용어
1. DNN (Deep Neural Network: 심층 신경망)
- 개념: 아주 넓은 의미의 '포괄적인 단어(Umbrella term)'입니다. 입력층(Input layer)과 출력층(Output layer) 사이에 숨겨진 층(Hidden layer)이 여러 개(Deep) 존재하는 모든 신경망을 걍 뭉뚱그려서 DNN이라고 부릅니다.
- 하드웨어 관점: 층(Layer)이 깊다는 것은 곧 곱하고 더해야 할 MAC (Multiply-Accumulate) 연산량과, 메모리에서 불러와야 할 가중치(Weight) 데이터가 어마어마하게 많다는 뜻입니다.
2. MLP (Multi-Layer Perceptron: 다층 퍼셉트론)
- 개념: DNN의 가장 기본적이고 클래식한 형태입니다. 앞 층의 모든 노드가 다음 층의 모든 노드와 1:1로 촘촘하게 전부 연결되어 있습니다. 이를 Fully Connected (FC) Layer라고 부릅니다.
- 하드웨어 관점 (Memory-bound): 모든 노드가 연결되어 있으니 가중치(Weights)의 개수가 기하급수적으로 많습니다. 게다가 한 번 불러온 가중치는 딱 한 번 곱해지고 버려집니다 (No Weight Reuse). 즉, 연산기(MAC)는 쌩쌩한데 메모리에서 가중치를 가져오는 속도가 못 따라가서 성능이 떨어지는 전형적인 Memory-bound 워크로드입니다. (방금 읽으신 구글 TPU 논문에서 지적한 핵심 문제점이죠!)
3. CNN (Convolutional Neural Network: 합성곱 신경망)
- 개념: 주로 이미지 처리(Image Recognition)에 쓰입니다. 작은 필터(Filter 또는 Kernel)가 이미지 위를 돋보기처럼 슬라이딩하면서 특징(Edge, Shape 등)을 뽑아냅니다.
- 하드웨어 관점 (Compute-bound): 이전에 직접 FPGA로 깎아보셨던 하드웨어 가속기가 바로 이 녀석을 타겟으로 한 겁니다! CNN은 동일한 필터 가중치(Weight)를 이미지 전체에 걸쳐서 계속 재사용합니다 (High Weight Reuse). 메모리에서 데이터를 한 번만 가져오면 연산기들이 쉴 새 없이 일할 수 있으므로 연산량이 칩의 성능을 좌우하는 Compute-bound 워크로드입니다. Systolic Array 구조가 빛을 발하는 영역입니다.
4. RNN (Recurrent Neural Network: 순환 신경망)
- 개념: 이전의 결과가 다음 결과에 영향을 미치는 순차적인 데이터 (Sequential Data)를 처리합니다. (예: 음성 인식, 번역 등 "나는 밥을..." 다음에 "먹는다"가 나오는 것을 예측). 내부에 루프(Loop)가 있어서 과거의 정보를 '기억'합니다.
- 하드웨어 관점 (Sequential Dependency): 하드웨어 엔지니어가 제일 싫어하는 구조입니다. 시간 의 연산을 하려면 반드시 의 결과가 있어야 합니다. 즉, 파이프라인에서 배웠던 데이터 의존성(Data Hazard)이 알고리즘 자체에 박혀있어서, 병렬 처리(Parallelism)를 극대화하기가 매우 까다롭습니다.
5. LSTM (Long Short-Term Memory: 장단기 메모리)
- 개념: 기존 RNN이 너무 오래된 과거의 기억을 까먹어버리는 문제(Vanishing Gradient)를 해결하기 위해 나온 RNN의 진화 버전입니다. 내부에 기억을 유지할지 버릴지 결정하는 복잡한 문(Gates: Forget, Input, Output gate)들을 달아놨습니다.
- 하드웨어 관점: 구조가 똑똑해진 대신, 계산해야 할 행렬 연산(Matrix Multiplication)이 기본 RNN보다 4배로 늘어났습니다. 구글 데이터센터 워크로드의 상당수를 차지하며, 막대한 양의 가중치를 계속 불러와야 해서 이 역시 지독한 Memory-bound 특성을 가집니다.
요약
설계 배경: "왜 만들었는가? (Motivation)"
-
타겟은 오직 추론(Inference): 이 TPU는 딥러닝 모델을 학습(Training)시키는 용도가 아닙니다. 이미 학습된 모델을 실제 서비스(음성 인식, 검색 등)에 적용해 결과를 뽑아내는 추론(Inference 또는 Prediction)에 100% 올인한 커스텀 ASIC입니다.
-
비용과 전력의 한계: 구글 사용자들이 음성 검색을 하루 3분씩만 써도 기존 CPU 서버로는 감당이 안 되는 상황이었습니다. 목표는 기존 GPU 대비 가성비(Cost-Performance)를 10배 이상 끌어올리는 것이었습니다.
2. 하드웨어 아키텍처: "어떻게 생겼는가? (Architecture)"
일반적인 CPU/GPU에 있는 복잡한 기능(Cache, Branch Prediction, Out-of-order execution)을 싹 다 버리고, 오직 행렬 곱셈(Matrix Multiplication)에만 칩 면적을 몰빵했습니다.
-
Systolic Array (시스톨릭 어레이): 이 칩의 심장입니다. 무려 65,536개의 8-bit MAC(Multiply-Accumulate) 유닛이 256x256 배열로 꽉 차 있습니다. 데이터를 매번 메모리에서 읽지 않고, 심장 박동처럼 연산기 사이로 데이터를 흘려보내며 연산 효율을 극대화했습니다.
-
Quantization (양자화): 딥러닝 추론은 굳이 무거운 32-bit 부동소수점(Floating-point)이 필요 없습니다. 이를 8-bit 정수(Integer)로 압축하여 칩의 크기(Area)와 전력 소모(Power)를 획기적으로 줄였습니다.
-
Unified Buffer: 28 MiB 크기의 거대한 온칩 SRAM입니다. 하드웨어가 알아서 관리하는 캐시(Cache)가 아니라, 소프트웨어가 직접 주소를 관리하는 버퍼를 써서 설계 복잡도를 낮췄습니다.
-
Deterministic Execution: 분기 예측이나 비순차 실행이 없기 때문에, 명령어가 실행되는 시간이 항상 일정하고 예측 가능(Deterministic)합니다.
3. 성능 분석 핵심: "진짜 중요한 게 무엇인가? (Performance)"
논문에서는 CPU(Intel Haswell) 및 GPU(Nvidia K80)와 TPU의 성능을 비교합니다. 여기서 면접관들이 가장 좋아하는 인사이트가 나옵니다.
-
Throughput (처리량) vs. Response-time (응답 시간): * 데이터센터의 실제 서비스는 유저가 답답함을 느끼지 않도록 99%의 요청이 특정 시간(예: 7ms) 안에 끝나는 엄격한 99th-percentile response-time 제한이 있습니다.
- GPU는 데이터를 몽땅 모아서 한 번에 처리하는 Throughput은 높지만, 이 빡빡한 Latency 제한을 맞추지 못해 실제 성능을 다 뽑아내지 못했습니다. 반면 TPU는 구조가 단순해서 레이턴시 방어에 압도적으로 유리했습니다.
-
압도적인 전성비 (Performance/Watt): 결과적으로 TPU는 CPU, GPU 대비 15~30배 빠르며, 전력 대비 성능(TOPS/Watt)은 무려 30~80배 높았습니다.
-
Roofline Model (루프라인 모델) 분석: * CNN 모델은 연산량이 많아 피크 성능을 쳤지만(Compute-bound), 실제 구글 트래픽의 95%를 차지하는 MLP나 LSTM 모델들은 연산기보다 메모리에서 데이터를 가져오는 속도가 느려서 성능을 못 내는 Memory-bound 상태였습니다.
그래서 기존 CPU/GPU랑 비교해서 TPU가 뭐가, 왜 좋은데?
- Inference apps usually emphasize response-time over throughput since they are often user facing.
- 유저가 구글에 음성 검색을 했는데 1초 넘게 멍 때리면 다들 앱을 꺼버리겠죠? 데이터센터에서는 한 번에 많은 데이터를 처리하는 것(Throughput)보다, 단 한 명의 요청이라도 제한 시간(예: 7ms) 안에 지연 없이 처리하는 것(Latency/Response-time)이 생명이라는 뜻입니다.
- As a result of latency limits, the K80 GPU is just a little faster for inference than the Haswell CPU, despite it having much higher peak performance and memory bandwidth.
- K80 GPU는 덤프트럭입니다. 짐(데이터)을 한가득 모아야 진가가 발휘되는데, 지연 시간 제한 때문에 짐이 모이기도 전에 바로바로 출발해야 하니 제 성능을 못 낸 겁니다. 결국 평범한 승용차(CPU)랑 속도가 비슷해지는 굴욕을 겪었다는 의미입니다.
what is K80?
Nvidia Tesla K80은 구글이 1세대 TPU를 데이터센터에 깔기 시작했던 2015년 당시, 전 세계 데이터센터와 인공지능 업계를 씹어 먹고 있던 끝판왕 GPU
Dual-GPU Architecture (듀얼 칩 구조):
K80은 특이하게도 하나의 거대한 그래픽 카드 보드 안에 GPU 칩(Die)이 2개가 박혀있는 무식하고 강력한 구조입니다.
Throughput-Oriented (처리량 중심):
수천 개의 스레드(Threads)를 동시에 돌려서 엄청난 양의 데이터를 한 번에 밀어버리는 데 특화되어 있습니다.
High Memory Bandwidth (초고속 메모리 대역폭):
TPU v1이 구형 DDR3 메모리를 쓴 것과 달리, K80은 당시 최고급이었던 GDDR5 메모리를 달아서 데이터를 퍼 나르는 속도가 엄청나게 빨랐습니다.
Floating-Point Master (부동소수점 마스터):
무겁고 정밀한 32비트 부동소수점(FP32) 연산을 아주 기가 막히게 잘합니다.- While most architects are accelerating CNNs, they are just 5% of our datacenter workload.
- 논문 저자의 뼈 있는 일침입니다. "너네 맨날 학회에서 이미지 처리하는 CNN만 연구하는데, 실제 구글 서버에서 돌아가는 건 다중 퍼셉트론(MLP)이나 순환 신경망(LSTM)이 95%야. 현실 좀 봐!"라는 뜻입니다.
- The TPU is about 15X – 30X faster at inference than the K80 GPU and the Haswell CPU.
- TPU는 K80 GPU 및 Haswell CPU보다 추론(Inference) 작업에서 약 15~30배 더 빠르다.
- Four of the six NN apps are memory bound; if the TPU were revised to have the same memory as the K80 GPU, it would be about 30X – 50X faster than the GPU and CPU.
- TPU 연산기 자체는 엄청나게 빠르지만, 데이터를 창고(메모리)에서 가져오는 길이 좁아서 연산기가 놀고 있는 상태(Memory bound)라는 뜻입니다. GPU처럼 빠방한 메모리만 달아주면 성능이 훨씬 더 폭발할 거라는 아쉬움 섞인 자신감입니다.
- Despite having a much smaller and lower power chip, the TPU has 25 times as many MACs and 3.5 times as much on-chip memory as the K80 GPU.
- 칩 크기도 훨씬 작고 전력도 적게 먹지만, TPU는 K80 GPU보다 곱셈-누산기(MACs)가 25배나 많고 온칩 메모리(On-chip memory)도 3.5배나 많다.
- TPU는 범용 GPU가 가진 복잡한 캐시나 컨트롤 로직을 싹 다 갖다 버렸기 때문에, 남는 공간에 순수 연산기(8-bit MAC)와 데이터를 쟁여둘 SRAM(Unified Buffer)을 미친 듯이 때려 박을 수 있었다는 구조적 장점을 어필하는 겁니다.
- The performance/Watt of the TPU is 30X – 80X that of its contemporary CPUs and GPUs; a revised TPU with K80 memory would be 70X – 200X better.
- 데이터센터 운영에서 가장 무서운 건 전기세와 발열입니다. 성능도 성능이지만, 1와트(Watt) 당 뽑아내는 성능이 기존 대비 수십 배 좋다는 것은 기업 입장에서 엄청난 비용 절감(TCO)을 의미합니다.
왜 파이프라인에 좋은 최신 RISC를 버리고 구식 CISC를 썼을까?
RISC의 한계 (TPU 환경에서): 승윤님 말씀대로 RISC는 1클럭에 1명령어씩 쪼개서 파이프라인(Pipeline)을 돌리기 최고입니다. 하지만 TPU는 CPU 옆에 딱 붙어있는 게 아니라, 저 멀리 느려터진 PCIe I/O bus를 건너가야 합니다. 만약 TPU가 RISC 구조였다면, CPU는 데이터 하나 곱할 때마다 "가져와", "더해", "저장해" 같은 짤짤이 명령어 수만 개를 PCIe 버스로 던져야 하고, 결국 명령어 트래픽 때문에 버스가 터져버렸을 겁니다.
CISC의 부활: 그래서 구글은 한 번의 명령으로 아주 길고 복잡한 일을 수행하는 CISC를 부활시켰습니다. CPU가 PCIe 버스를 통해 "야, 저기 256x256 행렬 전체 한 번에 싹 다 곱해! (MatrixMultiply)"라는 묵직한 CISC 명령어 딱 하나만 툭 던져놓으면, TPU는 CPU 간섭 없이 자기 혼자서 수천 사이클 동안 땀 흘리며 묵묵히 행렬 곱셈을 다 끝내버립니다. (통신 병목 완벽 해결!)
TPU Block Diagram
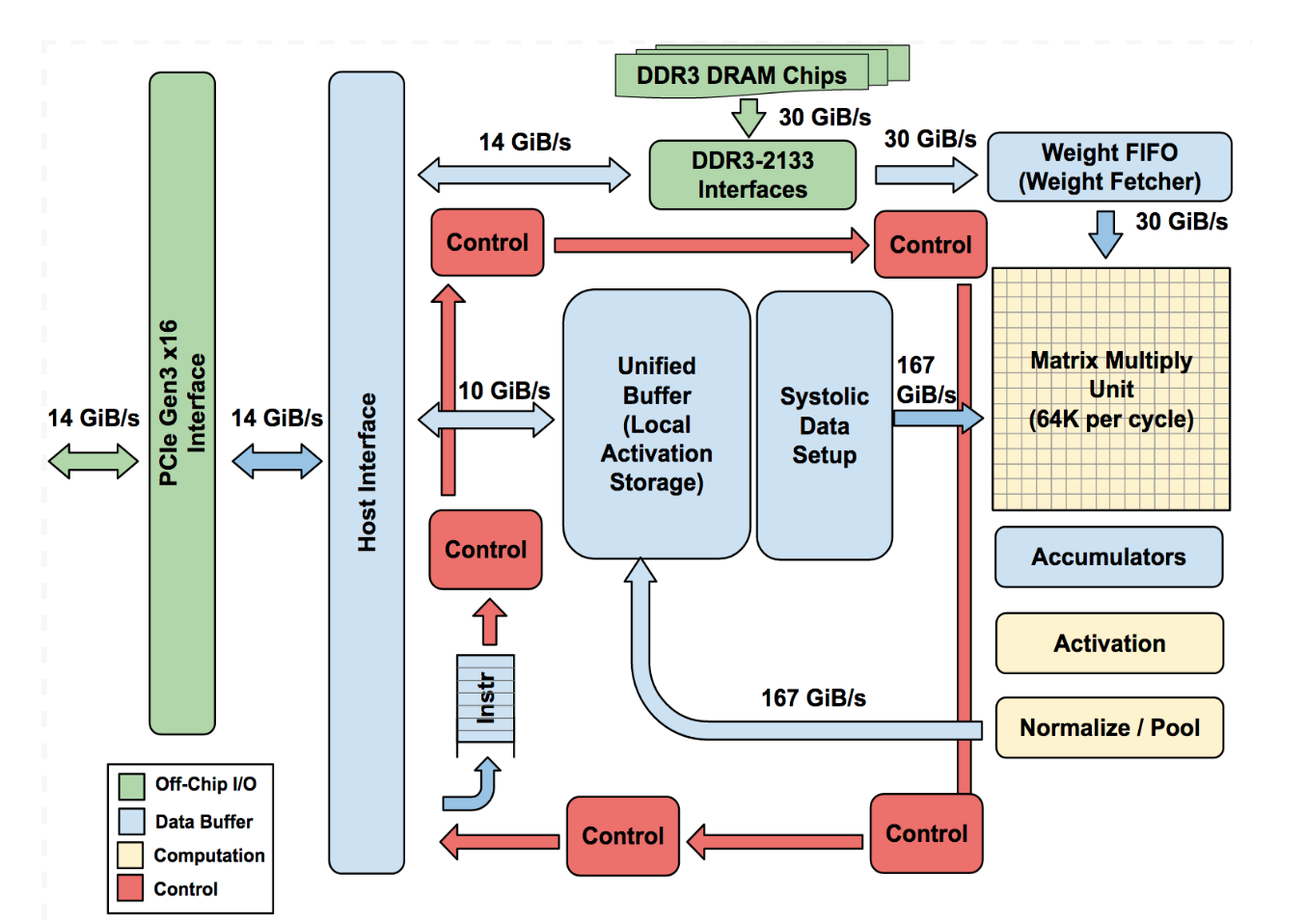
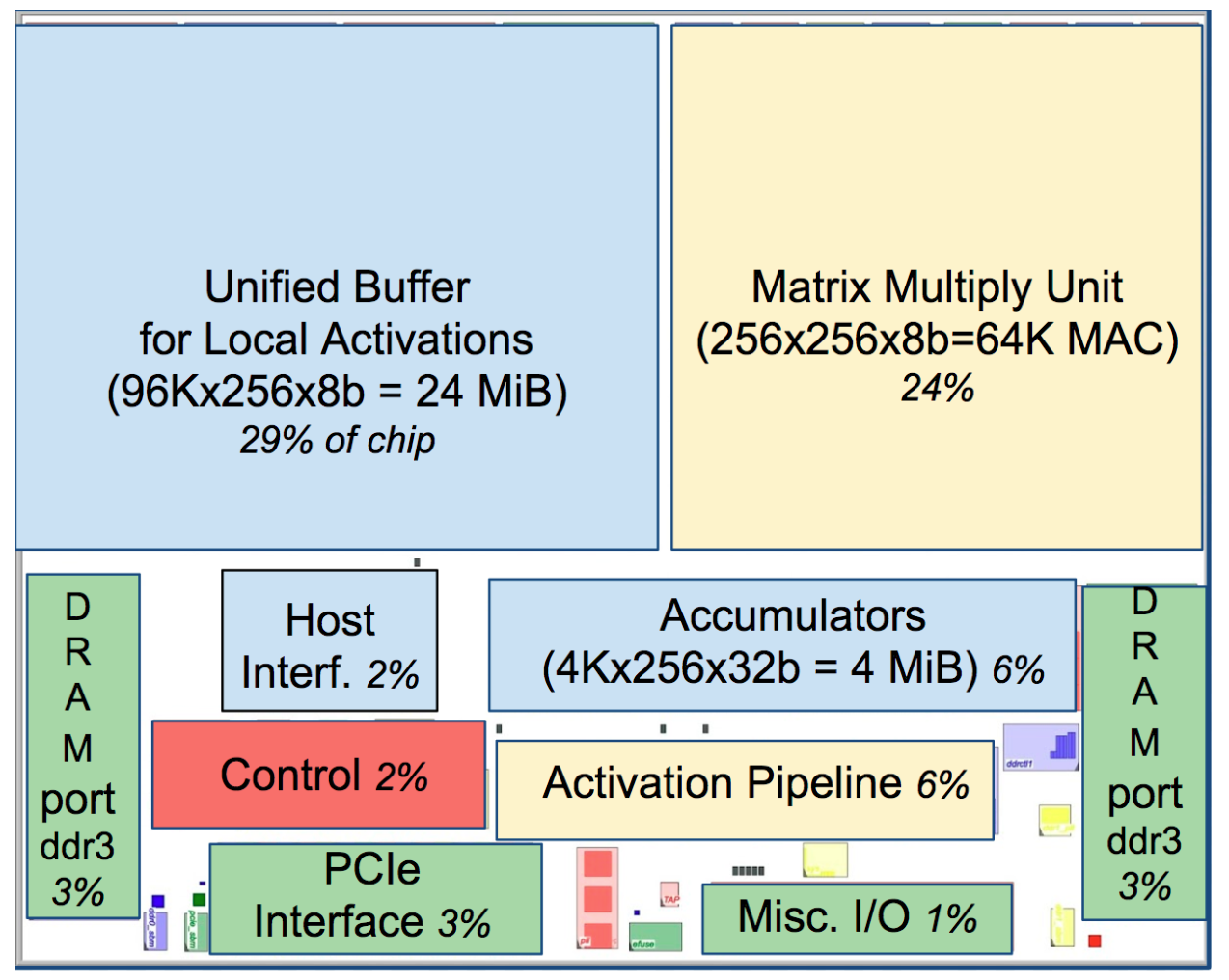
[ 입고 및 준비 ]
Step 1. Read_Host_Memory (원자재 입고): 칩 바깥의 CPU 램(Host Memory)에 있는 원본 데이터(예: 고양이 사진 픽셀 값)를 TPU 안방에 있는 거대한 Unified Buffer로 쓱 가져옵니다.
Step 2. Read_Weights (가공 레시피 준비): 동시에, 외부 램(Weight Memory)에 저장되어 있던 딥러닝 모델의 가중치(Weights)들을 칩 내부의 대기열인 Weight FIFO로 줄 세워 가져옵니다.
[ 메인 공정 ]
Step 3. MatrixMultiply / Convolve (쾅! 행렬 곱셈): 이 공장의 핵심입니다. Unified Buffer에 있는 데이터와 Weight FIFO에 대기 중이던 가중치를 심장부인 Matrix Multiply Unit (MMU)에 밀어 넣고 무식하게 곱합니다. 곱셈이 끝난 엄청난 양의 결과물(16-bit)은 바닥에 있는 널찍한 대야, Accumulators에 쏟아부어 모아둡니다.
[ 포장 및 출고 ]
Step 4. Activate (포장 - 비선형 함수 씌우기): Accumulators에 고여있는 숫자의 홍수들에다가 인공신경망 특유의 함수(ReLU, Sigmoid 등)를 쫙 씌워줍니다. 처리가 끝난 예쁜 결과물들은 다시 Unified Buffer로 올려보냅니다.
Step 5. Write_Host_Memory (완제품 출고): 모든 가공이 끝나고 Unified Buffer에 저장된 최종 결과물(Inference 결과)을 다시 PCIe bus를 태워서 CPU 램으로 돌려보냅니다. "주인님, 계산 다 끝났습니다!"
PCIe와 SATA의 관계 (헷갈림 방지)

아까 제가 TPU는 PCIe 버스를 타고 통신한다고 했죠? 그런데 왜 여기서 SATA 이야기가 나올까요?
모양은 SATA, 통신은 PCIe: TPU 카드의 물리적인 크기나 꽂는 방식은 서버의 SATA 베이(구멍)에 딱 맞게 만들었지만, 실제 그 구멍 안쪽의 연결 선은 PCIe 프로토콜을 지원하도록 개조해 둔 겁니다.
즉, "겉모양은 하드디스크처럼 생겨서 설치하기 편한데, 속도는 그래픽카드처럼 빠른 PCIe 고속도로를 쓴다"는 뜻입니다.
TPU IMPLEMENTATION, AND SOFTWARE
- 12바이트의 예술: CISC 명령어의 구조
내용: MatrixMultiply 명령어는 딱 12바이트(Bytes)로 이루어져 있습니다.
- Unified Buffer 주소 (3바이트) + Accumulator 주소 (2바이트) + 행렬 길이 (4바이트) + 나머지 Opcode 및 설정값들.
- 파이프라인 겹치기 (Overlapped Execution)
-
철학: "가장 크고 비싼 Matrix Multiply Unit (MMU)을 절대 놀게 하지 마라!"
-
동작 방식: TPU는 이 CISC 명령어들을 처리하기 위해 4단계 파이프라인(4-stage pipeline)을 씁니다. 핵심은 MatrixMultiply가 수천 사이클 동안 돌아가는 그 긴 시간 뒤에 숨어서(hide), 다른 명령어들을 동시에 겹쳐서 실행(overlapping)하는 것입니다.
-
Decoupled-access/execute: 예를 들어 Read_Weights 명령어는 "가중치 가져와!"라고 주소만 딱 던져놓고 자기 할 일은 끝냈다고 칩니다. 진짜 가중치가 메모리에서 도착하는 건 뒤에서 몰래 진행되는 거죠.
- 피할 수 없는 RAW Hazard와 Stall
-
문제점: 우리가 아는 MIPS 파이프라인은 1클럭에 1칸씩 예쁘게 움직이지만, TPU의 CISC 명령어는 한 스테이션에 수천 클럭(1000s of clock cycles)씩 머뭅니다. 그래서 예쁜 파이프라인 다이어그램을 그릴 수가 없습니다.
-
RAW (Read-After-Write) pipeline stall: 아까 우리가 그토록 파고들었던 그 해저드가 여기서 등장합니다!
-
딥러닝은 층(Layer)이 겹겹이 쌓여있죠? N번째 레이어의 연산(Activations)이 완전히 끝나서 Unified Buffer에 결과가 다 써져야(Write), 비로소 N+1번째 레이어가 그 값을 읽어서(Read) 다음 MatrixMultiply를 시작할 수 있습니다.
-
데이터가 완벽하게 준비될 때까지 MMU는 명시적인 동기화(explicit synchronization)를 기다리며 하염없이 멈춰 서야(Stall) 합니다. (DV 엔지니어들이 칩 검증할 때 가장 머리털 빠지는 '코너 케이스'가 바로 이런 겹침과 스톨이 일어나는 타이밍입니다!)
-
- 전기를 아끼는 마법: 시스톨릭 실행 (Systolic Execution)
-
이유: 아주 거대한 SRAM(Unified Buffer)에서 데이터를 읽고 쓰는 것은 계산하는 것보다 전력을 훨씬 많이 먹습니다.
-
해결책: 그래서 Systolic execution을 도입했습니다. 데이터를 어레이(배열) 왼쪽에서 흘려보내고, 가중치를 위에서 흘려보내면, 마치 대각선 파도(diagonal wavefront)가 치듯이 데이터가 연산기 셀들을 통과하며 알아서 곱해지고 더해집니다.
-
결과: 거대한 SRAM을 매번 읽고 쓸 필요가 없어져서 엄청난 에너지가 절약됩니다. 소프트웨어 프로그래머는 이 파도치는 구조를 몰라도 되지만, 성능을 쥐어짜려면 이 장치의 지연 시간(Latency)을 고려해서 코딩해야 합니다.
- 구글의 꿀단지: 소프트웨어 스택 (Software Stack)
- 호환성: 개발자들이 TPU 쓰겠다고 코드를 밑바닥부터 새로 짜면 아무도 안 쓰겠죠? 그래서 기존 CPU/GPU에서 쓰던 TensorFlow (텐서플로우) 코드를 그대로 쓸 수 있게 API를 만들었습니다.
구조:
-
Kernel Driver (커널 드라이버): 메모리와 인터럽트만 관리하는 아주 가볍고 안정적인 녀석입니다.
-
User Space Driver: 얘가 진짜 핵심 워커(Worker)입니다. 텐서플로우 코드를 TPU가 알아들을 수 있는 CISC 명령어로 번역하고 메모리 순서를 재배치합니다.
-
첫 실행의 마법: 모델을 처음 실행할 때 한 번 싹 번역해서 캐시(caching)해두고, 두 번째부터는 딜레이 없이 최고 속도(full speed)로 뽑아냅니다. 연산을 한 번 칩에 올리면 바깥으로 나가지 않고 끝까지 칩 안에서 돌려서 I/O 오버헤드를 극단적으로 줄입니다.
Systolic Array
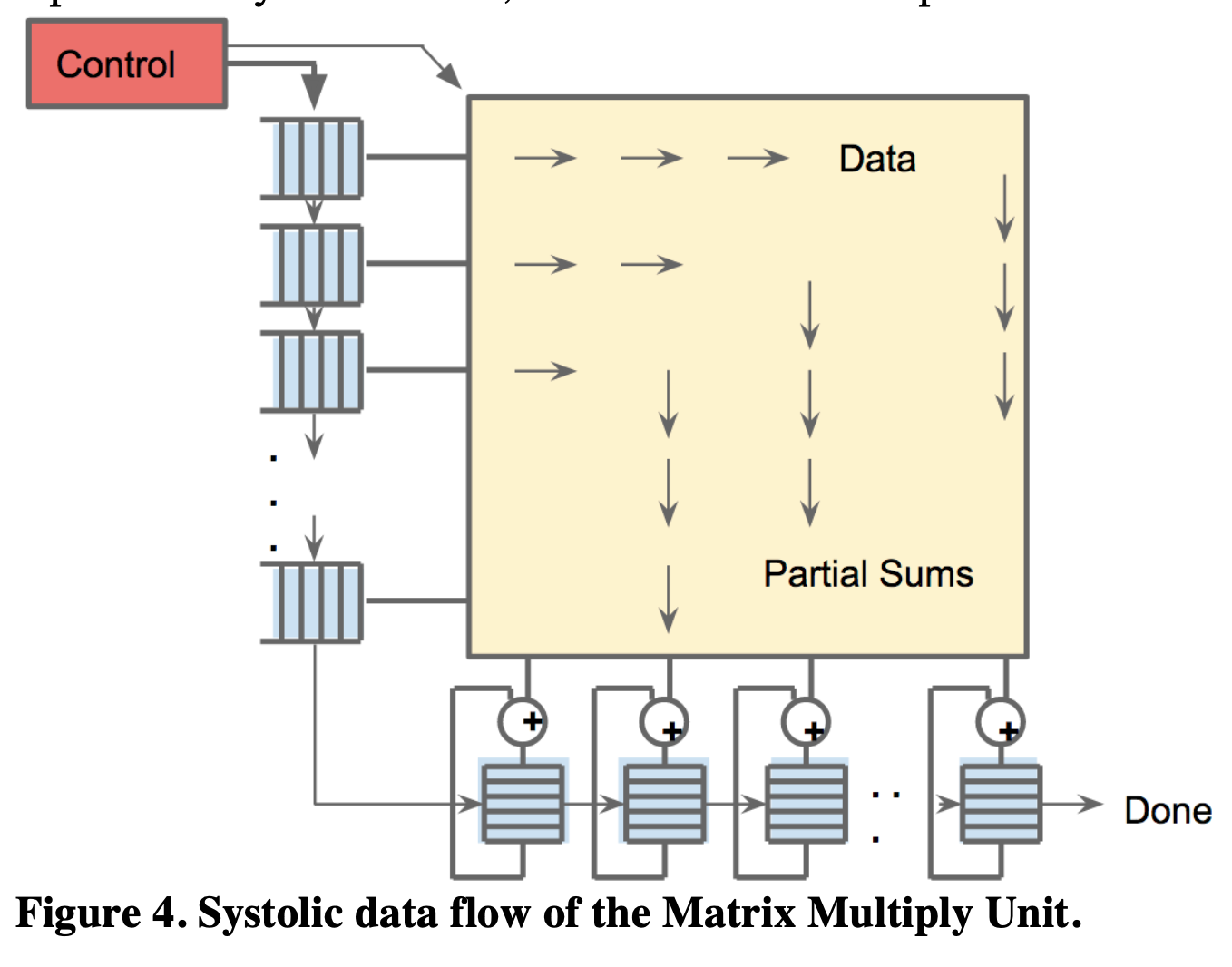
Systolic 이라는 단어는 원래 생물학/의학 용어로 '심장 수축기의(심박의)'라는 뜻입니다.심장이 쿵쾅(Clock) 뛸 때마다 피가 온몸의 핏줄을 타고 쫙 퍼져 흐르듯이, 칩의 클럭(Clock) 박동에 맞춰 데이터가 바둑판처럼 배열된 연산기들 사이를 맥박 치듯 흘러간다고 해서 붙여진 아주 시적인 이름입니다.
왜 만들었을까? (해결하려는 문제점)
-
기존의 무식한 방식: 일반적인 프로세서가 곱셈을 하려면 매번 1) 메모리(SRAM)에서 데이터 A를 읽고, 2) 데이터 B를 읽고, 3) 연산기에서 곱하고, 4) 결과를 다시 메모리에 저장해야 합니다.
-
진짜 병목 (Energy & Bandwidth Wall): 반도체 칩에서 곱셈기(MAC)를 한 번 돌리는 데 전기가 1만큼 든다면, 거대한 메모리(SRAM)에 접근해서 데이터를 꺼내오는 데는 전기가 수십~수백 배 더 듭니다. 매번 메모리에 들락날락하면 전기세(발열) 폭탄을 맞고 속도도 뚝 떨어집니다.
Systolic Array의 천재적인 작동 방식
Processing Element (PE)의 바둑판 배열: 칩 내부에 곱셈-누산기인 MAC (Multiply-Accumulate) 유닛들을 2D 바둑판 형태(Array)로 수만 개 쫙 깔아둡니다. (TPU는 256x256 = 65,536개)
물통 릴레이 패스 (Data Reuse): 메모리에서 데이터를 딱 한 번만 꺼내서 맨 모서리에 있는 PE에게 줍니다. 그러면 이 PE가 계산을 마친 뒤, 데이터를 메모리로 다시 돌려보내지 않고 바로 옆자리 PE에게 직접 토스(Pass)해 버립니다.
파도타기 연산 (Wavefront): 위에서 아래로는 가중치(Weights)가 흘러내리고, 왼쪽에서 오른쪽으로는 데이터(Activations)가 흘러갑니다. 이 두 데이터가 교차하는 모든 PE 셀에서 쉴 새 없이 동시다발적으로 곱셈과 덧셈이 일어납니다.
"The Systolic Array maximizes Data Reuse by passing data directly between adjacent PEs (Processing Elements)."
(시스톨릭 어레이는 인접한 PE들끼리 데이터를 직접 전달하여 데이터 재사용을 극대화한다.)
"This architectural design drastically reduces expensive SRAM Accesses, overcoming the Memory Bandwidth bottleneck and significantly improving the overall Energy Efficiency of the ML accelerator."
(이 아키텍처 설계는 값비싼 SRAM 접근을 획기적으로 줄여, 메모리 대역폭 병목을 극복하고 ML 가속기의 전체 전력 효율을 크게 향상시킨다.)
TPU가 기존의 CPU, GPU와 물리적으로 어떻게 다르고, 내부 연산은 어떤 방식으로 이루어지나?
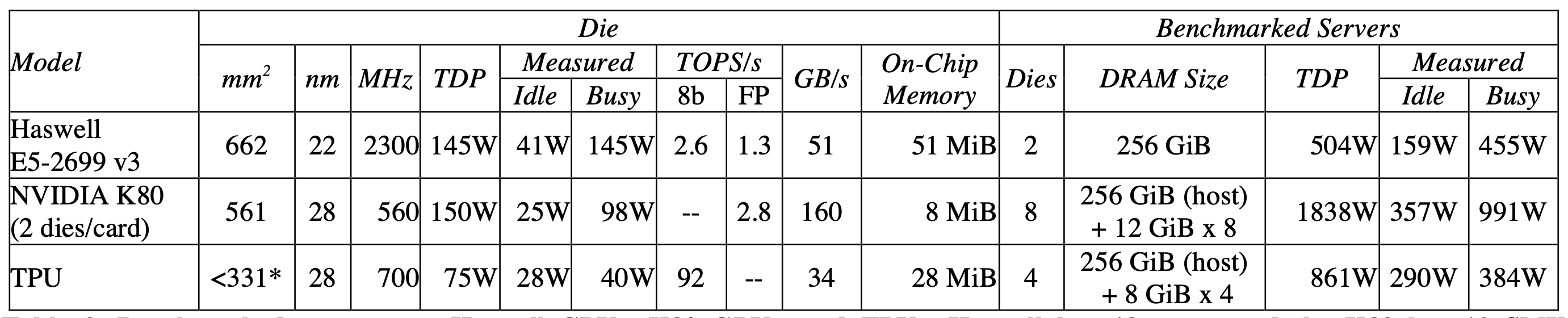
서버급 장비 (Server-class computers): 2015년 당시 데이터센터에서 실제로 쓰이던 장비들만 골랐습니다. 특히 메모리 오류를 잡아내는 SECDED (Single Error Correction, Double Error Detection) 보호 기능이 있는 칩만 선정했습니다. (이 때문에 Nvidia Maxwell 아키텍처는 제외되었습니다.)
-
크기와 전력 (Die Size & Power): TPU의 다이 크기()는 CPU와 GPU의 절반 수준입니다. 전력 소모(Busy Power) 역시 40W로, GPU(98W)나 CPU(145W)에 비해 압도적으로 낮습니다.
-
극한의 연산 성능 (TOPS/s): 무거운 32-bit 부동소수점(FP) 연산기를 빼버리고 가벼운 8-bit 정수 연산기를 꽉꽉 채워 넣은 덕분에, TPU는 92 TOPS라는 경이로운 피크 성능을 달성합니다.
-
메모리의 극단적 불균형 (Memory Bottleneck):
- 강점: 칩 내부의 임시 저장소인 On-Chip Memory (SRAM)는 28 MiB로 가장 큽니다.
- 약점: 하지만 칩 외부의 메인 메모리에서 데이터를 가져오는 속도인 대역폭(GB/s)은 고작 34 GB/s로, GPU(160 GB/s)에 비해 턱없이 부족합니다. 이 숫자가 바로 TPU가 맞닥뜨린 Memory-bound (메모리 병목)의 근본적인 원인입니다.
Roofline Model
1. Roofline Model의 기초 개념 (본문 1~3문단)
이 시각적 모델은 애플리케이션이 온칩 캐시에 다 들어가지 않는다는 가정하에, 성능 병목의 원인이 연산기인지 메모리인지 판별하는 도구입니다.
-
X축 (Operational Intensity): 연산 강도. 메모리(DRAM)에서 데이터 1바이트를 가져왔을 때, 칩이 연산을 몇 번이나 우려먹을 수 있는지 나타냅니다. (TPU의 경우 가중치 1바이트당 정수 연산 횟수로 정의했습니다.)
-
Y축 (Performance): 칩이 1초당 처리하는 연산량(FLOPS 또는 TOPS)입니다.
두 개의 지붕 (The Roofs):
-
평평한 지붕 (Flat part): 칩의 최대 연산 속도(Peak computation rate)를 나타냅니다. 데이터는 충분히 공급되고 있는데 연산기가 100% 돌아가서 더 이상 속도를 낼 수 없는 Compute-bound (연산 병목) 구역입니다.
-
기울어진 지붕 (Slanted part): 칩의 메모리 대역폭(Memory bandwidth) 한계를 나타냅니다. 연산기는 놀고 있는데 메모리에서 데이터가 너무 늦게 와서 성능을 못 내는 Memory-bound (메모리 병목) 구역입니다.
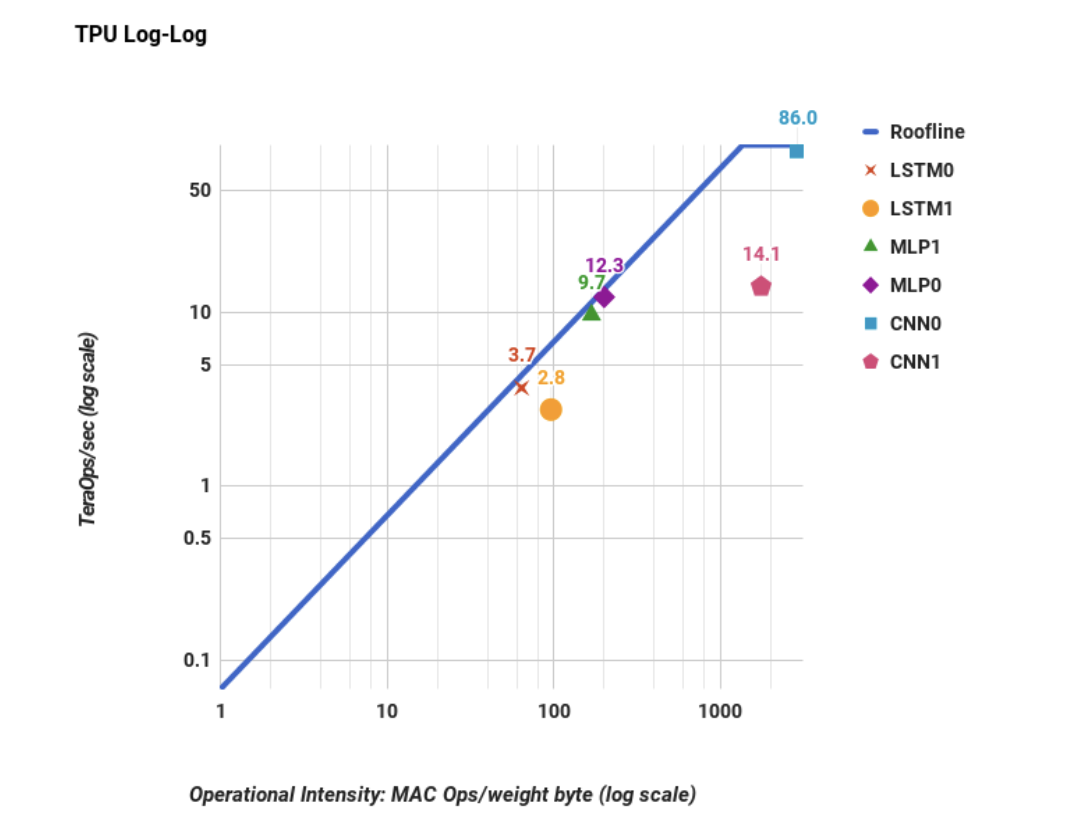
2. Figure 5: TPU는 현실에서 어땠는가?
Figure 5를 보시면 TPU의 슬픈 현실이자 이 논문의 핵심 주장이 여실히 드러납니다.
기울어진 지붕 밑의 희생자들: 6개의 워크로드 중 5개가 지붕(한계선)에 머리를 쿵쿵 박고 있습니다. 특히 구글 데이터센터의 주력인 MLP와 LSTM은 모두 Slanted part 아래에 위치하여 극심한 Memory bandwidth-bound 상태임을 보여줍니다. (데이터를 못 가져와서 연산기가 굶고 있음)
모범생 CNN0: CNN0은 X축(연산 강도)이 엄청나게 높아서 기울어진 지붕을 탈출해 평평한 지붕에 도달했습니다. 86 TOPS라는 피크 성능에 도달한 전형적인 Computation-bound 워크로드입니다.
3. Table 3: "CNN1은 왜 저 모양인가?" (Anomaly Analysis)
Figure 5를 보면, CNN1은 X축(연산 강도)이 굉장히 높음에도 불구하고 지붕까지 올라가지 못하고 바닥(14.1 TOPS)에 뚝 떨어져 있습니다. 연산 강도를 건드리지 않고 성능 튜닝만으로 지붕까지 올라갈 수 있는 잠재력(Gap)이 엄청나게 크다는 뜻입니다. Table 3의 하드웨어 카운터가 그 이유를 낱낱이 고발합니다.
연산기 낭비 (Unused MACs): CNN1은 레이어의 피처 깊이(Feature depths)가 너무 얕아서, 연산 사이클 동안 65,536개의 거대한 MACs 중 절반 정도만 유용한 가중치를 쥐고 있었습니다. (Table 3, Row 2 & 3 참조)
데이터 대기 (Weight stall cycles): CNN1 내부에는 연산 강도가 32밖에 안 되는 4개의 Fully Connected 레이어가 섞여 있는데, 이때 가중치를 가져오느라 전체 사이클의 약 35%를 멍때리며 허비했습니다. (Table 3, Row 4)
파이프라인 꼬임 (RAW stalls): TPU의 파이프라인이 겹쳐서 실행(Overlapped execution)되다 보니, 앞 레이어의 결과가 나올 때까지 다음 레이어가 기다려야 하는 데이터 의존성 문제(RAW dependences) 때문에 23%의 사이클이 스톨(Stall)에 걸렸습니다. (Table 3, Row 7)
4. 다시 등장하는 Latency의 벽 (본문 마지막 두 문단)
CPU(Haswell)와 GPU(K80)는 왜 이 지붕 근처에도 못 갔을까요? 바로 응답 시간(Response-time) 때문입니다.
실제 서비스(User facing services)는 7ms 이내에 응답해야 한다는 엄격한 제한(99th-percentile response time limit)이 있습니다.
추론(Inference)은 처리량(Throughput)보다 지연 시간(Latency)을 훨씬 더 중요하게 여깁니다.
CPU와 GPU는 이 제한 시간을 맞추느라 데이터를 크게 모아서 처리하지 못했고, 결국 자신들의 최대 처리량의 42%, 37%밖에 성능을 내지 못했습니다. 반면, TPU는 구조가 단순하고 실행이 예측 가능해서 최고 처리량의 80%까지 뽑아냈습니다.
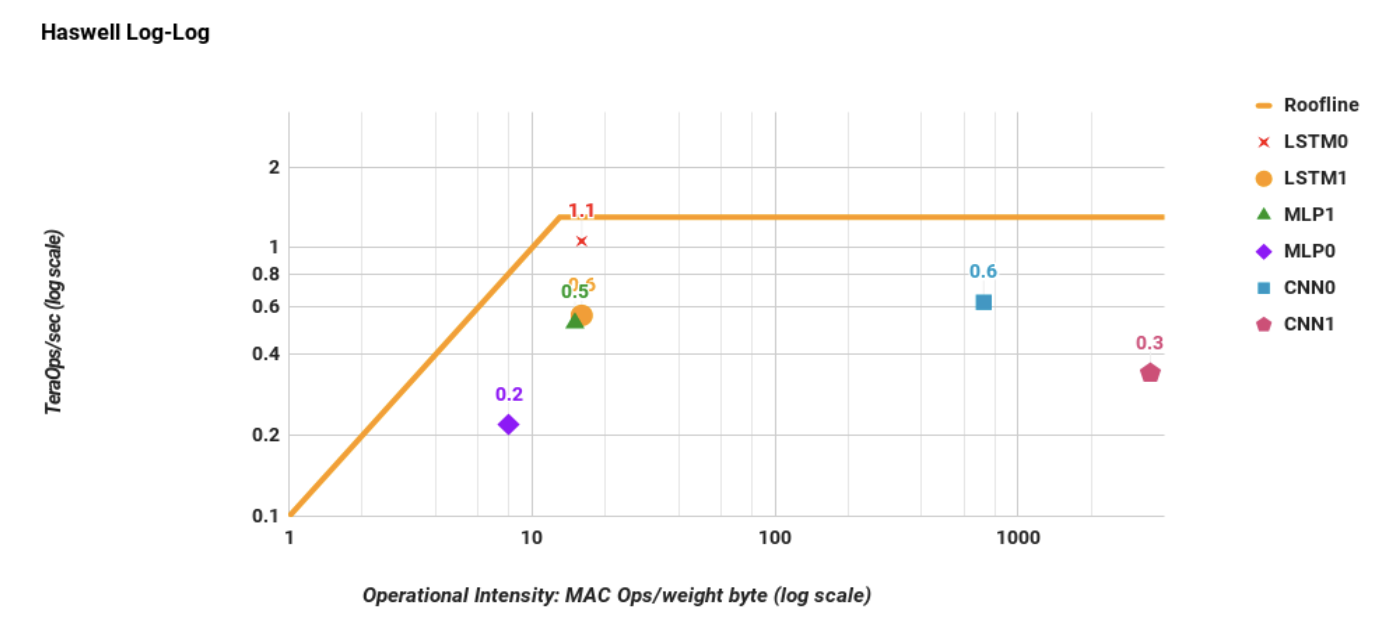
Figure 6. Intel Haswell CPU (die) roofline with its ridge point
at 13 multiply-accumulate operations/byte, which is much
further left than in Figure 5. LSTM0 and MLP1 are faster on
Haswell than on the K80, but it is vice versa for the other
DNNs. Response time limits DNN performance (Table 4).
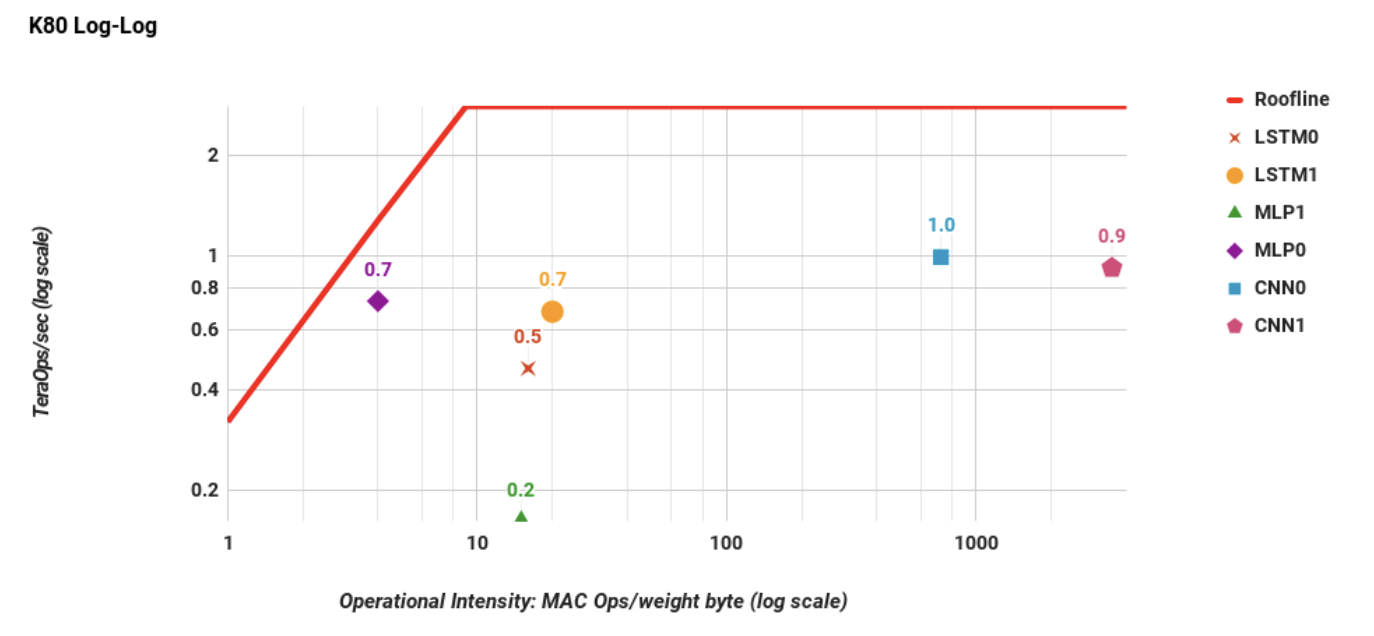
Figure 7. NVIDIA K80 GPU die Roofline. The higher memory
bandwidth moves the ridge point to 9 operations per weight
byte, which is further left than in Figure 6. The DNNs are far
from their Roofline because of response time caps (Table 4).
3대 하드웨어 스펙 변경 실험 결과
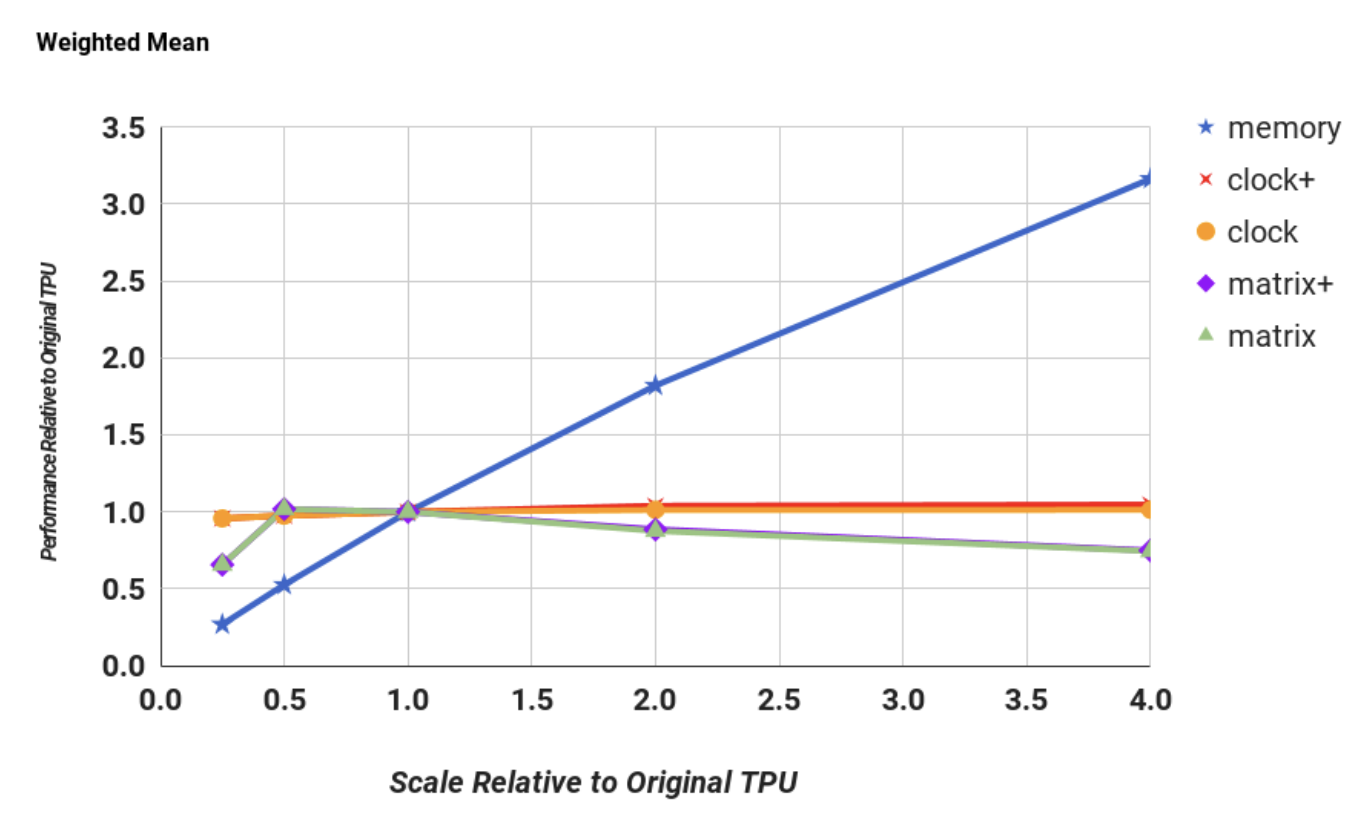
구글은 모델 성능을 측정하기 위해 세 가지 변수를 조작해 봅니다: 메모리 대역폭, 클럭 속도, 그리고 연산기(MMU)의 크기입니다.
① 메모리 대역폭 (Memory Bandwidth): 압도적 1위
결과: 대역폭을 4배 늘렸더니, 전체 평균 성능이 3배나 뛰었습니다.
이유: 워크로드의 90%를 차지하는 MLP와 LSTM이 지독한 Memory-bound 상태였기 때문에, 데이터가 들어오는 파이프(대역폭)를 넓혀주는 순간 막혀있던 성능이 뻥 뚫린 것입니다.
② 클럭 속도 (Clock Rate): 완전한 함정
결과: 클럭 속도를 아무리 팍팍 올려도 평균 성능은 거의 오르지 않았습니다.
이유: 밥(데이터)이 안 와서 주방장(연산기)이 놀고 있는데, 주방장 손놀림(클럭)만 4배 빠르게 해봤자 요리가 빨리 나올 리 없죠. (단, 연산 중심인 Compute-bound CNN은 클럭을 올린 만큼 성능이 2배 뛰었습니다.)
③ 연산기 크기 (Matrix Unit Size): 크다고 좋은 게 아니다! (핵심⭐)
결과: 256x256 크기였던 심장부(MMU)를 512x512로 4배나 무식하게 키웠더니, 오히려 평균 성능이 떨어지는(degrades) 대참사가 발생했습니다!
결론 (CONCLUSION)
1. 암달의 법칙을 깬 '풍요의 따름정리' (Cornucopia Corollary)
느린 I/O 버스(PCIe)에 묶여있고, 메모리 대역폭(Memory bandwidth)이 낮아서 6개 앱 중 4개가 메모리 병목(Memory-bound)에 걸렸음에도 불구하고, TPU는 엄청난 성능을 냈습니다.
저자들은 이를 "거대한 자원(MAC)의 활용률(Utilization)이 낮더라도, 애초에 자원 자체가 엄청나게 많고 싸다면 결과적으로 가성비 높은 성능(Cost-effective performance)을 낼 수 있다"고 요약합니다. (이를 Amdahl's Law에 빗대어 풍요의 따름정리라고 부릅니다.)
암달의 법칙:시스템의 전체 성능 향상은, 개선된 부분의 크기(비중)에 비례한다
가장 많이 사용되는 부분(Common Case)을 개선해야 진짜 성능이 올라간다
$$\text{Speedup} = \frac{1}{(1 - f) + \frac{f}{s}}$$2. 칩 설계의 '선택과 집중' (Resource Allocation)
TPU는 K80 GPU가 쓰던 무거운 32-bit 부동소수점(FP32) 대신, 8-bit 정수 시스톨릭 행렬 곱셈기(8-bit integer systolic matrix multipliers)를 채택해 면적과 에너지를 획기적으로 줄였습니다.
그 아낀 공간에 K80 대비 25배 많은 연산기(MACs)와 3.5배 큰 온칩 메모리(On-chip memory)를 때려 박았습니다. 심지어 전력은 절반 이하로 쓰면서 칩 크기도 훨씬 작습니다. 이 거대한 메모리 덕분에 앱들의 연산 강도(Operational intensity)를 끌어올릴 수 있었습니다.
3. 학계의 착각 꼬집기 (The CNN Fallacy)
학계(Architecture community)는 온통 CNN에 집중하지만, 실제 데이터센터 워크로드의 5%밖에 안 됩니다. MLP와 LSTM에 더 많은 관심을 가져야 합니다. (이건 마치 과거 설계자들이 실제로는 정수 연산(Integer)이 대세인데 부동소수점 연산기 최적화에만 집착했던 흑역사가 반복되는 것과 같습니다.)
4. 최악의 성능 지표 (IPS)
초당 추론 횟수인 IPS (Inferences per second)는 하드웨어 성능 지표로 쓰면 안 됩니다. 이건 하드웨어의 성능이라기보단 딥러닝 모델의 구조에 따라 고무줄처럼 변하기 때문에, CPU 시절의 MIPS나 MFLOPS보다도 훨씬 구린 지표입니다.
5. 처리량보다 중요한 레이턴시 (Latency > Throughput)
추론(Inference) 앱들은 유저가 바로 결과를 기다리기 때문에, 99%의 요청을 제한 시간 내에 처리해야 하는 엄격한 응답 시간 제한(99th-percentile latency deadlines)이 필수입니다.
K80 GPU는 학습(Training)엔 뛰어나지만 처리량(Throughput)에만 집중한 탓에, 이 레이턴시 기준을 맞추느라 추론 환경에서는 CPU(Haswell)보다 간신히 조금 더 빠른 수준에 그쳤습니다.
6. 압도적인 성적표 (Performance/Watt)
결과적으로 TPU 칩은 단일 스레드 구조와 방대한 메모리를 활용해 K80 대비 15배 빠르고, 전성비(Performance per Watt)는 29배나 높습니다. (CPU와 비교하면 29배 빠르고 전성비는 83배 높습니다).
만약 우리가 K80처럼 당시 최신이던 GDDR5 메모리만 달아줬더라면, 전성비가 GPU 대비 70배, CPU 대비 200배까지 떡상했을 겁니다.
7. [핵심 요약] TPU가 성공한 이유 (Why TPU Succeeded)
- 너무 크지 않고 딱 적당한 행렬 곱셈기(Matrix multiply unit)
- 소프트웨어로 직접 통제하는 거대한 온칩 메모리 (Software-controlled on-chip memory)
- CPU 간섭 없이 모델 전체를 칩 내부에서 돌릴 수 있는 능력
- 레이턴시 기준을 맞추기 딱 좋은 단일 스레드의 결정론적 실행 모델 (Single-threaded, deterministic execution)
- 범용 기능을 과감히 빼버려 달성한 작고 전력 소모가 적은 설계
- 가벼운 8-bit 양자화 (Quantization)
- 그리고 하드웨어 언어(Verilog)로 다시 짤 필요 없이 TensorFlow 코드를 그대로 포팅할 수 있는 소프트웨어 생태계
8. 도메인 특화 아키텍처의 시대 (Era of DSA)
컴퓨터 구조 역사상 자릿수가 다를 정도(Order-of-magnitude, 즉 10배 이상)의 성능 차이가 벌어지는 일은 극히 드뭅니다. TPU는 향후 특정 목적에 올인하는 도메인 특화 아키텍처(Domain-specific architectures, DSA)의 완벽한 원형(Archetype)이 될 것입니다.
