1. Addressing Modes (How to find the data)
Addressing modes define how the CPU locates the operands (data) it needs for an instruction.
Addressing Modes
1. Register //ADD R4, R3 (R4 = R4 + R3)
2. Immediate //ADDI R1, R2, #8 (R1 = R2 + 8)
3. Register indirect //ADD R4, (R1), R4 = R4 + Memory[R1]
4. Displacement //LD R4, 100(R1) (Address = R1 + 100)
5. Indexed // ADD R3, (R1+R2)/ Address = R1 + R2, R3 = R3 + Memory[Address]
6. Direct or Absolute // ADD R1/ (1001) Address = 1001, R1 = R1 + Memory[1001]1. Register (레지스터 주소 지정)
데이터가 이미 CPU 안의 레지스터(바구니)에 들어있는, 가장 빠르고 단순한 방식입니다. 메모리(RAM) 밖으로 나갈 필요가 없습니다.
- 명령어: ADD R4, R3
- 동작: // R4 = R4 + R3
- 해석: "R3 바구니에 있는 값을 꺼내서, R4 바구니에 있는 값과 더한 뒤, 그 결과를 다시 R4 바구니에 넣어라."
2. Immediate (즉시 주소 지정)
명령어 안에 우리가 쓸 '실제 숫자(데이터)'가 아예 대놓고 적혀 있는 방식입니다. 찾으러 갈 필요가 없습니다.
- 명령어: ADDI R1, R2, #8
- 동작: // R1 = R2 + 8
- 해석: "숫자 8을 명령어에서 바로 꺼내서, R2 바구니의 값과 더한 뒤, R1 바구니에 넣어라."
3. Register Indirect (레지스터 간접 주소 지정)
레지스터 안에 데이터가 있는 게 아니라, "데이터가 숨겨진 메모리 주소(보물지도)"가 들어있는 방식입니다. C언어의 포인터(*)와 완벽히 같습니다.
- 명령어: ADD R4, (R1)
- 동작: // R4 = R4 + Memory[R1]
- 해석: "R1 바구니를 열어보니 '1000번지'라는 주소가 적혀 있네? 메모리 1000번지로 달려가서 진짜 데이터를 꺼낸 뒤, R4 바구니 값과 더해라."
4. Displacement (변위 주소 지정) - ⭐ MIPS 메모리 접근의 핵심
기준점(Base)이 되는 주소에 특정 거리(Offset)를 더해서 최종 메모리 주소를 찾는 방식입니다. (아까 택배 비유로 설명해 드린 바로 그 방식입니다!)
- 명령어: LD R4, 100(R1)
- 동작: // Address = R1 + 100; R4 = Memory[Address]
- 해석: "R1 바구니에 적힌 기준 주소(예: 1000번지)에서 100만큼 더 떨어진 곳(1100번지)으로 찾아가라. 거기서 데이터를 꺼내 R4 바구니에 담아라."
5. Indexed (인덱스 주소 지정)
두 개의 레지스터 값을 더해서 최종 메모리 주소를 계산하는 방식입니다. 주로 배열[i] 같은 것을 탐색할 때 씁니다.
- 명령어: ADD R3, (R1+R2)
- 동작: // Address = R1 + R2; R3 = R3 + Memory[Address]
- 해석: "R1 바구니(배열의 시작 주소)와 R2 바구니(몇 번째 칸인지)의 값을 더해서 주소를 만들어라. 그 주소로 메모리에 찾아가 데이터를 꺼내고, R3 바구니 값과 더해라."
6. Direct or Absolute (직접 / 절대 주소 지정)
명령어에 아예 대놓고 "메모리 몇 번지!"라고 실제 주소 번호표를 쾅 찍어놓은 방식입니다.
- 명령어: ADD R1, (1001)
- 동작: // Address = 1001; R1 = R1 + Memory[1001]
- 해석: "다른 거 계산할 필요 없이, 곧바로 메모리 1001번지로 달려가라. 거기서 데이터를 꺼내서 R1 바구니 값과 더해라."
2. what address mode using at MIPS
MIPS (Microprocessor without Interlocked Pipeline Stages)
is a reduced instruction set computing (RISC) CPU architecture
known for its simplicity, efficiency,
and 5-stage pipeline, designed for high-speed instruction executionBecause MIPS is a strict RISC architecture, it likes to keep things simple. It primarily uses only three of the modes above:
- Register Mode: For all ALU arithmetic/logic operations (ADD, SUB, AND).
- Immediate Mode: For operations with constants (ADDI) and calculating Branch offsets, 16-bit immediate, offset field
- Displacement Mode: MIPS exclusively uses this for accessing memory (LW, SW). Note: In MIPS, to simulate "Register Indirect" or "Direct" addressing, you simply use Displacement mode and set either the offset to 0 or use the grounded R0 (which is always 0). load/store only
3. BNE (Branch Not Equal)
BNE (Branch Not Equal) 명령어는 MIPS 아키텍처에서 프로그램의 흐름을 바꾸는(제어하는) 아주 핵심적인 명령어입니다. C언어나 자바에서 쓰는 if (a != b) 나 while (a != b) 같은 조건문이 기계어로 번역되면 십중팔구 이 BNE (또는 단짝인 BEQ)가 됩니다.
1. BNE의 기본 형태 (I-Format)
BNE는 레지스터 두 개를 비교하고, 특정 주소로 점프해야 하므로 I-format (Immediate format)을 사용합니다.

기계어 구조 (32비트):
- Opcode (6비트): BNE임을 알림
- rs (5비트): 비교할 첫 번째 레지스터 (R1)
- rt (5비트): 비교할 두 번째 레지스터 (R2)
- Offset (16비트): 점프할 거리 (L1까지의 거리)
어셈블리어 형태: BNE R1, R2, L1
- 의미: "만약(Branch) R1과 R2의 값이 같지 않다면(Not Equal), L1이라는 라벨(주소)로 점프해라. 만약 같다면, 그냥 무시하고 다음 명령어(PC+4)를 실행해라."
2. 점프할 주소 계산법 (PC-Relative Addressing)
CPU는 BNE를 읽자마자 PC를 PC+4(다음 명령어 주소)로 바꿔놓습니다.
목적지가 현재 위치에서 앞뒤로 얼마나 떨어져 있는지(Offset)를 계산한 뒤, 명령어 길이인 4바이트를 곱해() 실제 점프할 메모리 주소를 구합니다.
4. Single cycle datapath
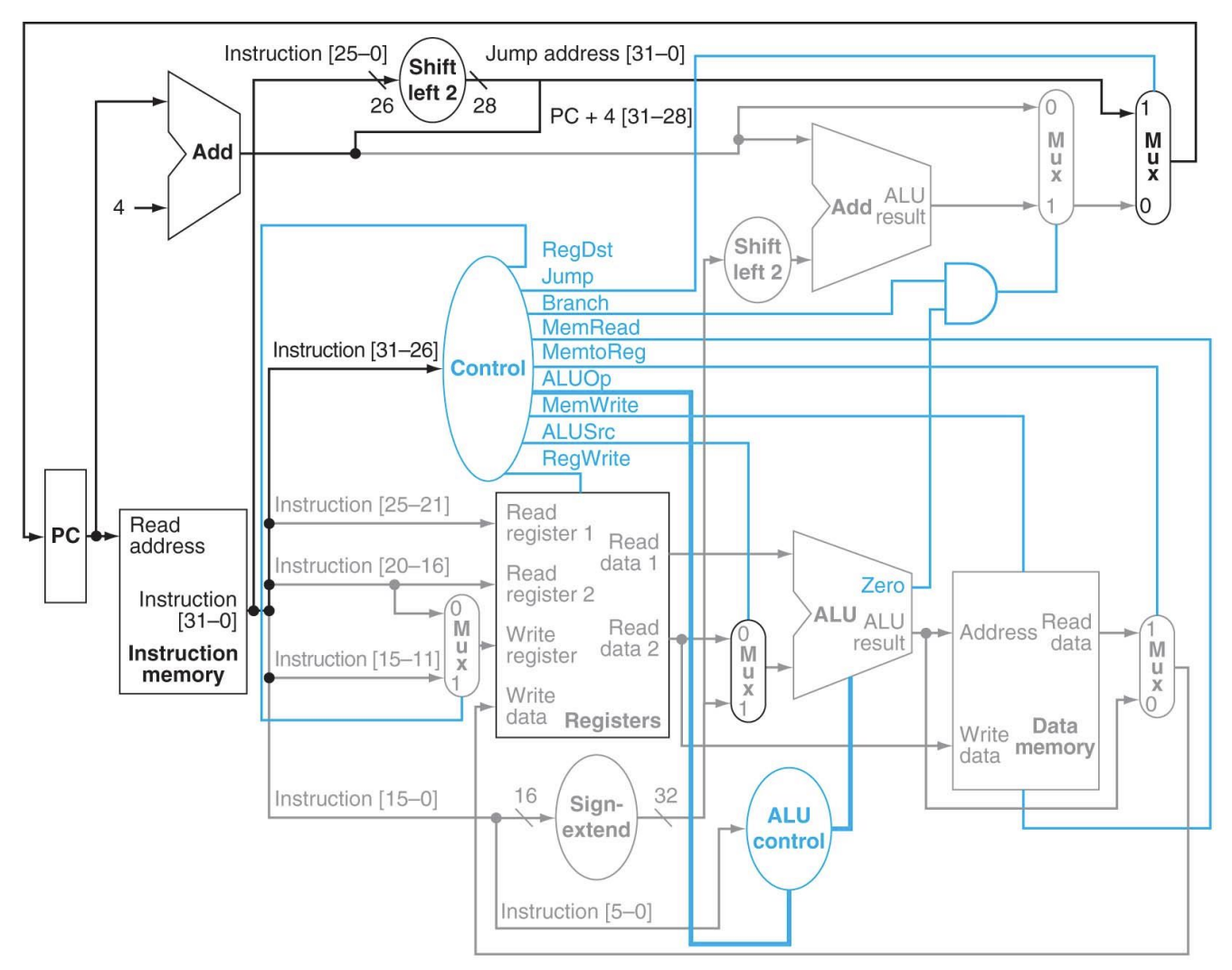
5. MIPS Architecture
MIPS (Microprocessor without Interlocked Pipeline Stages) is a reduced instruction set computing (RISC) CPU architecture, designed for high performance, simplicity, and efficiency.
MIPS는 "최대한 단순하게 만들자"는 RISC(Reduced Instruction Set Computer) 철학의 대표 주자입니다.
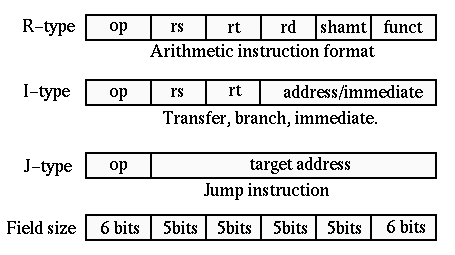
Load-Store Architecture:
- 메모리에 있는 데이터끼리는 직접 더하거나 뺄 수 없습니다. (예: Memory[A] + Memory[B] 불가능)
- 무조건 Load(가져와서 레지스터에 넣고) -> 계산(레지스터끼리) -> Store(다시 메모리에 저장) 과정을 거쳐야 합니다.
32-bit Fixed Format:
- 모든 명령어의 길이가 32비트(4바이트)로 똑같습니다. (파이프라인 설계하기 아주 편하겠죠?)
Registers (작업대):
- GPR (General Purpose Register, R0-R31): 정수 계산용 32개.
특징: R0는 항상 0입니다. (0이 필요할 때 따로 만들 필요 없이 갖다 쓰면 됨) - FPR (Floating Point Register, F0-F31): 실수 계산용 32개.
왜 컴퓨터는 GPR, FPR 로 나누었을까
명령어 길이 절약 (Instruction Encoding Efficiency)
이게 RISC 설계 철학에서 가장 현실적인 이유
- MIPS 명령어는 32비트 고정 길이입니다.
- 레지스터를 가리키는 주소 비트로 5비트(개)를 씁니다.
- 만약 GPR과 FPR을 합쳐서 64개로 만들면? 주소 비트가 6비트(개) 필요합니다.
- 명령어 포맷(R-format)에는 rs, rt, rd 3개의 레지스터 필드가 들어갑니다.
- 각각 1비트씩 늘어나면 총 3비트가 더 필요해집니다.
해결책: 그냥 32개씩 따로 두고, 명령어의 Opcode가 "이번엔 정수(GPR)야", "이번엔 실수(FPR)야"라고 알려주는 방식이 훨씬 경제적입니다.
1. MIPS R-format (Register format)

레지스터끼리 지지고 볶는 연산(더하기, 빼기 등)을 할 때 쓰는 포맷입니다. 32비트를 알뜰하게 쪼개 씁니다.
- ALU instruction. ADD R1, R2, R3
- op (6bit): Opcode. "이거 R포맷이야!"라고 알려주는 역할 (R-format은 보통 0).
- rs (5bit): 첫 번째 재료 레지스터 (Source 1).
- rt (5bit): 두 번째 재료 레지스터 (Source 2).
- rd (5bit): 결과 저장할 레지스터 (Destination).
- shamt (5bit): Shift Amount. 비트 이동(<<, >>) 연산할 때만 쓰고, 더하기 할 땐 0입니다.
- funct (6bit): Function Code. Opcode가 0일 때, "그래서 더하기야? 빼기야?"를 구체적으로 알려줍니다.
핵심: 레지스터 개수가 32개()라서 주소 비트가 5비트입니다.
2. MIPS I-format (Immediate format)

숫자(상수)를 직접 쓰거나, 메모리에 접근(Load/Store)할 때 씁니다.
특징:
- rt의 역할 변화: R-format에선 재료였지만, 여기선 결과 저장소(Destination)가 되기도 하고(Load 명령어), 저장할 값(Source)이 되기도 합니다(Store 명령어).
- Constant (16bit): 상수를 쓸 수 있는데, 범위는 ~ (약 ) 입니다. 이보다 큰 숫자는 못 씁니다.
LD/ST R1 &(R2), BME R1,R2,L1; ADDI R1
Q: store instruction, do you need second source for store instucrion, only need to read second value
답변: 네, SW R1, 100(R2) 같은 Store 명령어는 ID(Decode) 단계에서 레지스터 파일로부터 두 개의 레지스터를 반드시 읽어야 합니다.
최종 메모리 주소(R2 + 100)를 계산하기 위해 ALU로 보낼 R2 (Base 주소)를 읽어야 합니다
메모리에 실제로 저장할 데이터인 R1을 읽어서 메모리 단계(MEM)로 전달해야 합니다.
Branch 명령어 (I-Format, 예: BEQ R1, R2, L1): PC-Relative 주소 지정을 사용합니다.
공식: Target Address = (PC + 4) + (Offset 4)
MIPS J-format (Jump format)
명령어의 32비트를 아주 시원하게 쪼개어 씁니다.
Opcode (6비트): "나 점프(J) 명령어다!"라고 알려줌.
Target Address (26비트): 점프할 목적지 주소.
Target addr = pc+ L1 + L1 * L1
Pipelining
Similar to an assembly line
– Divide instruction execution into smaller tasks
– Each task is performed on a part of an instruction
– Overlap the execution of multiple instructions by
completing different tasks from different
instructions in parallel
Five stages, one step per stage
1. IF: Instruction fetch from memory
2. ID: Instruction decode & register read
3. EX: Execute operation or calculate address
4. MEM: Access memory operand
5. WB: Write result back to registerState of pipeline Diagram
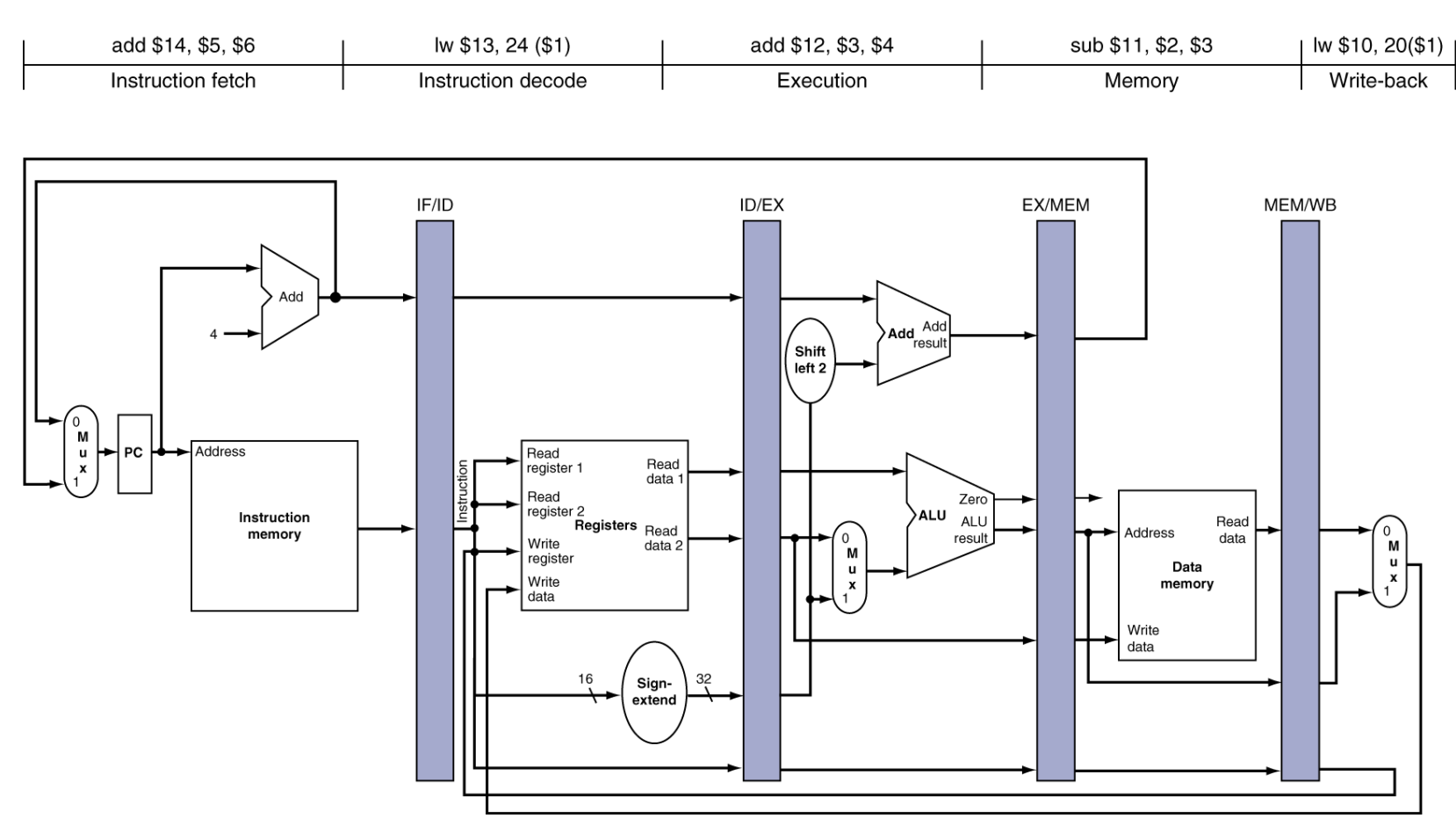
pipeline register
IF/ID 레지스터, ID/EX 레지스터, EX/MEM 레지스터, MEM/WB 레지스터.
역할: 각 단계가 끝날 때마다 결과물을 임시로 저장합니다.
예를 들어, 1번 명령어가 IF(인출)를 마치면 그 32비트 명령어 데이터는 IF/ID 레지스터에 저장됩니다.
다음 클락(Clock)이 오면, 1번 명령어는 ID(해석) 단계로 넘어가고, 그 빈자리에 2번 명령어가 들어와 IF를 수행합니다.
파이프라인 규칙 (A & B)
A. all instructions enter into the pipline stage at the same time
clock cycle time is determined by the slowest stage
one stage is one cycle
B. all instucion have to go through all the piplines stage
단계가 겹쳐 interuption 발생 -> doing nothing, just staying at register for one cycle(pipeline Stalls/bubbles)
IF (Instruction Fetch)
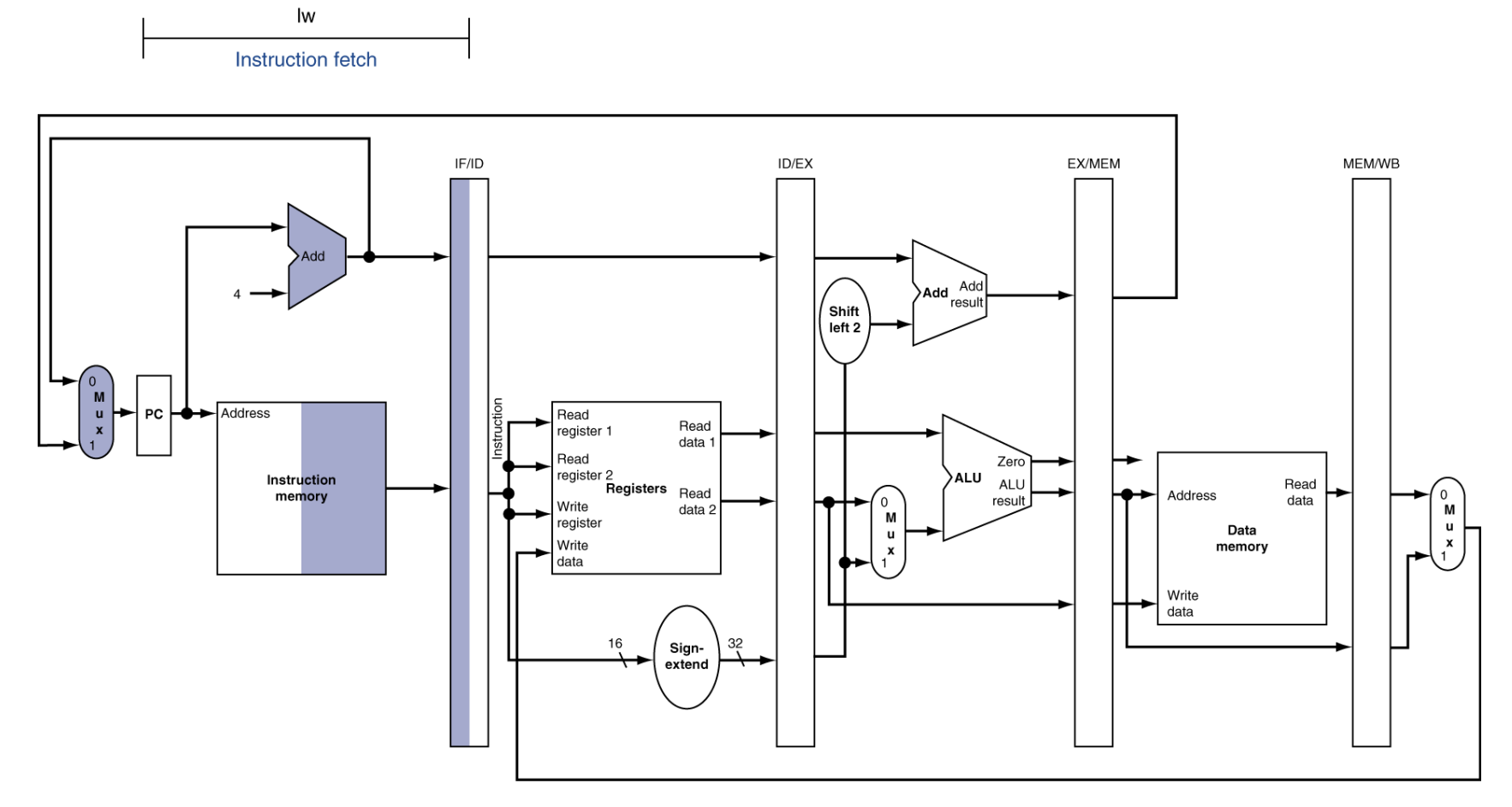
Fetch station
read register value at memory and fetch
동작: PC(Program Counter)가 가리키는 주소를 Instruction Memory에 보냅니다. 메모리는 해당 주소에 저장된 32비트 기계어(0과 1)를 뱉어냅니다.
상세 메커니즘:
- PC 업데이트: 명령어를 가져오는 동시에 PC + 4를 계산합니다. (32비트 명령어는 4바이트이므로 다음 명령어 주소는 현재+4입니다.)
- Mux(멀티플렉서)의 존재: 만약 이전 명령어 중에 Branch(분기) 명령이 있었다면, PC + 4가 아닌 '점프할 주소'를 선택해서 PC에 넣어야 합니다.
결과물: 32비트 명령어 뭉치 → IF/ID 레지스터로 전달.
ID (Instruction Decode)
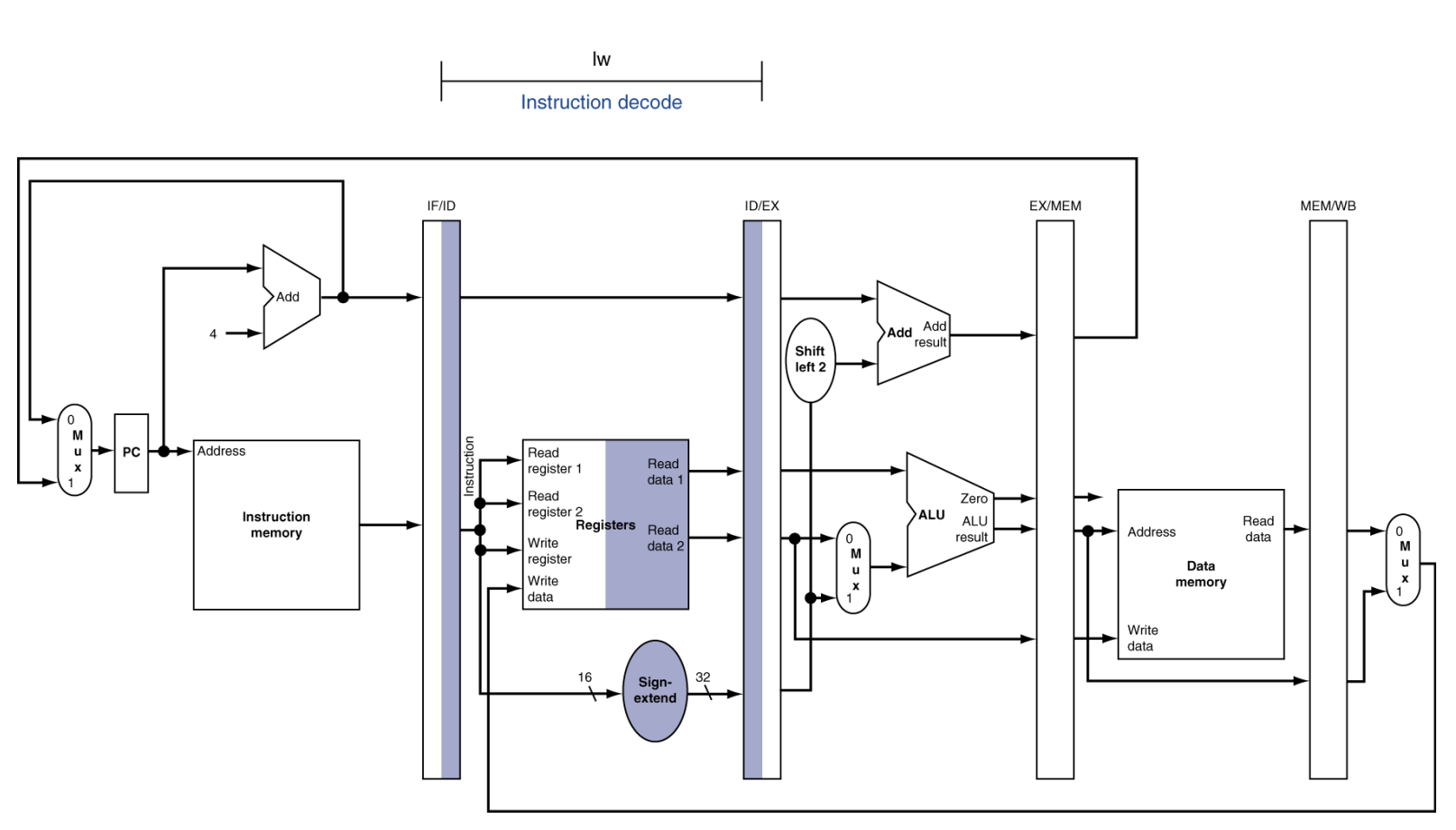
동작: 가져온 32비트가 무엇을 의미하는지 쪼개고, 필요한 재료(데이터)를 가져옵니다.
상세 메커니즘:
- Control Unit: 명령어의 앞부분(Opcode)을 보고 "아, 이건 더하기(ADD)구나!" 혹은 "메모리에서 읽는(Load) 거구나!"를 판단하여 CPU 전체에 뿌려줄 제어 신호를 만듭니다.
- Register File Read: 명령어에 적힌 번호(예: R2, R3)를 보고 레지스터 저장소에서 실제 데이터(예: 10, 20)를 꺼냅니다.
- Immediate Generation: 만약 ADDI R1, R2, 100처럼 숫자(상수)가 포함된 명령어라면, 100이라는 숫자를 32비트로 확장(Sign-extend)합니다.
결과물: 해석된 제어 신호 + 레지스터에서 읽은 값 → ID/EX 레지스터로 전달.
EX (Execute)
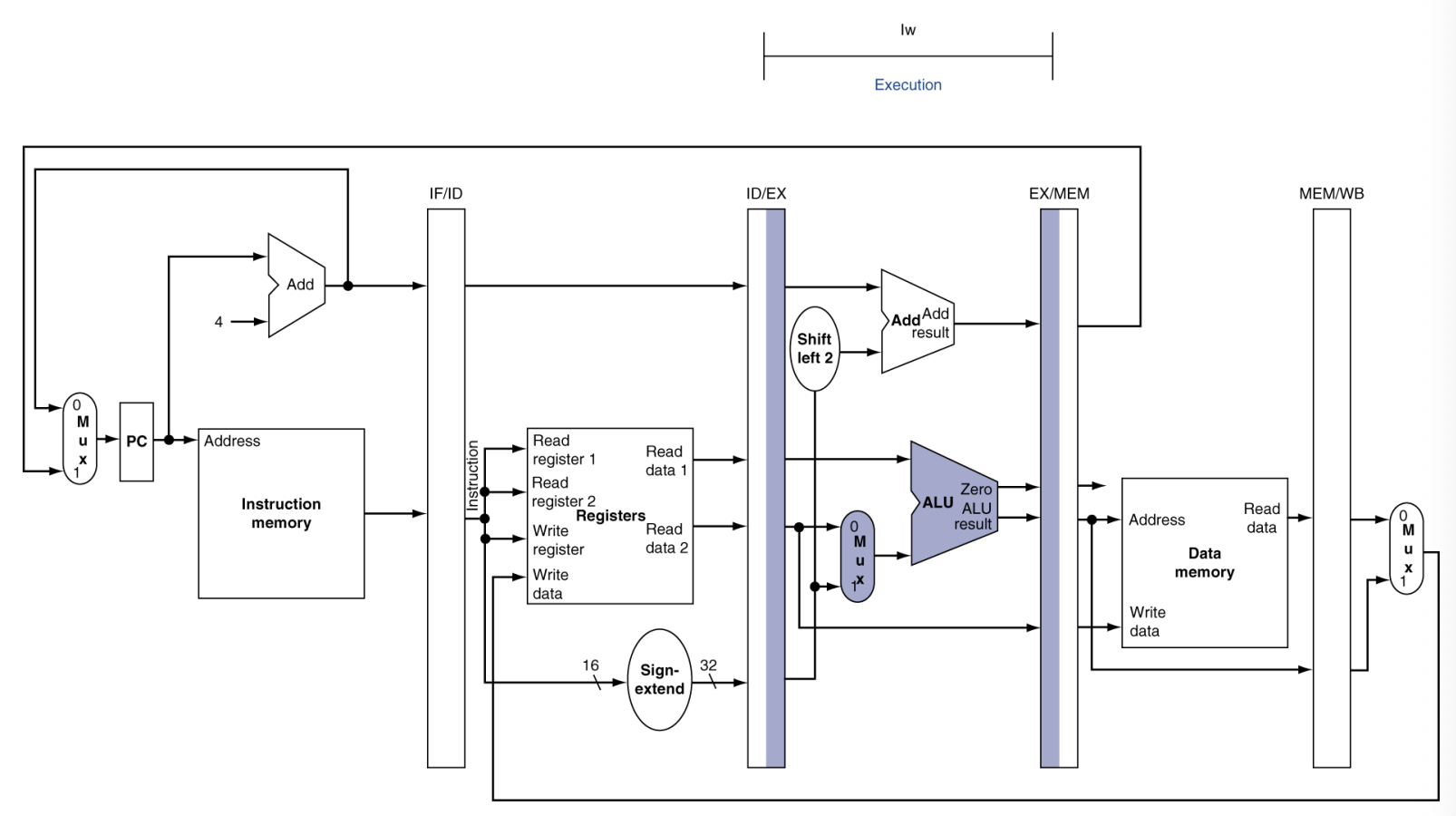
동작: 실제 연산이 일어나는 ALU(산술논리연산장치) 단계입니다.
상세 메커니즘:
- ALU 연산: 앞 단계에서 가져온 두 값을 더하거나, 빼거나, AND/OR 연산을 합니다.
- 주소 계산: 만약 Load 명령이라면, 기본 주소 + 오프셋을 계산하여 "메모리의 몇 번지"에 갈지를 결정합니다.
- Zero Flag: 만약 두 값을 뺐는데 0이 나왔다면 'Zero' 신호를 줍니다. (이건 Branch 명령에서 "두 값이 같은가?"를 판단할 때 쓰입니다.)
결과물: 연산 결과값 혹은 메모리 주소 → EX/MEM 레지스터로 전달.
MEM (Memory Access)
동작: 데이터 메모리에 데이터를 쓰거나(Store), 읽어옵니다(Load).
MEM for Load
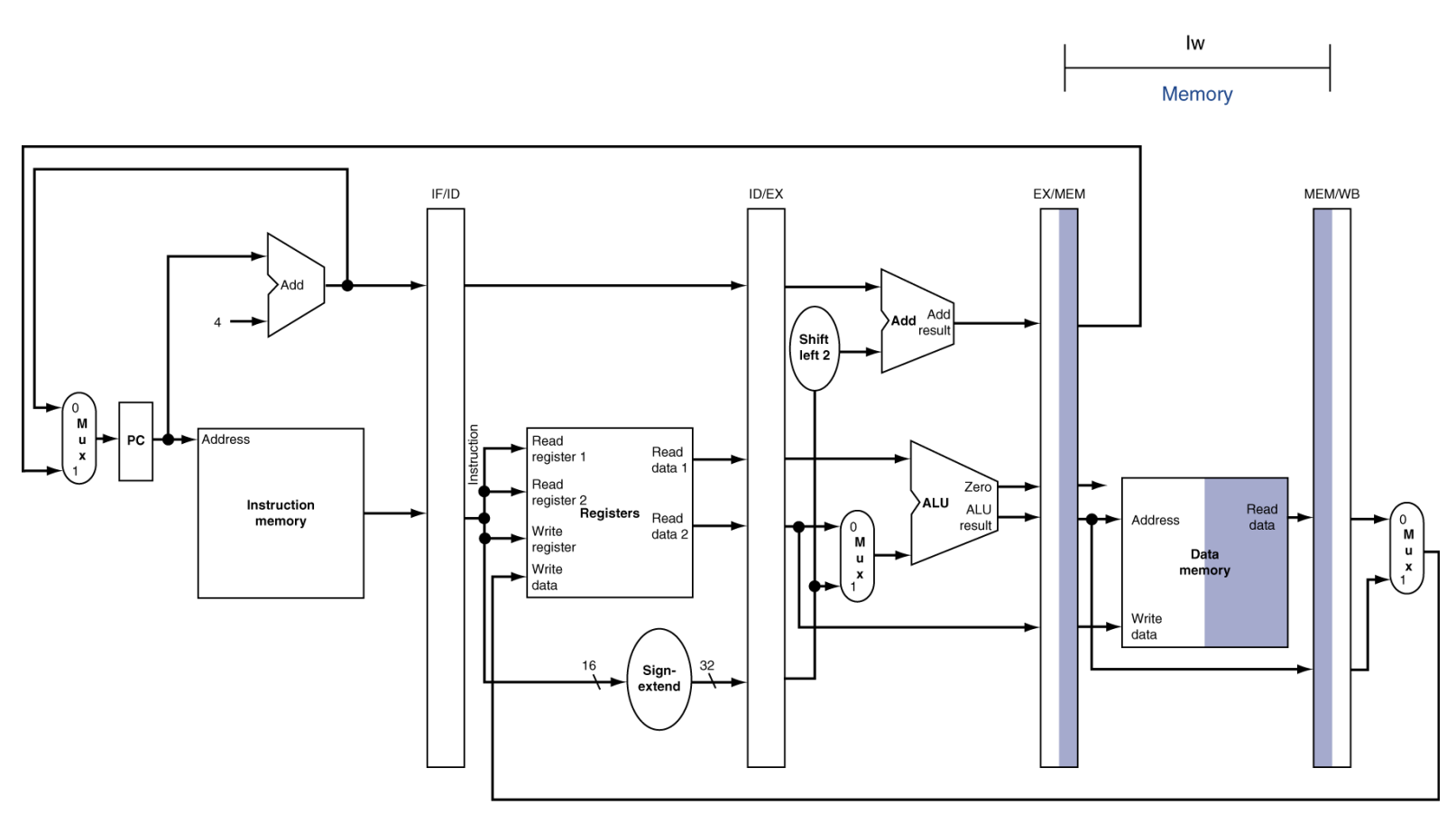
Load: EX 단계에서 계산된 주소에 가서 값을 읽어옵니다.
MEM for Store
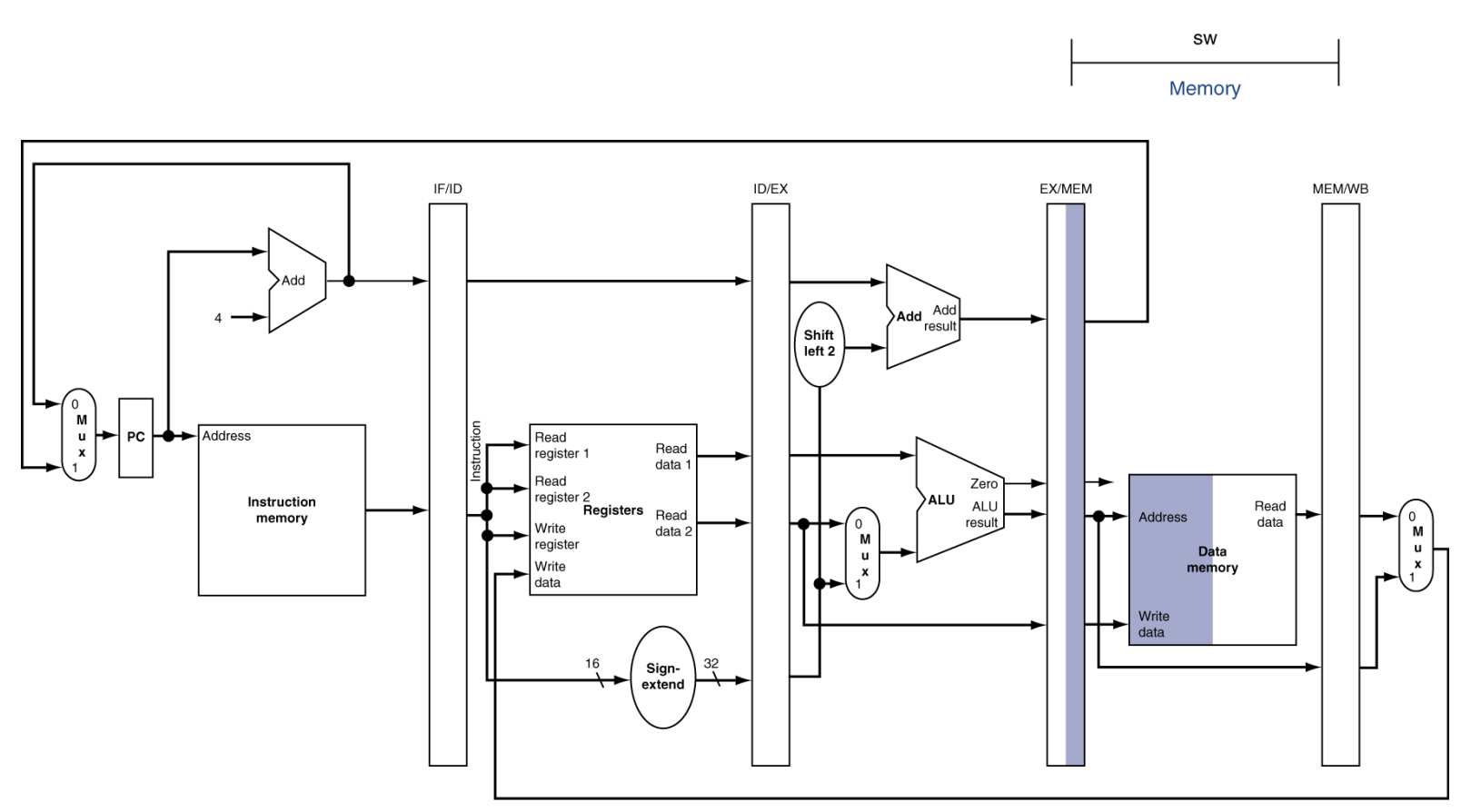
Store: EX 단계에서 계산된 주소에 레지스터 값을 저장합니다.
나머지: 일반 산술 연산(ADD 등)은 아무것도 안 하고 EX 단계의 결과값을 다음 단계로 그대로 전달만 합니다.
결과물: 메모리에서 읽은 데이터 혹은 ALU 연산 결과 → MEM/WB 레지스터로 전달.
WB (Write Back)
최종 결과를 레지스터 파일에 저장합니다.
최종 결과(메모리에서 읽은 값일 수도, ALU가 계산한 값일 수도 있음)를 선택해서 명령어에 지정된 목적지 레지스터(Destination Register, 예: R1)에 기록합니다.
WB for Store
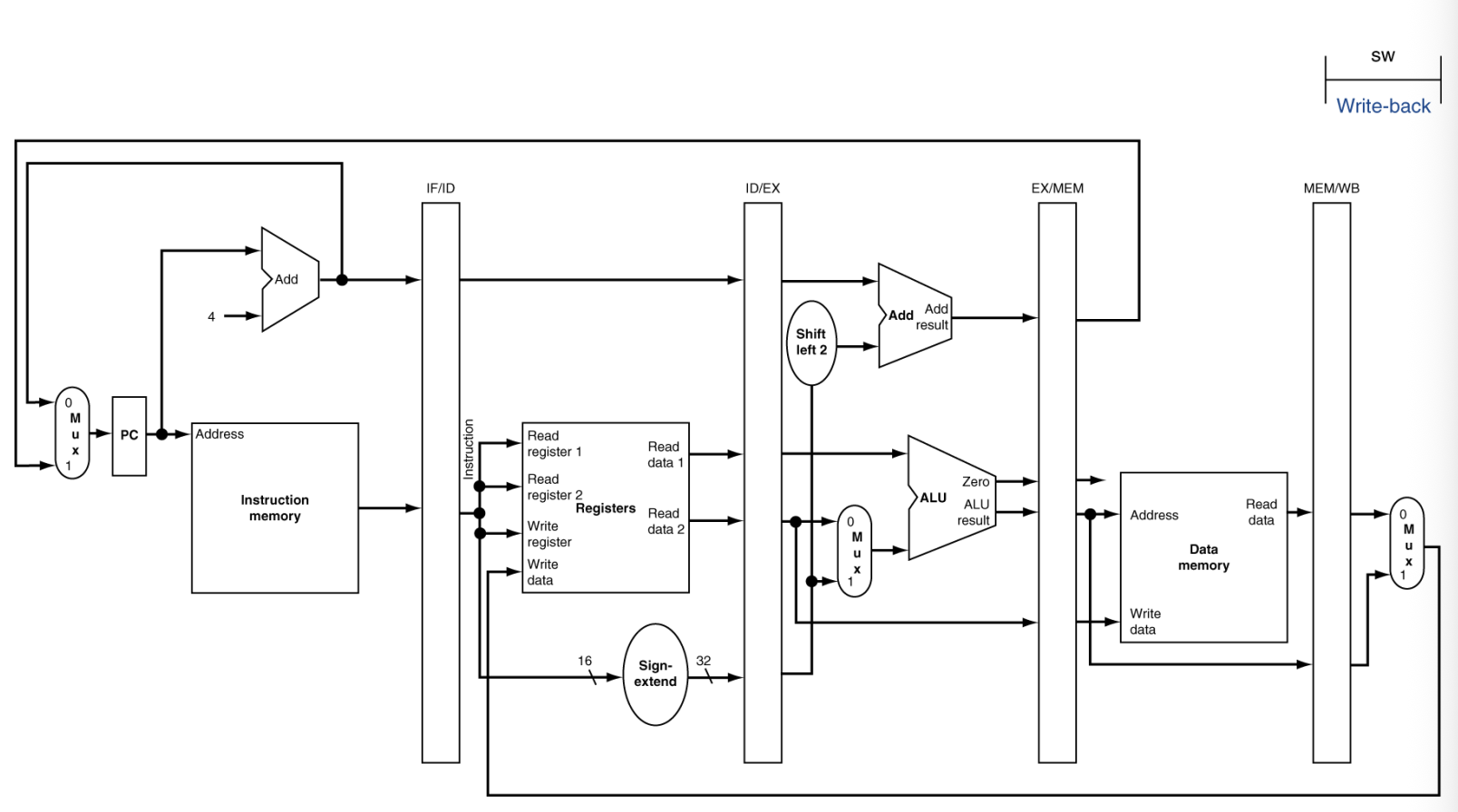
WB for Load
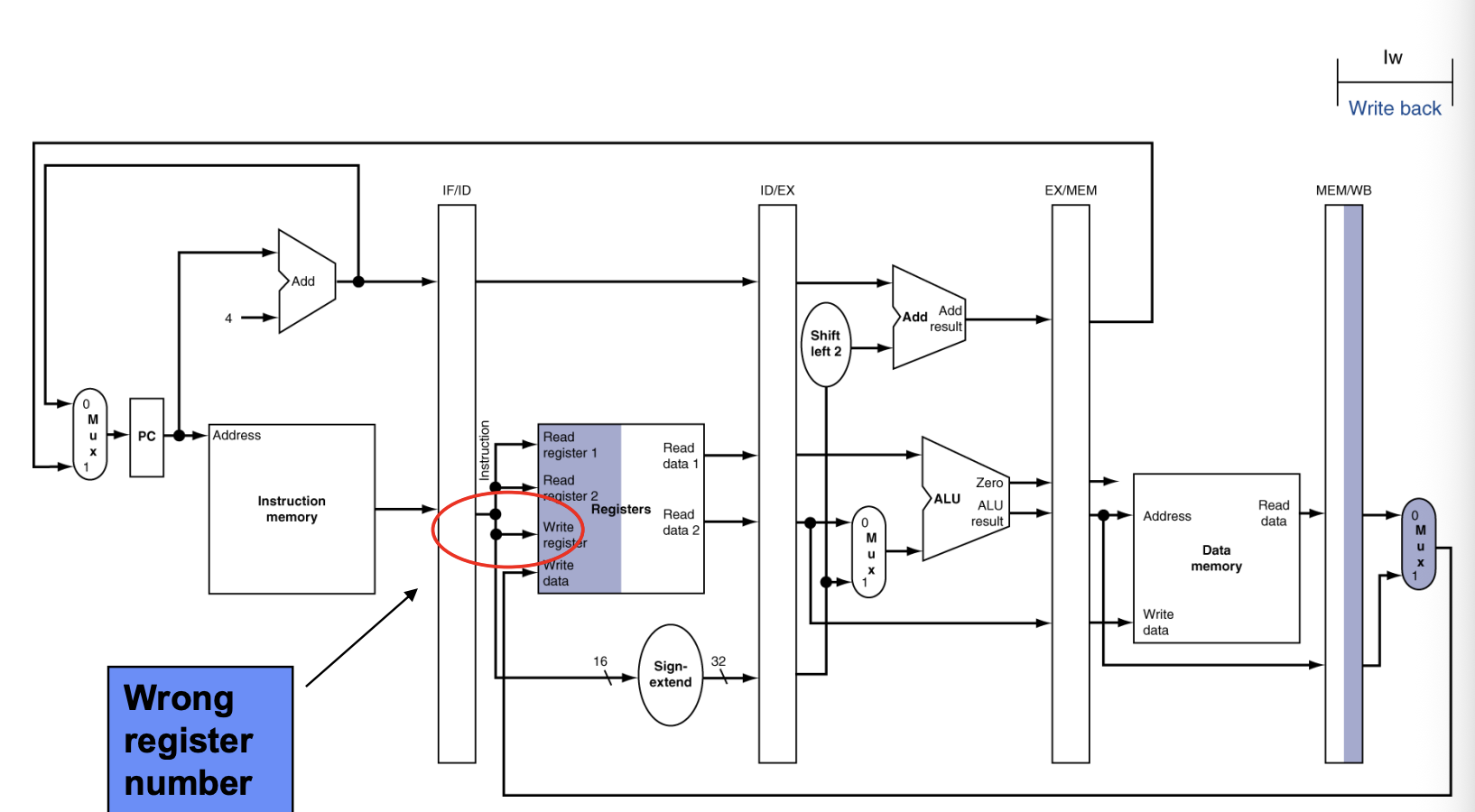
write to Degistiantion register wb -> 바로 write register 로 가는 경로 필요
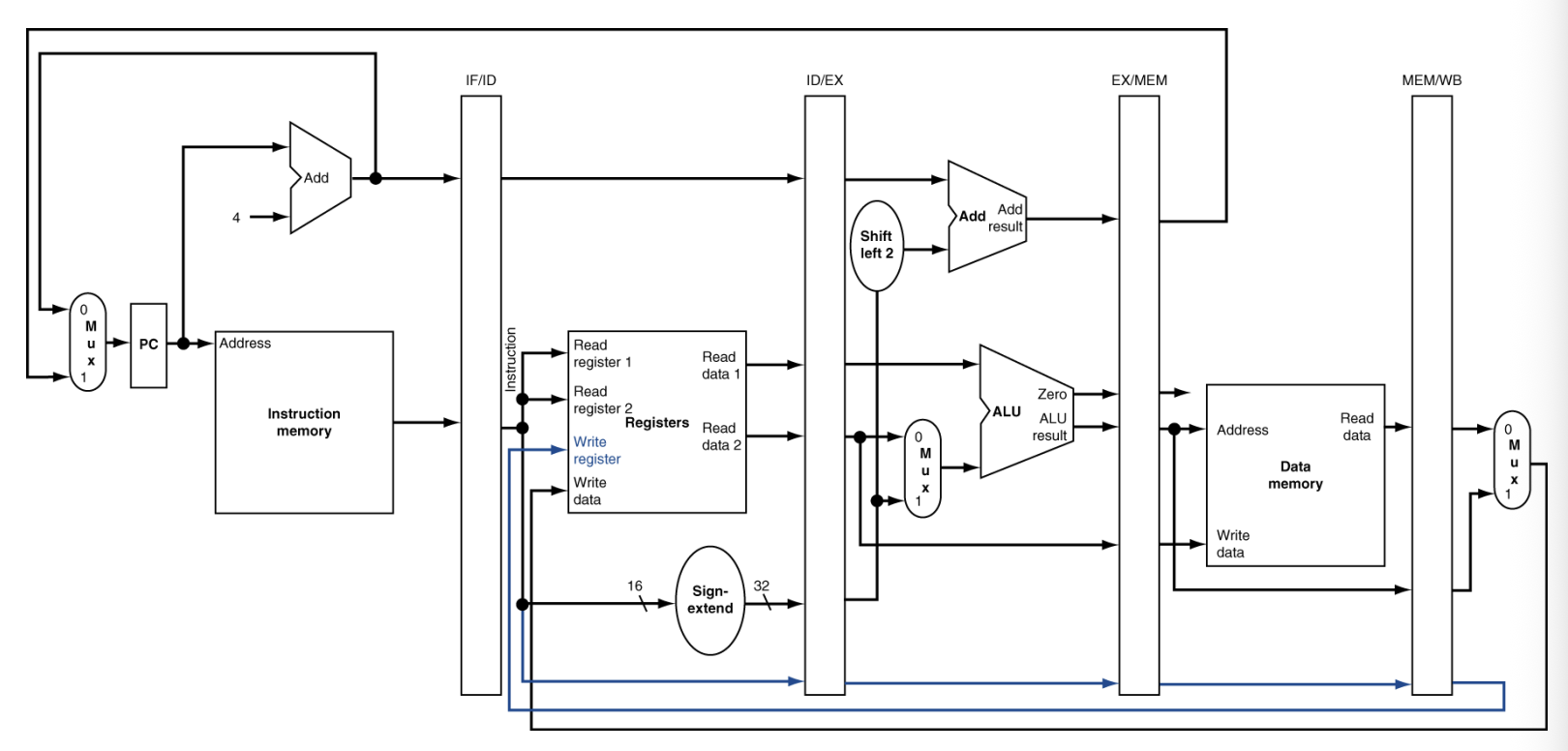
MIPS 명령어 동작분석
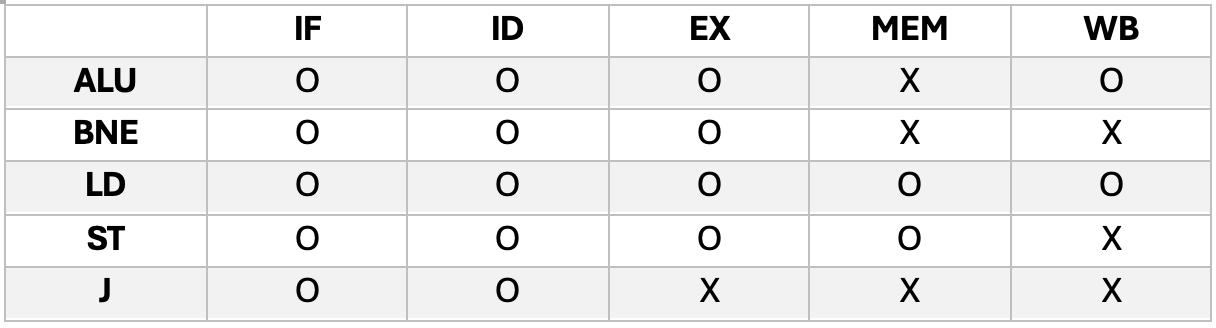
- ALU (산술/논리 연산 명령어)
- 예시: ADD, SUB, AND
- 패턴: O - O - O - X - O
- 설명: 레지스터의 값을 읽어와(ID) 더하거나 뺍니다(EX). 메모리에 접근할 필요가 없으므로 MEM 단계는 놉니다(X). 계산된 최종 결과값을 다시 레지스터에 저장해야 하므로 WB(Write Back) 단계는 사용합니다(O).
- BNE (조건부 분기 명령어)
- 참고: BNE or BEQ(Branch Not Equal)
- 패턴: O - O - O - X - X
- 설명: 두 레지스터의 값을 비교하고(ID/EX), 점프할 타겟 주소를 계산하기 위해 EX 단계까지는 ALU를 사용합니다(O). 하지만 메모리에서 데이터를 가져올 일도 없고(MEM X), 계산 결과를 레지스터에 덮어쓸 일도 없으므로(WB X) 뒤의 두 단계는 사용하지 않습니다.
- LDP (메모리 읽기 명령어 - Load)
- 참고: Load 명령어이므로 LW (Load Word)나 LD를 의미합니다.
- 패턴: O - O - O - O - O
- 설명: 유일하게 5단계를 모두 꽉 채워서 사용하는 명령어입니다. 주소를 계산하고(EX), 그 주소로 메모리를 찾아가 데이터를 꺼내온 뒤(MEM), 그 데이터를 레지스터에 최종적으로 저장(WB)해야 하기 때문입니다. 이 명령어 때문에 파이프라인 클럭 주기가 5단계로 맞춰지게 됩니다.
- ST (메모리 쓰기 명령어 - Store)
참고: Store 명령어이므로 SW (Store Word)를 의미합니다.
- 패턴: O - O - O - O - X
- 설명: EX 단계에서 주소를 계산하고, MEM 단계에서 메모리에 데이터를 밀어 넣습니다(O). 하지만 메모리에 "쓰기"만 할 뿐, CPU 내부의 레지스터로 다시 가져올(Write Back) 데이터가 없으므로 WB 단계는 비워둡니다(X).
- J (무조건 점프 명령어 - Jump)
- 패턴: O - O - X - X - X
- 설명: 가장 빨리 끝나는 명령어입니다. 명령어를 가져와서 해석해 보니(ID) "아, 무조건 점프구나!"라는 걸 알게 되고, ID 단계에서 목적지 주소 계산이 이미 끝나버립니다. 따라서 뒤의 연산(EX), 메모리(MEM), 레지스터 저장(WB) 단계는 모두 필요 없습니다.
이 표를 볼 때 주의해야 할 점이 하나 있습니다.
표에는 'X'라고 표시되어 있지만, 실제 파이프라인 회로 내부에서는 해당 명령어가 그 단계를 건너뛰고 휙 날아가는 것이 아닙니다. 파이프라인의 동기화(Synchronization)를 유지하기 위해, 'X'인 단계에서도 명령어는 해당 파이프라인 레지스터(예: EX/MEM 레지스터)에 머물며 한 클럭을 소모합니다. 다만 제어 신호(Control Signal)를 0으로 꺼서, "아무런 동작도 하지 않고 통과(NOP)"하게 만들 뿐입니다.
실제 RTL(Register Transfer Level) 코드로 CPU를 설계하고 검증(Verification)할 때, 이 'X' 구간에서 잘못된 값이 레지스터나 메모리를 덮어쓰지 않도록 제어 신호를 정확히 매핑하는 것이 매우 중요합니다.
