Aquabolt-XL: Samsung HBM2-PIM with in-memory processing for ML accelerators and beyond
1. 하드웨어 아키텍처: PIM 통합
CPU 핀 수나 PCB 배선을 늘려 메모리 대역폭을 물리적으로 확장하는 방식은 이미 물리적 한계에 도달했습니다. Aquabolt-XL은 데이터가 머무는 곳에 연산 장치를 직접 배치하여 이 문제를 우회합니다.
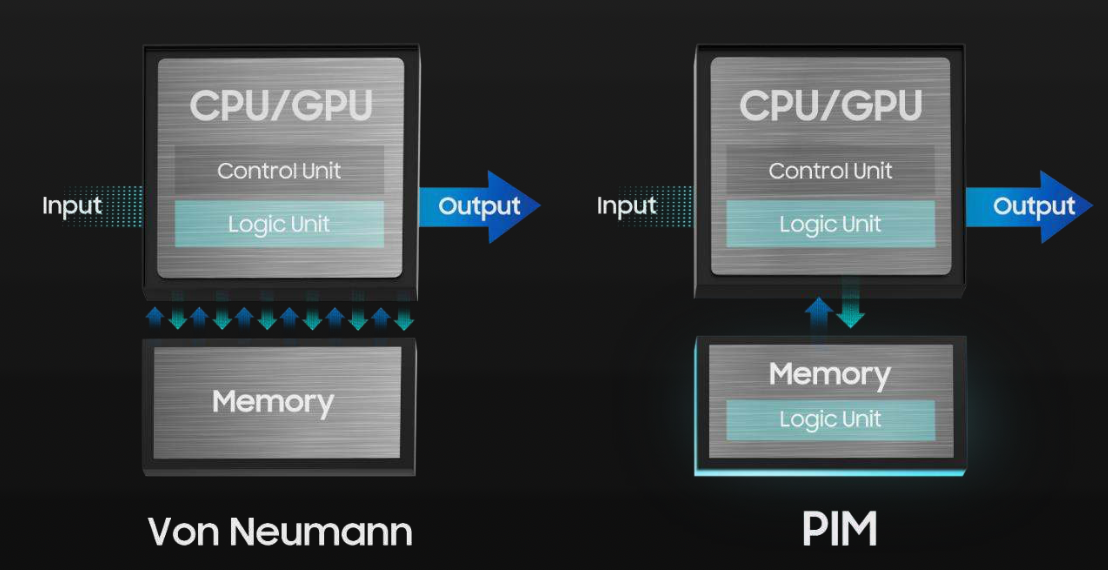
기존 시스템과 호환 (Drop-in Replacement): 표준 JEDEC Aquabolt HBM2와 완전히 동일한 폼팩터 및 타이밍 파라미터를 유지합니다. 호스트 컨트롤러의 물리 계층(PHY)을 수정할 필요 없이 기존 시스템에 그대로 장착할 수 있습니다.
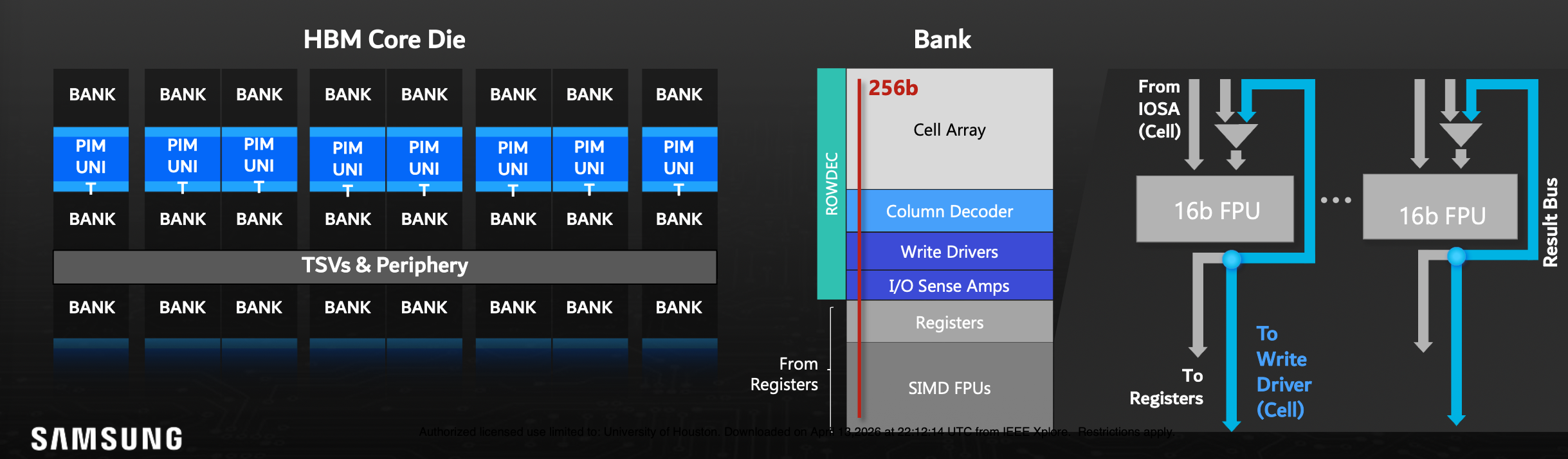
PCU 마이크로아키텍처: 컴퓨팅 유닛이 메모리 뱅크의 I/O 경계에 위치하며 다음을 포함합니다.
- 16-lane FP16 SIMD FPU 어레이 (16개의 곱셈기 및 덧셈기 쌍)
- 레지스터 파일: Command(CRF), General(GRF), Scalar(SRF)
- 명령어 페치(Fetch), 디코드 및 파이프라인 신호를 제어하는 컨트롤러
PIM ISA:
산술(ADD, MUL, MAC, MAD), 데이터 전송(MOVE, FILL), 제어 흐름(NOP, JUMP, EXIT) 등 총 9개의 명령어로 구성된 32비트 RISC 스타일의 명령어 셋을 사용합니다.
초경량 RISC 아키텍처와 9개의 명령어
"Supports RISC-style 32-bit instructions / Total 9 instructions"
설계 의도: DRAM 칩은 데이터를 저장하는 캐패시터(Capacitor)를 집적하는 데 최적화된 공정이지, 복잡한 로직 게이트를 넣기 좋은 공정이 아닙니다. CPU처럼 거대한 명령어 해독기(Instruction Decoder)를 넣을 공간도, 전력 여유도 없습니다.
현실적 제약: 그래서 명령어 길이를 32비트로 고정(RISC)하고, 명령어 종류를 단 9개로 극단적으로 줄였습니다. 복잡한 계산은 호스트 CPU가 하고, PIM은 오직 머신러닝에 필요한 단순 무식한 반복 연산만 하겠다는 타협입니다.
머신러닝 특화 연산 (MAC, MAD)
"4 Arithmetic: ADD, MUL, MAC, MAD"설계 의도: CNN 가속기를 만들어보셔서 아시겠지만, 인공지능 연산의 99%는 형태의 행렬 곱셈(MAC: Multiply-Accumulate)입니다.
PIM의 존재 이유는 이 MAC 연산을 메모리 밖으로 빼내지 않고 내부에서 처리하는 것이므로, 이 4개의 산술 명령어만으로도 ML 워크로드를 처리하는 데 충분합니다.
Zero-cycle static branch
"Zero-cycle static branch: supports only a preprogrammed numbers of iterations"
설계 의도: 아까 우리가 Tomasulo 알고리즘과 Branch Prediction을 공부할 때, 분기 예측이 틀리면 파이프라인에 들어온 명령어들을 다 버리고(Flush) 2-cycle penalty를 입었던 것 기억하시죠?
해결책: PIM 내부에는 그런 복잡한 분기 예측기(Branch Predictor)를 넣을 하드웨어 공간이 없습니다. 대신 머신러닝의 반복문(For loop)은 "행렬 크기만큼 정확히 N번 반복한다"는 특징이 있습니다.
따라서 컴파일할 때 반복 횟수를 하드웨어 카운터에 미리 세팅(Static)해 버립니다. 루프를 돌 때마다 카운터만 1씩 줄어들기 때문에, 조건문을 계산하고 점프할지 말지 고민할 필요 없이 페널티(딜레이) 0클럭(Zero-cycle)으로 루프를 돌 수 있습니다.
오퍼랜드와 호스트 CPU의 종속성
"Operand type: Vector Register, Scalar Register, and Bank Row Buffer"
- 의미: 계산할 재료(Operand)를 가져오는 곳입니다.
- Vector (GRF): 행렬 데이터 같은 큰 배열을 담습니다.
- Scalar (SRF): 가중치(Weight)나 바이어스(Bias) 같은 단일 상숫값을 담습니다.
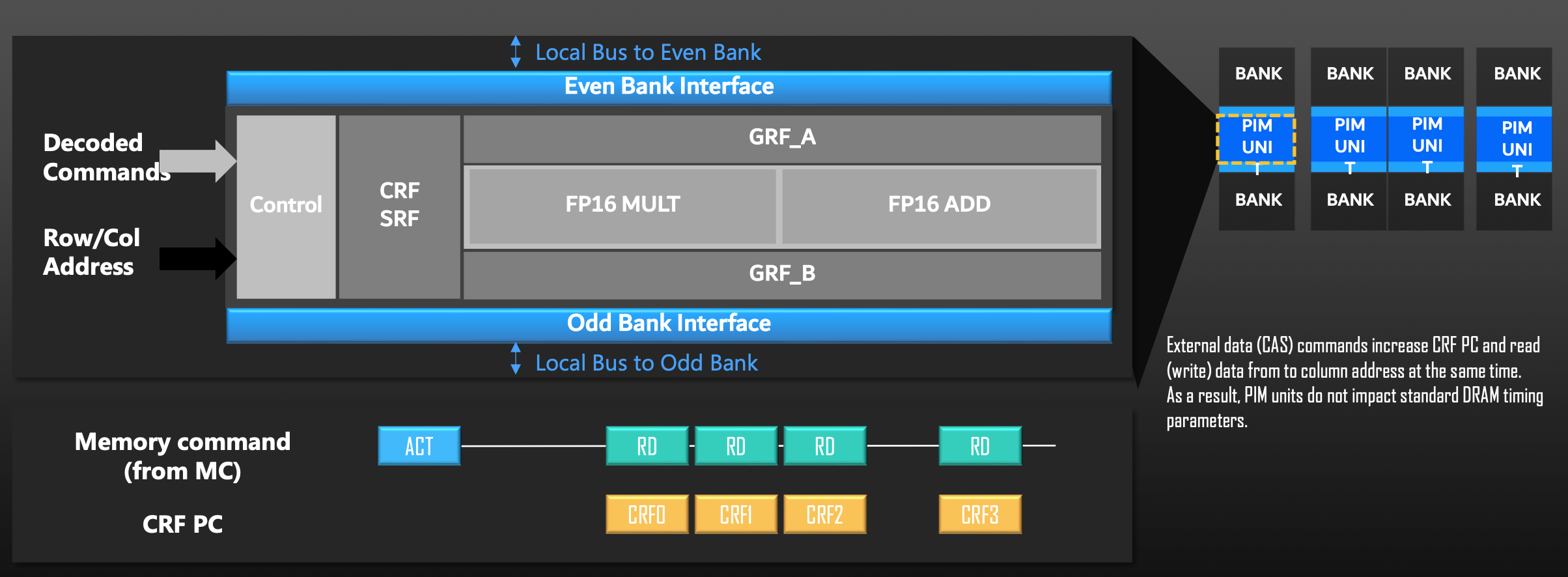
- Bank Row Buffer: 이것이 PIM의 핵심입니다. DRAM의 Sense Amplifier에 올려진 수천 비트의 데이터를 버스를 태우지 않고 연산기(FPU)로 직행시킵니다.
"DRAM commands decide where to retrieve data..." (매우 중요)
설계 의도: PIM의 32비트 명령어 안에는 "메모리 몇 번지 주소에서 데이터를 가져와라"라는 복잡한 메모리 주소 체계(MMU 기능)가 없습니다.
데이터를 꺼내는 역할은 철저하게 메인보드에 있는 호스트 CPU의 메모리 컨트롤러(Memory Controller)가 담당합니다. 호스트 CPU가 평소처럼 ACT(Activate), RD(Read) 명령을 보내 특정 Row를 Bank Row Buffer에 올려주면, PIM은 그저 "지금 버퍼에 올라와 있는 데이터랑 내 레지스터 값을 곱해라"라고 단순하게 동작할 뿐입니다. 기존 시스템의 메모리 프로토콜을 전혀 건드리지 않기 위한 천재적인 꼼수입니다.
PIM Operation mode
작동 모드: 표준 DRAM 명령어를 사용하여 SB(Single Bank), AB(All Bank), AB-PIM 모드 사이를 전환합니다.
PIM은 기본적으로 일반 DRAM으로도 쓰일 수 있어야 하고, 필요할 때만 연산 가속기로 변신해야 합니다. 이를 위해 세 가지 모드를 정의했습니다.
세 가지 실행 모드 (SB, AB, AB-PIM)
- Single Bank (SB): 기존의 일반적인 HBM 동작 방식입니다. 한 번에 하나의 뱅크에만 접근하여 데이터를 읽고 씁니다.
- All Bank (AB): 일반 HBM에서도 대역폭을 극대화하기 위해 여러 뱅크를 동시에 열어서 데이터를 병렬로 가져오는 모드입니다.
- All Bank PIM (AB-PIM): 이 칩의 핵심 모드입니다. 각 뱅크 입구에 달려있는 16개의 FPU(연산기)들을 동시에 모두 깨워서, 뱅크 밖으로 데이터를 꺼내지 않고 내부에서 일제히 병렬 연산(MAC 등)을 수행하게 만듭니다.
2. 소프트웨어 스택 및 시스템 통합
시스템 설계 관점에서, 이 하드웨어를 도입하더라도 애플리케이션 개발자가 소스 코드를 수정할 필요가 없습니다.
프레임워크 지원: PIM 인식(PIM-aware) 소프트웨어 스택을 제공하여, TensorFlow나 PyTorch 기반 애플리케이션에서 PIM에 적합한 연산을 자동으로 찾아 오프로딩합니다 (Native execution path).
직접 제어: 커스텀 가속이 필요한 경우 PIM-direct 경로를 통해 특정 PIM 연산을 명시적으로 호출할 수 있습니다.
타이밍 보장: 표준 DRAM의 RD/WR 명령어가 PIM 명령어의 실행을 트리거하는 방식으로 설계되어, 기존 DRAM의 결정론적(Deterministic) 타이밍 특성을 그대로 유지합니다.
Chip Implementation and Integration
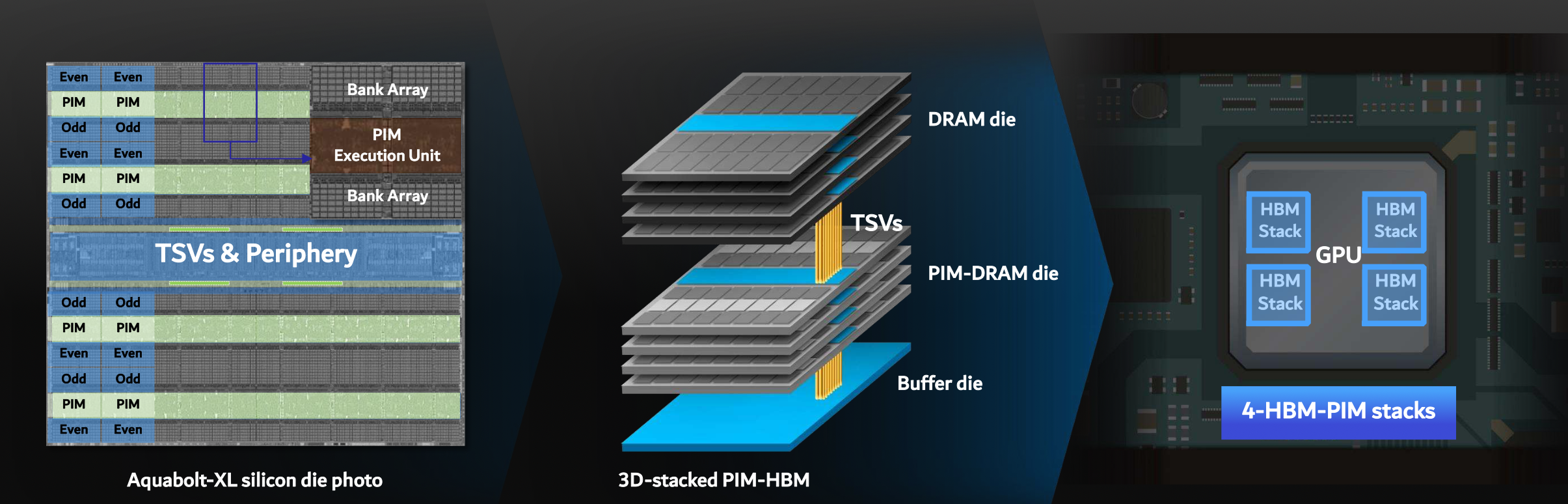
-
Off-chip Bandwidth (1.23 TB/s): * 메모리 뱅크에서 데이터를 꺼내 TSV(실리콘 관통 전극)와 실리콘 인터포저를 타고 칩 밖으로 빠져나가 호스트(GPU/FPGA)로 전달되는 기존 방식의 속도입니다. 아무리 HBM이라도 칩 외부로 데이터를 내보내는 물리적 병목이 존재합니다.
-
On-chip PIM compute Bandwidth (4.92 TB/s): * 데이터를 칩 밖으로 보내지 않고, 뱅크 문턱에 있는 16b FPU들에게 직접 데이터를 쏴주면서 연산하는 속도입니다.
결론: 칩 외부로 나가는 톨게이트를 거치지 않고 내부에서 직접 연산함으로써, 메모리가 코어에 데이터를 공급하는 속도가 무려 4배 (4.92 / 1.23) 폭증했습니다. 머신러닝 연산에서 병목을 일으키는 Memory-bound 워크로드를 하드웨어의 물리적 배치만으로 박살 낸 것입니다.
3. 평가 결과 (GPU 및 Xilinx FPGA)
삼성은 이 칩을 실제 제작하여, 상용 GPU 및 Xilinx FPGA 시스템에 통합하여 테스트를 완료했습니다.
전력 소모: HBM-PIM 칩은 표준 HBM 대비 단 5.4%의 전력만 추가로 소모합니다. 내부에 추가된 FPU로 인해 DRAM 내부 전력은 증가하지만, 데이터가 칩 외부로 나갈 필요가 없어 글로벌 I/O 버스 및 PHY에서 소모되는 동적 전력이 극적으로 감소하기 때문입니다.
GPU 통합 결과: DeepSpeech2 애플리케이션 기준 3.5배의 성능 향상을 기록했으며, 시스템 전체 에너지 소비를 70% 이상 줄였습니다.
Xilinx Alveo U280 통합 결과: 정확한 명령어 순서를 보장하고 Auto pre-charge를 막기 위해 커스텀 메모리 컨트롤러 설정을 적용했습니다. 그 결과 GEMV 2.82배, ADD 2.85배의 속도 향상을 보였으며, RNN-T 추론 지연 시간을 2.49배 단축하고 에너지를 62% 절감했습니다.
4. 한계점 및 향후 로드맵
이 논문은 현재 아키텍처의 한계점과 이를 극복하기 위한 현실적인 방향성도 명시하고 있습니다.
ECC 지원의 한계: 현재의 Aquabolt-XL 아키텍처에서는 PIM 내부 로직이 생성한 데이터에 대해 시스템 규격에 맞는 ECC 코드를 칩 내에서 자체 생성할 수 없어, 시스템 ECC 기능이 비활성화되어 있습니다. 차세대 HBM-PIM 설계에서는 On-die ECC 회로를 PIM과 공유하여 지연 시간 추가 없이 데이터를 보호할 계획입니다.
차세대 PIM 확장: 이 개념을 확장하여 모바일/엣지 시스템을 위한 LPDDR5-PIM(RNN-T 2.3배 성능 향상 검증) 및 대규모 추천 모델을 겨냥한 랭크(Rank) 수준의 병렬 처리가 가능한 AXDIMM(DIMM-PIM)을 개발 중입니다.
