Abstract, Introduction
이 논문은 기존 하드웨어 가속기들이 겪고 있던 메모리 대역폭(Memory Bandwidth) 병목 현상을 해결하기 위해 '연산 순서' 자체를 뒤집어버린 선구적인 논문입니다.
기존 가속기들이 "어떻게 하면 SRAM과 DRAM 사이를 효율적으로 왔다 갔다 할까?"를 고민했다면, 이 논문은 "Pyramid sliding window 구조로 연산 순서를 꼬아서, 아예 DRAM에 갈 일 자체를 없애버리자"라고 접근한 점이 핵심 Novelty입니다.
기존 방식의 문제점 (Layer-by-Layer): 보통 하드웨어는 Layer 1의 연산을 모두 끝내고 그 결과물(Feature maps)을 외부 DRAM (Off-chip memory)에 저장한 뒤, 다시 불러와서 Layer 2를 시작합니다. 레이어가 깊어질수록 외부 메모리를 왔다 갔다 하는 데이터 이동(Data movement)이 너무 많아져 엄청난 전력 소모와 병목이 발생합니다.
제안하는 해결책 (Layer Fusion & Dataflow): Layer 1을 다 끝내고 넘어가는 것이 아니라, 입력 이미지의 작은 타일(Tile) 하나가 들어오면 Pyramid-shaped sliding window 구조를 이용해 해당 영역에 대한 Layer 1, Layer 2, Layer 3의 연산을 한 번에 연달아 끝내버립니다.
하드웨어적 이점 (On-chip Caching): 이렇게 연산 순서를 바꾸면, 중간에 발생하는 Intermediate data를 외부 DRAM으로 뺄 필요 없이 칩 내부의 아주 작은 SRAM (On-chip storage, 362KB)에 잠깐 캐싱해두었다가 바로 다음 레이어 연산에 쓸 수 있습니다. 결과적으로 외부 메모리 전송량을 95%나 깎아내는 기적 같은 효율을 냅니다.
Trade-offs:
이 논문이 제시한 방식은 오프칩 대역폭을 극적으로 줄여주지만, 공짜는 아닙니다. 연산 순서가 복잡한 Pyramid-shaped 형태로 꼬이게 되므로, 하드웨어 내부의 컨트롤 로직(Control Logic)과 버퍼 관리 체계가 일반적인 Layer-by-layer 구조에 비해 기하급수적으로 까다로워집니다. 또한, 이 구조를 하드웨어 언어(Verilog 등)로 쌩으로 짜는 것은 매우 어려우므로 논문에서도 C/C++ 기반의 High-level synthesis (HLS) 템플릿을 대안으로 사용했습니다.
1. Core Problem: 기존 방식의 한계 (Layer-by-Layer)
-
Traditional Approach: 기존의 CNN 가속기는 네트워크 구조를 따라 한 번에 하나의 레이어씩(One layer at a time) 연산합니다.
-
Bottleneck: Layer 1의 연산이 끝나면 그 결과물인 막대한 양의 Intermediate Feature Maps(중간 피처 맵)를 칩 내부의 SRAM에 다 담을 수 없어 Off-chip Memory(외부 DRAM)로 모두 내보내야(Write) 합니다. 그리고 Layer 2 연산을 위해 방금 쓴 데이터를 다시 그대로 읽어와야(Read) 합니다. 레이어가 깊어질수록 이 쓸데없는 Data Movement(데이터 이동)가 시스템의 전력과 성능을 다 갉아먹습니다.
2. Core Innovation: 융합 계층 설계 (Layer Fusion)
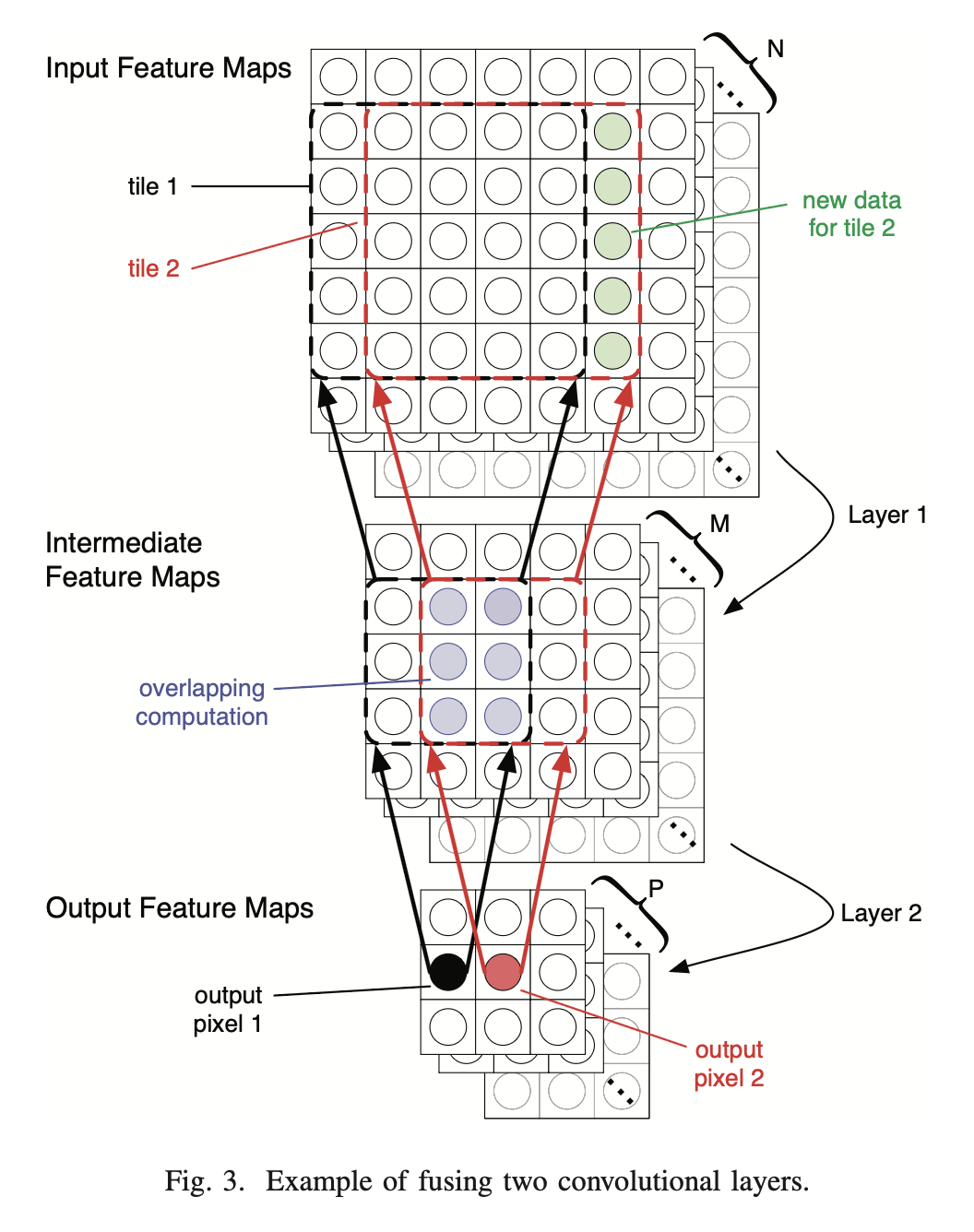
이 논문의 가장 핵심적인 기여는 연산이 진행되는 '데이터 흐름(Dataflow)'을 바꾼 것입니다.
-
Pyramid-shaped multi-layer sliding window: Layer 1을 전부 끝내고 Layer 2로 넘어가는 대신, 입력 이미지의 작은 타일(Tile) 하나가 들어오면 그 타일에 의존하는 Layer 1, Layer 2, Layer 3의 연산을 피라미드 형태로 한 번에 끝내버립니다.
-
On-chip Caching: 이렇게 연산 순서를 재조정(Restructure)하면, 인접한 레이어들 사이에서 발생하는 Intermediate data를 외부 DRAM으로 뺄 필요 없이, 칩 내부의 버퍼에 잠깐 캐싱(Caching)했다가 바로 다음 레이어 연산에 던져줄 수 있습니다.
3. Architectural Trade-offs: 재연산 vs. 재사용 (Recompute vs. Reuse)
피라미드 윈도우가 옆으로 한 칸(Stride) 슬라이딩할 때, 이전 피라미드와 필연적으로 데이터가 겹치는 영역(Overlapping computation)이 발생합니다. 하드웨어 아키텍트는 여기서 두 가지 선택의 기로에 놓입니다.
-
Recompute (재연산): 겹치는 부분을 그냥 매번 새로 다시 계산하는 방식입니다. 메모리(버퍼)는 덜 들지만, KxK 필터 연산을 계속 반복해야 하므로 산술 연산량(Arithmetic operations)이 폭발적으로 증가합니다. (AlexNet 기준 8.6배 증가)
-
Reuse (재사용): 한 번 계산한 중간 값을 버리지 않고 칩 내부 버퍼에 저장해두는 방식입니다. 이 논문이 채택한 방식으로, 추가적인 On-chip storage가 필요하지만 연산량 낭비가 없습니다.
-
Buffer Management: 이를 구현하기 위해 설계상에 이전 피라미드의 왼쪽 데이터(BL, Buffer Left)와 위쪽 데이터(BT, Buffer Top)를 보관하는 정교한 재사용 버퍼 로직(Reuse module)을 추가했습니다.
4. Hardware Implementation (FPGA & HLS)
저자들은 이 복잡한 데이터플로우를 Verilog로 직접 짜는 대신, Vivado HLS(High-Level Synthesis)를 사용하여 C++ 코드를 Xilinx Virtex-7 FPGA용 하드웨어로 합성(Synthesis)했습니다.
-
Loop Unrolling & Tiling: C++ 코드 내의 루프 변수 Tm과 Tn을 타일링(Tiling) 및 언롤링(Unrolling)하여 하드웨어 병렬성을 추출했습니다. 하드웨어의 DSP slices(곱셈/덧셈기) 개수에 맞춰 최적의 파이프라인을 구성했습니다.
-
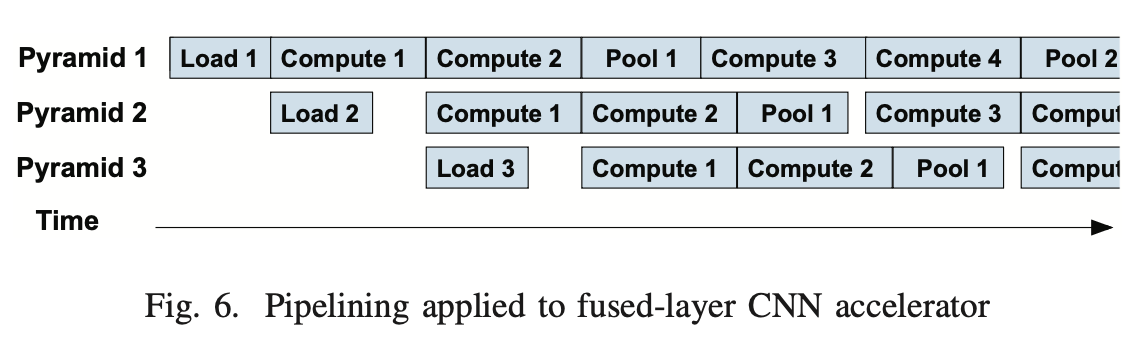
Double-buffering: 외부 메모리에서 데이터를 읽어오는 시간과 연산하는 시간을 겹치게(Overlap) 하기 위해 Double-buffering 기법을 적용해 파이프라인 효율을 극대화했습니다.
5. Experimental Results (최종 성과)
-
VGGNet-E (처음 5개 레이어 융합 기준): 기존 방식대로라면 이미지 한 장당 77MB의 오프칩 메모리 전송(Off-chip transfer)이 필요했지만, Layer Fusion을 적용한 결과 이를 3.6MB로 95% 감소시켰습니다.
-
Hardware Overhead: 이 엄청난 대역폭 절감을 얻기 위해 치른 대가는 칩 내부에 고작 362KB의 추가 BRAM(Block RAM)과 복잡해진 컨트롤 로직을 위한 약간의 DSP/LUT 증가뿐이었습니다.
