1. Pipelined control
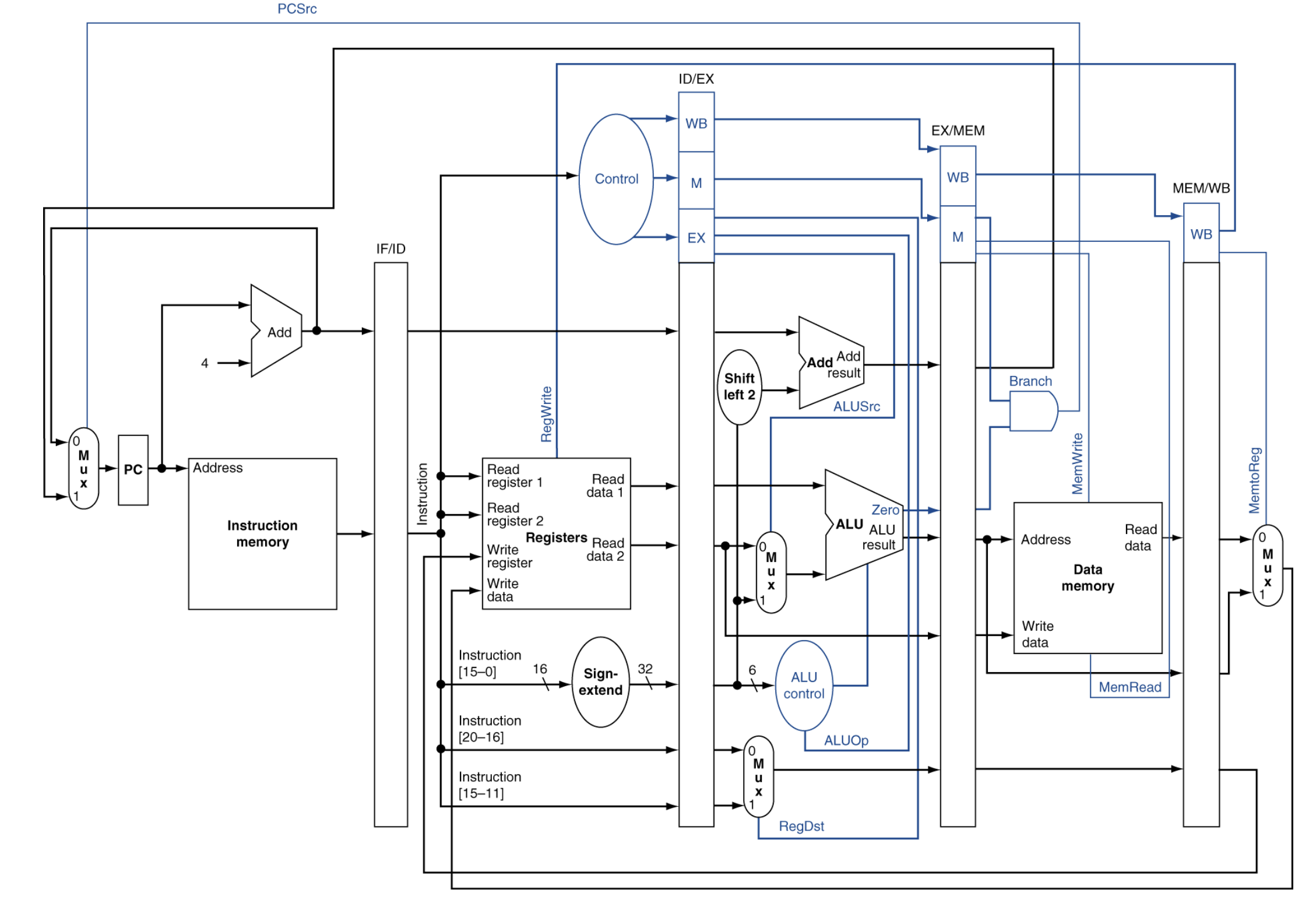
control signal: Blue
data path: Black

2. CPI 와 Fill-up Time
파이프라인의 궁극적인 목표는
"매 클럭마다 명령어 1개씩을 끝마치는 것(Ideal CPI = 1)"입니다.
수식 분석:
- 의미: 처음 파이프라인이 텅 비어있을 때는 첫 번째 명령어가 5단계(IF-ID-EX-MEM-WB)를 모두 통과할 때까지 4번의 빈 클럭(Fill-up time, )이 필요합니다.
- 결론: 하지만 명령어 개수(Instruction Count, IC)가 100개, 1,000개, 무한대로 늘어나면, 초반에 낭비한 4사이클은 티도 안 나게 됩니다. 따라서 명령어가 무한히 많다면 파이프라인의 CPI는 1에 수렴합니다.
, (IC를 무한대로하면) == 1 에 가까워진다
3. Pipeline Speedup
- Goal of pipelining is to increase throughput – number of instructions completed per clock cycle
- Ideally this should lead to throughput of one
instruction per clock cycle - In ideally balanced pipeline with n stages:
Speedup = n
Pipelining increases throughput, reduces the average execution time per instruction
It does not reduce the time needed to execute each instruction
Throughput (처리량) vs Latency (지연 시간):
세탁(30분), 건조(30분), 개기(30분) 코스가 있다고 가정해 봅시다.
파이프라이닝을 하더라도 내 옷 한 벌이 완성되는 데 걸리는 시간(Latency)은 여전히 1시간 30분입니다.
하지만 세탁기가 쉬지 않고 돌아가기 때문에, 전체적으로 보면
**30분마다 옷 한 벌씩이 완성되어 나오는 것(Throughput 증가)**입니다.
오히려 개별 시간은 늘어난다: 실제 하드웨어에서는 각 단계 사이에 '파이프라인 레지스터'를 거쳐야 하므로,
데이터를 넘겨주는 딜레이(Overhead) 때문에 명령어 하나가 통과하는 총시간은 아주 살짝 더 길어집니다.4. 성능 비교: Single vs. Pipelined vs. Unpipelined
IF:1, ID:0.5, EX:1, MEM:0.5, WB:1
Single-cycle Datapath (단일 사이클)
명령어 하나가 끝날 때까지 클럭이 기다려줘야 합니다.
가장 오래 걸리는 명령어(예: 4만큼의 시간이 필요한 Load)에 클럭을 맞춰야 하므로, 클럭 주기(Clock Cycle Time, CCT)는 4가 됩니다.
Pipelined Datapath (파이프라인)
클럭 주기는 가장 느린 단계(The slowest stage)에 맞춰집니다. (이 예시에서는 IF, EX, WB가 1이므로 CCT = 1이 됩니다.)
속도 향상 계산:
주의: 단계가 5개라고 무조건 5배 빨라지는 게 아닙니다. 단계별 시간(0.5, 1 등)이 불균형(Unbalanced)하기 때문에, 가장 긴 '1'에 클럭을 맞추다 보니 4배만 빨라진 것입니다.
Multi-cycle Unpipelined (다중 사이클)
명령어마다 필요한 단계까지만 쓰고 끝냅니다. (ALU는 4사이클, Branch는 3사이클 등). 따라서 전체 평균 CPI는 5보다 작아집니다.
condition
- balanced pipelined
- ideal pipelin = no pipeline harzardas
5. MIPS ISA designed for pipelining
왜 MIPS는 파이프라이닝을 위해 태어났는가?
Intel의 x86(CISC)과 비교해 보면 MIPS(RISC)의 위대함이 드러납니다.
모든 명령어가 32비트 고정: IF 단계에서 "어디까지 읽어야 하나?" 고민할 필요 없이 무조건 4바이트씩 뚝뚝 끊어 읽으면 됩니다. (x86은 1~17바이트로 들쭉날쭉해서 IF가 지옥입니다.)
단순한 포맷: ID 단계에서 명령어를 해독하는 동시에 레지스터를 미리 읽어올 수 있습니다.
Load/Store 구조: 3단계(EX)에서 주소만 계산하고, 4단계(MEM)에서 메모리에 접근하는 규칙적인 박자를 만들어냅니다.
6. Pipeline Hazards
완벽해 보이는 파이프라인의 발목을 잡는 3가지 장애물입니다. 이때 하드웨어는 파이프라인을 잠시 멈추는 Stall (또는 Bubble)을 발생시킵니다. 첨부하신 두 번째 이미지가 바로 이 Stall이 발생한 다이어그램입니다.
-
Structure Hazard (구조적 해저드): 하드웨어 자원이 부족해서 발생. (예: 메모리가 1개뿐인데, 1번 명령어가 MEM 단계에서 메모리를 쓰고 있으면 4번 명령어가 IF 단계에서 메모리를 읽지 못하고 기다려야 함)
-
Data Hazard (데이터 해저드): 앞의 명령어가 계산 중인 결과를 뒤의 명령어가 바로 가져다 써야 할 때 발생.
-
Control Hazard (제어 해저드): Branch 명령어 때문에 다음에 무얼 실행할지 몰라서 발생.
Hazards may make it necessary to stall (bubble)
the pipeline:

- Instruction A and all subsequent instructions are delayed until the hazard resolves
해석: 해저드에 걸린 명령어 A와, 그 뒤를 따라 들어오던 새로운(더 늦게 들어온) 명령어들은 모두 제자리에 멈춰야(Stall) 합니다.
이유: 앞차가 막혔는데 뒤차가 계속 달리면 연쇄 추돌이 일어나겠죠? 파이프라인 레지스터의 값이 덮어씌워지는 것을 막기 위해 뒤쪽 파이프라인의 진행을 일시 정지시킵니다.
- All previous instructions proceed with execution, otherwise hazard will never clear
하지만 명령어 A보다 먼저 들어와서 앞서가고 있던(더 오래된) 명령어들은 멈추지 않고 계속 실행되어야 합니다.
이유: 앞서가던 명령어들이 메모리나 레지스터에 값을 다 써줘야(Write-back) 지금 걸려있는 해저드(예: 데이터 부족)가 해결되기 때문입니다. 만약 전체를 다 멈춰버리면 영원히 해저드가 풀리지 않는 데드락(Deadlock)에 빠집니다.
1. Structure Hazards
• Case when we have instruction and data stored in
the same memory, with only one memory port

명령어가 메모리를 쓰는 단계는 2번 있습니다.
-
IF (Instruction Fetch): 명령어를 읽어올 때
-
MEM (Memory Access): Load/Store 명령어일 때 데이터를 읽거나 쓸 때
- 만약 명령어 1이 Load 명령어라서 4번째 클럭에서 MEM 단계에 진입해 메모리를 뒤지고 있다고 가정해 봅시다.
- 4번째 클럭에서 새롭게 파이프라인에 진입하려는 명령어 4는 IF 단계를 수행하기 위해 메모리에서 명령어를 읽어와야 합니다.
- 충돌! 메모리로 들어가는 문(Port)이 하나뿐인데, 명령어 1과 명령어 4가 동시에 메모리를 쓰겠다고 싸웁니다.
- 해결: 항상 더 먼저 들어온 명령어 1에게 우선권이 있습니다. 따라서 명령어 4는 한 클럭 Stall(대기) 해야 합니다.
Performance Degradation Due to Hazards
IC, CCT는 같거나 비슷하다, 관건은 CPI이다.
(분자): 파이프라인 단계 수입니다.
(예: 5단계면 최고 속도 향상치는 5배입니다.)
(분모): 해저드 때문에 발생하는 페널티입니다.
예시: 5단계 파이프라인()에서 해저드 때문에 명령어 1개당 평균 0.5사이클씩 대기(Stall)해야 한다고 칩시다.즉, 원래 5배 빨라져야 할 파이프라인이 해저드 때문에 3.33배밖에 빨라지지 못한 것입니다.
Example
Suppose that data references constitute 40% of the mix, and that the ideal CPI of the pipelined
processor (if we didn’t have the hazard) is 1. Assume that the processor with the structural hazard (data and instructions are stored in the same memory) has a clock rate that is 1.05 times higher than the clock rate of the processor where we avoid the hazard. Is the pipeline with or without structural hazard faster, and by how
much? (1+0.4x1)/(1x1.05)
이 문제는 "구조적 해저드를 없애려고 하드웨어(메모리 2개)를 복잡하게 만들면 클럭이 느려지는데, 과연 그게 이득일까?"를 묻는 수식 계산 문제입니다.
상황 조건:
- Load/Store 연산 비율 = 전체의 40% (0.4)
- 이상적인
Design A: 해저드가 있는 단순한 CPU (단일 메모리)
- 메모리가 1개라 Load/Store(40%)를 할 때마다 명령어가 겹쳐서 1사이클씩 Stall이 발생합니다.
- 대신 회로가 단순해서 클럭이 빠릅니다. 속도를 라고 하면, 주기는 입니다.
Design B: 해저드가 없는 복잡한 CPU (메모리 2개 분리)
- Stall이 없으므로 입니다.
- 하지만 회로가 복잡해져서 Design A보다 클럭이 1.05배 느립니다. 즉, 주기가 이라고 가정합니다.
성능 비교 (누가 더 빠를까?):
시간 공식을 써서 A의 시간과 B의 시간을 나눕니다. (필기에 적힌 (1+0.4x1)/(1x1.05) 공식의 정체입니다.)
정답 및 결론:
계산 결과값이 1보다 크다는 것은 A(해저드 있음)가 B(해저드 없음)보다 1.33배 더 오래 걸린다는 뜻입니다. 따라서 클럭 속도가 5% 느려지더라도, 구조적 해저드를 없앤 파이프라인(Design B)이 전체적으로 1.33배 더 빠릅니다.
2. Data Hazard
레지스터 파일의 '반 클럭(Half-clock)' 동작
- WB 단계 (쓰기): 클럭의 전반부(First half)에 레지스터에 값을 씁니다.
- ID 단계 (읽기): 클럭의 후반부(Second half)에 레지스터에서 값을 읽습니다.
결론: 만약 같은 클럭 사이클(Clock Cycle, CC)에 어떤 명령어는 WB를 하고, 어떤 명령어는 ID를 한다면 충돌이 발생하지 않고 정상적으로 값을 읽어올 수 있습니다.
1. simple problem
- add R3, R1, R2
- sub R5, R3, R4
ADD R3, R1, R2 // R3 = R1 + R2 (Writes to R3)
SUB R5, R3, R4 // R5 = R3 - R4 (Reads R3, needs ADD's result)이 코드의 문제는 ADD가 R3에 값을 열심히 계산해서 넣으려고 하는데, 바로 다음 명령어인 SUB가 그 R3를 재료로 쓰려고 한다는 점입니다. SUB 명령어는 ADD가 R3에 값을 완전히 써넣을 때(WB 단계)까지 기다려야 합니다. 따라서 교수님 말씀대로 사이클 3, 4번에서 강제로 대기(Stall)하게 됩니다.

- CC3, CC4 (Stall): SUB가 해독(ID)을 하려고 보니 R3가 아직 준비 안 된 것을 깨닫고 파이프라인에 거품(Bubble)을 넣고 가만히 멈춰서 기다립니다.
- CC5 (ID): 드디어 ADD가 레지스터에 값을 씁니다(전반부). 그럼 SUB는 같은 사이클 후반부에 값을 안전하게 읽어옵니다. (반 클럭 규칙)
2. simple problem
What are the data hazards in this example? (시험나옴)
• Draw the timing information for the instructions
ADD R1, R2, R3 // Writes to R1
SUB R4, R1, R5 // Reads R1
AND R6, R1, R7 // Reads R1
OR R8, R1, R9 // Reads R1
XOR R10, R1, R11 // Reads R1
SUB의 대기: SUB는 CC3, CC4에서 ADD를 기다리느라 Stall에 걸립니다. (CC5에서 안전하게 읽음)
AND의 연쇄 대기: 앞차인 SUB가 안 가고 버티고 있으니, AND도 덩달아 파이프라인에 진입하지 못하고 CC4, CC5에서 Stall에 걸려버립니다. (CC6에서 안전하게 읽음)
