삼성 논문이 "최고 성능의 HBM에 PIM을 결합하자"는 하이엔드 전략이었다면, 이 하이닉스 논문의 핵심은 "HBM은 TSV(실리콘 관통 전극) 공정 때문에 단가가 너무 비싸니, 그래픽 카드에 널리 쓰이는 가성비 좋은 GDDR6에 PIM을 이식해서 대중적인 AI 가속기를 만들자"는 것입니다.
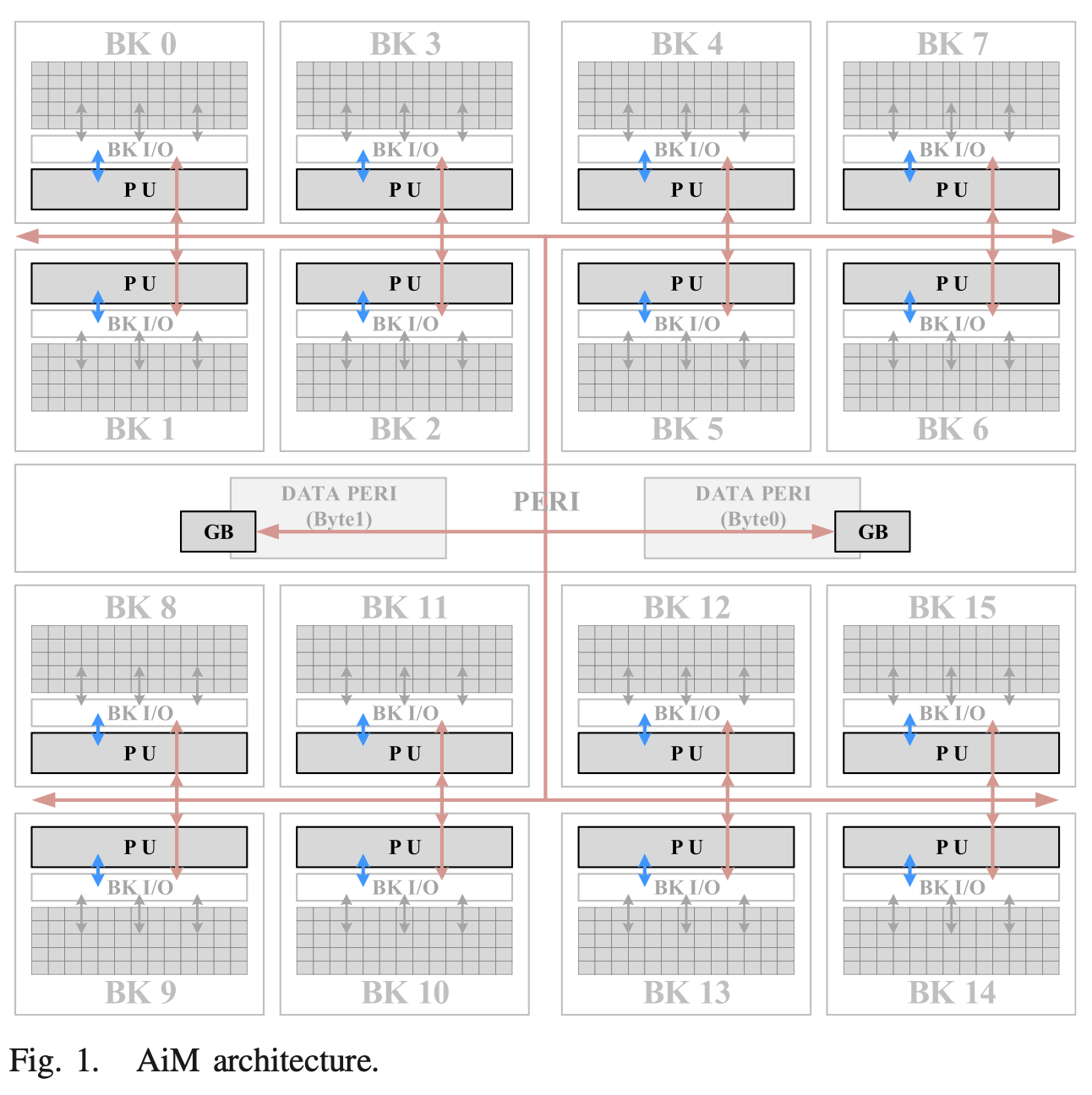
1. GDDR6 프로토콜의 확장 (Dedicated DL CMD)
CMD: command
GDDR6의 기존 표준을 해치지 않으면서 연산기를 컨트롤해야 하는 딜레마를 하이닉스는 ADM (AiM DL Mode) 비트 하나로 해결했습니다.
하이닉스 AiM 논문에서 CMD가 중요한 이유
그런데 메모리 안에 연산기(PIM/AiM)를 집어넣고 나니 문제가 생겼습니다. 기존의 읽기(RD), 쓰기(WR) CMD만으로는 메모리 내부의 덧셈기나 곱셈기를 작동시킬 방법이 없었던 것입니다.
그렇다고 칩 외부에 "계산 시작" 버튼용 물리적 핀(Pin)을 새로 뚫으면, 표준 GDDR6 규격을 위반하게 되어 상용 그래픽카드에 칩을 꽂을 수가 없습니다.
그래서 하이닉스 엔지니어들은 기존 핀 구조를 그대로 유지한 채, 신호들의 조합을 비틀어 딥러닝 전용 특수 명령어(Dedicated DL CMD set)를 새롭게 정의했습니다.
DRAM 모드 레지스터의 예약된(Reserved) 비트를 ADM으로 할당하여, 이 비트가 켜졌을 때만 딥러닝 전용 명령어(MAC, ACTAF 등)가 동작하도록 만들었습니다. 모드 스위칭 지연 시간을 최소화하여 일반 읽기/쓰기 동작과 딥러닝 연산을 매끄럽게 오갈 수 있도록 설계했습니다.
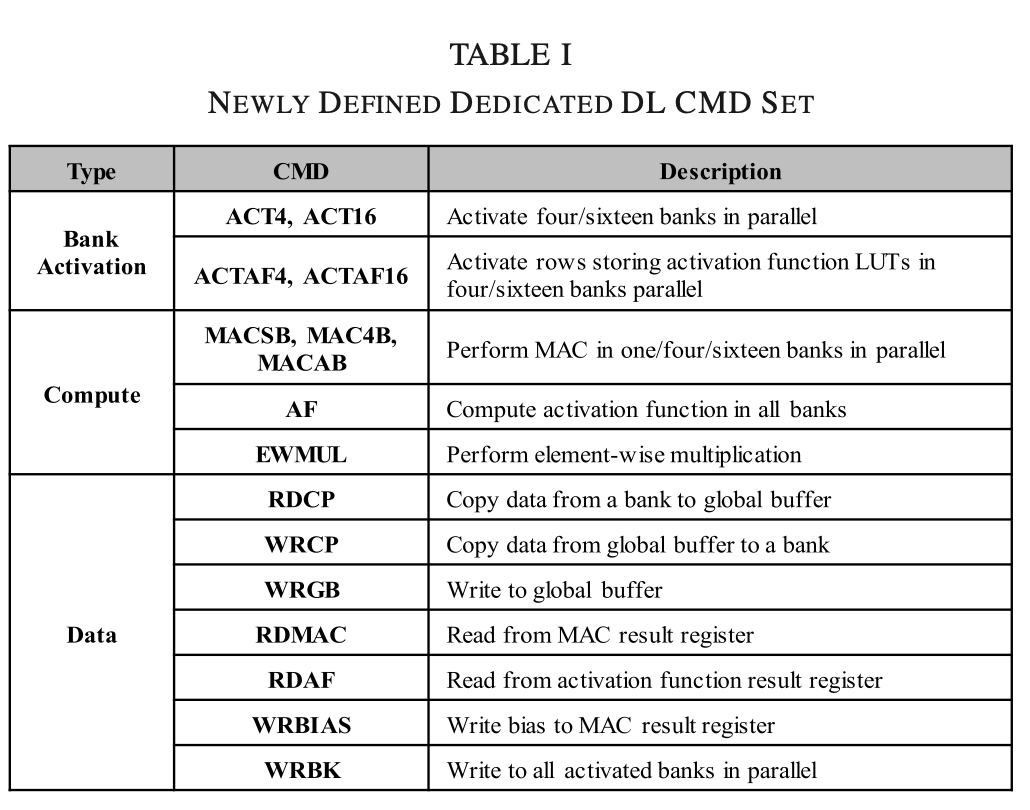
- MAC / MACAB: "데이터 밖으로 빼지 말고, 니들끼리 곱하고 더해라! (Multiply-Accumulate)"
- ACTAF: "활성화 함수(Activation Function) 쓸 거니까, 룩업 테이블(LUT) 들어있는 숨겨진 공간 열어라!"
- WRGB: "이 데이터는 모든 뱅크가 공통으로 쓸 거니까, 글로벌 버퍼(GB)에 써둬라!"
GB: Global Buffer
존재하는 근본적인 이유: 행렬 곱셈의 특성머신러닝의 핵심인 행렬-벡터 곱셈()의 데이터 흐름을 생각해 보면 GB의 존재 이유가 명확해집니다.
- Weights (): 수억 개에 달하는 엄청난 양의 가중치 데이터입니다. 너무 커서 각 DRAM 뱅크(Bank) 셀에 쪼개서 저장해 둡니다.
- Input Vector (): 이미지 픽셀 값이나 음성 데이터 같은 입력값입니다. 이 데이터는 크기가 상대적으로 작지만, 모든 가중치들과 빠짐없이 한 번씩 곱해져야 하는 '공통 재료'입니다.
만약 Global Buffer가 없다면, 16개의 뱅크에 있는 연산기(PU)들이 똑같은 Input Vector 값을 읽기 위해 외부 메모리 채널이나 자신의 뱅크를 계속해서 반복적으로 뒤져야 합니다. 이는 엄청난 전력 낭비와 지연(Latency)을 발생시킵니다.
하드웨어 동작 방식 (Data Broadcasting)
이 문제를 해결하기 위해 AiM은 다음과 같은 순서로 파이프라인을 구동합니다.
- WRGB (Write to Global Buffer) 커맨드: 연산 시작 전, 호스트 CPU가 공통으로 쓰일 Input Vector 데이터(최대 2kB)를 칩 내부의 Global Buffer에 딱 한 번만 써둡니다.
- MAC (Multiply-Accumulate) 커맨드: 16개의 뱅크에 있는 16개의 연산기(PU)들이 일제히 깨어납니다.
병렬 연산 수행:
- 각 PU는 자신의 뱅크(Local Bank)에서 고유한 Weight 데이터를 읽어옵니다.
- 동시에 Global Buffer는 저장하고 있던 Input Vector 데이터를 16개의 PU 모두에게 한 번에 쫙 뿌려줍니다 (Broadcasting).
- 각 PU는 전달받은 공통 Vector와 자신의 Weight를 곱해서 누적(Accumulate)합니다.
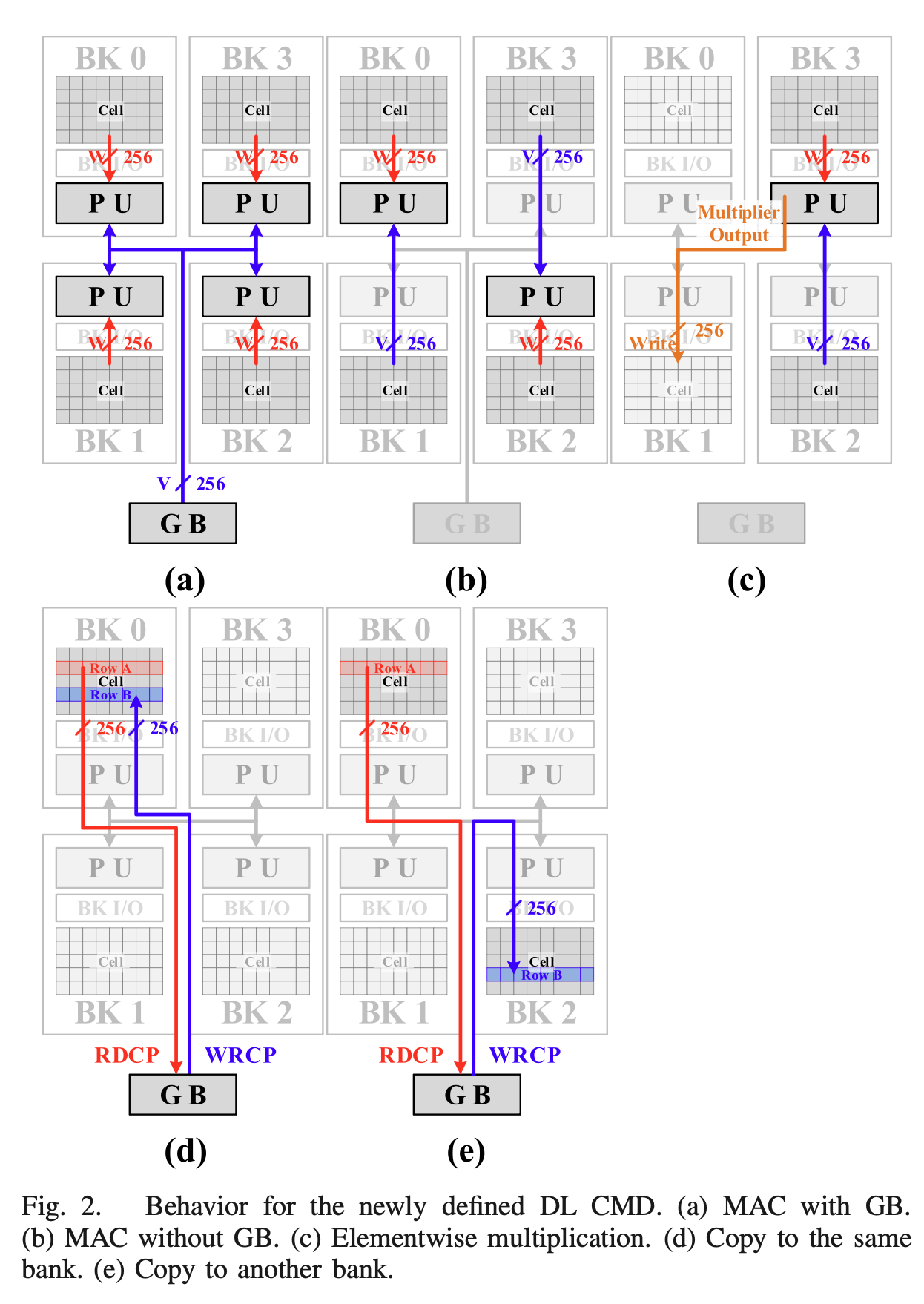
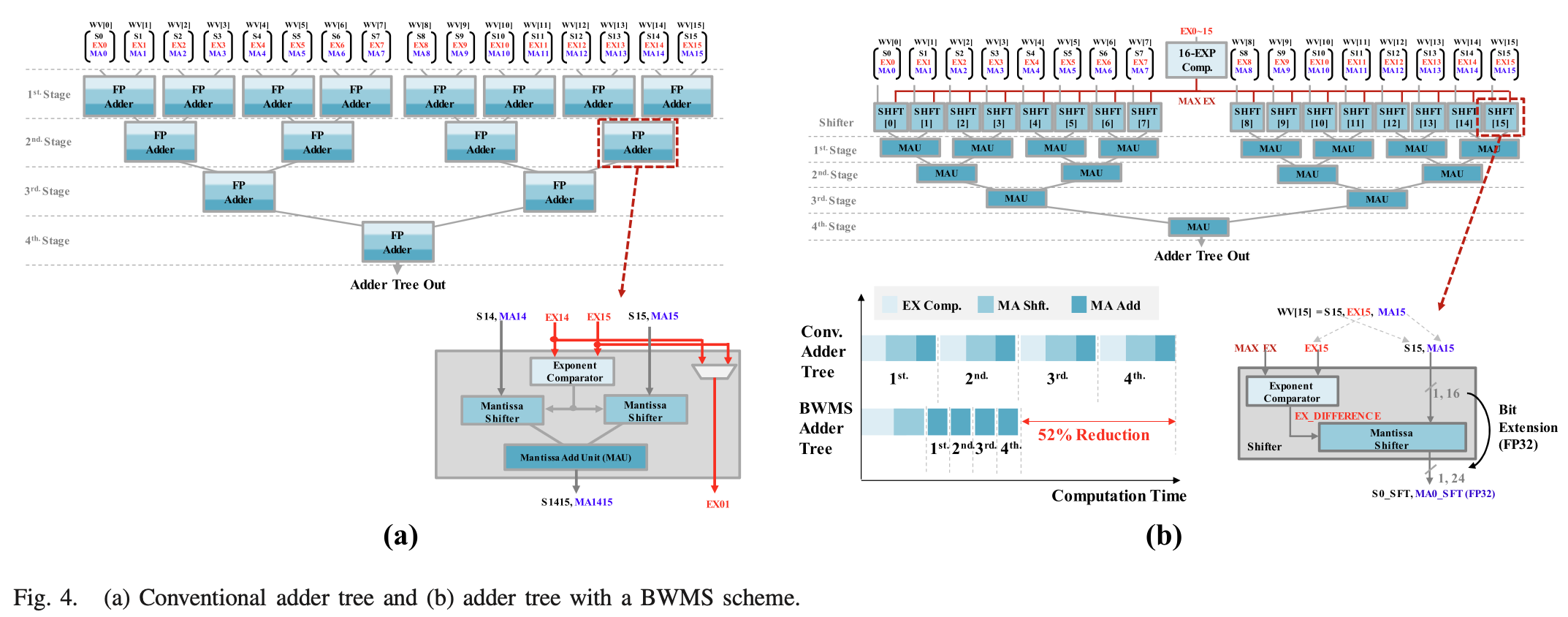
2. 하드웨어 최적화의 꽃: BWMS 기반 Adder Tree
FPGA로 MAC 유닛을 설계해 보셨다면, 부동소수점(Floating-Point) 덧셈기가 게이트 면적과 사이클을 얼마나 많이 잡아먹는지 잘 아실 겁니다. 16개의 곱셈 결과를 더하려면 일반적인 Adder Tree는 매 단(Stage)마다 지수(Exponent)를 비교하고 가수(Mantissa)를 시프트(Shift)해야 합니다.
하이닉스는 이를 BWMS (Bank-Wide Mantissa Shift)라는 기법으로 뚫어버렸습니다.
-
16-입력 지수 비교기(16-EXP comparator)가 16개의 곱셈기 출력 지수들을 비교하여 최댓값 지수를 찾습니다.
-
16개의 시프터가 이 최댓값 지수를 받아들여, 최댓값 지수와 각 곱셈기 출력 지수 사이의 차이(Difference)를 구합니다.
-
모든 시프터가 그 차이값만큼 가수를 한꺼번에 시프트합니다.
-
마지막으로, 모든 시프트 연산이 이미 완료되었기 때문에, 덧셈기 트리의 4단에 걸쳐 있는 가수 덧셈 유닛(MAU)들은 지수 비교나 가수 시프트 과정 없이 단순한 가수 덧셈만을 수행하게 됩니다.
이 구조적 혁신을 통해 Adder Tree의 면적을 75%, 전력 소모를 66%, 연산 지연 시간을 52%나 줄였습니다. 더 놀라운 것은, 이렇게 아낀 칩 면적에 전력 안정화용 커패시터(Reservoir Capacitor)를 가득 채워 넣었다는 점입니다. 그 결과 전력 부족 문제없이 DRAM의 고질적인 제약인 tFAW (Four Active Window)를 무시하고 16개 뱅크를 동시에 열어버리는(All-bank parallel ACT) 괴물 같은 대역폭을 만들어냈습니다.
3. 활성화 함수(Activation Function)의 꼼수: LUT 활용
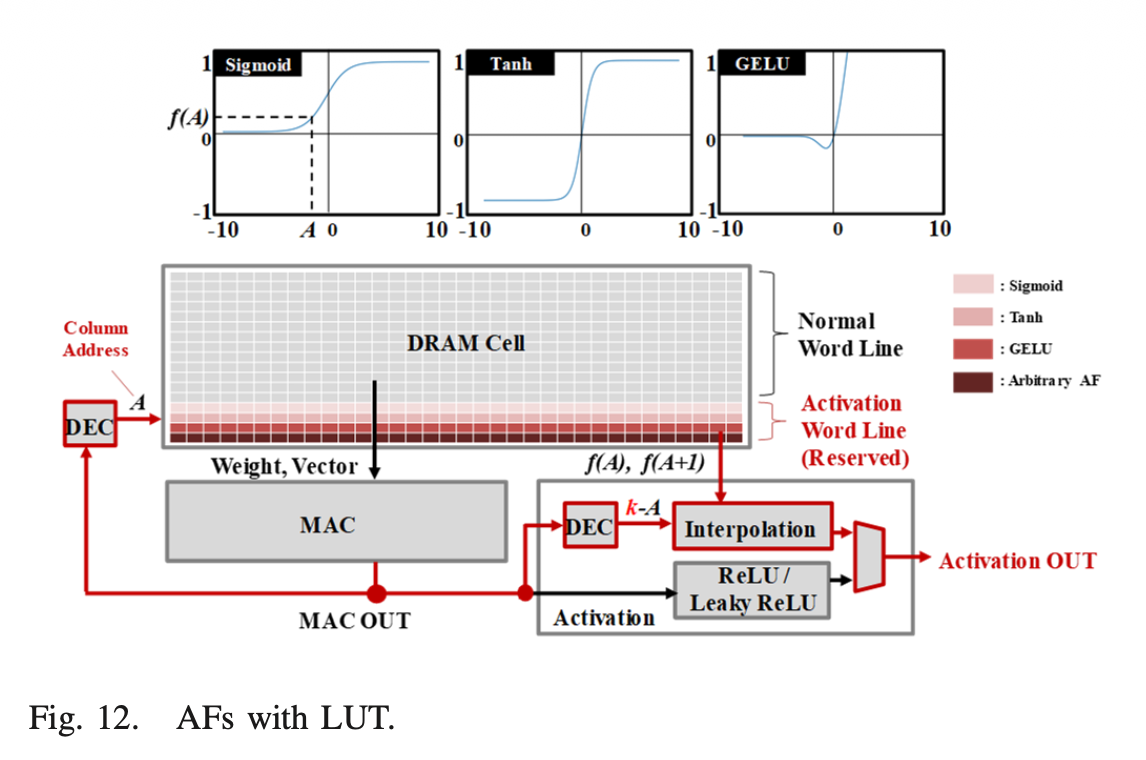
문제: ReLU 같은 단순한 함수는 로직 게이트 몇 개로 구현되지만, Sigmoid나 Tanh, GELU 같은 비선형 함수는 하드웨어로 직접 연산하기에 너무 무겁고 복잡합니다.
해결책: PIM 연산기 내부에 복잡한 수학 연산 블록을 넣는 대신, DRAM 뱅크 내부의 안 쓰는 여유 공간(Reserved Word Line)에 함수 결과값들을 표(LUT, Look-Up Table) 형태로 미리 다 구워서 적어버렸습니다.
연산 결과가 나오면 그걸 계산하는 게 아니라 메모리 주소(Column address)로 매핑해서 값을 그냥 읽어옵니다. 512개의 제한된 입력 갯수로 인한 오차는 두 값 사이의 선형 보간법(Linear Interpolation) 로직을 살짝 얹어서 24-bit fixed-point 수준의 높은 정밀도로 커버했습니다.
4. FPGA 시스템 레벨 검증
이 논문 역시 단순한 시뮬레이션에 그치지 않고, 직접 칩을 구워내어(Fabrication) Xilinx UltraScale+ FPGA 보드에 올려 검증했습니다. PCIe Gen3로 호스트 CPU와 연결하고, FPGA 내부에 AiM 컨트롤러와 DMA를 직접 구현했습니다.
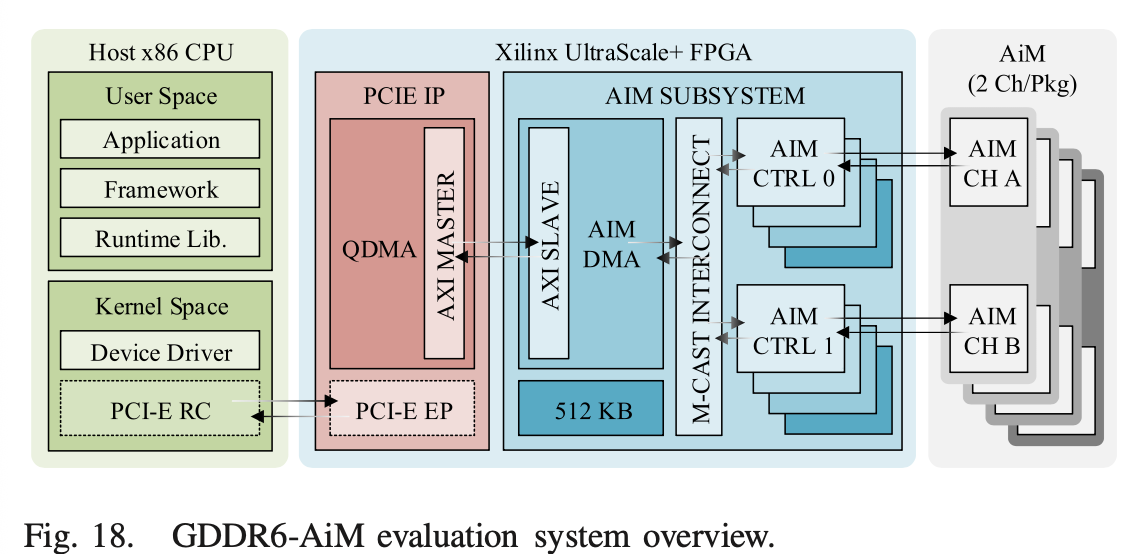
그 결과, 1.25V 환경에서 16Gbps의 속도로 동작하며, GEMV(행렬-벡터 곱셈) 및 MNIST 추론 워크로드에서 NVIDIA GV100(HBM 장착 GPU)과 대역폭을 동일하게 맞췄을 때 7.5배 ~ 10.5배의 성능 향상(Speedup)을 낼 수 있음을 입증했습니다.
