Forwarding (Bypassing) 개념
"어차피 ADD의 덧셈 결과는 EX 단계가 끝나면 이미 계산되어 나오잖아? 굳이 WB까지 가서 레지스터에 썼다가 다시 읽어올 필요 없이, 방금 나온 따끈따끈한 결과를 다음 명령어의 ALU 입력으로 직통으로 쏴주자!"
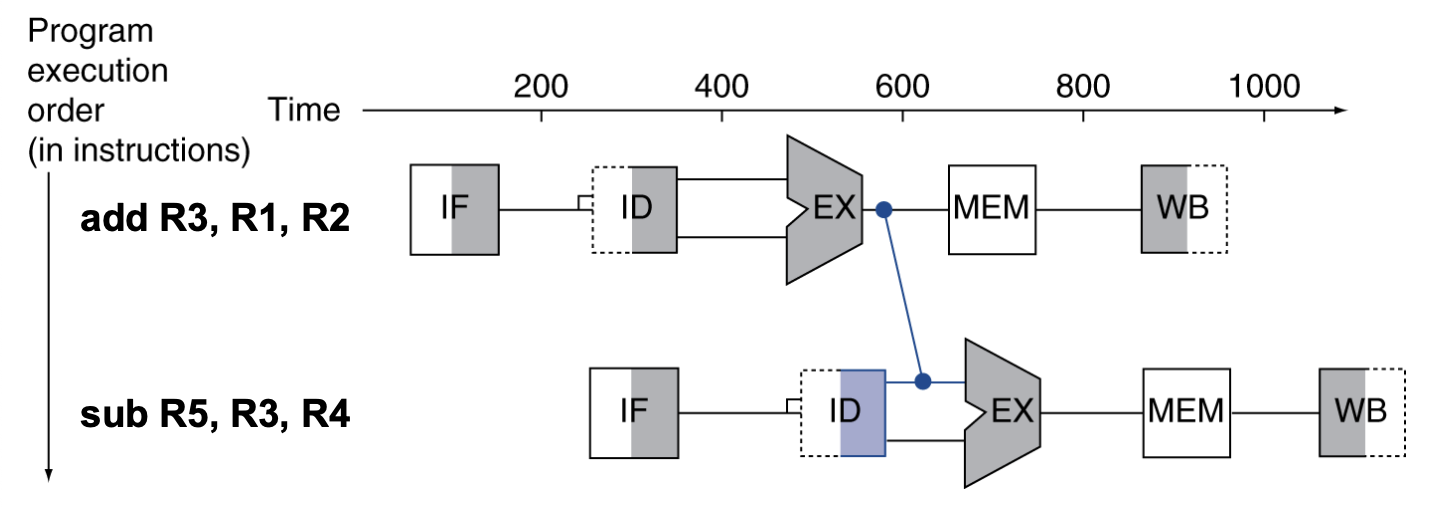
이것이 Forwarding입니다. 이를 위해 데이터패스(Datapath)에 새로운 선(Extra connections)과 멀티플렉서(MUX)를 추가합니다. 올려주신 이미지의 파란색 선이 바로 이 직통 연결선입니다.
2. "rs, rt, rd?

Forwarding Unit(전방 전달 유닛)이라는 하드웨어가 "어? 지금 쏴줘야겠다!"라고 판단하려면, 명령어의 어느 레지스터가 겹치는지 알아야 합니다. MIPS 명령어의 32비트 포맷을 쪼개면 나오는 각 구역의 이름입니다.
- rs (Register Source 1): 첫 번째 재료 레지스터.
- rt (Register Target / Source 2): 두 번째 재료 (또는 목적지) 레지스터.
- rd (Register Destination): 결과가 최종적으로 저장될 목적지 레지스터 (R-format에서 사용).
Forwarding 조건의 논리: "앞 명령어의 목적지(rd)가 내 명령어의 재료(rs나 rt)랑 똑같네? 그럼 레지스터에서 읽지 말고(Stall 하지 말고) 앞에서 계산된 거 바로 당겨와!"
1. Forwarding Unit의 위치와 역할
Forwarding Unit은 파이프라인의 EX (Execution, 실행) 단계에 딱 버티고 서 있습니다.
이 유닛의 유일한 목적은 ALU(산술논리연산장치)로 들어가는 두 개의 입력값을 원래 길(레지스터에서 온 값)로 보낼지, 아니면 지름길(앞 명령어에서 계산된 값)로 보낼지 결정하는 것입니다.
이 선택을 위해 ALU 앞에는 여러 갈래의 길을 하나로 골라주는 스위치인 MUX (Multiplexer, 멀티플렉서)가 두 개(위쪽 입력용, 아래쪽 입력용) 설치됩니다.
2. Forwarding Unit의 입력 (어떤 정보를 감시하는가?)
교통 정리를 하려면 앞뒤 차들의 번호판을 확인해야겠죠? Forwarding Unit은 다음 3가지 위치에서 파이프라인 레지스터의 정보(번호판)를 실시간으로 감시합니다.
- ID/EX 레지스터 (현재 내 명령어):
rs (첫 번째 재료 레지스터 번호)
rt (두 번째 재료 레지스터 번호)
- EX/MEM 레지스터 (바로 앞 명령어 - 1사이클 차이):
rd (결과를 저장할 목적지 레지스터 번호)
RegWrite 신호 (이 명령어가 진짜로 레지스터에 값을 쓰는 명령어가 맞는지 확인)
- MEM/WB 레지스터 (두 칸 앞 명령어 - 2사이클 차이):
rd (결과를 저장할 목적지 레지스터 번호)
RegWrite 신호
3. Forwarding Unit의 출력 (어떻게 조종하는가?)
정보를 다 모았다면, ALU 앞에 있는 두 개의 MUX에게 조종 신호(Control Signal)를 보냅니다.
- ForwardA 신호: ALU의 위쪽 입력(보통 rs 자리)을 고릅니다.
- ForwardB 신호: ALU의 아래쪽 입력(보통 rt 자리)을 고릅니다.
MUX의 선택지 (예: ForwardA의 경우):
- 00: 지름길 안 씀. (원래대로 레지스터 파일에서 읽어온 정상적인 값을 쓴다)
- 10: EX 해저드 발생! (바로 앞 명령어의 EX/MEM 파이프라인 레지스터에서 값을 당겨온다)
- 01: MEM 해저드 발생! (두 칸 앞 명령어의 MEM/WB 파이프라인 레지스터에서 값을 당겨온다)
3.Forwarding이 적용된 다이어그램 그리기
ADD R1, R2, R3 // Writes to R1
SUB R4, R1, R5 // Reads R1 (Forward from ADD's EX/MEM)
AND R6, R1, R7 // Reads R1 (Forward from ADD's MEM/WB)
OR R8, R1, R9 // Reads R1 (Half-clock register read)
XOR R10, R1, R11 // Reads R1 (Normal read)
시험 꿀팁 (화살표 그리기):
1. ADD의 EX 끝부분에서 SUB의 EX 시작부분으로 화살표를 그립니다. (EX to EX Forwarding)
2. ADD의 MEM 끝부분에서 AND의 EX 시작부분으로 화살표를 그립니다. (MEM to EX Forwarding)
3. OR는 이전과 동일하게 반 클럭(Half-clock) 규칙으로 레지스터에서 안전하게 읽습니다.
4. Load-Use Data Hazard
"Can't forward backward in time! (시간을 거슬러 포워딩할 순 없다!)"가 핵심입니다. Forwarding은 만능이 아닙니다.
참고
Addressing Modes
1. Register //ADD R4, R3 (R4 = R4 + R3)
2. Immediate //ADDI R1, R2, #8 (R1 = R2 + 8)
3. Register indirect //ADD R4, (R1), R4 = R4 + Memory[R1]
4. Displacement //LD R4, 100(R1) (Address = R1 + 100) 로 찾아가서 데이터를 꺼낸다음 R4에 저장해라
5. Indexed // ADD R3, (R1+R2)/ Address = R1 + R2, R3 = R3 + Memory[Address]
6. Direct or Absolute // ADD R1/ (1001) Address = 1001, R1 = R1 + Memory[1001]LD R1, 20(R2) // Reads from memory (Data ready AFTER MEM stage)
SUB R4, R1, R3 // Needs R1 AT EX stage
-
문제점: LD 명령어는 데이터를 MEM 단계가 끝나야 메모리에서 가져옵니다 (CC4 끝). 그런데 SUB는 덧셈을 해야 하니까 EX 단계 시작할 때 데이터가 필요합니다.
-
결론: CC4 시작할 때 데이터가 필요한데 CC4가 끝나야 데이터가 나오니, 타임머신이 없는 이상 방법이 없습니다. 따라서 Load 명령어 바로 다음에 그 데이터를 쓰는 명령어가 오면, 무조건 1사이클의 Stall(Bubble)이 발생합니다. 이후 CC5로 넘어가면 Forwarding(MEM to EX)으로 받아옵니다.
5. Double Hazard (이중 해저드)
ADD R1, R1, R2 // (A)
ADD R1, R1, R3 // (B)
ADD R1, R1, R4 // (C)명령어 (C)가 EX 단계에서 R1을 쓰려고 보니, (A)도 R1을 뱉어내고 (B)도 R1을 뱉어냅니다. Forwarding Unit에 두 군데서 동시에 데이터가 날아오는 상황입니다.
누구의 데이터를 받아야 할까요? 당연히 프로그램의 순서상 "가장 최근에 업데이트된 데이터(The most recent)", 즉 바로 앞의 명령어 (B)의 데이터를 받아야 합니다.
따라서 하드웨어를 설계할 때 "EX 해저드와 MEM 해저드가 동시에 발생하면, EX 해저드(가장 최근)를 우선시한다"는 조건을 걸어둡니다.
Practice
LD R2, 0(R1) // Load data from memory address R1+0 into R2
LD R3, 4(R1) // Load data from memory address R1+4 into R3
ADD R4, R2, R3 // R4 = R2 + R3 (Needs R2 from LD, and R3 from LD)
ST R4, 12(R1) // Store R4 to memory address R1+12 (Needs R4 from ADD)
LD R5, 8(R1) // Load data from memory address R1+8 into R5
ADD R6, R2, R5 // R6 = R2 + R5 (Needs R5 from LD)
ST R6, 16(R1) // Store R6 to memory address R1+16 (Needs R6 from ADD)case 1: without Forwarding

- ADD R4: R3를 LD R3가 CC6에 저장(W)하므로, 그때까지 기다렸다가 CC6에 해독(D)을 완료합니다.
- ST R4: 앞선 ADD R4가 값을 CC9에 저장(W)하므로, CC9까지 길게 기다렸다가 해독(D)을 완료합니다.
- ADD R6: R5를 LD R5가 CC13에 저장(W)하므로, CC13에 해독(D)을 완료합니다.
- ST R6: 앞선 ADD R6가 값을 CC16에 저장(W)하므로, CC16에 해독(D)을 완료합니다.
- 결과: 엄청난 병목현상으로 인해 총 19 사이클이 소요됩니다.
case 2: with forwarding

with Forwarding 일땐 Decode는 상관없이 가능하다
-
ADD R4 (Load-Use Hazard): 바로 앞 LD R3가 가져오는 데이터를 연산(X)에 써야 합니다. LD는 M 단계(CC5)가 끝나야 데이터가 나오므로, ADD는 어쩔 수 없이 CC5에서 1사이클 쉬고(S), CC6의 X 단계로 포워딩을 받습니다.
-
ST R4 (스톨 없음): 여기서 교수님들이 많이 내는 함정이 있습니다! ADD 다음에 ST가 올 때는 추가 스톨이 필요 없습니다. 왜냐하면 ST는 저장할 데이터(R4)가 EX 단계가 아니라 MEM 단계(CC8)에서 필요하기 때문입니다. ADD가 앞서 계산을 다 끝내놨기 때문에 여유롭게 포워딩을 받습니다. (표에서 S가 있는 이유는 데이터 충돌 때문이 아니라, 앞차 ADD가 멈추면서 기차놀이처럼 밀려난 구조적 스톨입니다.)
-
ADD R6 (Load-Use Hazard): 역시 바로 앞 LD R5가 가져오는 데이터가 필요하므로, CC9에서 1사이클 쉬고(S), CC10의 X 단계로 포워딩 받습니다.
-
결과: 19 사이클이 걸리던 코드가 13 사이클로 대폭 단축되었습니다!
Load-Use Hazard:
일반적인 덧셈(ADD) 명령어는 EX(실행) 단계가 끝나면 결과가 나옵니다. 하지만 메모리에서 데이터를 가져오는 LD (또는 LW) 명령어는 MEM (메모리 접근) 단계가 완전히 끝나야만 비로소 진짜 데이터가 손에 들어옵니다.
