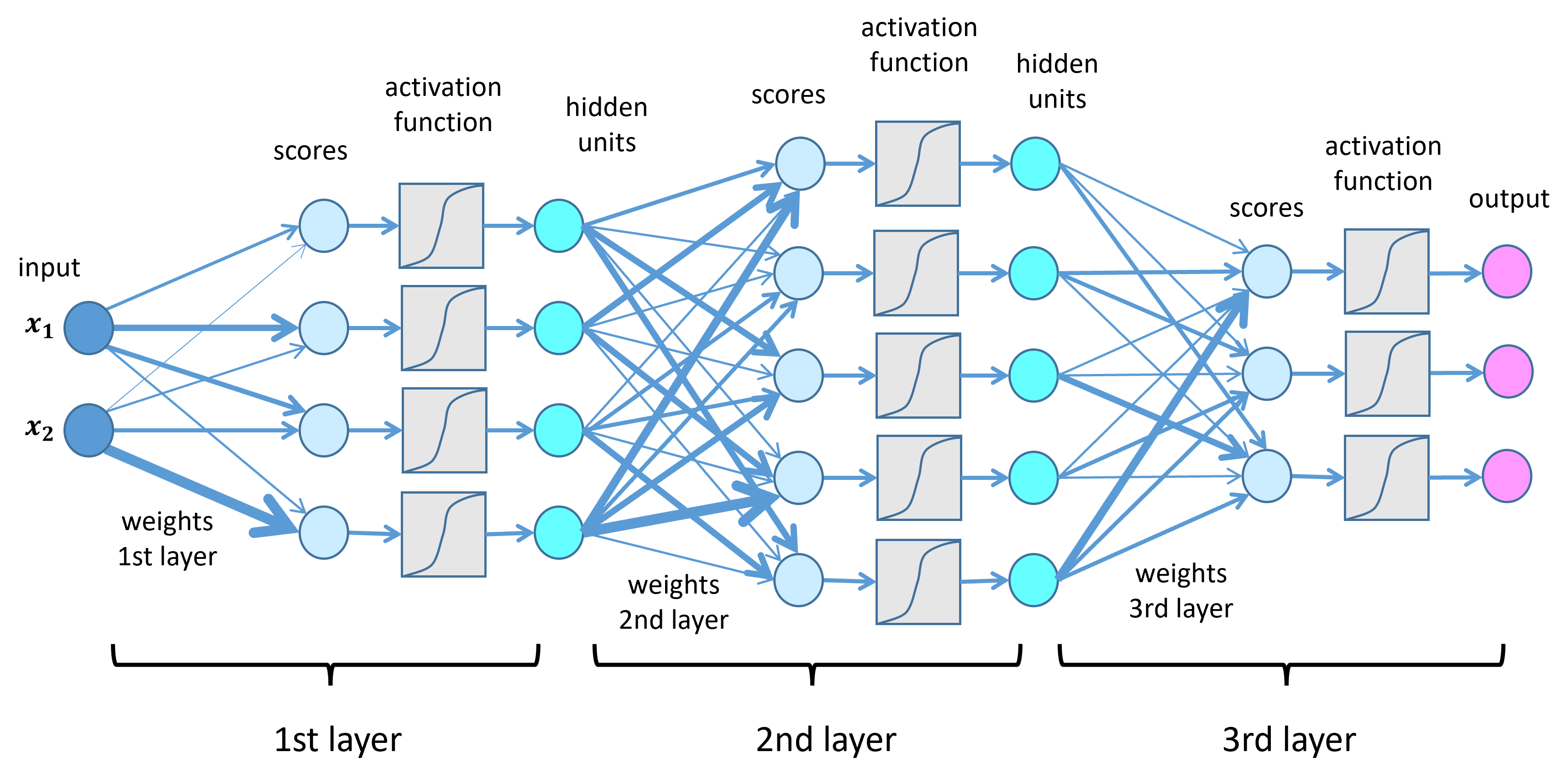
딥러닝 네트워크에서 노드에 입력된 값들을 비선형 함수에 통과시킨 후 다음 레이어로 전달하는데, 이 때 사용하는 함수를 활성화 함수(Activation Function)라고 한다.
-
인공신경망에서 활성화 함수는 입력 데이터를 다음 레이어로 어떻게 출력하느냐를 결정하는 역할이기 때문에 매우 중요하다.
즉, 활성화 함수는 입력을 받아서 활성화 또는 비활성화를 결정하는 데에 사용되는 함수이다. -
선형 함수가 아니라 비선형 함수를 사용하는 이유는 딥러닝 모델의 레이어 층을 깊게 가져갈 수 있기 때문이다.
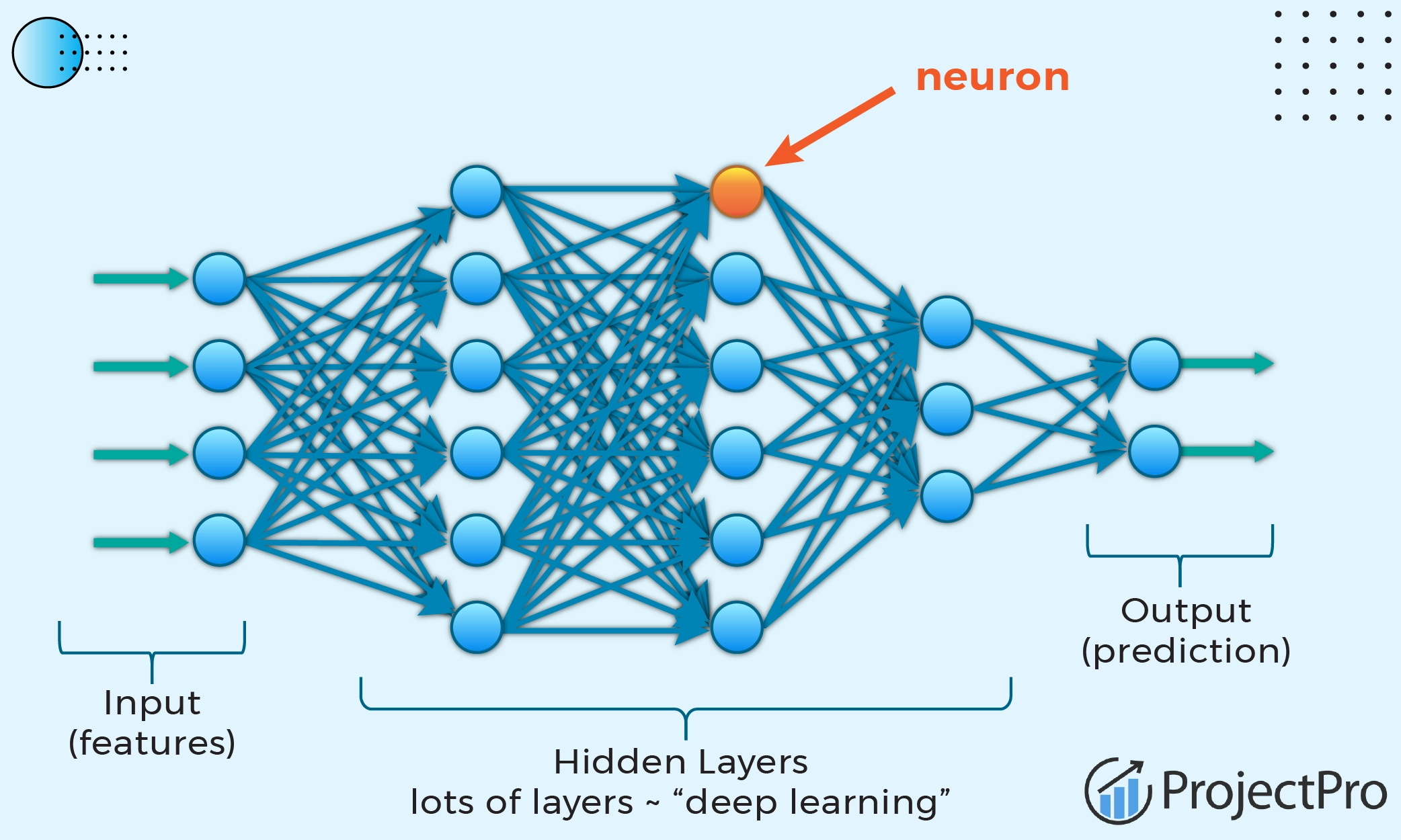
DNN Terminology
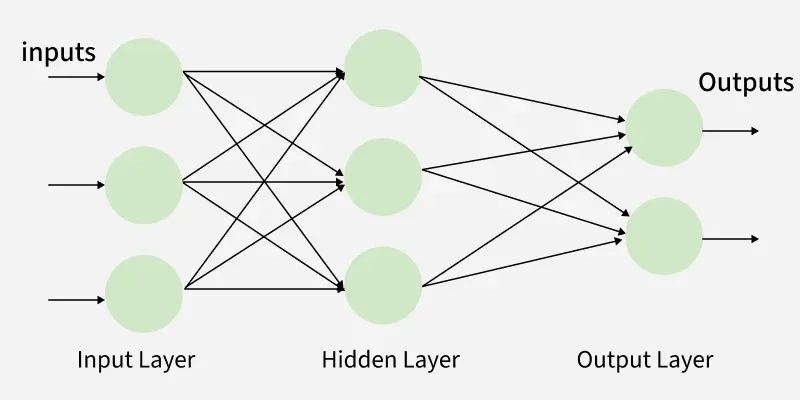
layer는 노드 사이를 얘기하는 것
위 사진은 2개의 layer를 가짐
fully-connected
all i/p neurons connected to all o/p neurons
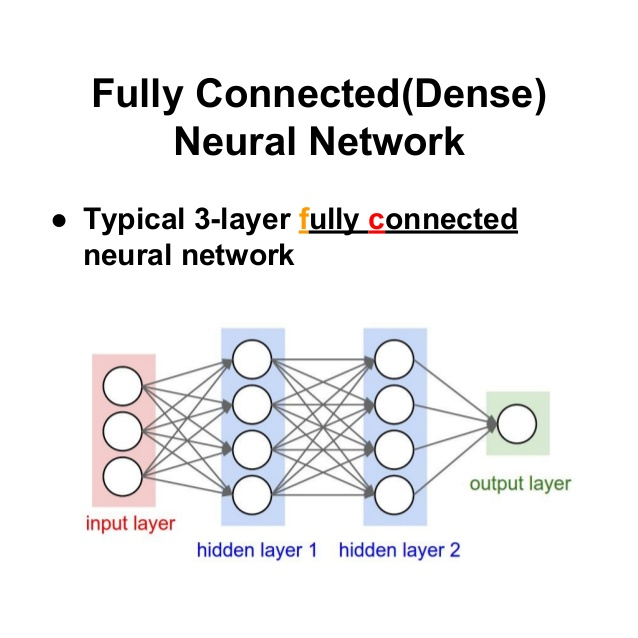
layer 수: 3개
weight 개수: (3x4)+(4x4)+(4x1) = 29
Training & Inference
딥러닝은 크게 두가지 단계로 나눌 수 있다.
학습(Training)
학습과정의 특징은 축적된 많은 데이터를 바탕으로 각 신경망들의 Weight를 업데이트 해가며 딥러닝 모델을 만들어 가는 과정이다.
추론(Inference)
학습을 통해 만들어진 모델을 실제로 새로운 입력 데이터에 적용하여 결과를 내놓는 단계이다.
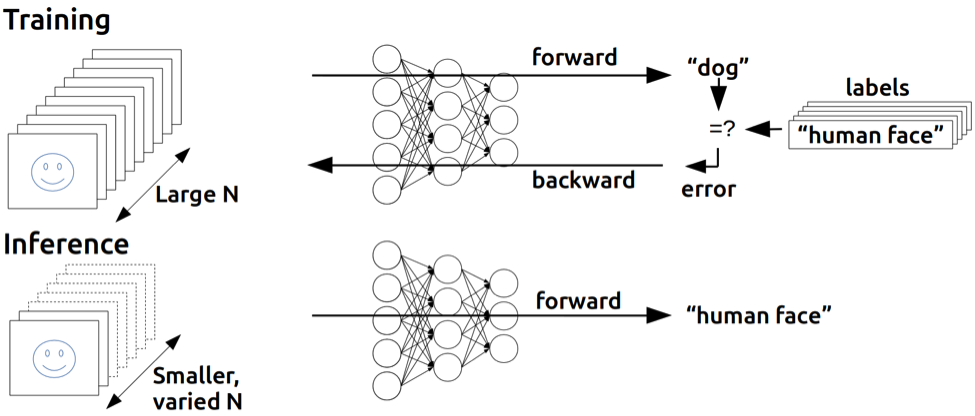
순방향 전파를 통해 각 신경망을 거쳐가고 Loss function을 통해 에러율이 얼마나 되는지 판단하고, 그 에러율을 줄이기 위해 역방향 전파로 다시 신경망을 반대로 지나가면서 각 신경망의 Weight들을 바꾸는 것이다.
NPU는 Inference에 사용되고 GPU에서 Training을 한다.
실제 NPU는 Training이 완료된 모델을 inference 하기 위해 사용된다.
layer를 Deep하게 쌓으면 어려운 문제를 해결할 수 있으나, training이 어렵고 연산량이 증가한다
Types of DNNs
1. Fully-commected NN
feed forward, multilayer perceptron(MLP)
정보를 취합, 전달하는데 적합한 특징, 주로 분류의 답을 구할때 사용
2. Convolutional NN (CNN)
feed forward, sparsely-connected w/weight sharing
시각적 영상을 분석하는데 사용되는 다층의 feed forward적인 DNN의 한종류
시각적 영상 분석에 주로 적용, shift를 하면서 곱하고 누적값을 구해낸다
3. Recurrent NN (RNN)
feedback
출력을 입력으로 다시 사용하는 feedback 구조
음성인식, 차트 예상
4. Long Short-Term Memory(LSTM)
feed back + storage
장기, 단기 정보를 저장하는 memory cell로 구성된 RNN
CNN
Shift를 하면서 곱하고 누적 값을 구해낸다
합성곱 신경망은(Convolutional Neural Network)은 이미지 처리에 탁월한 성능을 보이는 신경망이다.
합성곱 신경망은 크게 합성곱층과(Convolution layer)와 풀링층(Pooling layer)으로 구성된다.
a. channel
기계는 글자나 이미지보다 숫자. 다시 말해, 텐서를 더 잘 처리할 수 있습니다. 이미지는 (높이, 너비, 채널)이라는 3차원 텐서입니다. 여기서 높이는 이미지의 세로 방향 픽셀 수, 너비는 이미지의 가로 방향 픽셀 수, 채널은 색 성분을 의미합니다. 흑백 이미지는 채널 수가 1이며, 각 픽셀은 0부터 255 사이의 값을 가집니다. 아래는 28 × 28 픽셀의 손글씨 데이터를 보여줍니다.

하나의 픽셀은 세 가지 색깔, 삼원색의 조합으로 이루어집니다. 만약, 높이가 28, 너비가 28인 컬러 이미지가 있다면 이 이미지의 텐서는 (28 × 28 × 3)의 크기를 가지는 3차원 텐서입니다. 채널은 때로는 깊이(depth)라고도 합니다. 이 경우 이미지는 (높이, 너비, 깊이)라는 3차원 텐서로 표현된다고 말할 수 있을 겁니다.
sparsely-connected w/weight sharing
weight 는 고정인 상태에서 input feature map을 로딩하여, output feature map을 연산함
b. padding
zero padding, Replication 등 여러방법있음
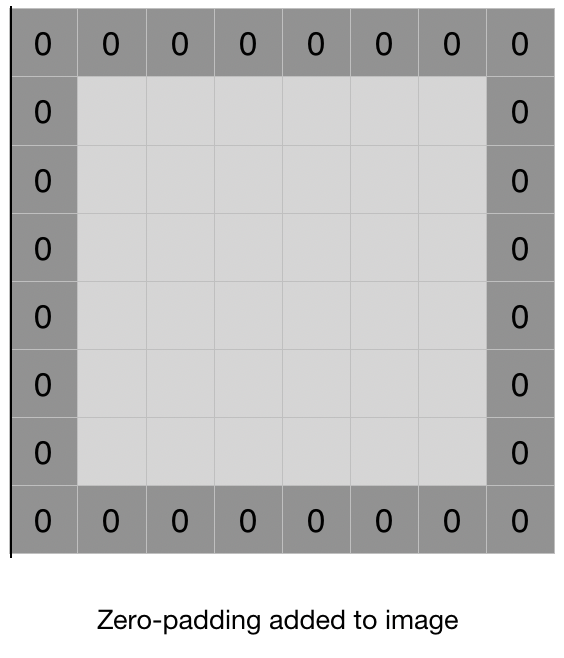
왜 padding이 필요한가?
이미지 데이터의 축소를 막기 위해.
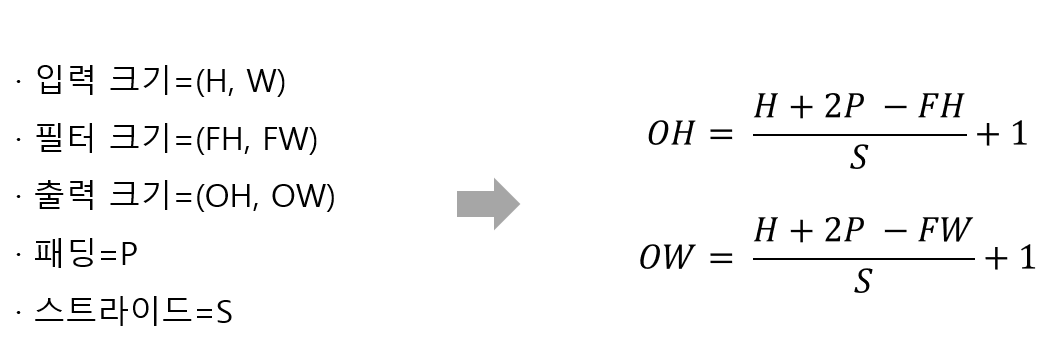
convolution operation에서 input data인 (n x n)pixel image가 (f x f) filter을 통해 (n – f + 1) x (n – f + 1) pixel image로축소된다.
CNN과정에서 위와같이 여러번의 계산을 해야하는데 초반부터 이미지가 너무 작아져 버리면 더 깊게 학습시킬 데이터가 부족해지는 현상이 만들어진다. 이는 neural network의 성능에 악영향을 미치기 때문에 padding을 이용하여 크기를 조절할 수 있다.
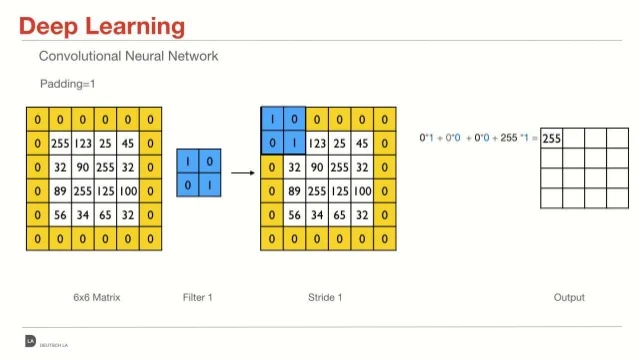
원래 이미지의 크기가 ( n x n ) 이었다면 -- 패딩 후 -> ( (n+2) x (n+2)) 로 이미지의 크기가 커지지만, 합성곱 이후 본래 이미지가 유지되는 것을 볼 수 있다.
패딩을 하지 않을 시에 합성곱의 결과 최종 이미지 크기는 ( n - f + 1 ) x ( n - f + 1 ) 이다.(n: 이미지 한 축 크기, f: 필터 한 축 크기)
예를 들어 6X6 이미지를 3X3 필터로 합성곱 연산시 최종이미지크기는 (6-3+1)x(6-3+1) : (4x4) 가 된다.
그러나 1픽셀의 패딩을 적용하게 되면, 합성곱의 결과 최종 이미지 크기는 ( n + 2p - f + 1 ) x ( n + 2p - f + 1 ) 가 된다. (n: 이미지 한 축 크기, p: 패딩 크기, f: 필터 한 축 크기)
c. Stride (보폭)
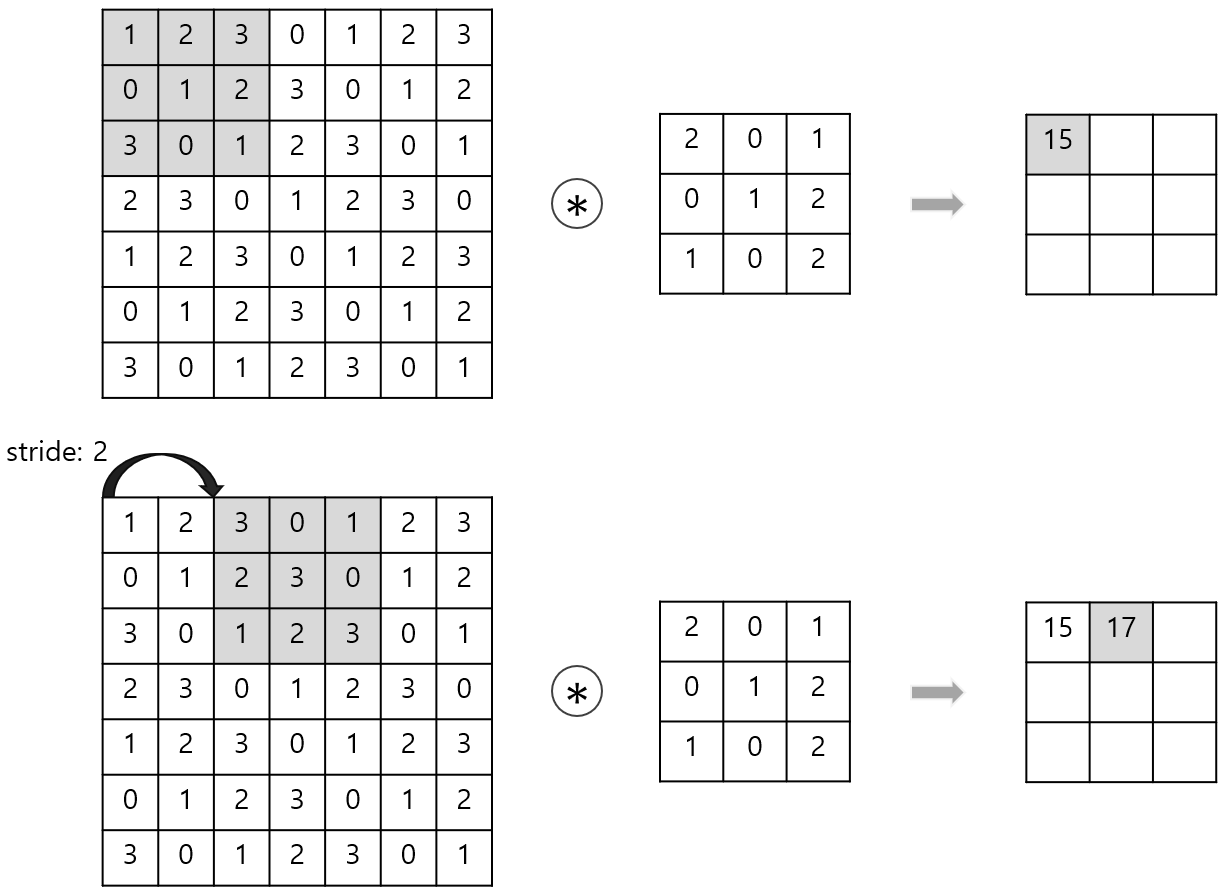
필터를 적용하는 간격
패딩을 크게하면 출력 데이터의 크기가 커지는 반면 스트라이드를 크게하면 출력 데이터의 크기는 작아진다.
d. Pooling
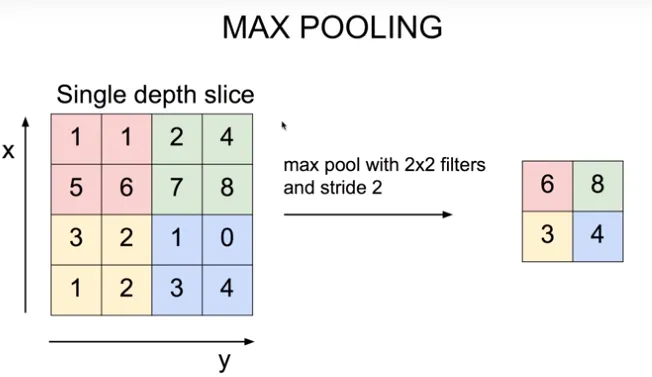
각 pixel마다 최댓값을 뽑아낸다. (max pooling)
합성곱 신경망(CNN)에서 특징 맵(feature map)의 공간적 크기(높이, 너비)를 줄여 모델의 복잡도를 낮추고, 중요한 특징을 강조하며 과적합(overfitting)을 방지하는 다운샘플링(down-sampling) 기술
