AI HW Paper
1.AI HW Basic
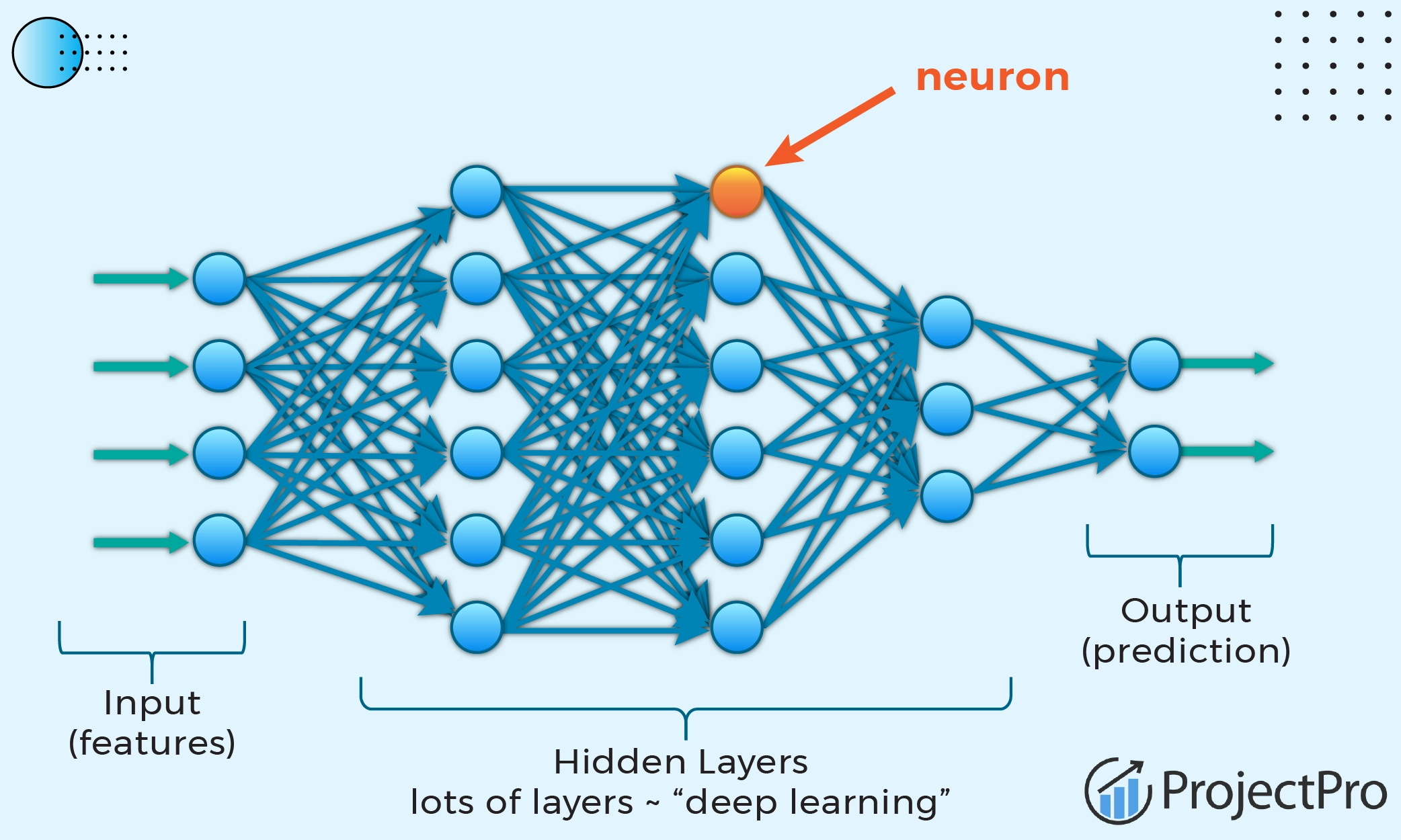
Number of Layer : 5 ~ over 1000• DNN (Deep Neural Networks)• Visualizing CNN• low-level features / higher level features:다수의 신호를 입력으로 받아 하나의 신호를 출력하는
2.AI HW 이미지분류 논문
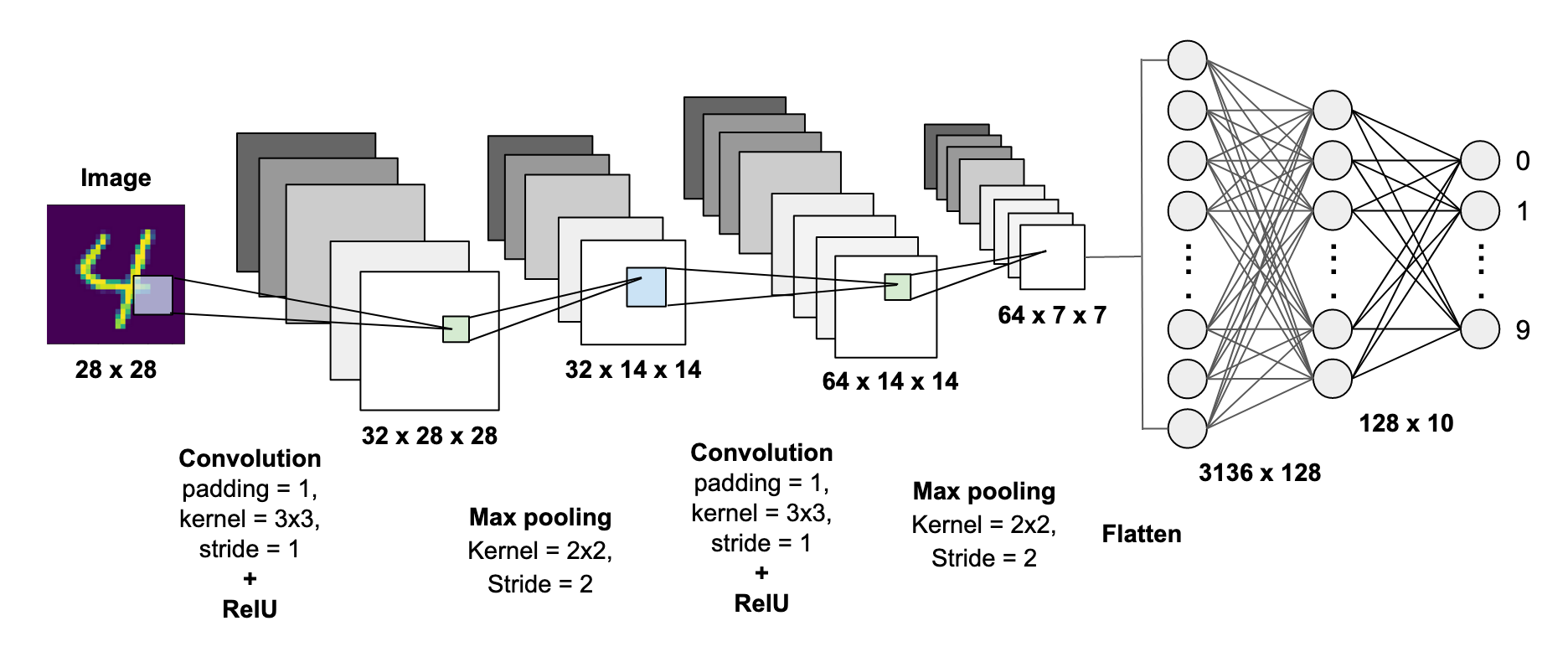
CONV Layer:2fully connected layer: 2weight: 60kMACs: 341kSigmold used for non-linearityCONV Layer:5fully connected layer: 3weight: 61MMACs: 724MReLU u
3.Tensor processing unit (TPU)
Tensor processing unit Top-Level Architecture Fixed Point(INT) / Floating Point(FP) Off-chip Memory big size power consumtion high on-chip big res
4.Verilog Syntax for AI HW

레지스터와 combinational logic의 조합으로 구성된 이 회로를 RTL, Register Transfer level이라고 합니다.define macor_name txt_stringex) define (Macro) vs parameter차이점: define은
5.Model Compression (모델 경량화)
정의: 딥러닝 모델의 파라미터 수와 연산량(FLOPs)을 줄이면서도, 원본 모델의 정확도(Accuracy)를 최대한 유지하는 기술입니다.목적: 모바일 기기나 임베디드 시스템(Edge Device)처럼 메모리와 연산 능력이 제한된 환경에서 모델을 효율적으로 실행하기 위함
6.MobileNet v1
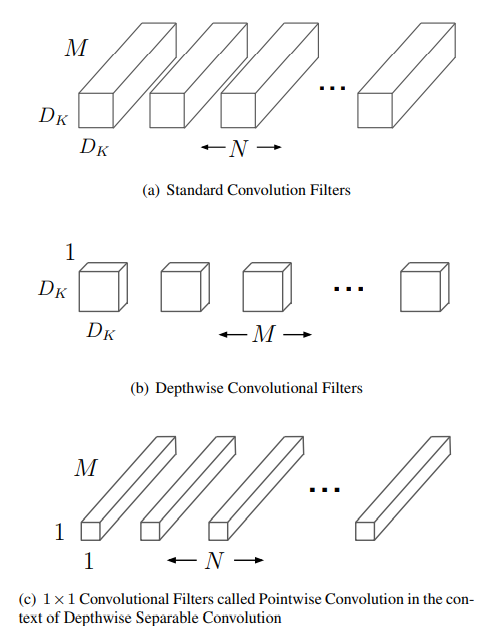
정의: 구글이 2017년에 발표한 모바일 및 임베디드 비전 애플리케이션을 위한 효율적인 모델입니다.목표: 제한된 리소스(CPU, 배터리 등) 환경에서 Latency(지연 시간)를 줄이고 크기를 작게 만드는 것입니다.기존의 표준 Convolution(Standard Co
7.MobileNet V2
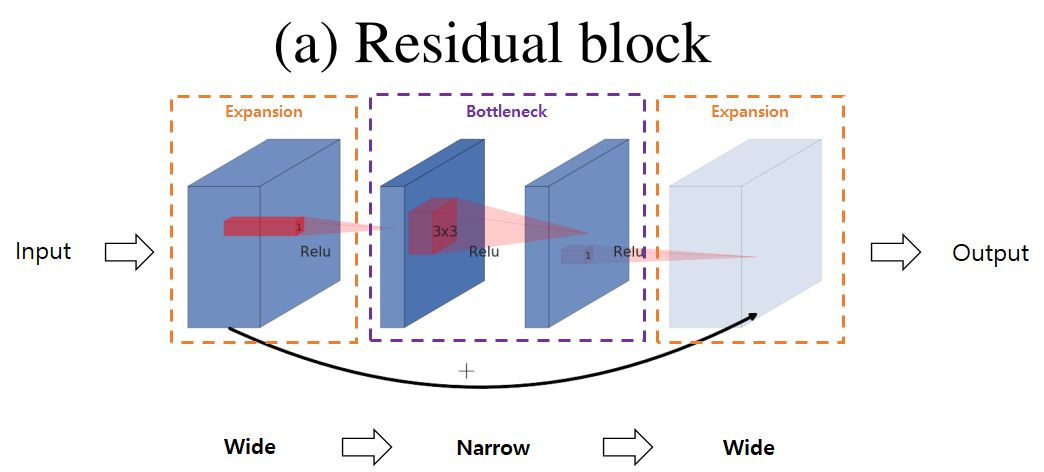
등장 배경: MobileNet V1은 가벼웠지만, 채널을 너무 많이 줄이다 보니 정보가 손실되는 문제가 있었습니다. V2는 이를 해결하기 위해 구조를 뒤집었습니다.기존의 ResNet과는 정반대의 구조를 가집니다.구조: Wide -> Narrow -> Wide (모래시계
8.In-Datacenter Performance Analysis of a Tensor Processing Unit
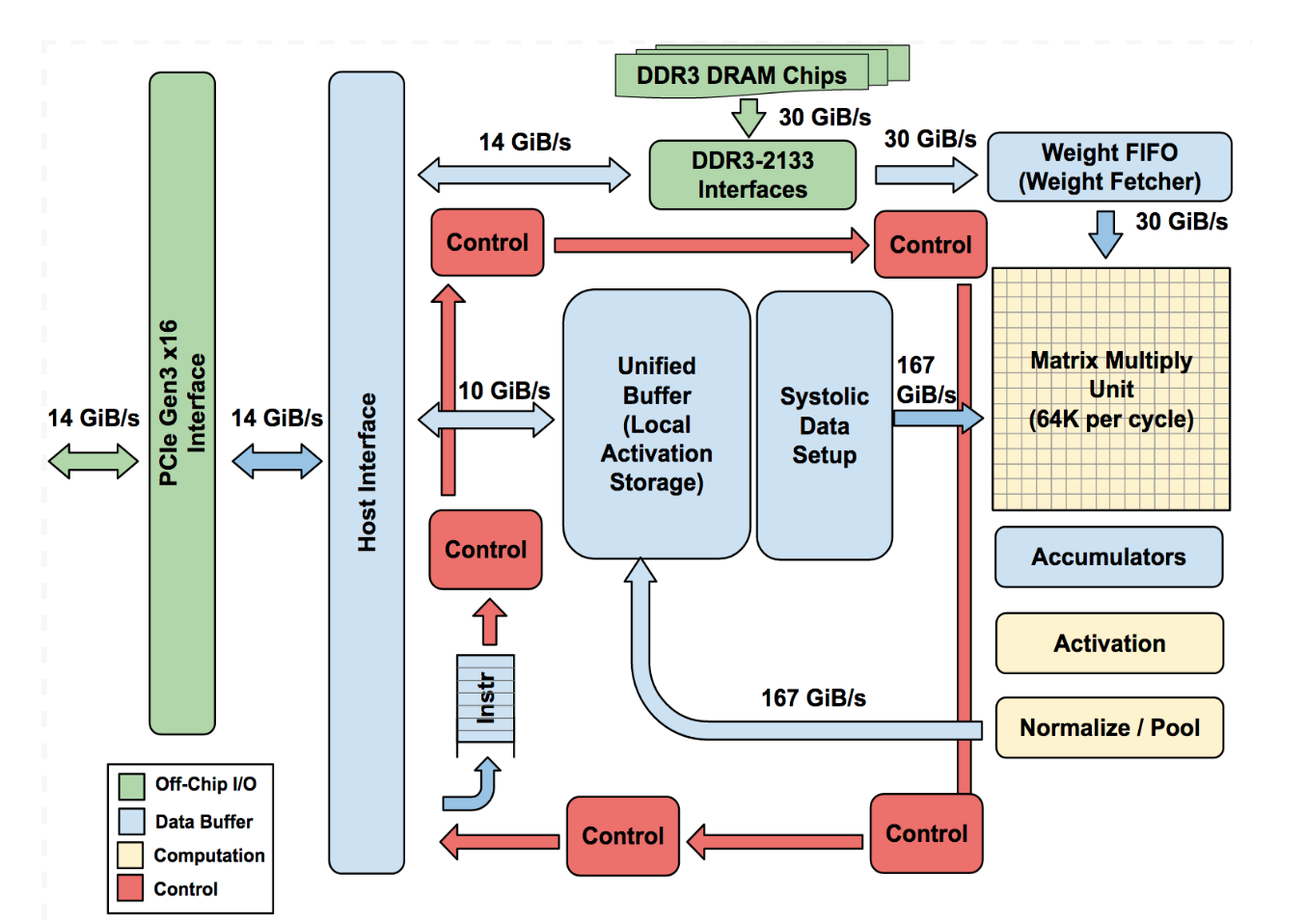
개념: 아주 넓은 의미의 '포괄적인 단어(Umbrella term)'입니다. 입력층(Input layer)과 출력층(Output layer) 사이에 숨겨진 층(Hidden layer)이 여러 개(Deep) 존재하는 모든 신경망을 걍 뭉뚱그려서 DNN이라고 부릅니다.하드
9.ShiDianNao: Shifting Vision Processing Closer to the Sensor
SRAM은 전원이 공급되는 동안에는 데이터가 변하지 않고 그대로 유지되는(Static) 특성을 가진 Volatile memory(휘발성 메모리)입니다.실생활 비유 (Analogy): SRAM은 한 번 스위치를 '딸깍' 켜두면, 누군가 물리적으로 끄지 않는 이상 그 상태
10.Minerva: Enabling Low-Power, Highly-Accurate Deep Neural Network Accelerators
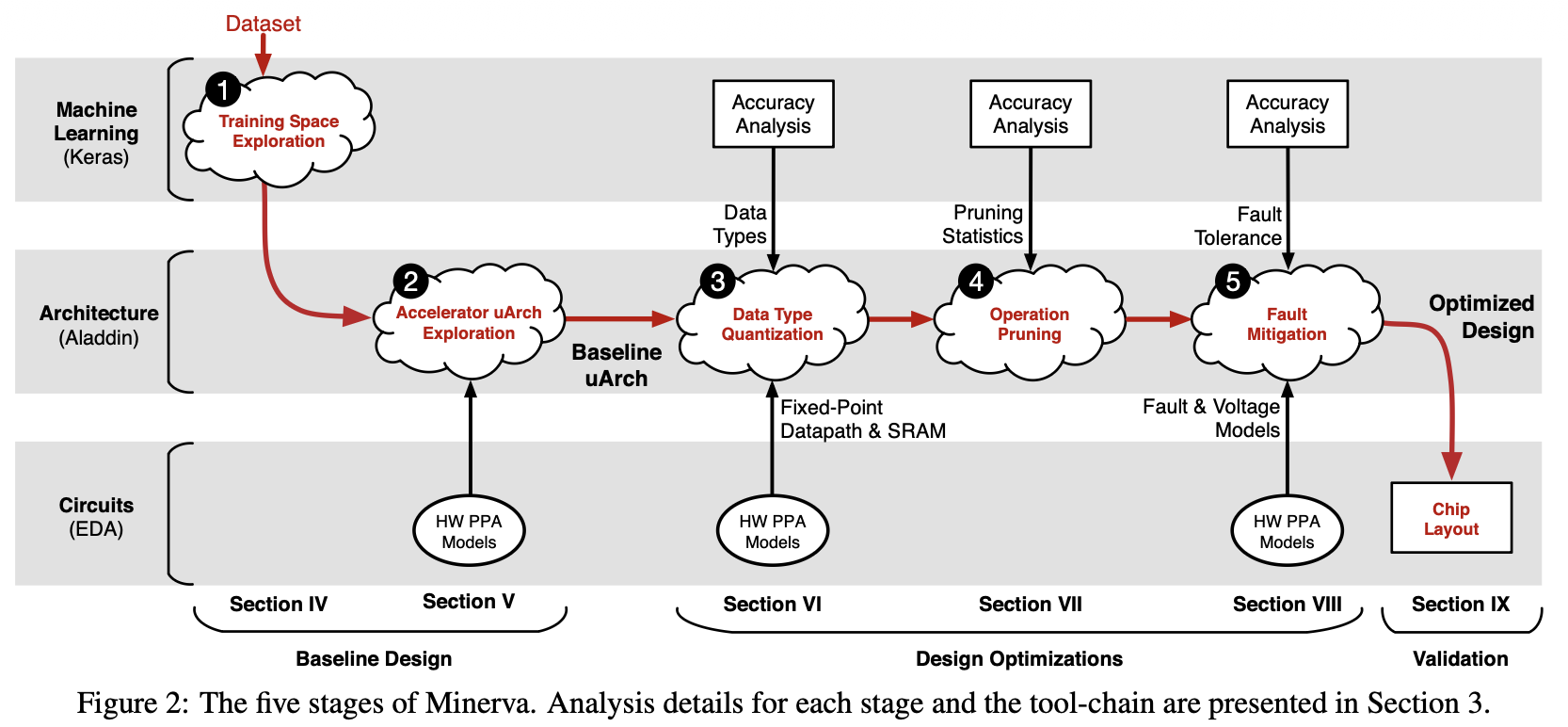
이 논문은 단순히 아키텍처 구조 하나만 바꾸는 것이 아니라, 알고리즘부터 실제 칩의 전압 제어까지 수직적으로 뚫어버린 Cross-layer Co-design의 교과서적인 논문입니다.연구의 배경 및 동기 (The Gap):ML 학계: 전력을 엄청 쓰더라도(GPU 활용)
11.Fused-Layer CNN Accelerators
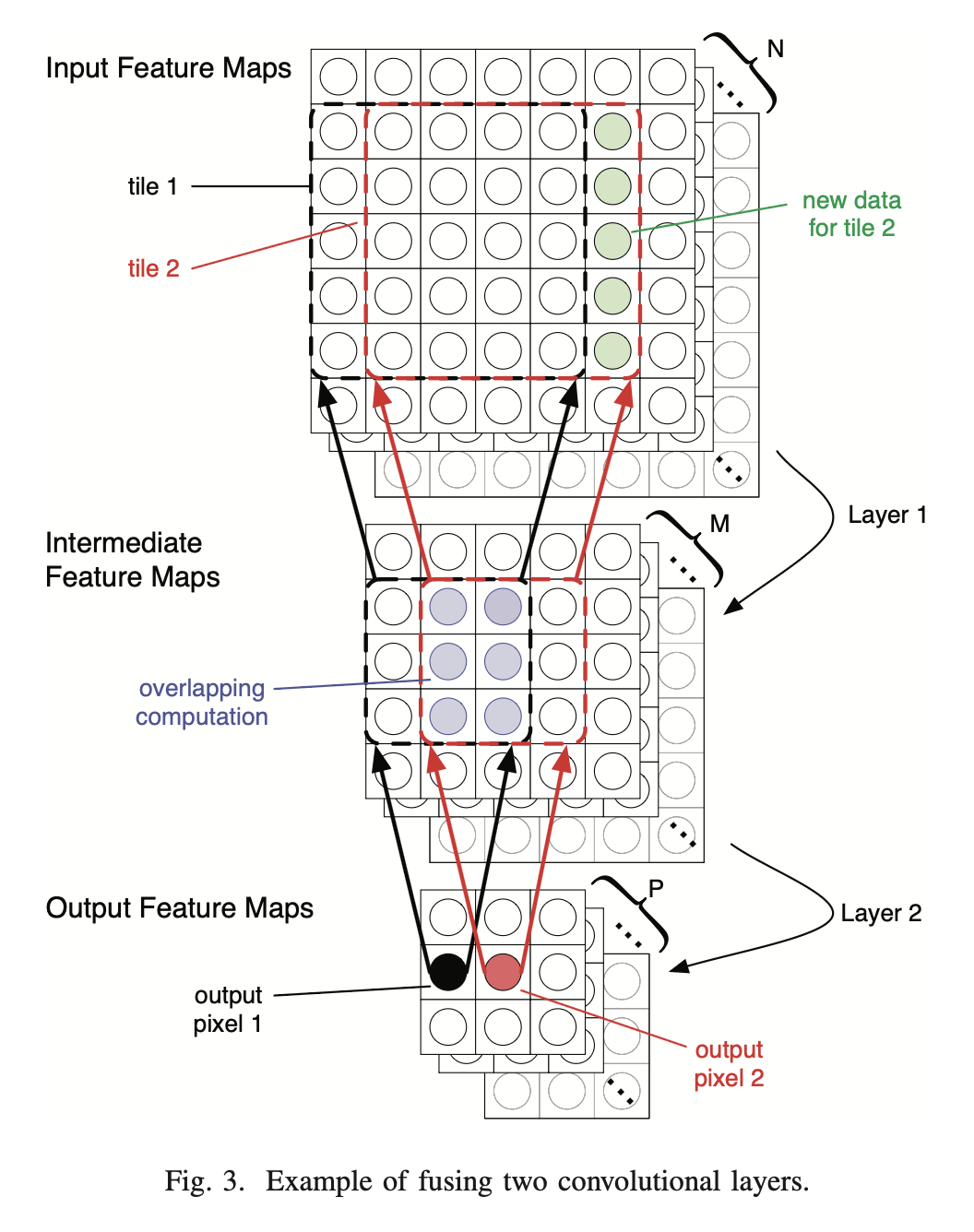
이 논문은 기존 하드웨어 가속기들이 겪고 있던 메모리 대역폭(Memory Bandwidth) 병목 현상을 해결하기 위해 '연산 순서' 자체를 뒤집어버린 선구적인 논문입니다.기존 가속기들이 "어떻게 하면 SRAM과 DRAM 사이를 효율적으로 왔다 갔다 할까?"를 고민했다
12.논문 4개 요약
TPU (In-Datacenter Performance Analysis...): 클라우드 데이터센터 환경에서 Systolic Array 구조와 거대한 Software-Managed On-Chip Memory를 사용하여 CPU/GPU 대비 압도적인 추론 속도(Infere
13.Samsung HBM2-PIM
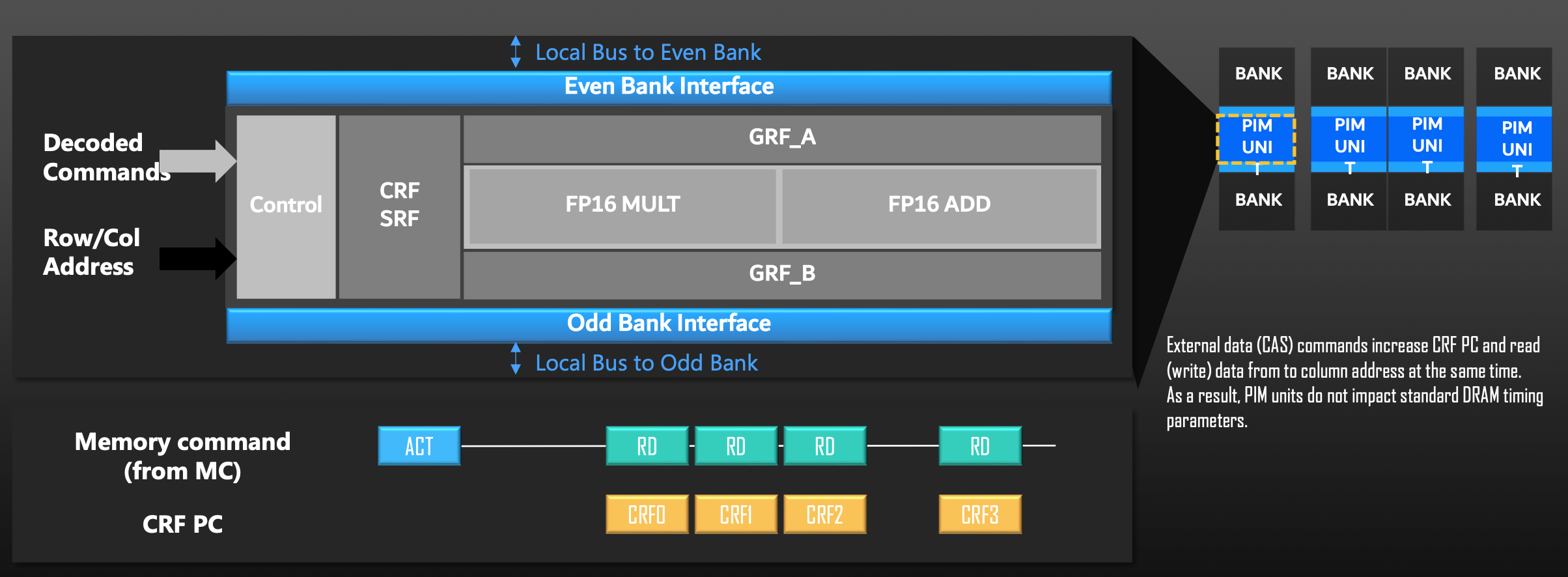
Aquabolt-XL: Samsung HBM2-PIM with in-memory processing for ML accelerators and beyondCPU 핀 수나 PCB 배선을 늘려 메모리 대역폭을 물리적으로 확장하는 방식은 이미 물리적 한계에 도달했습니다. A
14.GDDR6 AiM (SK Hynix)
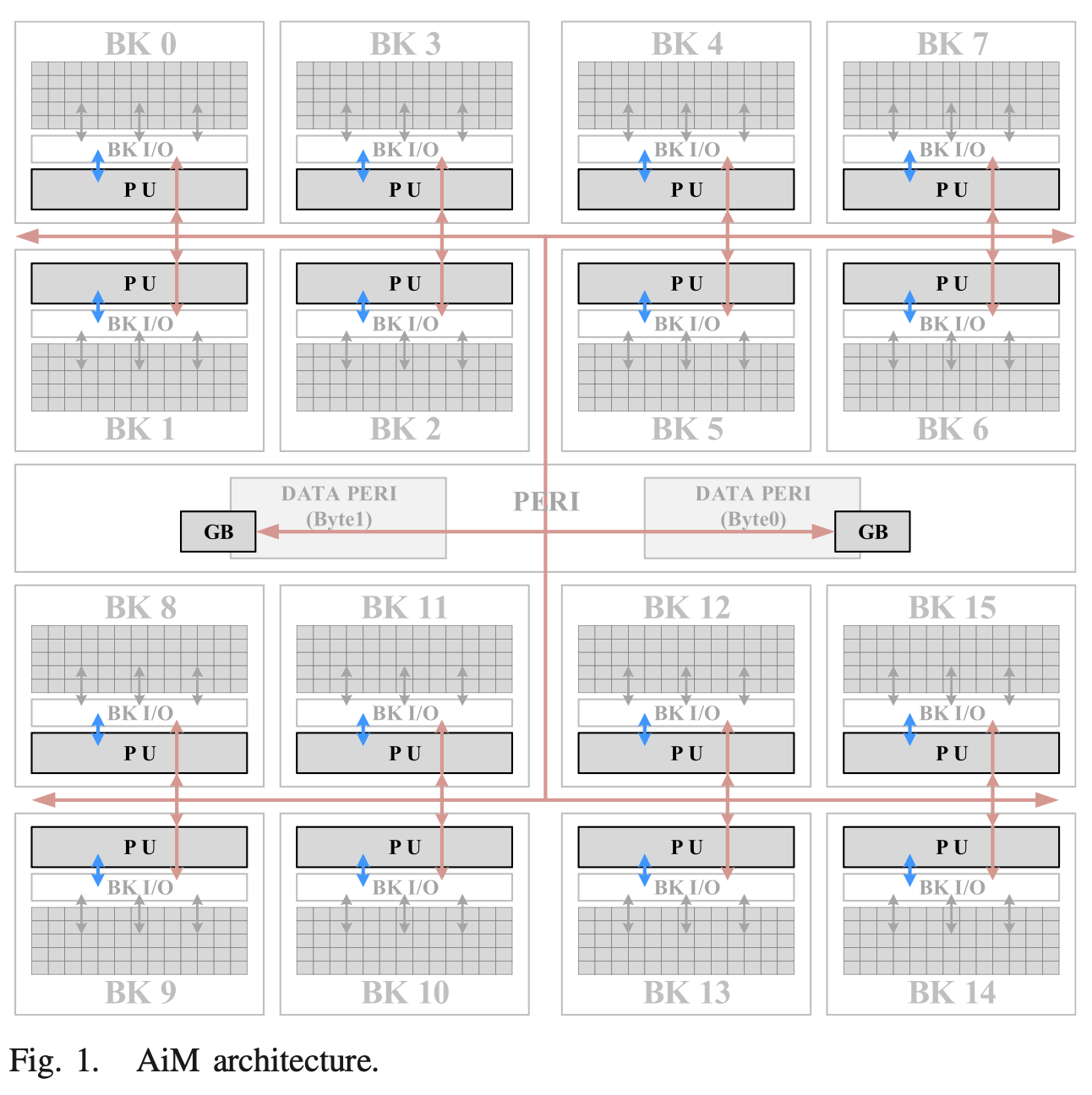
삼성 논문이 "최고 성능의 HBM에 PIM을 결합하자"는 하이엔드 전략이었다면, 이 하이닉스 논문의 핵심은 "HBM은 TSV(실리콘 관통 전극) 공정 때문에 단가가 너무 비싸니, 그래픽 카드에 널리 쓰이는 가성비 좋은 GDDR6에 PIM을 이식해서 대중적인 AI 가속기