1. Top-Level Architecture & 연산 정밀도 (Fixed vs Floating)
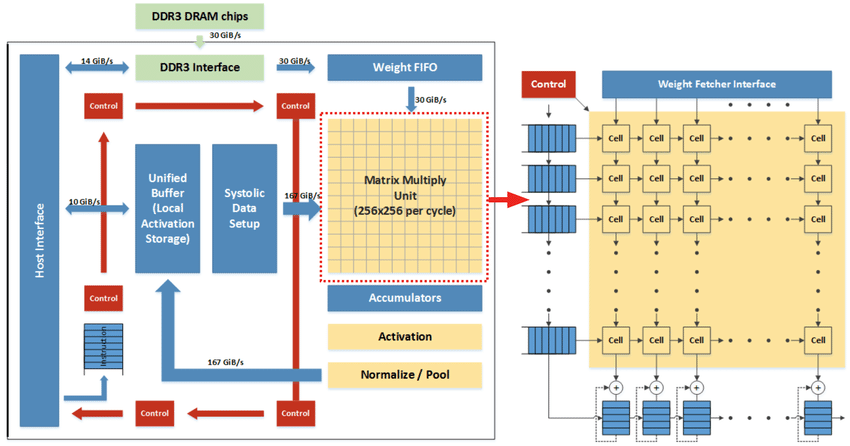
TPU는 범용 CPU/GPU와 달리, 딥러닝의 핵심 연산인 '행렬 곱(Matrix Multiplication)'에만 올인한 구조입니다.
(1) Systolic Array (시스톨릭 어레이) 구조
-
CPU는 데이터를 레지스터로 가져와 계산하고 다시 저장하는 과정을 반복하지만, TPU는 심장 박동(Systolic)처럼 데이터가 연산 유닛(PE) 사이를 흐르며 연속적으로 계산됩니다.
-
결과: 레지스터 접근 횟수를 획기적으로 줄여 전력 소모를 감소시키고 처리량을 높입니다.
(2) Fixed Point (INT8) vs Floating Point (FP16/32)
- Fixed Point (정수 연산): TPU v1은 주로 추론(Inference)용으로 설계되어 8-bit 정수 연산(Quantization)을 사용합니다.
- 장점: FP32 대비 하드웨어 크기와 전력 소모가 훨씬 적음. 더 많은 PE(Processing Element)를 칩에 집적 가능.
- Floating Point (부동 소수점): 학습(Training)용인 TPU v2/v3부터는 bfloat16 같은 포맷을 지원합니다.
- 이유: 학습 시에는 미세한 기울기(Gradient) 변화를 표현해야 하므로 정수만으로는 부족하기 때문입니다.
2. 메모리 계층 구조 (Memory Hierarchy)
TPU는 "데이터 이동 비용(Data Movement Cost)이 연산 비용보다 비싸다"는 점에 착안하여 설계되었습니다.
(1) Off-chip Memory (DRAM/HBM)
- 특징: 칩 외부에 있는 대용량 메모리.
- 단점: 용량은 크지만(Big Size), 데이터 전송 속도(Bandwidth)가 느리고 접근 시 전력 소모가 매우 큼(Power Consumption High).
- 역할: 모델의 전체 가중치(Weight)나 큰 입력 데이터를 저장.
(2) On-chip Memory (Unified Buffer / Activation SRAM)
- 특징: 칩 내부에 있는 고속 메모리.
- 단점: 다이를 많이 차지하여 비용이 비쌈(Big Resource). 용량 제한이 있음.
- 장점: 접근 속도가 매우 빠르고 전력 소모가 적음.
- 전략: 한 번 Off-chip에서 가져온 데이터는 On-chip에서 최대한 재사용(Reuse)하여 외부 메모리 접근을 최소화해야 함.
3. Roof line Model
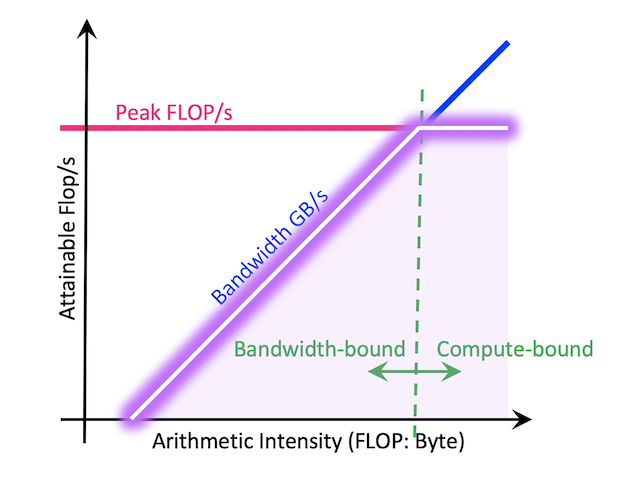
"내 시스템의 성능 병목이 어디인가?"를 시각적으로 보여주는 모델입니다. 작성해주신 "PE를 많이 쓴다고 성능이 느는 게 아니라 Bandwidth도 봐야 한다"는 내용이 핵심입니다.
"내 시스템의 성능 병목이 어디인가?"를 시각적으로 보여주는 모델입니다. 작성해주신 "PE를 많이 쓴다고 성능이 느는 게 아니라 Bandwidth도 봐야 한다"는 내용이 핵심입니다.
(1) 그래프의 의미
- X축 (Operational Intensity): 데이터 1바이트를 가져왔을 때 얼마나 많은 연산(FLOPs)을 수행하는가? (연산 밀도)
- Y축 (Performance): 초당 처리 가능한 연산 수 (GFLOPS)
(2) 두 가지 성능 제한 영역
① Memory Bound (대각선 영역 - 지붕의 경사면)
- 연산 밀도가 낮은 영역.
- 아무리 PE(연산 장치)가 많아도, 메모리에서 데이터를 가져오는 속도(Bandwidth)가 느려서 PE들이 데이터를 기다리며 놀게 됨.
- 해결책: 메모리 대역폭을 늘리거나, 데이터 재사용을 늘려 연산 밀도를 높여야 함.
② Compute Bound (평평한 영역 - 지붕의 천장)
- 연산 밀도가 높은 영역.
- 메모리 공급은 충분하나, PE 자체의 계산 속도 한계에 도달함.
- 해결책: PE의 클럭을 높이거나 PE 개수를 더 늘려야 성능이 향상됨.
(3) 결론 (시사점)
- TPU가 아무리 강력한 행렬 연산 유닛(MXU)을 가지고 있어도, Off-chip 메모리 대역폭이 받쳐주지 못하면(Memory Bound 상태), 성능은 지붕의 경사면 아래에 갇히게 됩니다.
- 따라서 최적화의 목표는 알고리즘을 개선하여 '연산 밀도(Arithmetic Intensity)'를 높여 그래프의 오른쪽(Compute Bound)으로 이동시키는 것입니다.
4. FLOPS / TOPS
-
성능 지표의 이동: FLOPS에서 TOPS로
과거 슈퍼컴퓨터나 GPU는 과학 연산을 위해 소수점 계산이 중요했지만, AI 추론(Inference) 시장이 커지면서 지표가 바뀌고 있습니다.(1) FLOPS (Floating-point Operations Per Second)
- 정의: 초당 부동소수점(실수) 연산 횟수 (예: FP32, FP16)
- 용도: 주로 'AI 학습(Training)' 단계나 과학 시뮬레이션에서 사용
- 이유: 학습 시에는 미세한 가중치 업데이트(Gradient Descent)가 필요하므로 정밀도가 높은 실수가 필수적임.(2) TOPS (Tera Operations Per Second)
- 정의: 초당 정수(Integer) 연산 횟수 (주로 INT8)
- 용도: 주로 'AI 추론(Inference)' 단계와 모바일/엣지 NPU에서 사용
- 차이: 'Operation'은 실수 연산보다 포괄적인 단위이며, 최근 NPU 스펙에서는 "INT8 연산 속도"를 의미하는 경우가 많음.
5. 저전력 설계 전략
1: Fixed Point (고정 소수점/정수) 사용
왜 NPU는 정확도가 떨어질 수 있는 정수 연산을 선호할까요?
(1) 하드웨어 복잡도 감소
- 부동소수점 연산기(FPU)는 지수부와 가수부를 따로 계산하고 정렬해야 해서 회로가 크고 복잡합니다.
- 반면 정수 연산기(ALU)는 단순한 덧셈/곱셈 회로로 구성되어 크기가 훨씬 작습니다. (같은 면적에 더 많은 연산 유닛 배치 가능)
(2) 에너지 효율 (Energy Efficiency)
- 일반적으로 32비트 부동소수점 덧셈보다 8비트 정수 덧셈이 에너지를 30배 이상 적게 소모합니다.
- 핵심 기술: 양자화 (Quantization)
* 학습된 FP32 모델의 가중치를 성능 저하를 최소화하면서 INT8로 변환하는 기술이 필수적입니다.
2: Off-chip Memory 접근 최소화
"Compute is cheap, Data movement is expensive" (연산은 싸고, 데이터 이동은 비싸다)라는 격언이 핵심입니다.
(1) 에너지 비용의 불균형
- 칩 내부(On-chip)에서 계산하는 에너지보다, 칩 외부(Off-chip, DRAM)에서 데이터를 가져오는 에너지가 100배~1000배 더 듭니다.
- 따라서 NPU가 아무리 저전력으로 설계되어도, DRAM을 자주 읽으면 배터리가 광탈합니다.
(2) 해결책: 데이터 재사용 (Data Reuse)과 데이터 흐름(Dataflow) 최적화
- 한 번 DRAM에서 가져온 데이터(가중치 혹은 입력값)를 내부 버퍼(SRAM)에 저장해두고, 뽕을 뽑을 때까지(?) 재사용해야 합니다.
- 대표적인 아키텍처 (Dataflow):
Weight Stationary (WS): 가중치를 레지스터에 고정해두고 입력만 흘려보냄 (TPU가 사용하는 방식)
Output Stationary (OS): 부분합(Partial Sum)을 레지스터에 고정해두고 계산
