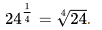1. Dependability(신뢰성/의존성)
1. Dependability의 핵심 개념
Dependability는 "사용자가 시스템을 믿고 의존할 수 있는 능력"을 말합니다. 단순히 "고장이 안 난다"를 넘어서, 고장이 나더라도 얼마나 빨리 복구하느냐까지 포함하는 포괄적인 개념입니다.
① Service States (서비스 상태)
Service Accomplishment (서비스 달성): SLA(Service Level Agreement)에 명시된 대로 시스템이 정상 작동하는 상태.
Service Interruption (서비스 중단): 시스템이 약속된 기능을 수행하지 못하는 상태.
Failure (고장): 정상(1) → 중단(2)으로 넘어가는 사건.
Restoration (복구): 중단(2) → 정상(1)으로 돌아오는 사건.
② 핵심 지표 (Metrics) - 공식 암기 필수
MTTF (Mean Time To Failure): 고장 날 때까지 걸리는 평균 시간. (수명)
MTTR(Mean Time To Repair): 고장 난 후 고칠 때까지 걸리는 평균 시간. (수리 시간)
MTBF (Mean Time Between Failures): 고장과 다음 고장 사이의 간격.
Availability (가용성): 전체 시간 중 시스템이 '살아있는' 비율.
2. Failure Rate (고장률)와 FIT
MTTF만으로는 계산이 복잡하기 때문에, 역수인 Failure Rate (고장률, )를 더 많이 사용합니다.
- 공식:
- 직렬 시스템(Serial System)의 법칙: 부품이 하나라도 고장 나면 전체가 멈추는 시스템에서, 전체 고장률은 각 부품 고장률의 합입니다.
FIT (Failures In Time): 10억 시간( hours) 동안 발생하는 고장 횟수. (반도체/서버 신뢰성 표준 단위)
3. 예제 문제 풀이 (Disk Subsystem MTTF)
이 문제는 "각 부품의 고장률을 다 더해서 전체 고장률을 구한 뒤, 다시 뒤집어서(역수) 전체 MTTF를 구하라"는 문제입니다.
[Step 1] 각 부품의 고장률(Failure Rate) 구하기
계산 편의를 위해 시간 단위를 통일하거나 단순히 역수로 표현합니다.
1. Disk: 시간
2. Controller: 시간
3. Power Supply: 시간
4. Fan: 시간
5. Cable: 시간
[Step 2] 시스템 전체 고장률 합산하기 ()주의할 점은 부품의 개수를 곱해야 한다는 것입니다. (디스크가 10개면 고장 확률도 10배!)
[Step 3] 전체 시스템의 MTTF 구하기
고장률의 역수가 곧 MTTF입니다.
2. Performance Measurement
(성능 측정의 기준)
① Throughput (처리량) vs Execution Time (실행 시간)
-
Execution Time (Latency, Response Time):
- 정의: 작업 하나를 끝내는 데 걸리는 시간. (예: 프로그램 실행부터 종료까지 5초)
- 누구에게 중요? 개인 사용자(PC, 모바일). "내 게임 로딩이 얼마나 빠른가?" -
Throughput (Bandwidth):
- 정의: 단위 시간당 처리하는 작업의 총량. (예: 1초에 100개의 검색 요청 처리)
- 누구에게 중요? 데이터센터, 서버 관리자. "이 서버가 동시 접속자를 몇 명까지 버티나?"
② Relative Performance (상대적 성능 비교)
"컴퓨터 X가 컴퓨터 Y보다 배 빠르다"를 수식으로 나타내는 법입니다.
성능(Performance)은 시간(Time)과 반비례한다는 점을 꼭 기억하세요.
해석: X가 Y보다 배 빠르다 = X의 실행 시간이 Y보다 배 짧다.
3. Metrics for Execution Time (시간을 재는 법)
시간을 잴 때도 "무엇을 포함하느냐"에 따라 두 가지로 나뉩니다.
Wall-clock time (Elapsed time):
벽에 걸린 시계로 잰 시간. CPU 작업 시간뿐만 아니라 디스크 로딩(I/O), 메모리 접근, 다른 프로그램이 끼어든 시간 등을 모두 포함합니다.
CPU time: CPU가 순수하게 내 프로그램을 실행하는 데 쓴 시간. (우리가 집중할 부분)
- User CPU time: 내 프로그램 코드 실행 시간.
- System CPU time: OS가 내 프로그램을 돕기 위해(파일 열기 등) 쓴 시간.
- 수업의 초점: User CPU time on unloaded system (다른 부하가 없는 상태에서의 순수 사용자 CPU 시간)
4. CPU Performance Equation
이 공식은 "Iron Law of Processor Performance"라고 불릴 정도로 중요합니다. CPU 시간을 세 가지 요소로 분해합니다.
① 기본 공식 유도
CPU 시간은 단순히 (총 클럭 사이클 수) (한 사이클의 길이)입니다.
또는 클럭 속도(Rate, Frequency)를 이용하면:
참고: (예: 1GHz = 1ns 주기)
② 심화 공식 (Instruction Count & CPI 도입)
하지만 '총 사이클 수'만으로는 분석이 어렵습니다. 그래서 명령어 개수(Instruction Count)와 CPI(Cycles Per Instruction) 개념을 도입합니다.
-
Instruction Count (IC): 프로그램이 실행한 기계어 명령어의 총개수.
-
CPI (Cycles Per Instruction): 명령어 하나를 실행하는 데 평균적으로 드는 사이클 수.
이걸 위 공식에 대입하면 그 유명한 3변수 공식이 나옵니다.
IPC (Instructions Per Cycle) 란?
정의: 한 사이클(Clock) 동안 처리할 수 있는 명령어의 개수.
수식:
의미: "우리 CPU는 한 번 쿵! 할 때마다 명령어를 몇 개씩 해치우나?" (높을수록 좋음)
CPI (낮을수록 좋음): "이번 신형 CPU는 CPI가 0.8에서 0.5로 줄었어!" -> 뭔가 줄었다니 좋은 건가? (헷갈림)
IPC (높을수록 좋음): "이번 신형 CPU는 IPC가 1.2에서 2.0으로 늘었어!" -> 와! 성능이 두 배 가까이 뛰었네! (직관적)
The Three Factors (성능을 결정하는 3대 요소)
이 3가지 변수는 서로 독립적이지 않고, 하드웨어/소프트웨어 기술이 복합적으로 영향을 미칩니다. 교수님이 "어떤 기술이 어떤 변수에 영향을 주는지" 묻는 문제를 자주 냅니다.

핵심 요약 (시험 대비)
1. 성능과 시간은 반비례: 배 빠르다 = 시간이 로 줄었다.
2. CPU 성능 공식 암기:
(Time = Instruction Count CPI Cycle Time)
3. Trade-off (트레이드오프): 기술 하나가 모든 걸 좋게 만들진 않습니다.
- 예시: 명령어를 아주 복잡하게 만들면(CISC), 명령어 개수()는 줄어들지만, 명령어 하나 처리가 어려워져 나 사이클 타임()이 늘어날 수 있습니다.
- 결론: 셋을 모두 곱한 최종 CPU Time이 줄어드는 것이 진짜 성능 향상입니다.
Benchmark
1. 벤치마크의 계층 (Hierarchy of Benchmarks)
성능을 측정하는 프로그램도 '얼마나 실제와 비슷하냐'에 따라 급이 나뉩니다.
A. Toy Programs (장난감 프로그램):
프로그래밍 입문 때 짜는 100줄 미만의 아주 작은 코드들. (예: 퀵 정렬, 하노이의 탑)
문제점: 너무 작아서 캐시 메모리에 다 들어가 버리거나, 컴파일러가 최적화해 버리기 쉬워 실제 성능을 대변하지 못함.
B. Kernels (커널):
실제 응용 프로그램에서 가장 핵심적인 부분(Key pieces)만 떼어낸 것.
예: 행렬 곱셈(Matrix Multiply), FFT(고속 푸리에 변환).
과학 계산 등 특정 분야 성능 측정엔 좋지만 전체 시스템 성능을 보기엔 부족함.
C. Synthetic Benchmarks (합성 벤치마크):
실제 프로그램은 아니지만, 실제 프로그램의 통계적 특성(연산 빈도 등)을 흉내 내어 만든 가짜(Fake) 프로그램.
예: Dhrystone(정수), Whetstone(실수).
문제점: 컴파일러가 "아, 이거 가짜네?" 하고 패턴을 파악해서 과도하게 최적화해 버릴 수 있음.
D. Real Applications (실제 응용 프로그램):
가장 확실한 방법. 우리가 실제로 쓰는 프로그램(압축 프로그램, 컴파일러, 데이터베이스 등)을 그대로 돌리는 것.
SPEC CPU가 바로 이 방식입니다.
2. 벤치마크 스위트 (Benchmark Suite)
프로그램 하나만 돌리면 편파적일 수 있으니, 여러 성격의 프로그램을 모아놓은 종합 선물 세트입니다.
A. Desktop (데스크톱용)
특징: CPU 연산 능력(Processor-intensive)과 그래픽 성능이 중요.
대표주자: SPEC CPU2006
12 Integer (CINT): 정수 연산 (컴파일러, 압축, AI 등)
17 Floating-point (CFP): 실수 연산 (물리 시뮬레이션, 유체 역학 등)
B. Server (서버용)
특징: 처리량(Throughput)과 다중 사용자 지원이 핵심.
종류:
SPEC CPU (Rate mode): 여러 카피를 동시에 실행해서 처리량을 봄.
SPECSFS: 네트워크 파일 시스템(NFS) 성능 측정.
SPECWeb: 웹 서버 성능. 수많은 클라이언트가 접속해서 데이터 요청/전송하는 상황 시뮬레이션.
TPC (Transaction Processing): 데이터베이스(DB) 성능 측정. 은행 입출금처럼 데이터의 무결성이 중요한 트랜잭션 처리를 다룸.
3. 성능 비교 방법 (Comparing Performance)
측정된 여러 개의 시간 데이터를 어떻게 평균 낼 것인가?
① Arithmetic Mean (산술 평균)
공식:
특징: 총 실행 시간(Total Execution Time)을 줄이는 게 목표일 때 사용.
문제점: 실행 시간이 긴 프로그램 하나가 전체 평균을 좌지우지할 수 있음.

주어를 분모로, 비교대상을 분자로
B가 A보다 빠르다 ->
B is 9.1 times faster than A 1001/110 = 9.1
C is 25 times faster than A 1001/40 = 25
C is 2.75 times faster than B 110/40 = 2.75
② Weighted Arithmetic Mean (가중 산술 평균)
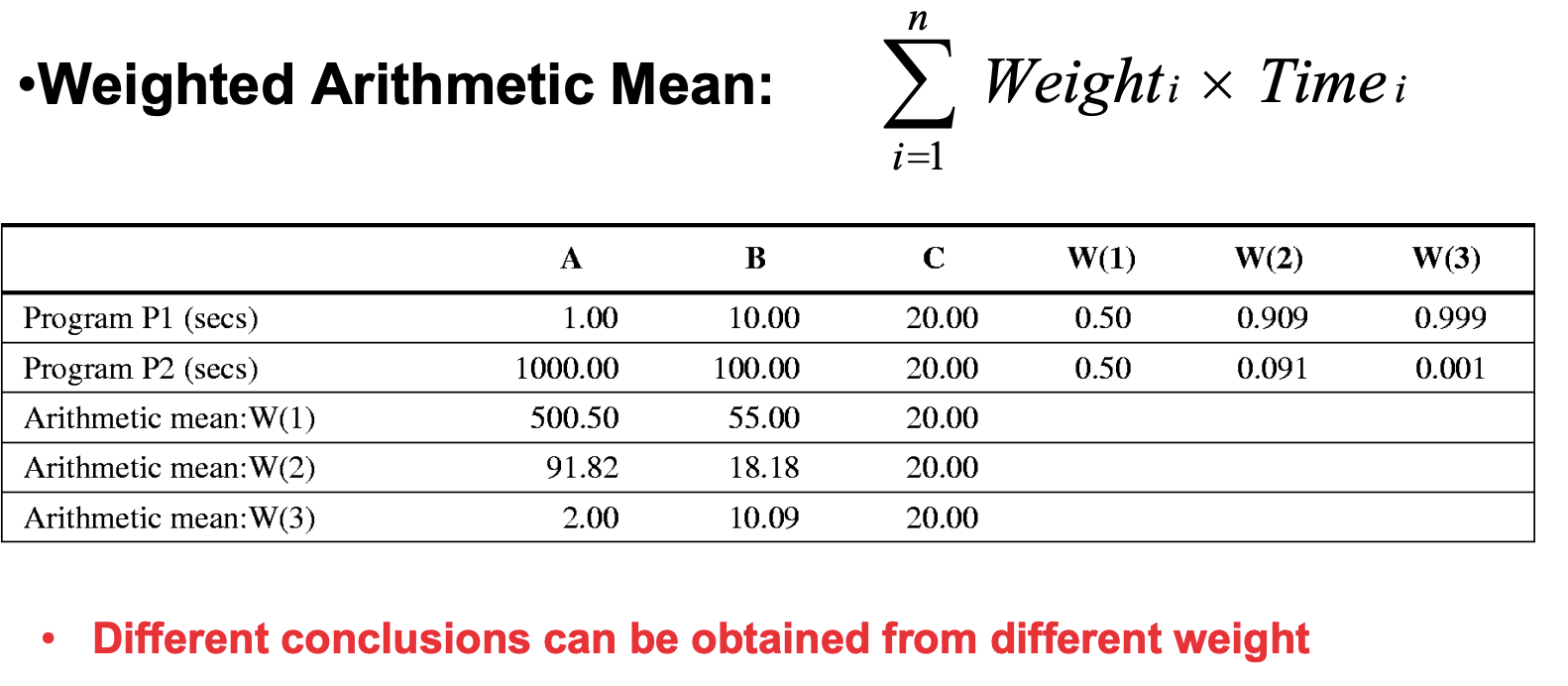
공식:
특징: 덜 중요한 프로그램과 더 중요한 프로그램에 가중치(Weight)를 다르게 줌.
③ Geometric Mean (기하 평균) - SPEC의 표준
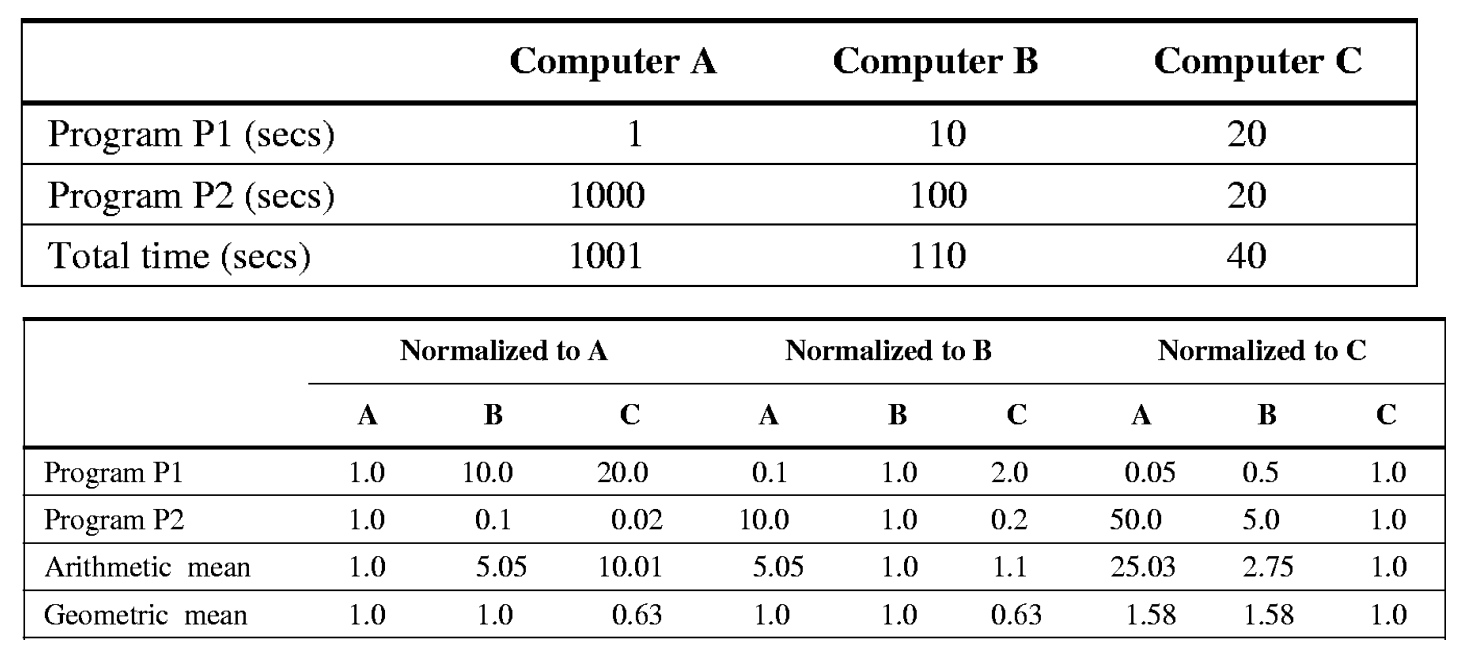
사용 이유: Normalized Execution Time (정규화된 실행 시간)을 평균 낼 때 씁니다.
SPEC은 기준 머신(Reference Machine) 대비 몇 배 빠른지를 나타내는 SPECRatio를 사용합니다.
기준 머신을 A로 하든 B로 하든, 성능 비교 결과(비율)가 모순 없이 일정하게 나옵니다. (산술 평균은 기준 머신을 바꾸면 결과가 뒤집히는 모순이 발생할 수 있음)
"왜 SPEC은 기하 평균을 쓰나?"
"SPEC 점수는 절대 시간이 아니라 기준 머신(Reference) 대비 비율(Ratio)인 SPECRatio를 사용하기 때문입니다. 비율을 평균 낼 때는 기하 평균(Geometric Mean)을 써야 기준 머신이 바뀌어도 성능 우열 관계가 변하지 않는 일관성(Consistency)을 유지할 수 있습니다."
기하평균이란?
기하평균은 주어진 n개의 양수의 곱의 n제곱근의 값을 말한다. 이 기하평균은 물가상승률, 성장률 등의 평균값을 이용할 때 사용한다.
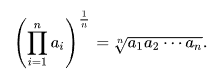
값 1, 2, 3, 4가 있을 때 1 x 2 x 3 x 4 = 24를 한후에 4의 제곱근을 한 값이다.