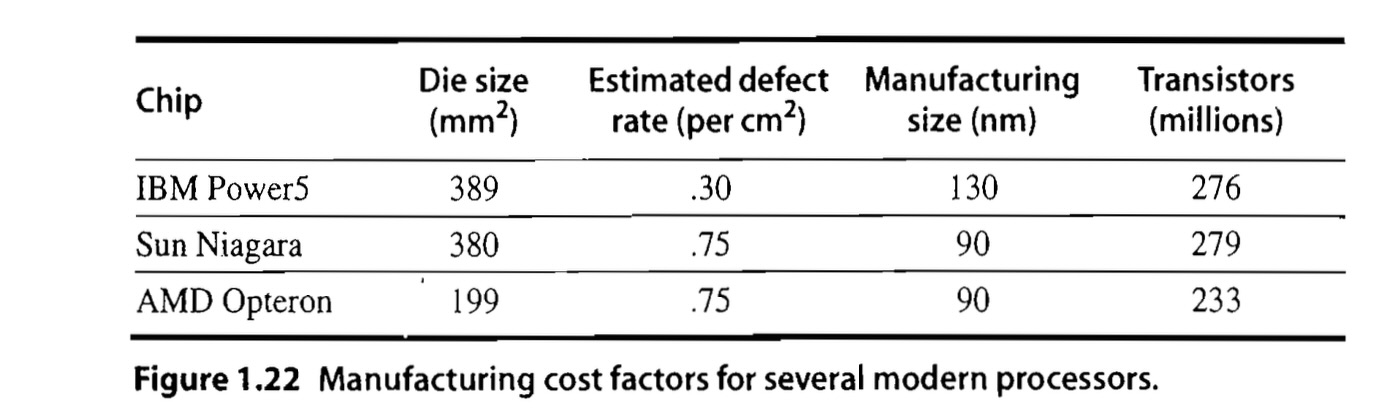
Good Dies: 416×0.653≈270개
Profit per Wafer: 270×$20=$5,408
b) Marcon chip
(250 mm2=2.5 cm2)
DPW: 2.5π×152−2×2.5π×30≈282.7−42.1=240
Yield (수율):(1+4.00.30×2.5)−4=(1.1875)−4≈0.5%
Good Dies: 240×0.5≈120개Profit per Wafer: 120×$25=$3,000
c)
Woods Chip을 생산하는 게 이득
d)
Woods chips: 50,000/416 = 120.2 wafers needed
Markon chips: 25,000/240 = 104.2 wafers needed
Therefore, the most lucrative split is 120 Woods wafers, 30 Markon wafers.
1.7
a)
듀얼 코어를 쓰는데, 싱글 코어와 성능(시간)을 똑같이 맞추려면 주파수(속도)를 얼마나 낮춰도 되는가?"
b)
(a)에서 구한 그 상태(속도 0.6)로 돌린다면, 전력(Power)은 싱글 코어 때보다 얼마나 줄어들까?"
"Voltage may be decreased linearly with frequency" (전압은 주파수에 비례해서 줄어든다)라고 되어 있습니다.즉, 주파수가 0.6배가 되었으니, 전압(V)도 똑같이 0.6배가 됩니다
전압 하한선(Voltage Floor)에 딱 맞춰서 성능을 유지하려면, 병렬화 비율(x)은 몇 %여야 하는가?"
싱글 코어와 동일한 성능(1)을 내야 합니다. 1=듀얼코어실행시간비율주파수비율 1=(1−x)+2x0.75
(해석: 주파수를 0.75로 낮췄을 때, 작업 시간도 그에 맞춰 줄어들어야 쌤쌤이 된다) x=0.5
정답: 50%
(설명: 병렬화가 50%밖에 안 되는 프로그램이라면, 주파수를 0.6(60%)까지 낮출 필요 없이 0.75(75%)까지만 낮춰도 싱글 코어랑 똑같은 성능이 나온다는 뜻입니다.)
d)
원래 프로그램(병렬화 80%)을 돌릴 건데, 전압 하한선(Voltage Floor)이 걸려 있다. 이때 전력은 얼마나 드는가?"
(a)번 문제에서 구했듯이, 병렬화 80%인 프로그램을 싱글 코어 성능과 똑같이 맞추려면 주파수는 0.6 (60%)만 있으면 됩니다.그래서 F=0.6을 씁니다.
원래대로라면 주파수가 0.6이니까 전압도 0.6으로 낮추고 싶습니다.
(V∝F)하지만! 하드웨어 제약(Voltage Floor) 때문에 전압은 0.75 밑으로 내릴 수가 없습니다.
울며 겨자 먹기로 주파수는 0.6으로 돌리지만, 전압은 0.75를 공급해야 합니다.
그래서 V=0.75가 됩니다.
[기본 전제 조건 (Baseline)]
전체 서버의 개수를 N이라고 합시다.
서버 1대가 낼 수 있는 최대 전력을 Pmax라고 합시다.
현재 전력 소모: 문제에서 "60% 용량으로 일할 때, 최대 전력의 90%를 소모한다"고 했습니다.
총 기존 전력 (Old Power) = N×0.9Pmax=0.9NPmax
a)
60%의 서버를 아예 꺼버렸을 때 (Turned off) 전력 절감률은?
꺼진 서버: 전체의 60% (0.6N). 얘네는 전원 코드가 뽑혔으니 전력 소모가 0입니다.
켜져 있는 서버: 전체의 40% (0.4N).
켜져 있는 서버들의 상태: 전원이 켜져 있는 이 40대의 서버들은 여전히 원래 하던 대로 60%의 작업량(Capacity)으로 돌아가고 있습니다.따라서 켜져 있는 서버 1대당 먹는 전력은 아까와 똑같이 0.9Pmax 입니다.
켜져 있는 40% 서버의 전력 = 0.4N×0.9Pmax=0.36NPmax
새로운 총 전력 (New Power) = 0.36NPmax Savings=기존전력기존전력−새로운전력Savings=0.9NPmax0.9NPmax−0.36NPmax=0.90.54=60%
컴퓨터 구조에서는 성능을 평가할 때 항상 "원래 상태(Baseline) 대비 얼마나 좋아졌는가?"를 따지기 때문에, 비교 공식의 분모에는 무조건 '기존 값(Old)'이 들어간다고 외워두시면 편합니다.
일상생활의 세일(Sale) 퍼센트 계산과 똑같다
Savings (절감률)=원래가격순수하게깎은금액=기존전력기존전력−새로운전력
b)
60%의 서버를 "거의 꺼진 상태(barely alive)"로 두었을 때 전력 절감률은?
아예 끄는 대신 빠르게 재시작할 수 있는 대기 상태(최대 전력의 20% 소모)로 두는 상황입니다.
대기 상태인 60% 서버의 전력 = 0.6N×0.2Pmax=0.12NPmax
켜져 있는 40% 서버의 전력 = 0.4N×0.9Pmax=0.36NPmax
새로운 총 전력 (New Power) = 0.12NPmax+0.36NPmax=0.48NPmax
전압(Voltage)을 20% 줄이고 주파수(Frequency)를 40% 줄였을 때 전력 절감률은? Power∝Voltage2×Frequency
원래 상태(1.0)에서 전압을 20% 낮추고, 주파수를 40% 낮췄으므로:
새로운 전압 (Vnew) = 1.0−0.20=0.8
새로운 주파수 (Fnew) = 1.0−0.40=0.6
NewPower=(0.8)2×0.6×Old Power NewPower=0.64×0.6×Old Power=0.384×Old Power
새로운 전력이 기존 전력의 38.4% 수준으로 떨어졌습니다.
[절감률 계산] Savings=1.0−0.384=0.616→61.6%
d)
30%는 "대기 상태", 30%는 "꺼짐", 나머지는 켜두었을 때 전력 절감률은?
서버를 세 그룹으로 쪼개서 계산합니다. (나머지 켜진 서버는 100% - 30% - 30% = 40%입니다.)
대기 상태(barely alive) 30%의 전력 = 0.3N×0.2Pmax=0.06NPmax
꺼진(off) 30%의 전력 = 0
켜져 있는 40%의 전력 = 0.4N×0.9Pmax=0.36NPmax
새로운 총 전력 (New Power) = 0.06NPmax+0+0.36NPmax=0.42NPmax
Step 1: 전체 시스템의 하루 고장률(λ) 구하기컴퓨터 1대가 고장 나는 데 평균 35일이 걸립니다. 즉, 1대의 하루 고장률은 1/35 입니다.
컴퓨터가 10,000대 있으므로, 서버 팜 전체에서 하루에 발생하는 고장 건수는: 시스템하루고장률=10,000×351≈285.7대/일
시스템이 붕괴하려면 총 10,000대의 1/3인 3,333대가 고장 나야 합니다.
하루에 285.7대씩 고장 나니까, 3,333대가 고장 나는 데 걸리는 시간은 단순히 나누면 됩니다.
MTTFsys=285.7대/일3,333대≈11.66일
1.16
a.
페널티를 무시했을 때의 순수 Speedup은?
새로운 FP(부동소수점) 유닛이 FP 연산만 2배 빠르게 해주는 아주 이상적인 상황입니다.
조건:
FP 연산 비중 (fFP) = 20% (0.2)
FP 속도 향상 (nFP) = 2배 (2)
영향을 받지 않는 나머지 부분 = 80% (0.8)
공식 (기본 암달의 법칙): Speedup=(1−fFP)+nFPfFP1
계산: Speedup=0.8+20.21=0.8+0.11=0.91
Speedup≈1.11
b.
캐시 속도 저하(Penalty)를 포함한 실제 Speedup은?
이제 진짜 트레이드오프를 계산할 차례입니다. 전체 실행 시간(1.0)을 세 조각으로 완벽히 나누어야 합니다.
1. FP 연산 부분 (20%): 2배 빨라짐.
2. Data Cache 부분 (10%): 1.5배 느려짐 (실행 시간이 1.5배로 늘어남).
3. 나머지 부분 (70%): 아무 영향 안 받음. (100%−20%−10%=70%)
[새로운 실행 시간(New Execution Time) 계산]
나머지 부분: 0.7 (그대로)
FP 부분: 0.2÷2=0.1 (시간이 절반으로 단축됨)
Cache 부분: 0.1×1.5=0.15 (시간이 1.5배로 늘어남)
새로운 총 실행 시간: 0.7+0.1+0.15=0.95
[최종 Speedup 계산] Speedup=새로운총시간원래총시간=0.951.0 Speedup≈1.053
정답: 1.05 배
해석: FP 연산을 2배나 무지막지하게 늘렸지만, 캐시가 느려지는 페널티를 맞아서 전체 성능 향상은 고작 5%에 그쳤습니다. (a번의 11% 향상에서 반토막이 났습니다.)
c.
최적화 이후, FP와 Cache가 차지하는 '새로운' 시간 비중은?
이 문제의 핵심은 "기준이 바뀌었다(Total time is now 0.95)"는 것을 캐치하는 것입니다. 전체 시간이 1.0에서 0.95로 줄어들었으므로, 분모를 0.95로 두고 다시 퍼센트를 계산해야 합니다.
정답:
FP operations: 10.5%
Data cache accesses: 15.8%
이 문제를 풀고 나면 하드웨어 아키텍처 설계에서 왜 병목(Bottleneck) 분석이 중요한지 직관적으로 다가옵니다.
처음에 FP 연산은 전체의 20%를 차지하는 제법 큰 비중이었습니다. 하지만 최적화를 거친 후, FP 비중은 10.5%로 쪼그라들고, 오히려 아무것도 건드리지 않았던(심지어 느려진) Data Cache의 비중이 10%에서 15.8%로 튀어 올랐습니다.
이제 다음 버전을 설계할 때는 FP 유닛을 건드리는 게 아니라, 비중이 가장 커져버린 Data Cache 구조를 어떻게 개선할지 고민해야 성능을 제대로 끌어올릴 수 있습니다!