*Tournament Predictor (토너먼트 예측기)는 말 그대로 칩 내부에서 두 개의 서로 다른 예측기를 경쟁시켜서, "지금 이 분기문에서는 누구 말을 듣는 게 더 정확할까?"를 하드웨어가 스스로 판단하고 선택하는 메타 예측기(Meta-Predictor)**입니다.
왜 이런 복잡한 방식을 사용하는지, 하드웨어 구조와 논리를 쪼개어 설명해 드리겠습니다.
1. 도입 배경: 완벽한 단일 예측기는 없다
로컬 예측기(Local Predictor): 오직 자기 자신의 과거만 봅니다. 아주 단순하고 규칙적으로 뱅글뱅글 도는 for 루프문(Loop)의 횟수를 예측하는 데는 귀신같이 정확합니다. 하지만 앞서 본 널뛰기 패턴이나 다른 변수의 영향을 받는 조건문에서는 박살이 납니다.
글로벌/상관 예측기(Global/Correlated Predictor): 주변의 문맥(다른 분기문의 결과)을 봅니다. 복잡한 if-else 구조나 얽혀있는 조건문을 예측하는 데 강력합니다. 하지만, 완전히 독립적이고 단순한 루프문을 돌 때는 오히려 쓸데없는 남의 문맥을 참조하느라 혼란에 빠져 정확도가 떨어질 때가 있습니다.
결론: 실제 프로그램 안에는 로컬이 잘 맞추는 단순한 분기문과 글로벌이 잘 맞추는 복잡한 분기문이 섞여 있습니다. 따라서 두 개를 다 만들어 놓고, 상황에 맞게 더 잘 맞추는 예측기를 고르자는 것이 토너먼트 예측기의 철학입니다.
2. 하드웨어 구조: 3개의 컴포넌트
토너먼트 예측기는 내부에 3개의 하드웨어 테이블을 독립적으로 굴립니다.
- Local Predictor Array: 자신의 과거 기록(PC 주소)만 참조하여 0 또는 1을 내뱉는 예측기.
- Global Predictor Array: 글로벌 히스토리(GHR)를 참조하여 0 또는 1을 내뱉는 예측기.
- Selector (선택기 / 메타 예측기): 이 둘 중 누구의 예측값을 최종적으로 채택할지 결정하는 '심판' 역할을 합니다.
3. Selector의 동작 원리 (The Referee)
Selector 역시 우리가 앞서 배운 2비트 포화 카운터(2-bit Saturating Counter)로 동작합니다. 다만, 뛰느냐(Taken) 안 뛰느냐(Not Taken)를 기록하는 것이 아니라, "누가 정답을 맞혔는가"를 기록합니다.
상태값 (예시):
- 00, 01: "최근에 로컬(Local) 예측기가 계속 정답을 맞히더라. 이번에도 로컬의 예측값을 파이프라인에 전달해야지."
- 10, 11: "최근에 글로벌(Global) 예측기가 계속 정답을 맞히더라. 이번엔 글로벌의 예측값을 파이프라인에 전달해야지."
업데이트 규칙:
- 두 예측기가 모두 맞히거나 모두 틀리면 카운터는 변하지 않습니다.
- 로컬은 틀렸는데 글로벌이 맞히면, 카운터를 글로벌 쪽으로 1 증가(+1)시킵니다.
- 글로벌은 틀렸는데 로컬이 맞히면, 카운터를 로컬 쪽으로 1 감소(-1)시킵니다.
이 슬라이드는 지금까지 배운 화려한 분기 예측 기술(로컬, 글로벌, 토너먼트)들이 고전적인 5단계 MIPS 파이프라인의 물리적 구조 앞에서는 무용지물이 되는 치명적인 모순을 뼈아프게 지적하고 있습니다.
아무리 예측기가 똑똑하게 "뛴다(Taken)"라고 정답을 맞춰도 파이프라인 지연 시간이 전혀 단축되지 않는 이유를 설계 관점에서 쪼개어 분석해 드리겠습니다.
Implementing Branch Histories
1. IF (Fetch) 단계의 맹점: "명령어의 정체를 모른다"
프로세서의 첫 단계인 IF(Instruction Fetch)에서는 단순히 메모리에서 32비트짜리 기계어 덩어리를 가져올 뿐입니다.
예측기가 "이번엔 뛴다!"라고 강력하게 주장해도, 정작 방금 가져온 32비트 명령어가 덧셈(ADD)인지, 분기문(BEQ)인지 자체를 이 시점에서는 알 길이 없습니다. 해독(Decoding)을 거쳐야만 정체를 알 수 있습니다.
2. 목적지 주소(Target Address)의 부재
백번 양보해서 방금 가져온 것이 분기문이라는 것을 IF 단계에서 기적적으로 알았고, 예측기가 점프할 것(Taken)이라는 것도 맞췄다고 가정해 봅시다.
하지만 "어디로(Where) 뛸 것인가?"를 모릅니다. 목적지 주소를 알려면 명령어의 하위 비트(Offset)를 뜯어서 현재 PC 주소와 더하는 산술 연산 로직을 거쳐야만 합니다. 어디로 갈지 모르면 다음 명령어를 미리 당겨올(Fetch) 수 없습니다.
3. ID (Decode) 단계의 역설: "알았을 때는 이미 늦었다"
MIPS 파이프라인에서는 ID(Instruction Decode) 단계에 도달해야 비로소 이 명령어가 분기문임을 해독하고, 목적지 주소를 계산해 냅니다.
치명적 문제 (Haven't saved any time!): 방향 예측을 미리 하든 안 하든, 어차피 목적지 주소를 알기 위해 ID 단계까지 멍하니 기다려야 한다면 예측을 미리 해둔 의미가 전혀 없습니다. 다음 명령어를 미리 Fetch 하려고 예측하는 것인데 주소를 몰라서 기다린다면, 결국 예측을 안 했을 때와 똑같이 1사이클 패널티(Control Stall)를 꼼짝없이 맞게 됩니다.
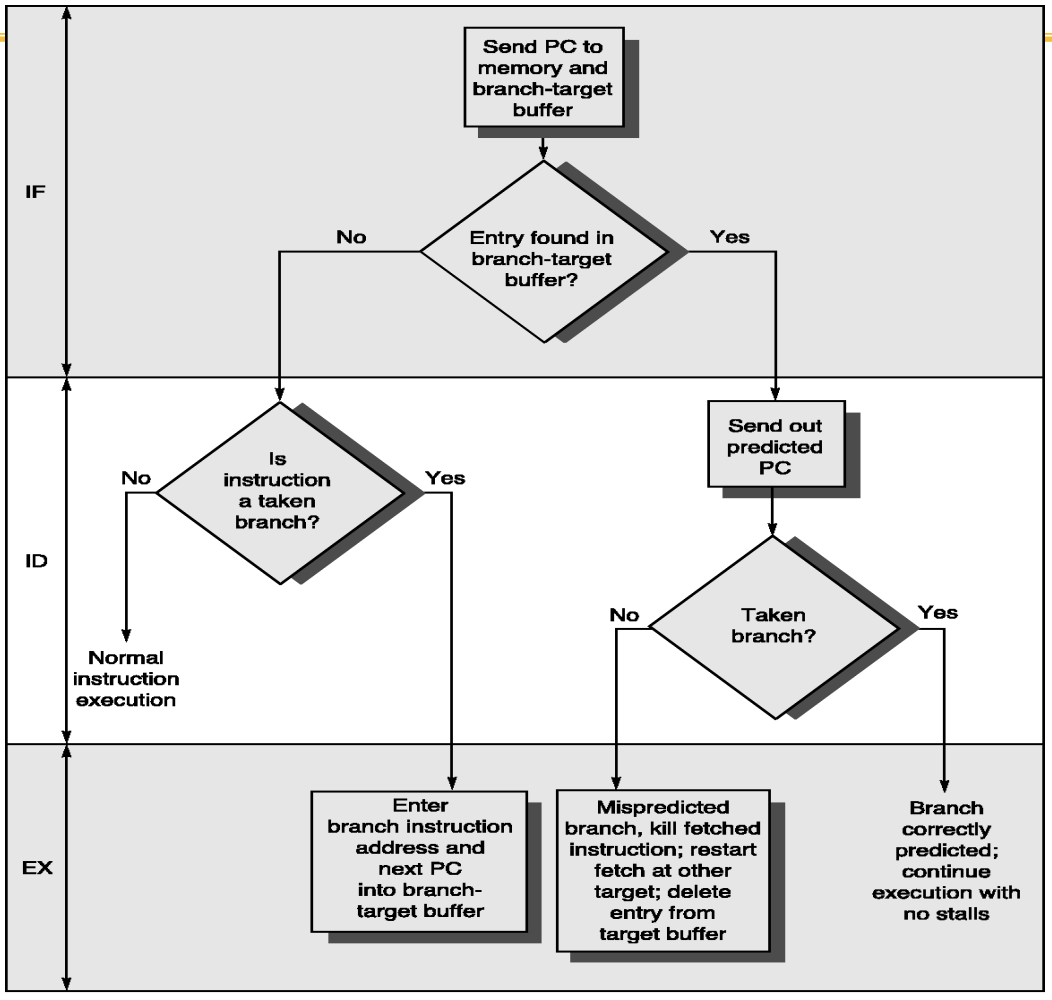
Branch-Target Buffers (BTB)
1. 일반적인 MIPS 파이프라인의 현실 (Extra ID cycle)
아무런 보조 장치가 없는 일반적인 파이프라인에서는 명령어를 처음 가져오는 IF(Fetch) 단계에서 다음 주소(Next PC)를 바로 알아낼 방법이 없습니다. 최소한 다음 단계인 ID(Decode) 단계까지 한 사이클을 온전히 기다려야만 비로소 다음 3가지를 알아낼 수 있습니다.
- 방금 메모리에서 긁어온 32비트 덩어리가 하필 '분기 명령어'라는 사실
- 조건이 충족되어 진짜로 '점프(Taken)' 해야 한다는 사실
- 현재 PC에 Offset을 더하는 산술 연산을 통해 알아낸 실제 '목적지 주소(Target Address)'
2. 방향 예측의 반쪽짜리 진실 (Branch prediction alone doesn't help)
우리가 지금까지 다루었던 1비트/2비트 카운터, 상관 예측기, 토너먼트 예측기 등은 오직 "뛸 것인가, 말 것인가?(Taken / Not Taken)"만 예측해 줍니다.
예측기가 "이번엔 100% 뜁니다!"라고 확신하더라도, 정작 "그래서 어디로(Next PC) 뛸 것인데?"라는 질문에 대답하지 못하면 무용지물입니다. 목적지 주소 계산이 끝날 때까지 다음 명령어를 Fetch 할 수 없으므로 파이프라인은 멈춰서 기다려야 합니다.
3. 완전한 해결책: BTB (Branch-Target Buffers)
이 문제를 근본적으로 해결하기 위해 칩 내부에 추가한 하드웨어가 바로 BTB입니다.
BTB는 과거에 분기문이 '어디로 뛰었는지' 그 목적지 주소(Target Address) 자체를 통째로 캐싱해 두는 전용 메모리입니다.
동작 원리: IF 단계에서 현재 명령어를 가져오기 위해 PC 주소를 메모리에 던질 때, 이 PC 주소를 BTB 캐시에도 동시에 던집니다.
효과: 만약 BTB에 "이 주소는 예전에 점프했던 분기문이고, 그때 목적지는 0x4000번지였어"라는 기록(Hit)이 남아있다면, ID 단계까지 가서 명령어를 해독하고 주소 계산을 할 필요가 없습니다. 다음 사이클에 지체 없이 곧바로 0x4000번지에서 명령어를 당겨옵니다.
결론적으로 방향 예측기(BHT)의 "뛴다"는 판단과, 주소 예측기(BTB)의 "이곳으로 간다"는 정보가 한 쌍으로 맞물려 돌아가야만 파이프라인의 지연(Stall)을 완벽하게 지워낼 수 있습니다.
BTB Schematic
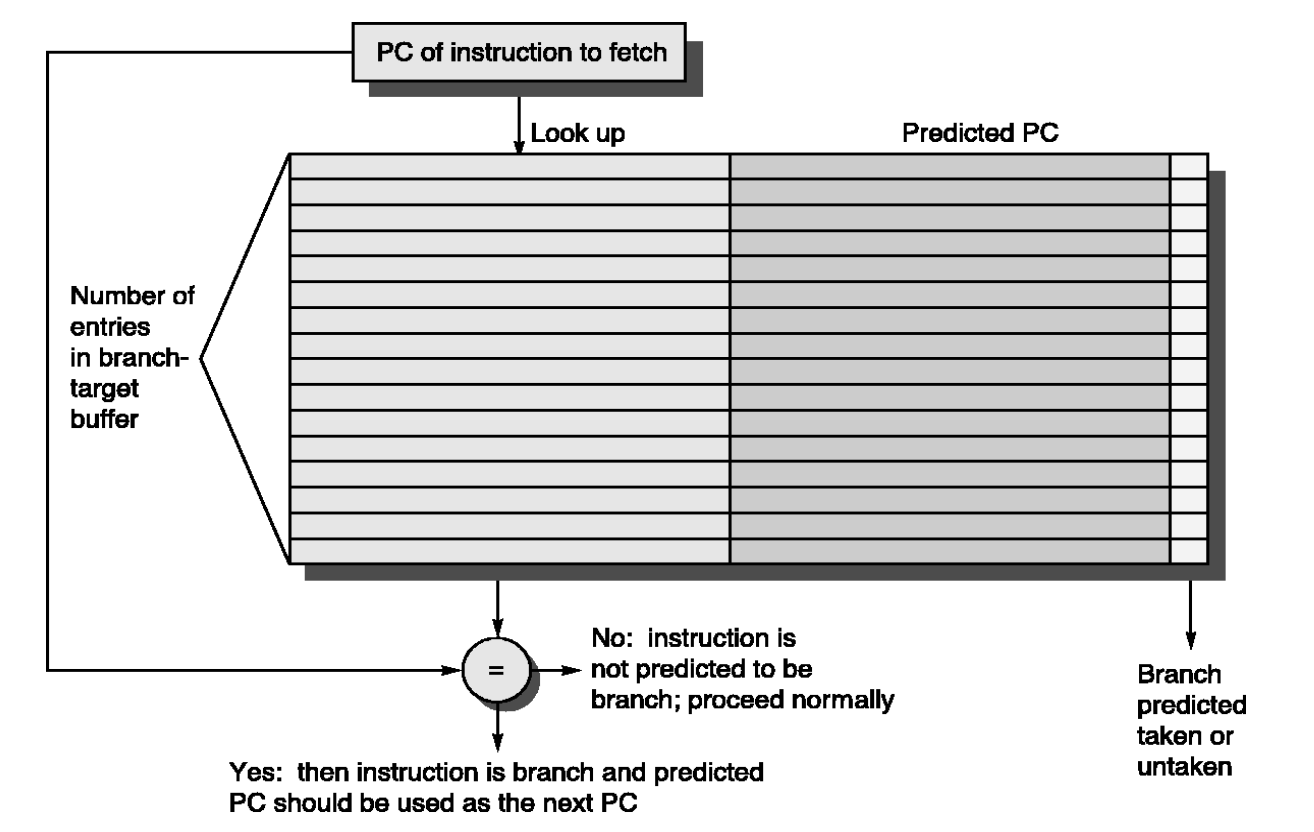
1. 주소 입력 및 검색 (Look up)
-
PC of instruction to fetch: 파이프라인이 IF 단계에서 메인 메모리로부터 명령어를 가져오기 위해 사용하는 현재 PC 주소입니다.
-
하드웨어는 메인 메모리에 주소를 요청함과 동시에, 이 PC 주소를 BTB 테이블의 왼쪽 구역(Tag 배열)으로 보냅니다 (Look up).
2. 하드웨어 비교기 (Comparator '=')
다이어그램 하단에 있는 동그란 = 기호가 이 아키텍처의 핵심 논리 회로입니다. 현재 PC 주소와 BTB 안에 과거 기록으로 저장된 주소들을 병렬로 비교합니다.
-
No (Miss 발생): 일치하는 주소가 없는 경우입니다. 하드웨어는 "이 명령어는 분기문이 아니거나(예: 일반 덧셈 명령어), 태어나서 처음 보는 분기문이구나"라고 판단합니다. 따라서 특별한 조치 없이 PC + 4를 하여 다음 명령어를 순차적으로 가져옵니다 (proceed normally).
-
Yes (Hit 발생): 일치하는 주소가 있는 경우입니다. 명령어 해독(ID 단계)을 거치지도 않았는데, 단지 메모리 주소만 보고도 "어! 이거 예전에 점프했던 그 분기문이네!"라고 즉시 명령어의 정체를 파악해 낸 것입니다.
3. 예측 확인 및 목적지 반환 (Predicted PC)
Hit가 발생했다고 해서 무조건 목적지로 점프하는 것은 아닙니다. 테이블의 오른쪽 구역을 확인해야 합니다.
-
Branch predicted taken or untaken (가장 오른쪽 칸): 우리가 앞서 지겹게 다루었던 1비트, 2비트, 혹은 토너먼트 방향 예측기의 상태값이 들어있는 곳입니다. 여기서 "이번에도 뛴다(Taken)"라고 결론이 나면 다음 단계를 수행합니다.
-
Predicted PC (가운데 넓은 칸): "어디로 뛸 것인가"에 대한 정답입니다. 과거에 계산해 두었던 목적지 주소를 여기서 즉시 끄집어냅니다.
-
결과 적용: 하드웨어는 이 Predicted PC 값을 파이프라인의 다음 Fetch 주소로 강제로 덮어씌웁니다.