1. 단순 예측의 한계 (Superscalar의 현실)
한 사이클에 명령어를 4개, 8개씩 빨아들이는(Fetch) 슈퍼스칼라 구조에서는 단순히 분기 방향 하나 맞췄다고 파이프라인이 매끄럽게 돌아가지 않습니다. 명령어들 사이에 얽혀있는 데이터 의존성(Data Hazard) 때문에 ALU가 놀고 있는 시간이 생기기 때문입니다. 이 한계를 깨기 위해 두 가지 기술을 융합합니다.
동적 스케줄링 (Dynamic Scheduling): 컴파일러가 정해준 순서에 얽매이지 않고, 하드웨어가 런타임에 데이터가 준비된 명령어부터 연산기에 먼저 밀어 넣습니다.
추측 실행 (Speculative Execution): 앞선 분기문의 진짜 결과가 나오기도 전에, 예측기의 결과를 100% 맹신하고 그 너머의 명령어들을 미리 실행(Pre-execute)해 버립니다.
2. 파이프라인의 이원화 (OOO Execute vs. In-order Commit)
가장 중요한 슬라이드의 핵심입니다. 아키텍처 설계자들은 프로세서의 동작을 두 개의 독립적인 세계로 완전히 쪼개버렸습니다.
실행 (Out-of-order execution): 백엔드 연산기(ALU) 쪽은 말 그대로 무법지대입니다. 순서와 상관없이 오퍼랜드(Operand) 데이터만 준비되면 먼저 낚아채서 계산해 버립니다. 이를 통해 명령어 수준의 병렬성(ILP)을 극대화합니다.
확정 (In-order commit): 연산이 끝났다고 해서 그 결과값을 R1, R2 같은 메인 아키텍처 레지스터나 메모리에 즉시 덮어쓰지 않습니다. 무조건 프로그램에 적혀있던 원래 순서대로 차례가 돌아왔을 때만 영구적으로 반영(Commit) 합니다.
3. 핵심 철학: "순서대로 가져오고, 맘대로 실행하고, 순서대로 확정한다"
하드웨어 기반 추측의 동작 원리는 다음 3단계 파이프라인 흐름으로 요약됩니다.
In-order Issue (순서대로 발급): 메모리에서 명령어들을 프로그램에 적힌 원래 순서대로 긁어옵니다.
Out-of-order Execute (비순차 실행): 데이터 의존성이 해결된 명령어부터 닥치는 대로 먼저 연산기(ALU)에 밀어 넣고 계산합니다. (여기서 순서가 완전히 뒤죽박죽 섞입니다.)
In-order Commit (순서대로 확정): 계산이 끝났다고 바로 레지스터에 값을 쓰지 않습니다. 원래 프로그램 순서대로 차례가 돌아왔을 때만 최종적으로 값을 씁니다.
4. 마법의 핵심 부품: ROB (Reorder Buffer)
비순차 실행으로 난장판이 된 순서를 다시 원래대로 끼워 맞추고, 예측이 틀렸을 때 파이프라인을 복구할 수 있게 해주는 가장 중요한 하드웨어 컴포넌트가 바로 ROB(재정렬 버퍼)입니다.
ROB는 일종의 원형 큐(Circular Queue) 형태의 하드웨어 테이블입니다.
명령어가 파이프라인에 들어올 때(Issue), 하드웨어는 무조건 ROB의 꼬리(Tail) 쪽에 빈 방을 하나 할당합니다.
연산기가 계산을 마치면, 그 결과값을 메인 레지스터(예: R1, R2)가 아니라 자기 자신에게 할당된 ROB의 방 안에 임시로 적어둡니다.
오직 예측이 맞았다는 것이 확정되고, 내 명령어가 ROB의 머리(Head) 부분에 도달했을 때만(Commit), 비로소 ROB에서 결과값을 빼내어 메인 레지스터에 영구적으로 기록합니다.
5. 예측 실패 시의 하드웨어 복구 (Hardware Flush)
ROB가 존재하는 진짜 이유입니다. 만약 분기 예측기(BHT/BTB)가 틀렸다는 것이 뒤늦게 판명되면 어떻게 될까요?
하드웨어는 ROB를 쭉 스캔합니다.
틀린 분기문 이후에 섣불리(Speculatively) 실행되어 ROB에 임시로 결과값을 적어둔 모든 잉여 명령어들의 방을 단 1사이클 만에 한꺼번에 초기화(Flush)해 버립니다.
값들이 메인 레지스터에는 아직 쓰이지 않았기 때문에, 프로세서의 공식적인 상태(Architectural State)는 전혀 오염되지 않은 깔끔한 상태를 유지할 수 있습니다.
고전적인 토마술로(Tomasulo) 알고리즘에 ROB(Reorder Buffer)를 추가하여 하드웨어 기반 추측 실행(HWBS)을 완성한 궁극의 마이크로아키텍처 동작 원리입니다.
1. 파이프라인의 4단계 생명주기 (Steps of Execution)
기존 파이프라인과 가장 큰 차이점은 결과 쓰기(Write result)와 최종 확정(Commit)이 물리적으로 완전히 분리되었다는 점입니다.
1단계: Issue (발급) - In-order
- 메모리에서 명령어를 순서대로 가져옵니다.
- 연산기 앞의 대기열인 RS(Reservation Station)와 임시 장부인 ROB 양쪽 모두에 빈자리가 있어야만 명령어를 발급합니다. 하나라도 꽉 찼으면 파이프라인은 멈춥니다(Stall).
2단계: Execute (실행) - Out-of-order
- 연산에 필요한 데이터가 준비될 때까지 기다립니다.
- 다른 연산기가 공용 데이터 버스(CDB)에 내가 필요한 값을 던져주면(Broadcast), 그것을 낚아채서 즉시 연산기(ALU)에 밀어 넣습니다. 순서는 완전히 무시됩니다.
3단계: Write result (결과 임시 쓰기)
- 연산이 끝난 값을 CDB에 태워 보냅니다.
- 핵심: 이 값은 메인 레지스터(R1, R2)로 절대 가지 않습니다. 오직 나를 기다리고 있던 다른 RS들과, 내게 할당된 ROB의 특정 칸에만 임시로 기록됩니다. 연산을 마친 RS 자리는 이제 비워져서 다음 명령어를 받을 준비를 합니다.
4단계: Commit (최종 확정) - In-order
- 내 명령어가 ROB의 맨 앞줄(Head)에 도달할 때까지 얌전히 기다립니다.
- 내 차례가 왔고, 앞선 분기 예측들이 모두 맞았음이 확인되면, 비로소 ROB에 들고 있던 임시 값을 메인 레지스터나 메모리에 영구적으로 덮어씁니다.
- Flush (복구): 만약 맨 앞줄에 도달한 명령어가 '실패한 분기문'이라면, 하드웨어는 뒤따라오던 잉여 명령어들이 담긴 ROB를 싹 다 비워버리고(Flush) 올바른 주소부터 다시 시작합니다.
2. ROB의 물리적 구조 (Fields in ROB)
ROB는 실제 RTL로 구현할 때 거대한 SRAM 레지스터 파일로 만들어집니다. 슬라이드에 적힌 필드들은 SRAM의 각 열(Column)을 의미합니다.
- Busy: 이 방이 현재 사용 중인가? (1-bit)
- Instruction: 어떤 종류의 명령어인가? (분기문, 저장, 덧셈 등)
- State: 현재 파이프라인 4단계 중 어디에 위치해 있는가?
- Destination: 최종적으로 이 값을 덮어쓸 메인 레지스터 번호(예: R1)나 메모리 주소.
- Value: 연산기에서 계산되어 날아온 32/64비트짜리 실제 데이터 값.
3. 하드웨어 구조의 결정적 변화 (Rename to ROB)
슬라이드 하단의 Register rename to ROB instead of RS는 프로세서 설계의 핵심입니다.
-
기존 토마술로: 레지스터가 "내 데이터는 3번 RS에서 계산 중이야"라고 RS 번호(Tag)를 가리켰습니다.
-
HWBS (ROB 도입 후): RS는 연산이 끝나자마자 다음 명령어를 위해 자리를 비워줘야 합니다. 따라서 데이터를 계속 들고 있을 수 없습니다. 대신, 레지스터는 "내 데이터는 ROB의 5번 방에 임시 보관되어 있어"라고 ROB의 인덱스 번호를 가리키게(Rename) 됩니다. 실제 하드웨어 아키텍처를 설계하고 UVM으로 검증할 때, 가장 많은 코너 케이스 버그와 타이밍 위반이 터져 나오는 곳이 바로 이 ROB의 상태 전이와 비동기적인 Flush 신호가 맞물리는 부분입니다. 명령어들이 꼬이지 않고 정확한 타이밍에 Commit 되는지 확인하는 것은 설계 검증의 최대 난제입니다.
4. Block Diagram
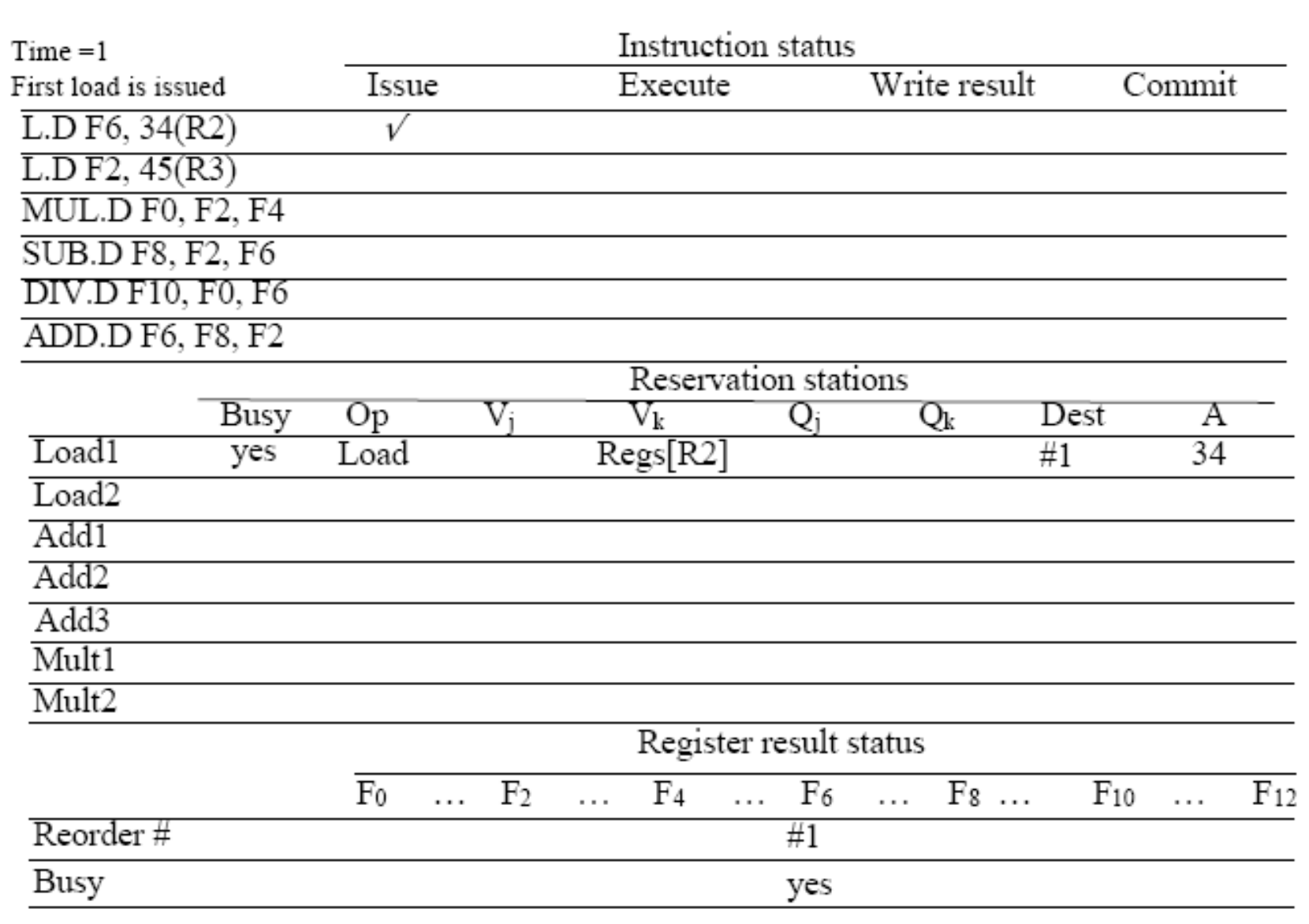
1. Instruction Status (명령어 상태)
첫 번째 명령어 L.D F6, 34(R2)가 메모리에서 성공적으로 Fetch되어 Issue 단계에 체크(✓) 표시가 되었습니다.
즉, 하드웨어가 이 명령어를 해독하고 내부 장치(RS와 ROB)에 자원을 성공적으로 할당했다는 뜻입니다.
2. Reservation Stations (RS - 연산기 대기열)
명령어가 발급되었으므로, 실제 연산을 수행할 대기열인 RS 테이블에 정보가 매핑됩니다.
할당: Load1 장치가 할당되어 Busy가 yes로 바뀝니다. 연산 종류(Op)는 Load입니다.
오퍼랜드 준비: * Vk 필드에 Regs[R2]가 기록되었습니다. 메모리 주소를 계산하기 위한 베이스 레지스터 R2의 값이 이미 준비되어 있다는 뜻입니다.
A 필드에 오프셋 값인 34가 기록되었습니다. ALU는 이제 이 두 값을 더해 실제 메모리 주소를 구하게 됩니다.
가장 중요한 구조적 변화 (Dest 필드): 이전 슬라이드에서 강조했던 Register rename to ROB instead of RS가 물리적으로 적용된 부분입니다. Dest 값이 RS 번호가 아니라 #1을 가리키고 있습니다. 이는 "메모리에서 데이터를 가져오면, 메인 레지스터나 다른 곳이 아니라 무조건 ROB의 1번 방에 임시로 써넣어라"라는 하드웨어의 엄격한 지시입니다.
3. Register Result Status (레지스터 상태 및 리네이밍)
이 아키텍처가 데이터 의존성(Data Hazard)을 뚫고 나가는 핵심 하드웨어 맵핑 구역입니다.
명령어의 목적지인 F6 레지스터 칸을 보십시오. 그곳에 #1 (Reorder #1) 이라는 꼬리표가 붙었고, Busy가 yes로 설정되었습니다.
의미: 하드웨어가 공용 데이터 버스(CDB)를 향해 이렇게 선언한 것과 같습니다. "지금부터 F6 레지스터의 진짜 최신 값은 메인 레지스터에 없다. F6가 필요한 명령어들은 엉뚱한 곳 찾지 말고, ROB의 1번 방(Reorder #1)에서 데이터가 튀어나오기만을 기다려라."
현대판 비순차(Modern OOO) 파이프라인
1. 아키텍처의 결정적 변화 (데이터 이동의 최소화)
고전적인 구조의 가장 큰 문제점은 데이터가 너무 많이 이사를 다닌다는 것이었습니다. 연산이 끝나면 RS에 썼다가, ROB에 썼다가, 마지막에 다시 메인 레지스터로 복사해야 했습니다. 이는 엄청난 전력 낭비와 칩 면적의 비효율을 초래합니다.
-
물리 레지스터(Physical Registers)의 도입: 현대 칩 내부에는 어셈블리 코드에 보이는 R1, R2 (아키텍처 레지스터) 외에, P1부터 P256까지 수백 개의 거대한 물리 레지스터 파일(PRF)이 존재합니다.
-
ROB의 경량화: 데이터는 연산이 끝난 직후 무조건 PRF의 특정 방에 딱 한 번만 쓰이고 다시는 움직이지 않습니다. 이제 ROB는 무거운 실제 데이터를 들고 있지 않고, "이 명령어의 결과값은 물리 레지스터 P45번에 들어있다"라는 가벼운 포인터(영수증)만 들고 순서를 관리합니다.
-
용어의 현대화: 예전의 Reservation Station(RS)은 기능이 조금 더 통합되어 Issue Queue (IQ) 또는 Instruction Window라는 이름으로 불리게 되었습니다.
2. 현대 OOO 파이프라인 스테이지 (사이클 흐름)
슬라이드 하단에 나열된 긴 스테이지들을 명령어가 파이프라인을 통과하는 시간순으로 쪼개어 보겠습니다.
-
Fetch & Decode (가져오기 & 해독): 메모리에서 명령어를 순서대로(In-order) 가져와 정체를 파악합니다.
-
Register Renaming (이름표 바꿔 달기): 명령어에 적힌 R1 같은 가짜 이름(아키텍처 레지스터)을, 현재 비어있는 실제 물리 레지스터(예: P10)에 1:1로 매핑해 줍니다. 데이터 의존성(WAW, WAR Hazard)이 여기서 완벽하게 끊어집니다.
-
Dispatch (배치): 이름표를 바꿔 단 명령어를 실행 대기열인 Issue Queue와, 순서 확정을 위한 ROB 양쪽에 동시에 밀어 넣습니다.
-
Issue (발급 - Wakeup & Select): 여기가 비순차(OOO) 마법이 시작되는 곳입니다.
-
Wakeup: 계산에 필요한 오퍼랜드 데이터가 준비될 때까지 대기열에서 잠자코 기다립니다.
-
Select: 데이터가 준비된 명령어들이 손을 들면, 하드웨어가 그중에서 연산기(ALU)로 보낼 놈을 고릅니다.
-
-
Read Register (레지스터 읽기): 연산기로 들어가기 직전, 배정받았던 물리 레지스터(PRF)에서 진짜 데이터를 읽어옵니다.
-
Execute (실행): ALU에서 실제 계산을 수행합니다.
-
Write back (결과 쓰기): 계산 결과를 물리 레지스터에 써넣습니다. 그리고 대기열(Issue Queue)에 있는 다른 명령어들에게 "내 데이터 계산 끝났다!"라고 방송(Broadcast)하여 그들을 깨웁니다.
-
Commit (최종 확정): 내 명령어가 ROB의 맨 앞줄에 도달했고 예측이 맞았다면, "이제부터 공식적인 R1의 진짜 최신 값은 P10에 있다"라고 시스템의 공식 장부(Architectural State)에 도장을 찍고 확정합니다.
결과적으로 현대 아키텍처는 무거운 데이터를 이리저리 옮기는 대신, '이름표(Tag)'와 '포인터'만 파이프라인에서 빠르게 굴리며 성능과 전력 효율을 극대화한 것입니다.
