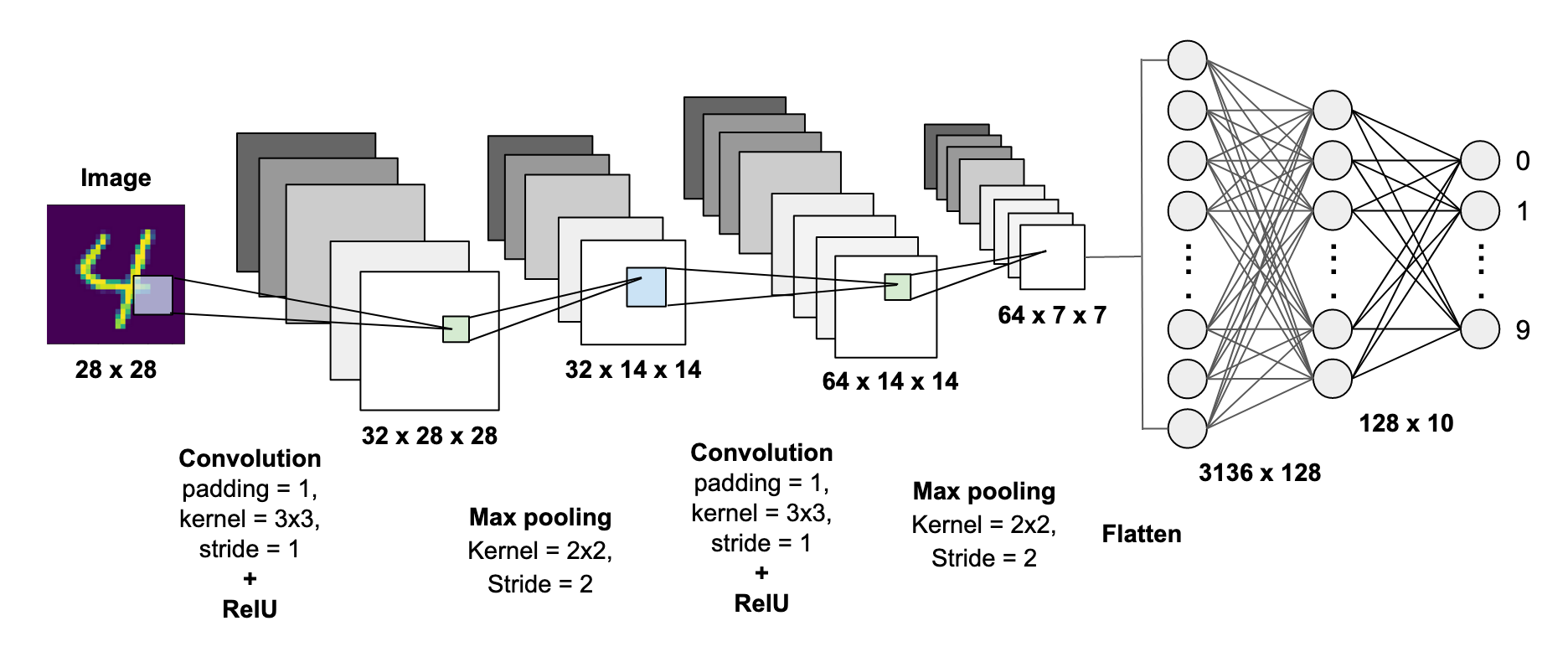
LeNet-5 (1998)
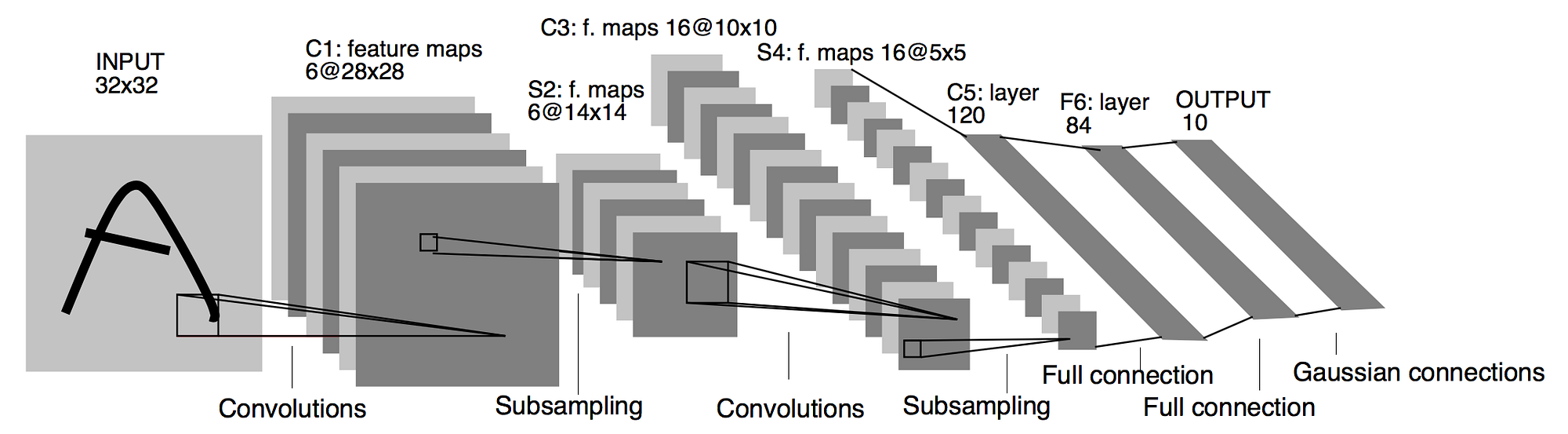
구조: Input C1(Conv) S2(Pool) C3(Conv) S4(Pool) C5(Conv/FC) F6(FC) Output(FC)
- 사용자가 언급한 CONV Layer: 2는 C1과 C3 계층을 의미합니다.
- 사용자가 언급한 Fully Connected(FC) Layer: 2는 보통 F6와 Output 계층을 의미합니다
CONV Layer:2
fully connected layer: 2
weight(파라미터 수): 60k
MACs(Multiply-Accumulate) 연산량: 341k
Sigmold used for non-linearity (비선형 함수)
AlexNet (2012)
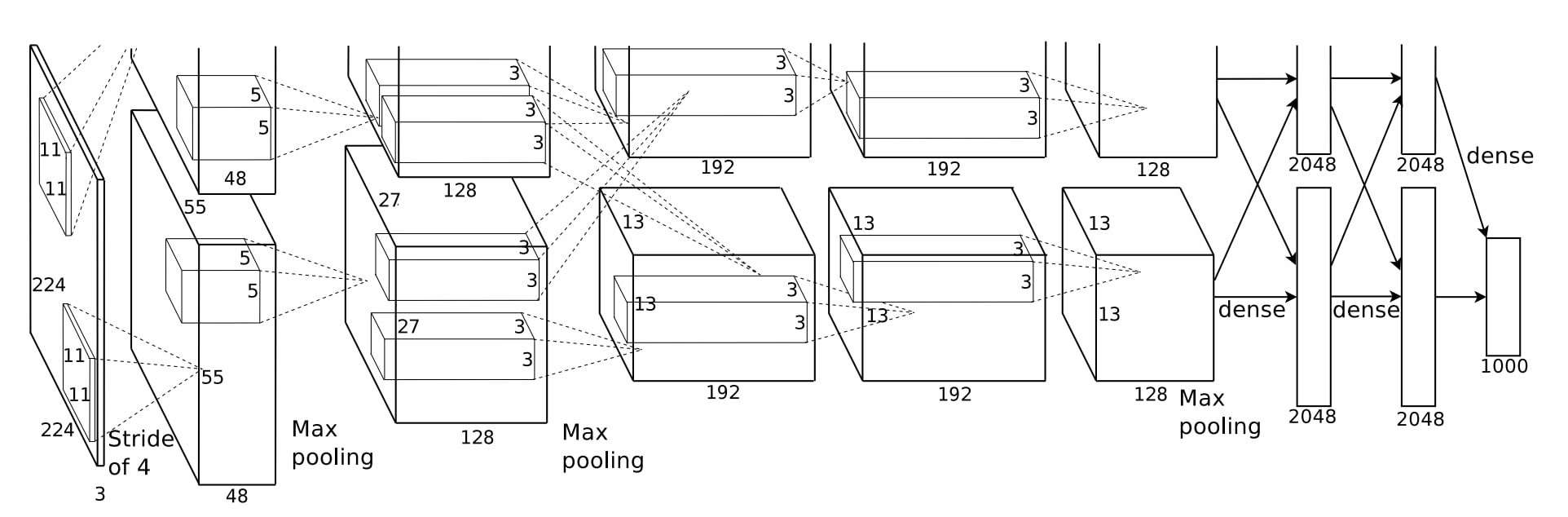

CONV Layer:5
fully connected layer: 3
weight: 61M
MACs: 724M
ReLU used for non-linerity
- 핵심 요약
- 의의: 딥러닝 붐의 시작 (ILSVRC 우승), LeNet-5의 확장판
- 구조: 5개의 Conv Layer + 3개의 FC Layer
- 파라미터: 약 6,000만 개 (LeNet의 1000배)
- 환경: GPU 2대 병렬 사용
- 주요 혁신 기술
- ReLU 도입: Sigmoid의 기울기 소실 문제 해결, 학습 속도 가속
- Dropout: FC Layer 뉴런을 50% 꺼버려 과적합(Overfitting) 방지
- Data Augmentation: 이미지 반전, 자르기 등으로 데이터 뻥튀기
- Overlapping Pooling: 풀링 영역을 겹쳐서 진행 (오버피팅 방지)
- 구조 상세 (입력: 227x227 컬러)
- Conv 1: 11x11 큰 필터 사용 (Stride 4)
- Conv 2: 5x5 필터
- Conv 3, 4, 5: 3x3 작은 필터를 연속으로 배치 (비선형성 증가)
- FC 6, 7: 4096개 노드 + Dropout 적용
- Output: 1000개 노드 (Softmax, 1000개 클래스 분류)
VGG-16 (2014)
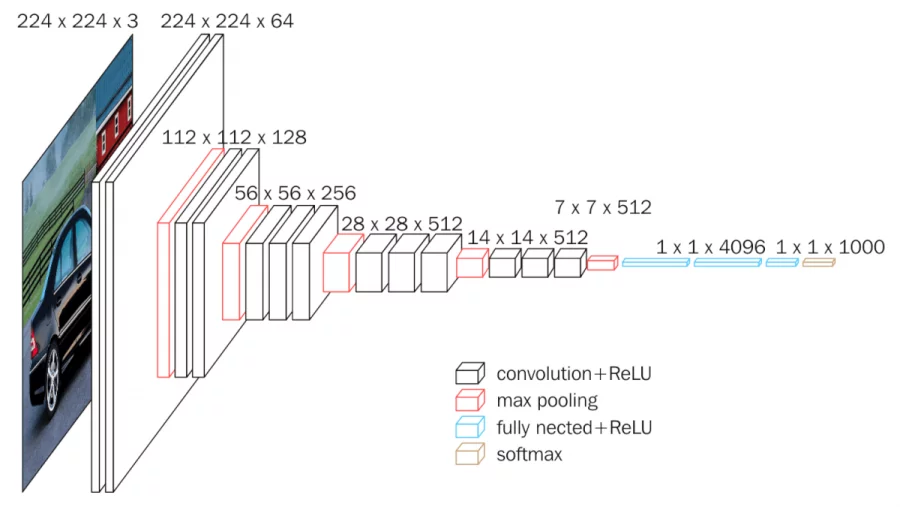
Conv layers:13
Fully connected layers:3
weights: 138M
MACs: 15.5G
3x3 conv
receptive field
다수의 레이어에 작은 커널을 써도 성능이 향상
-
개요
- 개발: 2014년 옥스퍼드 대학교 VGG 연구팀 (Simonyan & Zisserman)
- 성과: ILSVRC 2014 대회 준우승 (우승은 GoogLeNet이나, 실무에서는 VGG가 더 많이 쓰임)
- 의의: 네트워크의 '깊이(Depth)'가 성능에 중요하다는 것을 증명함
-
핵심 아이디어: 3x3 필터 사용
VGG-16은 모든 층에서 가장 작은 크기인 '3x3 필터'만 사용했습니다.- 원리: 3x3 필터를 2번 겹치면 5x5 필터 1개와 같고, 3번 겹치면 7x7 필터 1개와 같은 시야(Receptive Field)를 가짐
- 장점 1 (비선형성): 층이 깊어지면서 활성화 함수(ReLU)를 더 많이 통과해 복잡한 특징을 잘 잡아냄
- 장점 2 (파라미터 감소): 큰 필터 한 장보다 작은 필터 여러 장이 파라미터 수가 더 적음
-
아키텍처 구조 (총 16개 층)
입력 이미지는 224x224 RGB를 사용하며, 아래 과정을 거칩니다.(1) 합성곱 블록 (Convolution Blocks)
- 구조: [3x3 Conv] 반복 -> [2x2 Max Pooling]
- 채널 변화: 64 -> 128 -> 256 -> 512 -> 512 로 점점 두꺼워짐
- 특징: 이미지 크기는 절반씩 줄어들고, 깊이는 2배씩 늘어남(2) 완전 연결 층 (Fully Connected Layers)
- FC (4096 노드) -> ReLU -> Dropout
- FC (4096 노드) -> ReLU -> Dropout
- FC (1000 노드) -> Softmax (최종 분류) -
장단점 요약
[장점]
- 구조가 단순함: 작은 필터의 단순 반복이라 이해와 구현이 쉬움
- 전이 학습(Transfer Learning)에 유리: 이미지 특징을 추출하는 능력이 매우 뛰어나 다른 AI 모델의 베이스로 자주 쓰임
[단점]
- 엄청난 용량: 파라미터 개수가 약 1억 3,800만 개로 매우 무거움
- 느린 속도: 연산량이 많아 학습과 실행 속도가 최신 모델에 비해 느림
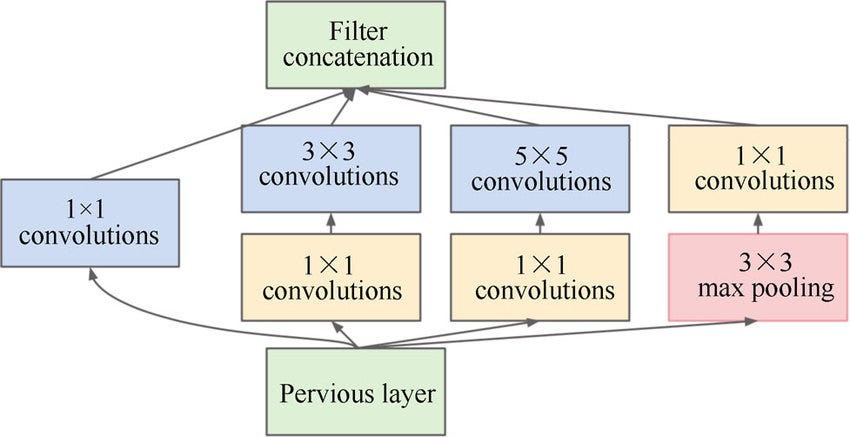
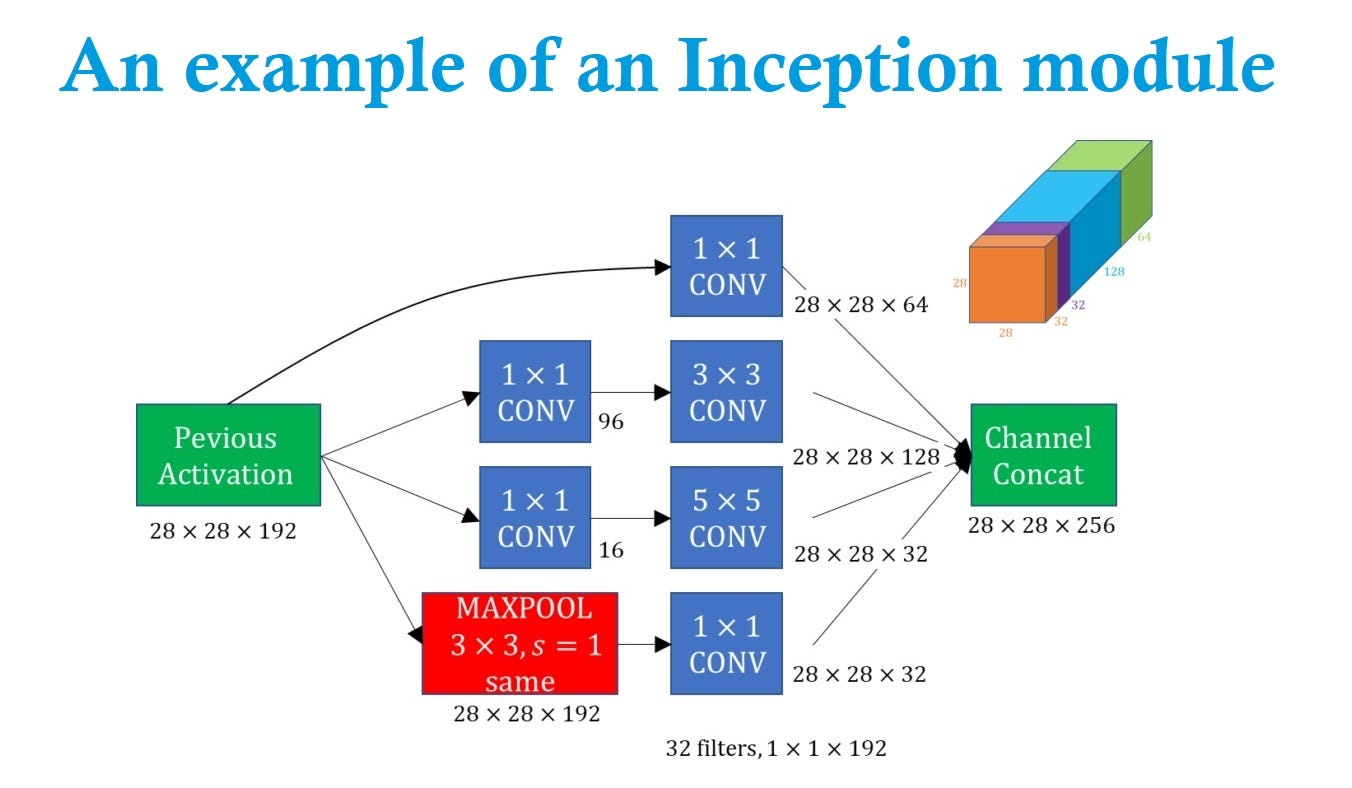
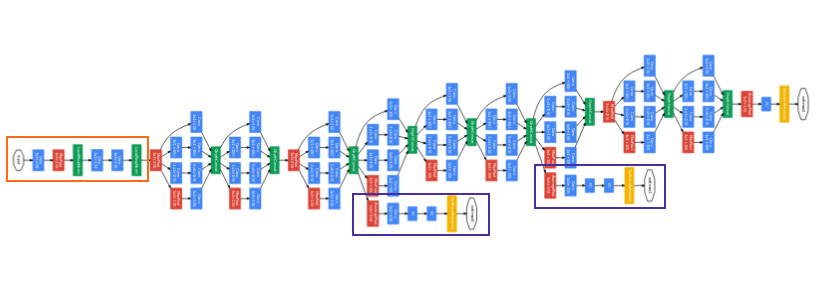
GoogLeNet, Inception Network (2014)
Conv layers: 21(depth), 57(total)
Fully connected layers: 1
weights: 7.0M
MACs: 1.43G
1x1 conv를 통해 연산량 MACs를 줄일 수 있다
-
개요
- 개발: 2014년 구글 (Szegedy et al.)
- 성과: ILSVRC 2014 대회 우승 (VGG-16을 제치고 1위)
- 특징: 22개의 층으로 구성되었으나, 파라미터 수는 VGG의 1/12 수준으로 매우 효율적임
-
핵심 아이디어: 인셉션 모듈 (Inception Module)
"필터 크기를 고민하지 말고 다 써보자"는 아이디어에서 출발했습니다.- 병렬 연산: 1x1, 3x3, 5x5 합성곱과 3x3 풀링을 나란히(병렬로) 수행한 뒤 합침(Concatenation)
- 1x1 Convolution의 활용: 연산량이 많은 3x3, 5x5 필터 앞에 1x1 필터를 두어 채널 수(두께)를 줄임. 이를 통해 연산량을 획기적으로 감소시킴 (Bottleneck 구조)
-
아키텍처 특징
- Global Average Pooling (GAP): 마지막에 파라미터가 많은 완전 연결 층(FC Layer)을 없애고, GAP를 사용하여 파라미터 수를 대폭 줄임
- 보조 분류기 (Auxiliary Classifiers): 네트워크가 깊어 학습이 잘 안 되는 문제(기울기 소실)를 막기 위해, 중간층에 임시로 결과를 출력하는 가지를 2개 추가하여 학습을 도움 (학습 때만 사용하고 테스트 때는 제거)
-
장단점 요약
- 장점: VGG보다 훨씬 깊지만(22층), 연산량과 파라미터(약 400만 개)가 훨씬 적어 효율적임
- 단점: 구조가 복잡하여 구현이 까다롭고, 데이터를 병렬로 처리하는 구조라 메모리 관리가 필요함
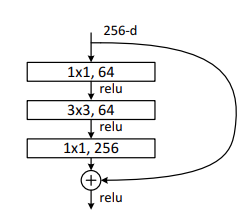
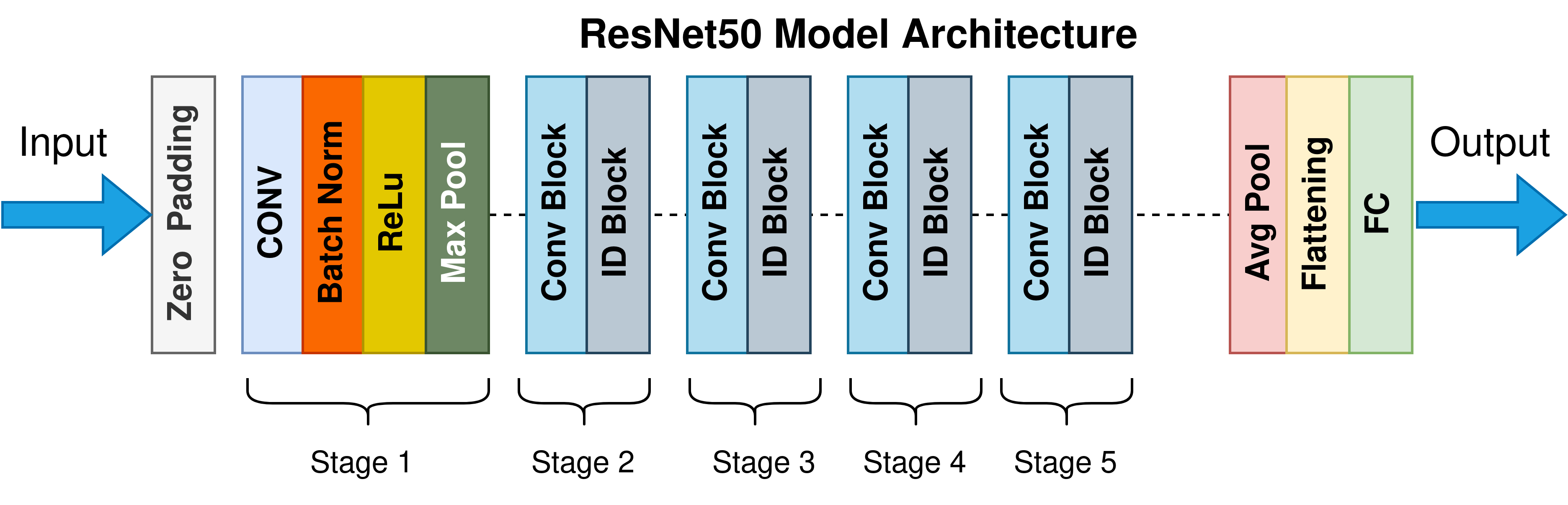
ResNet-50 (2015)
Conv layers: 49
Fully connected layers: 1
weights: 25.5M
MACs: 3.9G
vanishing giadient decent
ResNet-50 (Residual Network)
-
개요
- 개발: 2015년 마이크로소프트 (Kaiming He et al.)
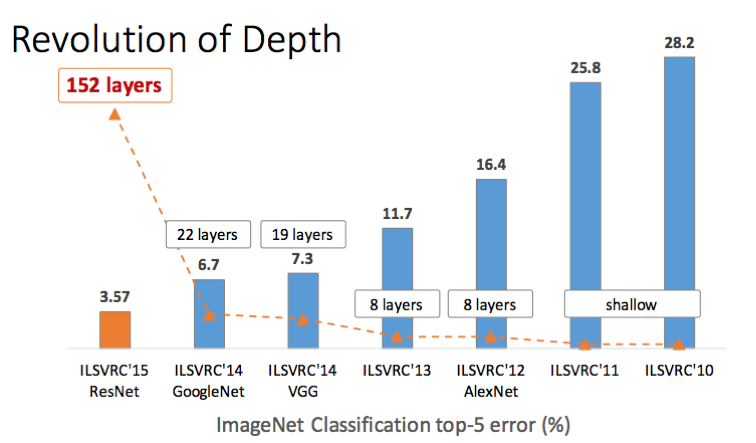
- 성과: ILSVRC 2015 대회 우승 (에러율 3.57%로 사람의 오분류율 5%보다 낮음)
- 의의: 딥러닝 모델이 100층, 1000층 이상 깊어져도 학습이 가능하다는 것을 증명함
-
핵심 아이디어: 스킵 연결 (Skip Connection / Shortcut)
기존에는 층이 깊어질수록 학습 신호(Gradient)가 사라지는 문제가 있었으나, 이를 '지름길'을 만들어 해결했습니다.- 잔차 학습 (Residual Learning): 입력값(x)을 출력값에 더해주는 방식 (H(x) = F(x) + x)
- 효과: 네트워크가 학습할 내용이 없으면 0을 학습해 입력을 그대로 내보내면 되므로, 층이 깊어져도 성능이 나빠지지 않음
- 역전파 용이: 미분했을 때 항상 1 이상의 값이 남아있어, 기울기 소실(Vanishing Gradient) 문제를 근본적으로 해결함
-
아키텍처 특징 (ResNet-50의 병목 구조)
ResNet-50부터는 연산 효율을 위해 3단계 구조의 'Bottleneck Block'을 사용합니다.- 구조: [1x1 Conv] -> [3x3 Conv] -> [1x1 Conv]
- 원리: 앞뒤의 1x1 Conv가 차원을 줄였다가 다시 늘려주어, 가운데 3x3 Conv의 연산 부담을 줄임
- 구성: 이 블록들을 50개 층 깊이까지 반복해서 쌓음
-
장단점 요약
- 장점: 층을 매우 깊게 쌓아도 학습이 잘 되며 성능이 계속 좋아짐. 현재까지도 딥러닝의 표준(Standard) 모델로 불림
- 단점: 층이 매우 깊기 때문에 학습 시간이 오래 걸릴 수 있음
시사점
CNN 발전사(LeNet-5 ~ ResNet-50)가 주는 핵심 시사점
-
"깊이(Depth)"가 성능의 핵심이다
- 흐름: LeNet(5층) -> AlexNet(8층) -> VGG(16/19층) -> GoogLeNet(22층) -> ResNet(50/152층)
- 시사점: 모델이 깊어질수록 더 추상적이고 복잡한 특징(Feature)을 잘 학습합니다.
단, 무작정 깊게 쌓으면 학습이 안 되는 문제(기울기 소실)가 발생하므로 이를 해결하는 것이 관건이었습니다.
-
활성화 함수와 구조적 해결책의 진화 (기울기 소실 해결)
- LeNet: Sigmoid/Tanh 사용 (층이 깊어지면 학습 불가능)
- AlexNet: ReLU 도입 (양수 구간에서 기울기가 죽지 않음 -> 딥러닝의 시작)
- ResNet: Skip Connection 도입 (미분해도 1이 남아있어 하위 층까지 신호 전달 가능)
- 시사점: 깊은 망을 학습시키기 위해서는 단순히 층을 쌓는 것뿐만 아니라, 신호(Gradient)가 잘 흐르도록 하는 '고속도로' 같은 구조적 장치가 필요합니다.
-
필터(Kernel) 크기의 축소와 효율성
- AlexNet: 11x11, 5x5 같은 큰 필터 사용
- VGG-16: 3x3 작은 필터만 여러 번 중첩 (큰 필터와 시야는 같으면서 파라미터는 감소)
- GoogLeNet/ResNet: 1x1 Convolution 적극 활용 (채널 수를 줄여 연산량 감소)
- 시사점: "큰 필터 한 방"보다 "작은 필터 여러 방"이 비선형성을 높이고 효율적입니다. 특히 1x1 Conv는 연산량을 줄이는 병목(Bottleneck) 구조의 핵심이 되었습니다.
-
파라미터 수와 모델 구조의 최적화
- VGG: 단순하지만 파라미터가 너무 많아 비효율적 (Fully Connected Layer 비중이 큼)
- GoogLeNet: GAP(Global Average Pooling)를 도입해 FC Layer를 제거, 파라미터 획기적 감소
- 시사점: 모델의 성능을 유지하면서도 가볍게 만드는 것(Lightweight)이 중요해졌으며, 현대 모델들은 VGG처럼 무식하게 큰 FC Layer를 잘 쓰지 않게 되었습니다.
[한 줄 요약]
CNN의 역사는 "깊이(Depth)를 확보하면서도 연산 효율성(Efficiency)을 잃지 않고, 학습 안정성(Stability)을 잡기 위한 아키텍처 디자인의 진화 과정"입니다.
