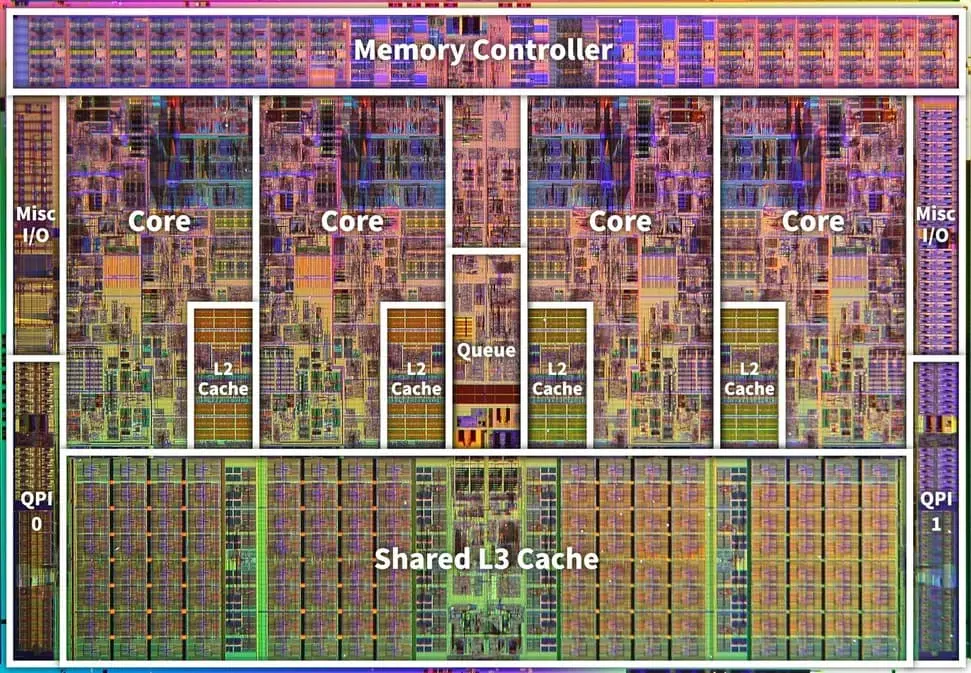

L1 Cache: 프로세서와 가장 가까운 캐시. 속도를 위해 I$ 와 D$로 나뉜다.
- Instruction Cache (I$): 메모리의 TEXT 영역 데이터를 다루는 캐시.
- Data Cache (D$): TEXT 영역을 제외한 모든 데이터를 다루는 캐시.
L2 Cache: 용량이 큰 캐시. 크기를 위해 L1 캐시처럼 나누지 않는다.
L3 Cache: 멀티 코어 시스템에서 여러 코어가 공유하는 캐시.
Cache Metrics
캐시의 성능을 측정할 때는 히트 레이턴시(Hit latency)와 미스 레이턴시(Miss latency)가 중요한 요인으로 꼽힌다.
- Cache Hit: CPU에서 요청한 데이터가 캐시에 존재하는 경우
- Hit latency: 히트가 발생해 캐싱된 데이터를 가져올 때 소요되는 시간
- Cache Miss: 요청한 데이터가 캐시에 존재하지 않는 경우
- Miss latency: 미스가 발생해 상위 캐시에서 데이터를 가져오거나(L1 캐시에 데이터가 없어서 L2 캐시에서 데이터를 찾는 경우) 메모리에서 데이터를 가져올 때 소요되는 시간을 말한다.
캐시의 성능을 높이기 위해서는 캐시의 크기를 줄여 히트 레이턴시를 줄이거나, 캐시의 크기를 늘려 미스 비율을 줄이거나, 더 빠른 캐시를 이용해 레이턴시를 줄이는 방법이 있다.
Cache Organization
캐시는 반응 속도가 빠른 SRAM(Static Random Access Memory)으로, 주소가 키(Key)로 주어지면 해당 공간에 즉시 접근할 수 있다. 이러한 특성은 DRAM(Dynamic Random Access Meomry)에서도 동일하지만 하드웨어 설계상 DRAM은 SRAM보다 느리다. 통상적으로 '메인 메모리’라고 말할 때는 DRAM을 의미한다.
주소가 키로 주어졌을 때 그 공간에 즉시 접근할 수 있다는 것은 캐시가 하드웨어로 구현한 해시 테이블(Hash table)과 같다는 의미다. 캐시가 빠른 이유는 자주 사용하는 데이터만을 담아두기 때문이기도 하지만, 해시 테이블의 시간 복잡도가 정도로 빠르기 때문이기도 하다.
캐시는 블록(Block)으로 구성되어 있다. 각각의 블록은 데이터를 담고 있으며, 주소값을 키로써 접근할 수 있다. 블록의 개수(Blocks)와 블록의 크기(Block size)가 캐시의 크기를 결정한다.
https://parksb.github.io/article/29.html
캐시 계층(Hierarchy)과 동작의 핵심
기본 개념: CPU는 속도가 매우 빠르기 때문에, 느린 DRAM(메인 메모리)에 직접 접근하지 않고 중간에 있는 L1 캐시를 통해 데이터를 주고받는다.
Hit (Match): CPU가 요청한 주소의 데이터가 캐시에 있을 때.
- 동작: DRAM을 거치지 않고 캐시에서 즉시 CPU로 전달 (최고 속도).
Miss (Mismatch): CPU가 요청한 주소의 데이터가 캐시에 없을 때.
- 동작: 캐시가 DRAM으로부터 필요한 데이터를 새로 가져와야 함 (Allocate 과정).
캐시 Miss 발생 시 처리 과정
Step 1 (Miss 판별): CPU가 요청한 주소가 캐시에 없음을 확인.
Step 2 (Eviction - 방 빼기): DRAM에서 새 데이터를 가져와야 하는데 캐시가 꽉 찼다면, 기존 데이터를 DRAM으로 쫓아냄.
- 주의: 쫓겨나는 데이터가 'Dirty(수정됨)' 상태라면, 반드시 DRAM에 먼저 기록(Write-Back)해야 데이터가 유실되지 않음.
Step 3 (Fill - 새로 채우기): DRAM에서 새로 필요한 데이터를 읽어와 캐시에 저장.
Step 4 (Respond - 응답): CPU에게 데이터를 전달.
검증 엔지니어의 핵심 검증 포인트
Hit/Miss 판별 로직: 주소와 태그(Tag) 비교가 정확한가? (X-State 등 무효값 처리)
데이터 무결성: DRAM에서 데이터를 가져오거나(Fill) 쫓겨날 때(Evict), 데이터의 값이 변형되지 않는가?
충돌 방지 (Bypass): 캐시에 데이터를 쓰고 있는(Write) 도중에 CPU가 읽으려 할 때(Read), 엉뚱한 데이터를 읽지 않도록 설계되었는가?
