전체 요약
1. The Big Picture (논문의 핵심 의의)
이 논문의 가장 큰 가치는 단순히 알고리즘 하나, 회로 기법 하나만 건드린 것이 아니라 Algorithm (Software) Architecture (RTL) Circuit (SRAM, Voltage) 레벨을 수직적으로 관통하는 Co-design (공동 설계) 방법론을 제시했다는 점입니다.
- 목표: 정확도 손실 없이(Without compromising accuracy), 전력 제약이 극심한 IoT 및 모바일 환경에서 구동 가능한 수십 밀리와트(10s of mWs) 수준의 초저전력 DNN Accelerator 설계.
- 결과: 5단계 최적화를 통해 정확도 하락 없이 평균 8.1배의 전력 감소(Power reduction) 달성.
2. Minerva's 5-Stage Pipeline (5단계 최적화 파이프라인)
이 5단계는 시험 문제로 출제하기 가장 완벽한 구조를 가지고 있습니다. 각 단계별 하드웨어적 의미를 이해하는 것이 핵심입니다.
Stage 1: Training Space Exploration (알고리즘 베이스라인 설정)
- Keras를 이용해 최적의 Hyperparameters(레이어 수, 노드 수 등)를 찾습니다.
- 가장 중요한 개념은 Intrinsic error variation (내재적 오차 변동성)입니다. 최적화를 하드웨어에 적용할 때 발생하는 정확도 하락의 허용 범위(예: MNIST의 경우 )를 엄격하게 설정하는 기준이 됩니다.
Stage 2: Microarchitecture Design Space (아키텍처 탐색)
Aladdin 시뮬레이터를 사용해 수천 개의 하드웨어 구현 시나리오(Design Space Exploration, DSE)를 돌려봅니다.
현실적 타협점: 연산기를 무작정 병렬화(Parallelism)하면 속도는 빨라지지만, 이에 맞춰 메모리 대역폭(Memory bandwidth)을 늘리려면 SRAM을 과도하게 잘게 쪼개야(Partitioning) 해서 칩 면적(Area)이 기하급수적으로 커지는 병목을 확인하고 최적점(Pareto-optimal)을 찾습니다.
Stage 3: Data Type Quantization (양자화)
- 모든 데이터를 16-bit로 퉁치는 것이 아니라, 레이어별/신호별(입력 QX, 가중치 QW, 부분합 QP)로 필요한 최소한의 Bitwidths (정밀도)만 남깁니다.
- RTL 효과: Datapath의 폭이 줄어들고 MAC 연산기의 사이즈가 작아져 Area와 Dynamic Power가 감소합니다 (1.5배 전력 절감).
Stage 4: Selective Operation Pruning (선택적 가지치기)
- 활성화 함수(ReLU 등) 특성상 0이거나 0에 아주 가까운 작은 값(Small activities)들이 압도적으로 많다는 점을 이용합니다.
- 임계값(Threshold)을 넘지 못하는 값들은 하드웨어 단에서 Predication(조건부 실행)을 통해 연산을 스킵합니다.
- RTL 효과: 불필요한 SRAM Read를 막고, 연산기에 Clock gating을 걸어 스위칭 전력을 아낍니다 (2.0배 추가 절감).
Stage 5: SRAM Fault Mitigation (SRAM 결함 완화)
- 가속기 전력의 핵심인 SRAM Supply Voltage를 공격적으로 낮춥니다.
- 전압이 낮아져 발생하는 물리적 에러(Read faults)는 Razor double-sampling 회로로 감지(Detection)하고, 에러가 난 비트를 부호 비트(Sign bit)로 덮어씌워 0에 가깝게 만드는 Bit Masking 기법으로 완화(Mitigation)합니다.
- RTL 효과: 칩이 에러를 자체적으로 무시할 수 있게 되어, 전압을 대폭 낮출 수 있습니다 (2.7배 추가 절감).
3. Hardware Validation & Real-world Trade-offs (검증 및 현실적 한계)
이 논문이 단순 이론으로 끝나지 않는 이유는 40nm CMOS 공정 기반의 RTL Place-and-Route (P&R) 레이아웃을 통해 시뮬레이터(Aladdin)의 결과를 검증했기 때문입니다.
- Specialization vs. Flexibility: 여러 네트워크를 다 지원할 수 있도록 범용적(Programmable)으로 SRAM을 크게 만들면, 아무리 Pruning을 잘해도 켜져 있는 메모리에서 새어나가는 Leakage power (누설 전력) 때문에 특수 목적(Hardcoded ROM) 가속기보다 전력을 1.4~2.6배 더 낭비하게 됩니다.
4. Appendix: DNN Math (기본 수학 식 정리)
부록에 나온 수식은 하드웨어 연산기(MAC)가 1클럭 사이클 동안 실제로 수행하는 디지털 논리 연산의 근간입니다.
- MAC (Multiply-Accumulate) Operation: 이전 레이어의 출력값과 가중치를 곱하고 누적하는 과정입니다.
- Activation Function (활성화 함수):
MAC의 결과를 비선형 함수(예: ReLU 등)에 통과시켜 최종 뉴런의 출력값을 결정합니다.
핵심 요약
이 논문은 단순히 아키텍처 구조 하나만 바꾸는 것이 아니라, 알고리즘부터 실제 칩의 전압 제어까지 수직적으로 뚫어버린 Cross-layer Co-design의 교과서적인 논문입니다.
연구의 배경 및 동기 (The Gap):
- ML 학계: 전력을 엄청 쓰더라도(GPU 활용) 정확도(Accuracy)만 높이면 장땡.
- HW 학계: 정확도가 좀 떨어지더라도 칩 면적(Area)과 전력 소모(Power)만 극단적으로 줄이면 장땡.
- 문제점: 이 둘 사이의 타협점이 없어서, 정확도도 높으면서 모바일/IoT에 들어갈 만한 초저전력 가속기 설계가 없었습니다.
Minerva의 해결책 (3대 핵심 최적화 기법):
- Heterogeneous Data-type Quantization (양자화):
모든 레이어에 똑같이 16-bit나 8-bit를 우겨넣는 것이 아니라, 레이어별로 필요한 데이터 정밀도(Precision)를 세밀하게 다르게 쪼개어 전력을 줄입니다 (1.5배 개선). - Dynamic Operation Pruning (동적 가지치기):
연산을 진행하다가 활성화 값(Activation value)이 0에 가깝거나 너무 작아서 결과에 영향을 안 줄 것 같으면, 아예 메모리 읽기나 MAC 연산을 생략(Pruning)해버립니다 (2.0배 개선). - Fault Mitigation for Low-voltage SRAM (SRAM 전압 스케일링):
칩이 소모하는 전력을 가장 극적으로 줄이는 방법은 전압을 낮추는 것입니다. 하지만 전압을 낮추면 SRAM에서 에러(Fault)가 발생합니다. Minerva는 알고리즘 레벨에서 이 에러를 보정(Mitigation)할 수 있는 구조를 엮어, 안전하게 SRAM 구동 전압을 깎아냅니다 (2.7배 개선).
최종 결과: 정확도는 그대로 유지하면서 기준선 대비 총 8.1배의 전력 효율을 달성하여, 수십 mW 수준으로 동작하는 IoT용 초저전력 칩 설계가 가능해졌습니다.
Hardware & RTL Perspective
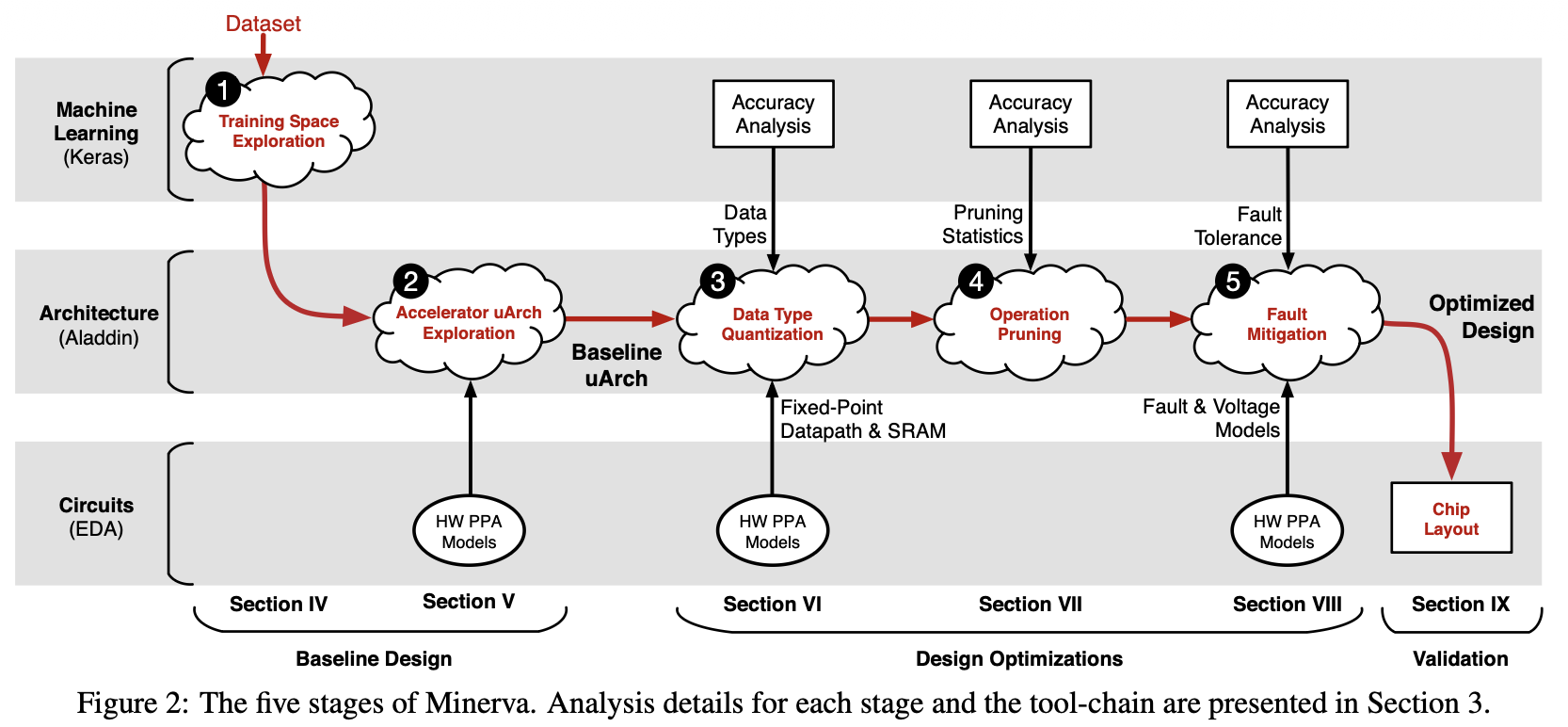
이 논문이 훌륭한 평기를 받는 이유는 소프트웨어(알고리즘)에서의 최적화가 실제 하드웨어 데이터패스(Datapath)와 로직 레벨에서 어떤 이득으로 이어지는지를 아주 현실적이고 체계적으로 증명했기 때문입니다.
Stage 1 & 2 (Baseline Setup):
무작정 최적화부터 하는 것이 아니라, Keras로 쓸만한 모델을 만들고, 현실적인 Clock frequency와 Memory bandwidth를 갖춘 마이크로아키텍처(uArch)를 기준점(Baseline)으로 잡습니다.
Stage 3 (Quantization):
알고리즘적으로 비트 수를 줄입니다. RTL 관점에서는 Datapath의 넓이(Bus width)가 줄어들고, 16x16 곱셈기가 8x8 곱셈기 등으로 작아지므로 Area와 Dynamic Power가 크게 감소합니다.
Stage 4 (Pruning):
값이 0에 가깝다면 굳이 연산하지 않고 건너뜁니다(Skip). RTL 관점에서는 불필요한 MAC 연산을 막기 위해 Clock Gating을 활용하거나, 아예 SRAM에서 데이터를 읽어오지 않도록 Read enable 신호를 제어하여 메모리 전력 소모를 억제합니다.
Stage 5 (Fault Mitigation):
SRAM에 인가되는 Voltage(Vdd)를 낮추면 전력 소모가 극적으로(제곱에 비례하여) 줄어들지만, 0과 1이 뒤집히는 물리적 에러(Bit flips)가 발생합니다. 이를 하드웨어에서 감지하고, 에러가 난 가중치를 그냥 '0'으로 처리(Rounding)해버리는 논리 회로를 추가하여 알고리즘의 강건성(Robustness)으로 에러를 덮어버립니다.
Conclusion
Specialization vs. Flexibility (특수화 vs 범용성):
Hardcoded ASIC (ROM 사용): 오직 한 가지 모델만 돌릴 수 있게 가중치를 ROM에 하드코딩하면 전력을 극도로 아낄 수 있습니다 (1.9배 추가 절감).
Programmable Accelerator (SRAM 사용): 여러 모델을 다 돌릴 수 있게 하드웨어를 넉넉하게(최댓값 기준) 만들면, 연산기가 아무리 Pruning으로 연산을 멈춰도 켜져 있는 거대한 SRAM에서 새어나가는 Leakage power(누설 전력) 때문에 전력 낭비가 커집니다
시뮬레이터의 한계와 RTL 검증 (Reality Check):
- Aladdin 같은 C/C++ 기반 시뮬레이터는 연산 코어의 PPA는 잘 맞추지만, 칩을 엮어주는 Bus interface logic(예: AXI bus)이나 실제 라우팅 오버헤드는 잡아내지 못합니다.
- 저자들은 40nm 공정으로 실제 RTL 코딩 Synthesis Place & Route까지 수행하여, 시뮬레이터 결과가 실제 하드웨어와 오차 12% 이내로 일치함을 증명했습니다. (이 부분이 이 논문의 신뢰성을 엄청나게 높여줍니다.)
기존 연구와의 차별성 (Novelty):
- Pruning: 기존엔 딱 '0'인 값만 스킵했다면, Minerva는 '0에 가까운 작은 값'도 과감히 날려버려서 최대 95%의 연산을 스킵합니다.
- Fault Tolerance: 기존 연구들은 칩에서 에러가 나면 칩마다 모델을 다시 학습(Re-training)시켜서 덮어씌우려 했습니다 (양산 관점에서는 절대 불가능한 짓). 반면 Minerva는 재학습 없이 하드웨어 로직 단에서 결함을 무시(Rounding)해버려 확장성을 확보했습니다.
