1.Reducing Power
A. Do nothing well
아무것도 안 할 거면, 확실하게 꺼라
놀고 있는 하드웨어는 전기를 0으로 먹게 만들어라
기술적 구현: Clock Gating
- 디지털 회로는 클럭 신호가 들어올때마다 전기를 사용
- 만약 ALU가 아무 일도 안하고 있다면, 하드웨어적으로 ALU로 들어가는 클럭 전선 자체를 끊어버림
- ALU 내부의 수백만 개 트랜지스터가 멈추고, Dynamic Power가 0이 됩니다.
B. DVFS
(Dynamic Voltage-Frequency Scaling)
개념: 일이 많을 땐 전압/클럭을 높여서 빨리 처리하고, 일이 적을 땐 둘 다 낮춰서( 효과) 에너지를 아낌
핵심: 단순히 클럭만 낮추는 게 아니라, 전압(Voltage)을 같이 낮춘다는 점이 포인트입니다.
Vdd 0.9~1.0v
Vth = 0.5v so 0.7까지 내릴수 있다
DVFS 한계: 전압()을 0.9V에서 낮추고 싶어도, 트랜지스터가 켜지는 최소 전압인 문턱 전압() 때문에 0.7V 밑으로 내리기가 힘듭니다.
NTC (Near threshold computing)
- 개념: 에라 모르겠다, 근처(Near Threshold)까지 전압을 극한으로 낮춰보자!
- 장점: 전력 소모()가 획기적으로 줄어듭니다.
- 단점: 전압이 낮으니 스위칭 속도가 느려져서 주파수(Frequency)가 떨어집니다. (It takes longer to finish job).
- 해결책 (Compensation): 느려진 속도를 만회하기 위해 코어 개수를 늘립니다(Multi-core). (싱글 코어는 느려도, 코어 100개가 동시에 일하면 처리량은 유지됨)
Dim Silicon & Dark Silicon
Dark Silicon: 전력 밀도(열) 때문에 칩 내의 모든 코어를 동시에 켤 수 없어, 일부는 꺼둬야 하는(Power Gating) 영역.
Dim Silicon: 끄지는 않지만, 열을 식히기 위해 클럭을 강제로 낮춰서 희미하게(Dim) 돌아가는 영역.
Timing Error와 TMR
전압을 NTC 수준으로 너무 낮추면, 신호가 0인지 1인지 헷갈리는 타이밍 에러(Timing Error)가 발생할 확률이 높습니다.
- TMR (Triple Modular Redundancy): 에러를 잡기 위한 무식하지만 확실한 방법.
똑같은 프로그램을 3번(Triple) 실행합니다.
Majority Vote (다수결): 셋 중 둘 이상이 내놓은 답을 정답으로 채택합니다. (신뢰성 확보)
C. Low power state
Do nothing well이 찰나의 순간(마이크로초 단위)에 작동한다면, 이건 좀 더 긴 시간 동안 쉴 때 시스템 전체를 재우는 것입니다(sleep mode)
DRAM Refresh 끄기: 메모리 데이터 유지를 위한 깜빡임(Refresh) 주기를 늦추거나 끕니다.
주변기기 끄기: Wi-Fi, 디스크, 모니터 전력을 차단합니다.
Processor C-states: 인텔 CPU의 C1, C6 같은 단계별 수면 모드입니다. 깊게 잘수록 깨어나는 데(Wake-up time) 오래 걸리지만 전기는 거의 안 씁니다.
P-state
C-state
D. Overclocking
이 부분이 조금 의아할 수 있습니다. "오버클럭은 전기를 더 먹는 건데 왜 여기 있지?"라고 생각하실 수 있죠. 여기에는 두 가지 중요한 맥락이 있습니다.
① Turning off cores (Power Gating) - 다크 실리콘
개념: 멀티코어 시대에는 모든 코어를 다 켜면 칩이 녹아버립니다(Thermal Issue). 그래서 사용하지 않는 코어는 전원 자체를 완전히 차단(Power Gating)합니다.
효과: Clock Gating보다 더 강력합니다. 누설 전류(Leakage Power)까지 0으로 만듭니다.
② Overclocking (Race to Halt 전략)
개념: 역설적이게도 "빨리 끝내고 쉬는 게(Race to Halt)" 에너지를 더 아낄 때가 있습니다.
[천천히 10초 동안 일하기] vs [오버클럭해서 2초 만에 끝내고 8초 동안 Deep Sleep 하기]
비유: 전등을 켜놓고 천천히 청소하는 것보다, 미친듯이 빨리 청소하고 전등을 꺼버리는 게 전기세가 덜 나올 수 있습니다.
Turbo Boost: 코어 3개를 끄고(Turning off), 남은 전력 여유분(Thermal Headroom)을 몰아주어 코어 1개를 오버클럭하는 기술. 이는 작업 효율을 높여 전체적인 에너지 소모를 최적화하는 전략입니다.
E. Specialized processors(전용 가속기)
Dark Silicon 문제 때문에 "모든 코어를 다 켤 수 없다"면, "특정 작업만 엄청 잘하는 놈(Specialized Accelerator)"만 켜는 게 효율적입니다.
- Heterogeneous Architecture (이기종 아키텍처): CPU(범용) + GPU(그래픽) + NPU(AI)를 섞어 씀.
- Domain Specific Architecture (DSA): 특정 도메인(예: AI 행렬 연산)에만 특화된 하드웨어.
- Power Efficiency (전력 효율성): 이제는 '얼마나 빠른가(Performance)'보다 '와트당 성능(Performance/Watt)'이 핵심 지표입니다.
F. Near-data processing(NDP), processing-in-memory(PIM)
이 부분 필기가 아주 중요합니다. 현대 AI 하드웨어의 가장 뜨거운 감자입니다.
-
배경: 폰 노이만 병목 현상. CPU가 아무리 빨라도 데이터를 메모리에서 가져오는 데 에너지의 50% 이상을 씁니다. (Data movement consumes lots of energy).
-
해결책 (PIM - Processing In Memory): 데이터를 CPU로 가져오지 말고, 메모리 안에서 계산해버리자!
-
기술 구현:
TSV (Through Silicon Vias): 칩에 구멍을 뚫어 수직으로 연결하는 엘리베이터. 데이터 고속도로 역할을 하여 대역폭(Bandwidth)을 엄청나게 높입니다.
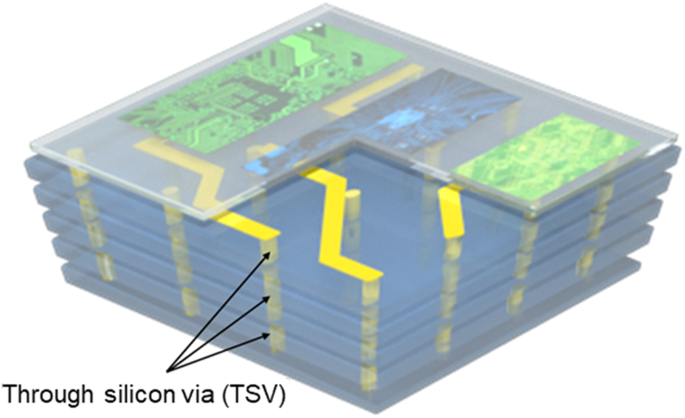
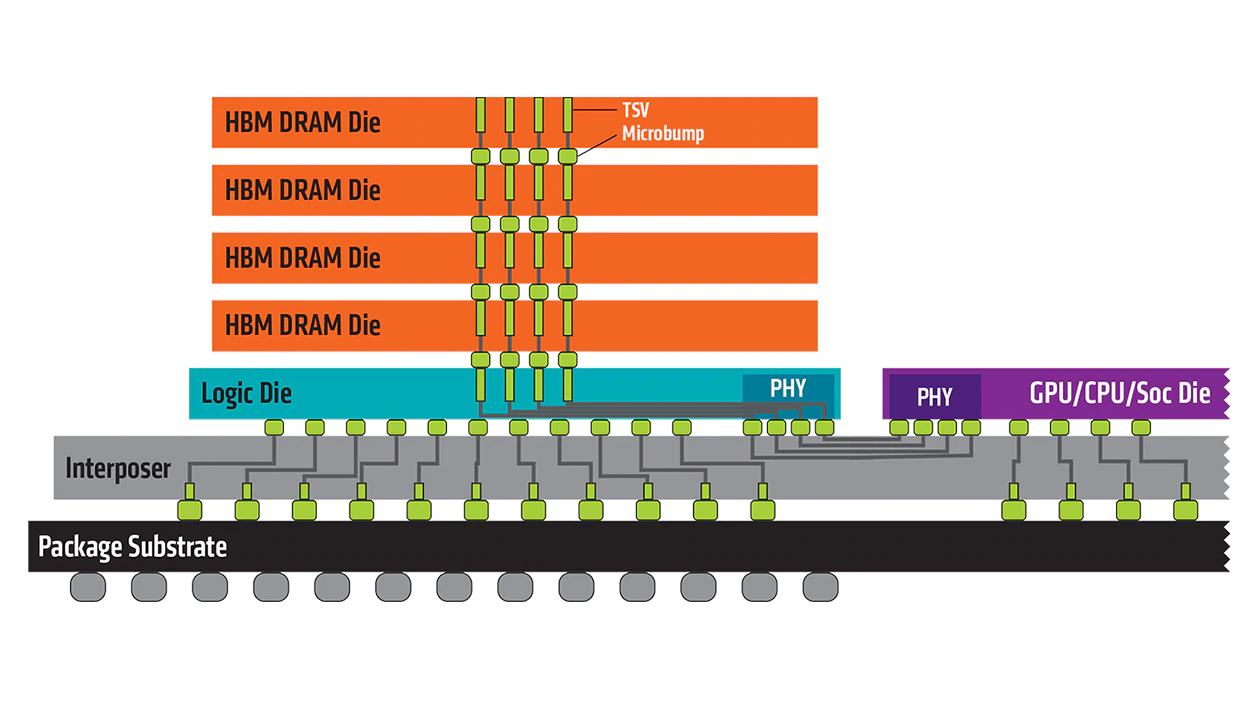
HBM (High Bandwidth Memory): DRAM을 TSV로 여러 층 쌓아 올린 것.
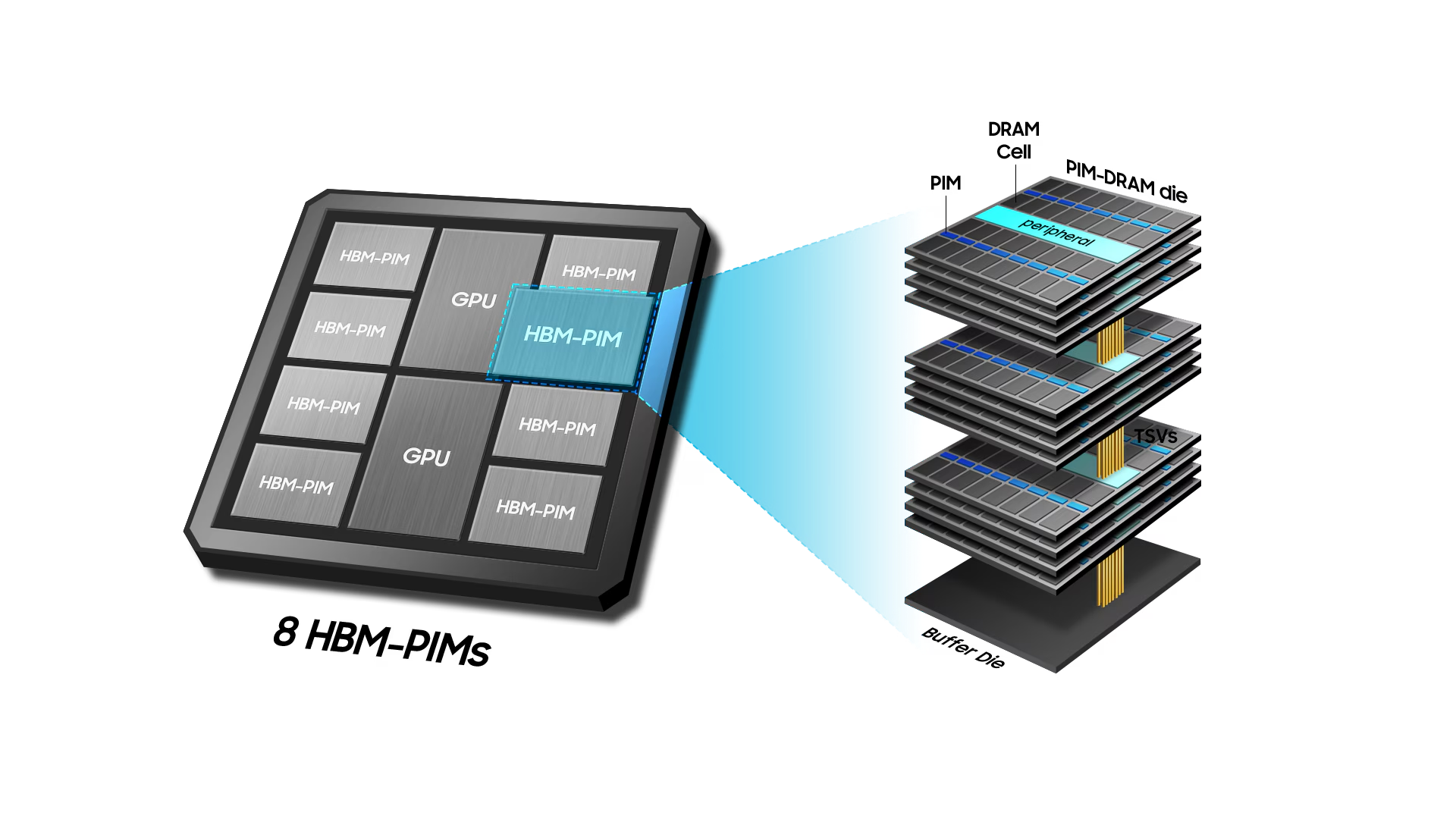
Samsung HBM-PIM: HBM 내부에 간단한 연산기(PCU)를 심어서, AI의 핵심 연산인 MAC (Multiply-Accumulate, 곱하고 더하기)을 메모리가 직접 수행합니다.
neural networks(NNS) : multiplitaion Addition cummalation (MAC)
HMC(hybrid memory cube): HBM + logic layer
2. Static power (대기전력)
트랜지스터가 꺼져() 있을 때도 새어 나가는 누설 전류(Leakage Current) 문제입니다.
① 수식 및 특징
미세 공정의 역설: 트랜지스터 크기가 작아질수록 절연막이 얇아져서 Leakage Current는 오히려 증가합니다.
② 해결책 1: Power Gating (Sleep Transistor)
개념: 수도꼭지를 잠그듯 전원 공급 자체를 차단하는 스위치를 답니다.
Sleep Transistor: 회로와 전원(Vdd) 사이에 High-Vth(문턱 전압이 높은) PMOS 스위치를 답니다. 평소엔 켜두다가, 쉴 때는 이 스위치를 꺼버려서(Broken circuit) 누설 전류 경로를 차단합니다. (필기의 "p mos will be broken"은 물리적으로 부서진다는 게 아니라, 회로 연결을 끊는다(Open switch)는 뜻입니다.)
③ 해결책 2: Non-Volatile Memory (비휘발성 메모리)
전원을 꺼도 데이터가 날아가지 않으므로, 대기 전력(Refresh Power)이 0입니다.
-
STT-MRAM (MTJ 소자):
자석의 N극/S극 방향을 이용.
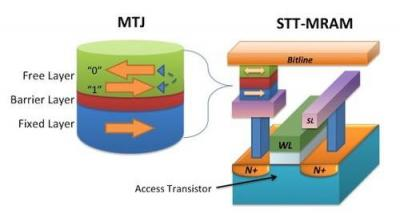
Free Layer와 Fixed Layer의 자화 방향이 같으면(Parallel) 0 (저항 낮음), 다르면(Anti-Parallel) 1 (저항 높음). -
ReRAM (Resistive RAM):
물질의 저항 변화를 이용.
Analog Computing: (옴의 법칙)을 이용해, 메모리 자체에서 AI의 가중치 곱셈()을 아날로그 방식으로 수행 가능.
3. Cost of IC
silicon crystal
wafer
die
chip
Floor of an Intel Core i7
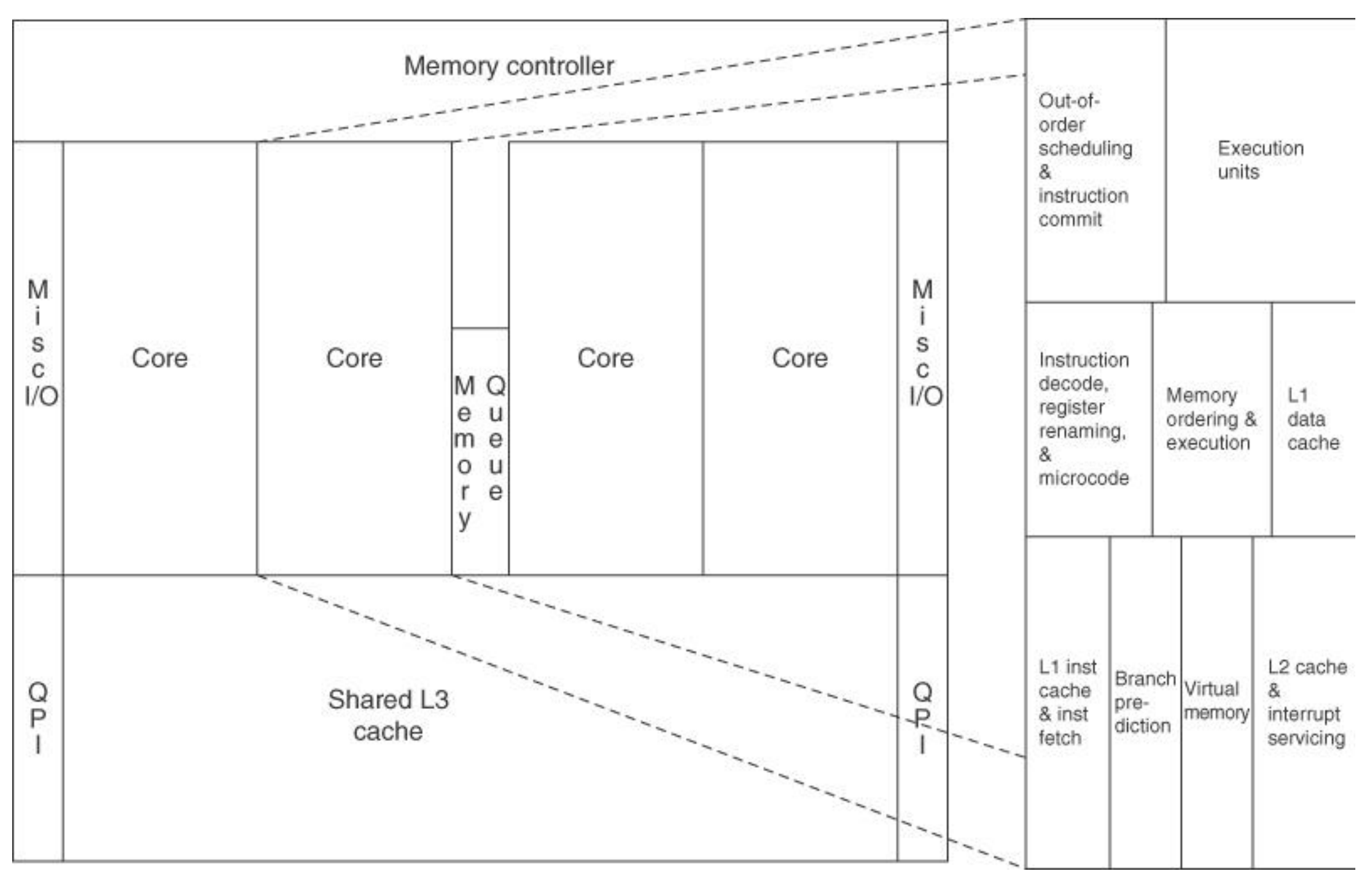
-
Cost of IC: (die + packaging + test) / final test yield
-
Cost of die: cost of wafer /(dies per wafer x die yield)
① Dies per wafer (DPW)
웨이퍼는 원형()인데 칩은 사각형이라, 가장자리(Edge)에 남는 부분은 버려야 합니다.
- 앞항: 전체 웨이퍼 면적 / 칩 면적 (이상적인 개수)
- 뒷항: 가장자리에 짤려서 버리는 칩 개수 보정치
② Die Yield (수율)
결함(Defect)이 뭉쳐서 발생한다고 가정하는 Negative Binomial 모델입니다. 교수님이 숙제에 쓰라고 한 공식입니다.
: 공정의 복잡도(Complexity factor). 보통 4.0 사용.
Good Die
정상 칩 개수= DPW x Yield
Exercise
Find the number of dies per 30cm(dimeter) wafer for a die that is 1.5 cm on a side
Wafer Diameter (): 30cm (= 300mm)
Die side: 1.5cm
Die Area:
300mm 웨이퍼에 1.5cm 칩이라면 위 계산대로 약 269개가 나옵니다. (반도체 칩 개수는 무조건 내림(Floor) 처리해서 정수(Integer)로 답해야 합니다.)
alpha is usually 4 부분, 값이 클수록 수율이 좋을까요, 나쁠까요?
- 가 무한대로 가면 (단순 지수 분포)가 됩니다.
- 가 작을수록 결함이 한곳에 뭉쳐(Clustered) 있다는 뜻이고, 이는 오히려 수율에 유리합니다. (불량이 한 칩에 몰빵되면 나머지 칩은 사니까요!)
