2-Stage 파이프라인, Direct-Mapped, Write-Back, Write-Allocate" 방식을 사용하는 캐시 컨트롤러
Background Knowledge
L1 Cache
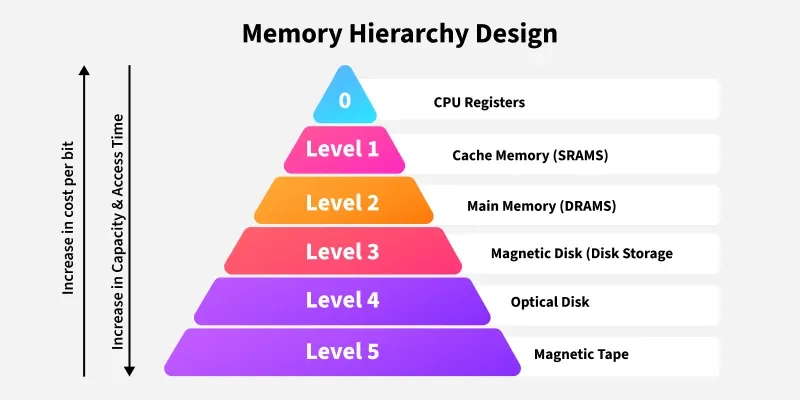
L1 Cache (Level 1 Cache, 1차 캐시)는 간단히 말해 CPU와 메인 메모리(RAM) 사이에 존재하는 '가장 빠르고, 가장 작으며, CPU와 가장 가까운 임시 저장소
l1_cache_core.sv가 CPU의 비서 역할
- 학생이 "A번 책 줘!"라고 요청했을 때, 책상 위에 그 책이 있으면 바로 줍니다. (Cache Hit)
- 책상에 없으면 학생에게 "잠시만요!(Stall)"라고 외치고, 도서관(RAM)으로 달려가서 책을 가져와 책상에 올려두고 학생에게 건네줍니다. (Cache Miss & Allocate)
- 책상이 꽉 찼는데 새 책을 가져와야 하면, 책상 위에서 더러워진(낙서한) 책을 찾아 도서관에 정식으로 반납하고 옵니다. (Write-Back)
2-stage pipeline
개념: 하나의 캐시 요청을 처리하는 과정을 두 단계로 쪼개어 공장 컨베이어 벨트처럼 돌리는 것입니다.
- Stage 1: 주소 쪼개기 + SRAM 읽기 시작
- Stage 2: 진짜 내 데이터가 맞는지(Hit/Miss) 검사 + CPU에 응답
결론부터 말씀드리면, '파이프라인(Pipeline)'이라는 공장 시스템(컨베이어 벨트)을 도입했다는 개념만 같을 뿐, 일하는 공장 자체가 다릅니다.
학교에서 배운 5-Stage Pipeline (CPU Core):
이건 "명령어(Instruction)를 처리하는 중앙 처리 장치(CPU) 본체"의 컨베이어 벨트입니다.
"메모리에서 명령어를 가져와서(F), 무슨 뜻인지 해독하고(D), 더하기/빼기 연산을 하고(E), 메모리에 접근하고(M), 결과를 저장하는(W)" 5단계를 거칩니다.
지금 우리가 짜는 2-Stage Pipeline (L1 Cache Controller):
이건 CPU 코어 외부에 붙어있는 "데이터 창고(비서)의 컨베이어 벨트"입니다.
위의 CPU 5단계 중 'Memory(M) 단계'에서 CPU가 "야 캐시야, 나 A 주소 데이터 좀 줘!" 라고 요청을 던지면, 그때부터 이 캐시 컨트롤러 내부의 2단계 컨베이어 벨트가 독자적으로 돌아가는 것입니다.
Direct-Mapped
개념: 주소의 특정 부분(Index)을 보고, 캐시 메모리의 '정해진 딱 한 자리'에만 데이터를 저장하는 무식하지만 빠른 방식입니다. 도서관(RAM)의 책을 가져와 책상(Cache)에 놓을 때, 1번부터 256번까지 지정석을 만들어 두고 무조건 그 자리에만 놓는 것과 같습니다.
왜 검증이 어려울까? 서로 다른 데이터인데 우연히 '지정석 번호(Index)'가 똑같을 수 있습니다. 이를 충돌 미스(Conflict Miss)라고 합니다. A 데이터와 B 데이터가 같은 자리를 놓고 계속 서로를 쫓아내는 핑퐁 게임(Thrashing)이 일어날 때 로직이 꼬이지 않는지 확인해야 합니다.
Write-Back (지연 쓰기)
개념: CPU가 데이터를 썼을 때, 곧바로 저 멀리 있는 메인 메모리(RAM)까지 달려가서 업데이트하지 않고, 일단 가까운 캐시에만 쓴 뒤 "이 데이터는 수정됐음!(Dirty=1)" 이라고 표시만 해두는 방식입니다.
왜 검증이 어려울까? 나중에 새로운 데이터를 캐시에 올리기 위해 방 빼야 할 때(Eviction), 이 녀석이 수정된 적이 있는지(Dirty == 1) 확인하고 메인 메모리로 쫓아내는(Write-Back) 엑스트라 로직이 들어갑니다. 제가 코드에 심어놓은 버그 중 하나가 바로 이 Write-Back 과정에서 메인 메모리 주소를 잘못 계산하는 버그입니다!
CPU 의 write-back 과 Cache의 write-back 차이
이름만 똑같을 뿐, 타겟(목적지)이 완전히 다른 개념입니다.
CPU 파이프라인의 5번째 단계: "Write-back (WB)"
- 무엇을? ALU 연산 결과(예: 1+1=2)나 메모리에서 읽어온 데이터를
- 어디에? CPU 내부에 있는 아주 작은 '레지스터 파일(Register File, 예: R1, R2)'에
- 언제? 명령어가 끝나는 즉시 써넣는 단계입니다.
Cache 컨트롤러의 정책: "Write-back (지연 쓰기 정책)"
- 무엇을? CPU가 새로 저장하라고 준 데이터를
- 어디에? 저 멀리 있는 '메인 메모리(DRAM)'에
- 언제? 당장 쓰지 않고 캐시에만 임시로 써뒀다가(Dirty=1), 나중에 캐시 자리가 꽉 차서 데이터를 쫓아내야 할 때(Eviction) 비로소 메모리에 업데이트하는 '정책'입니다.
참고: 반대말은 Write-through(CPU가 쓸 때마다 매번 메인 메모리까지 달려가서 동시에 쓰는 무식한 방식)입니다.
Write-Allocate (쓰기 할당)
개념: CPU가 특정 주소에 데이터를 쓰려고 했는데, 캐시에 그 주소가 없는 경우(Write Miss)입니다. 이때 "어차피 쓰는 거니까 캐시 무시하고 메모리에 바로 쓰자(No-Write-Allocate)"가 아니라, "일단 메모리에서 캐시로 한 줄(16 Byte)을 통째로 퍼온 다음(Allocate), 그 위에 CPU가 준 데이터를 덮어쓰자!"는 방식입니다.
왜 검증이 어려울까? 쓰기 작업인데도 불구하고 마치 읽기 작업처럼 메인 메모리에서 데이터를 퍼오는 과정(Read from RAM)이 선행되어야 하므로 FSM 상태 머신이 굉장히 복잡하게 빙글빙글 돕니다.
Stage
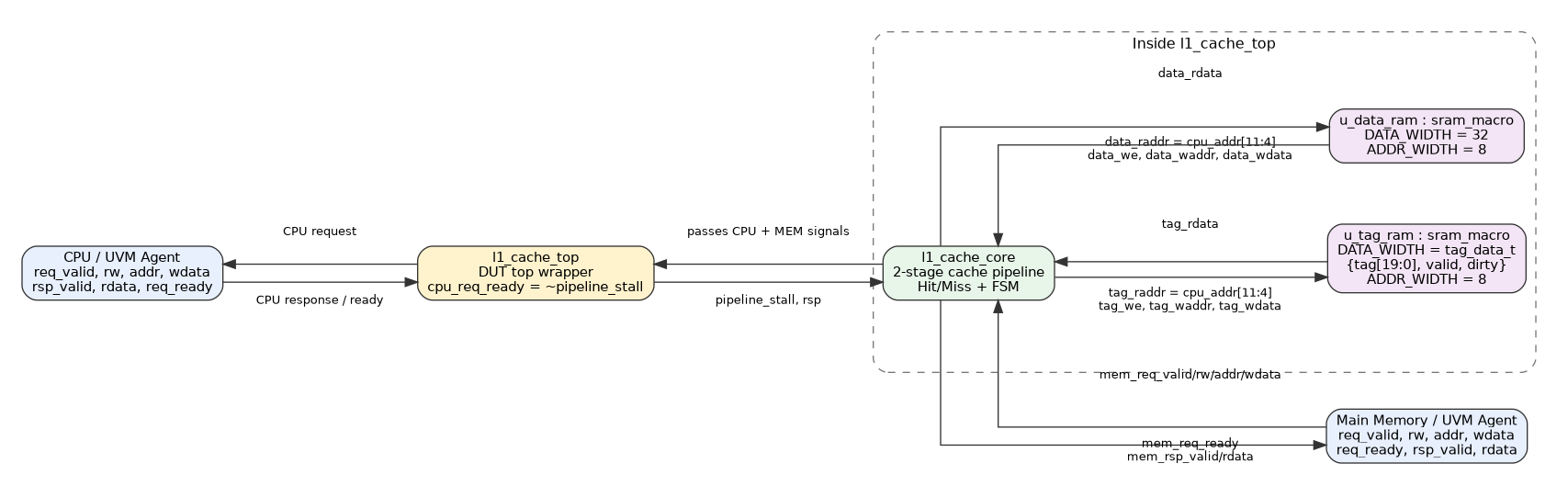
1. Stage 1: 요청 수신 및 해독 (Request & Decode)
CPU가 데이터를 달라고 주소(cpu_req_addr)를 던지면 가장 먼저 일어나는 일입니다.
-
주소 쪼개기 (Decoding): 32비트 주소를 잘라서 캐시 라인을 찾을 Index(8비트)와, 진짜 내 데이터가 맞는지 확인할 Tag(20비트)로 나눕니다.
-
SRAM 읽기 준비: 잘라낸 Index를 이용해 파운드리에서 가져온 Tag SRAM과 Data SRAM에 읽기 주소(raddr)를 꽂아 넣습니다.
-
파이프라인 레지스터 저장: CPU가 보낸 요청 정보(Valid, Read/Write, 주소, 데이터)를 플립플롭에 저장하여 다음 클럭(Stage 2)으로 넘길 준비를 합니다.
2. Stage 2: 태그 확인 및 적중 판별 (Tag Check & Data Access)
Stage 1에서 보낸 정보가 다음 클럭에 여기로 넘어옵니다. (동시에 SRAM에서도 데이터가 튀어나옵니다.)
Cache Hit (캐시 적중): SRAM에서 튀어나온 Tag와 CPU가 요청한 Tag가 똑같고, 데이터가 유효하다(Valid == 1)면 Hit입니다!
Read Hit: 읽어온 데이터를 CPU에게 바로 던져줍니다 (cpu_rsp_valid = 1).
Write Hit: CPU가 쓰라고 준 데이터를 SRAM에 쓰고, "이 데이터는 수정됐어!"라는 표시로 Dirty Bit를 1로 만듭니다.
3. 캐시 미스 해결사: FSM (상태 머신)
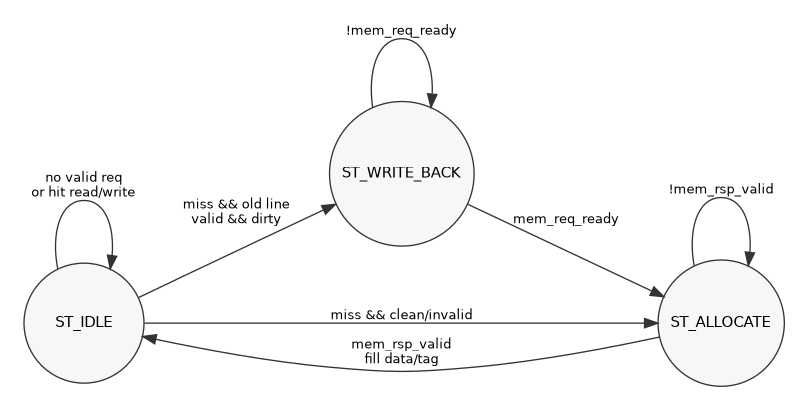
만약 Stage 2에서 Tag가 다르거나 Valid가 0이면 Cache Miss가 발생합니다. 이때 캐시는 하던 일을 멈추고(pipeline_stall = 1), 아래 3단계 상태 머신(FSM)을 가동합니다.
[ST_IDLE] 평시 상태: 평소엔 여기서 대기하다가 미스가 나면 다음 상태로 넘어갑니다.
[ST_WRITE_BACK] 대피 상태 (조건부): 만약 기존 자리에 있던 데이터가 수정된 적이 있다면(Dirty == 1), 덮어씌워지기 전에 메인 메모리로 안전하게 쫓아냅니다. (이곳에 제가 치명적인 주소 버그를 숨겨두었습니다!)
[ST_ALLOCATE] 할당 상태: 메인 메모리에 "진짜 데이터 내놔!"라고 요청(mem_req_rw = 0)합니다. 메모리에서 데이터가 도착하면 SRAM에 채워 넣고 다시 ST_IDLE로 돌아갑니다.
