전체 요약
1. Core Contribution
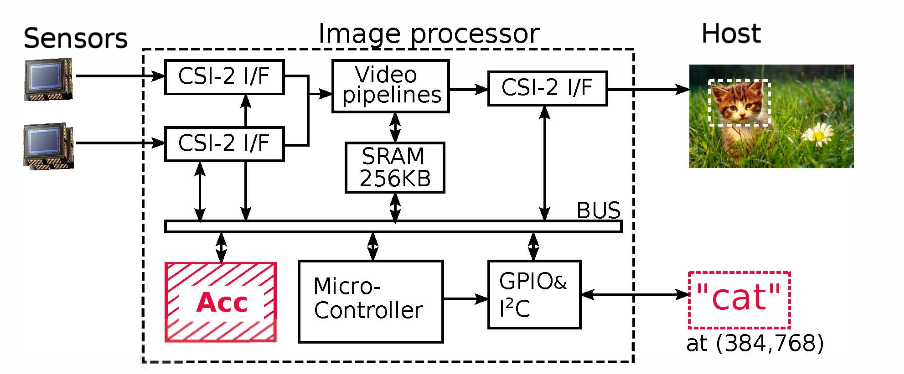
이 논문은 이미지 센서(CMOS/CCD) 바로 옆에 부착하여 DRAM 접근을 완전히 배제하는 데 초점을 맞춘 초저전력 CNN (Convolutional Neural Network) Accelerator인 ShiDianNao를 제안합니다.
이전 연구인 DianNao가 여전히 Memory bandwidth와 DRAM access energy에 병목 현상을 겪었던 것과 달리, 이 논문은 CNN 고유의 Weight sharing 특성을 역이용합니다. 즉, 필요한 전체 Synaptic weights의 크기가 작다는 점을 활용해 모델 전체를 On-chip SRAM에 저장하고, 센서로부터 들어오는 Input data만을 처리하여 외부 메모리 접근 비용을 완전히 제거했습니다.
2. Key Architectural Features
2D Mesh NFU (Neural Functional Unit):
기존 가속기들이 2D Feature map을 1D Vector로 처리해 비효율이 발생했던 반면, ShiDianNao는 PE (Processing Element)들을 2D 구조로 배열하여 이미지 데이터의 공간적 지역성(Spatial locality)을 극대화했습니다.
Inter-PE Data Propagation:
단순히 SRAM에서 데이터를 읽어오는 것을 넘어, 각 PE 내부에 수평/수직 FIFO (FIFO-H, FIFO-V)를 배치했습니다. 인접한 PE들끼리 한 번 읽은 Input neurons를 전달하고 재사용(Data reuse)함으로써, SRAM과 NFU 사이의 막대한 Internal bandwidth 요구량을 획기적으로 줄였습니다.
HFSM (Hierarchical Finite State Machine):
수만 사이클에 달하는 컨트롤 신호를 매번 메모리에서 읽어오면 Instruction memory가 비대해집니다. 이를 해결하기 위해 두 단계의 상태 머신(First/Second-level states)을 도입하여, 단 1KB의 Instruction storage만으로 복잡한 Control flow를 압축적으로 지원합니다.
3. Performance & Realistic Limitations
논문은 65nm 공정에서 4.86 의 면적과 320mW의 전력만으로 1GHz로 동작하며, 이전 세대인 DianNao 대비 약 60배의 에너지 효율을 달성했다고 보고합니다. 하지만 현실적인 관점에서 다음과 같은 분명한 제약이 존재합니다.
SRAM Capacity Bottleneck:
이 구조는 전체 모델 사이즈가 내부 SRAM (이 논문의 경우 288KB) 안에 완벽하게 들어맞아야만 성립합니다. 따라서 최근의 파라미터가 수십~수백 MB 단위를 넘어가는 거대한 Deep Learning 모델이나 DNN (Deep Neural Network)에는 이 아키텍처를 그대로 적용할 수 없습니다.
PE Underutilization (자원 낭비 문제):
한 번에 하나의 Output feature map을 계산하는 방식을 취하기 때문에, 만약 연산해야 할 Feature map의 크기가 하드웨어로 구현된 PE 배열의 크기(논문에서는 8x8)보다 작을 경우, 남는 PE들은 Idle 상태가 되어 컴퓨팅 자원의 낭비가 발생합니다 (논문의 Simple Conv 벤치마크 결과 참조).
Abstract
최근 몇 년 동안, Neural network accelerators(신경망 가속기)는 Recognition(인식) 및 Mining(마이닝) 애플리케이션이라는 중요한 범주 내의 광범위한 응용 분야에서 높은 Energy efficiency(에너지 효율성)와 Performance(성능)를 달성할 수 있음을 보여주었습니다.
그럼에도 불구하고, 이러한 가속기들의 Energy efficiency와 Performance는 여전히 Memory accesses(메모리 접근)에 의해 현실적인 제약을 받고 있습니다. 본 논문에서는 Recognition 및 Mining 애플리케이션 중 단연코 가장 중요한 범주인 Image applications(이미지 애플리케이션)에 초점을 맞춥니다.
이러한 애플리케이션을 위한 최첨단 신경망은 Convolutional Neural Networks (CNN)이며, 이는 매우 중요한 특성을 가집니다. 바로
- Weights(가중치)가 여러 뉴런 간에 공유되어 신경망의 Memory footprint(메모리 점유 공간)를 크게 줄여준다는 점입니다.
- 이 특성 덕분에 CNN 전체를 SRAM 내부에 매핑할 수 있으며,
- 결과적으로 Weights를 읽기 위한 모든 DRAM accesses를 완벽하게 제거할 수 있습니다.
- 더 나아가 이 가속기를 이미지 센서 바로 옆에 배치함으로써, Inputs(입력) 및 Outputs(출력)을 위해 남아있는 모든 DRAM accesses까지 없애는 것이 가능해집니다.
본 논문에서는 CMOS 또는 CCD sensor 옆에 배치되는 이러한 CNN accelerator를 제안합니다. DRAM accesses를 배제하고 CNN 내부의 특정 Data access patterns(데이터 접근 패턴)을 세심하게 활용함으로써, 우리는 이전 최첨단 가속기보다 60배 더 높은 Energy efficiency를 달성한 설계를 구현했습니다. 우리는 65nm 공정의 Layout(레이아웃) 단계까지 완료된 전체 설계를 제시합니다. 이 설계는 4.86 mm²의 작은 면적을 차지하고 320 mW의 전력만을 소비하면서도, 하이엔드 GPUs보다 약 30배 더 빠른 속도를 보여줍니다
Instruction
CNN의 핵심 특성: Weight Sharing (가중치 공유)
-
배경: 일반적인 신경망(DNN)은 가중치(Weights)가 너무 많아 외부 메모리(DRAM)에 저장하고 계속 읽어와야 합니다. 이 과정에서 엄청난 에너지 손실이 발생합니다.
-
CNN의 장점: CNN은 동일한 가중치를 이미지 전체에서 공유하는 Weight Sharing 특성이 있습니다. 덕분에 전체 모델의 크기(Memory Footprint)가 매우 작습니다.
-
결과: 모델 사이즈가 작기 때문에, DRAM이 아닌 연산기 옆의 작은 SRAM에 모델 전체를 담을 수 있습니다.
하드웨어 설계의 병목: Data Movement (데이터 이동)
-
문제: 컴퓨터 아키텍처에서 에너지를 가장 많이 쓰는 곳은 연산(Computation)이 아니라 데이터 이동(Data Movement), 특히 DRAM 접근입니다.
-
해결책: CNN 모델을 SRAM에 다 올리면 가중치를 읽기 위한 DRAM 접근이 사라집니다. 이제 남은 건 입력 이미지 데이터를 가져오는 DRAM 비용뿐입니다.
최종 해결책: 센서 옆으로 가속기 배치 (Sensor Proximity)
- 제안: 이미지는 원래 Sensor DRAM CPU/GPU 순서로 이동합니다.
- ShiDianNao의 방식: 가속기를 Sensor 바로 옆에 배치합니다.
- 이미지가 센서에서 나오자마자 가속기가 바로 처리합니다.
- 결과값(예: "고양이", 단 몇 바이트)만 호스트로 보냅니다.
- 효과: 입출력을 위한 DRAM 접근을 거의 100% 제거할 수 있습니다. 이를 통해 기존 가속기(DianNao)보다 60배 높은 에너지 효율을 달성했습니다.
Memory Footprint: 모델이 메모리에서 차지하는 공간. CNN은 이게 작아서 SRAM에 들어감.
DRAM Access Elimination: 이 논문의 궁극적 목표. 에너지 소모의 주범인 외부 메모리 접근을 없앰.
Translation Invariance: 이미지가 이동해도 특징을 인식하는 성질. Weight sharing이 가능한 이유.
약하자면, "CNN은 가중치가 적으니까 SRAM에 다 넣고 센서 옆에 딱 붙여서, 전력 많이 먹는 DRAM은 아예 쓰지 말자!"가 서론의 핵심 결론입니다.
System Intergration
현실적으로 이 가속기가 왜 대단한지 보여주는 대목입니다.
- No Full-Image Buffer: 8MP 이미지를 다 담으려면 메모리가 너무 많이 필요하므로, 이미지를 조각조각(Partial frame) 처리해야 함.
- No External DRAM: 전력 소모를 줄이기 위해 외부 DRAM 인터페이스를 아예 없앰.
- Limited SRAM (256KB): 매우 좁은 SRAM 공간 안에서 CNN 연산을 끝내야 함.
- Serial Streaming: 데이터가 들어오는 즉시 처리하는 스트리밍 구조를 가져야 함.
Primer on CNN
-
CNN vs. DNN (하드웨어 관점)
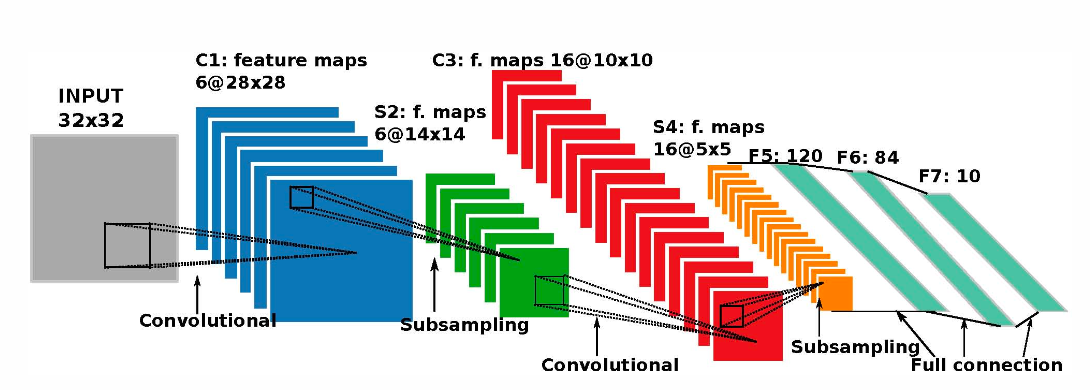
Weight Sharing: CNN은 가중치를 재사용(공유)함.Memory Footprint: 파라미터가 극적으로 적음 DRAM 없이 On-chip SRAM에 모델 전체를 탑재 가능. -
4대 주요 계층 (RTL Mapping 포인트)
-
Convolutional Layer: Kernel이 Sliding하며 특징 추출. 막대한 MAC (Multiply-Accumulate) 연산 블록과 Activation function 처리를 위한 로직 필요.
-
Pooling Layer: 데이터 크기를 줄이는 Downsampling. 곱셈기 없이 Comparator (Max pooling)나 단순 Adder/Shifter (Average pooling)만으로 구현 가능해 하드웨어 부담이 적음.
-
Normalization Layer: 정확도 향상을 위한 정규화. 식에 나눗셈(Division), 제곱(Square)이 포함되어 있어 ALU 설계가 까다로움.
-
Classifier Layer: 최종 분류(주로 Fully Connected). Independent synapses(가중치 공유 안 함)를 사용하므로 칩 내부 SRAM 용량을 가장 많이 잡아먹는 주범.
Mapping principles
이 섹션은 거대한 CNN 모델을 한정된 하드웨어 자원(PE)에 어떻게 올려놓고 계산할 것인가(Algorithm-to-Hardware Mapping)에 대한 현실적인 결정 과정을 다룹니다.
-
현실적 한계: 트랜지스터가 아무리 작아졌어도 수천만 개의 가중치를 가진 CNN을 하드웨어에 1:1로 펴서(Unrolling) 구현하는 Purely spatial implementation은 불가능합니다.
-
해결책: 전체 연산을 시간에 따라 나누어(Temporal partitioning) 제한된 하드웨어 위에서 반복적으로 돌리는 Sequential mapping 기법이 필수적입니다.
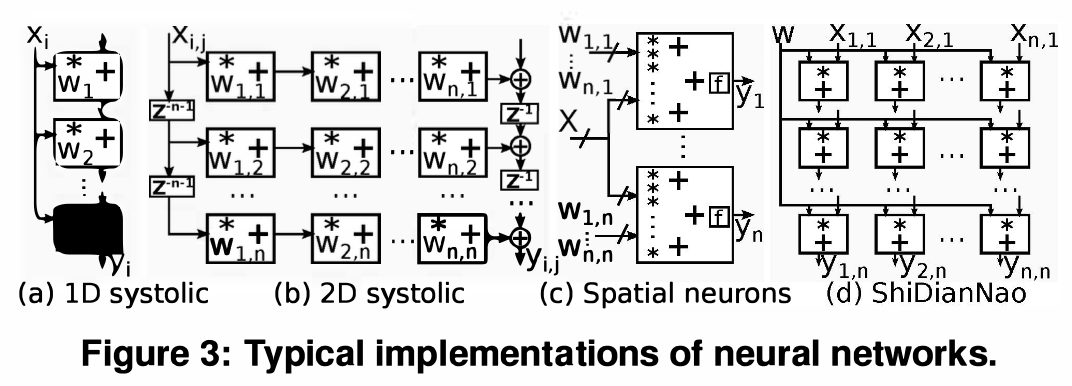
ShiDianNao의 Mapping Strategy (Figure 3(d) 핵심)
- Structure: 하드웨어 연산기인 PE를 이미지의 형태에 맞춰 2D mesh로 배열합니다.
- Kernel Data: 커널(가중치) 값은 한 번에 모든 PE로 뿌려줍니다(Broadcast).
- Input Data: 이미지 데이터(Input feature map)는 PE 배열 사이를 상하좌우로 이동(Shift)하며 들어옵니다.
- Output Data: 계산된 결과값(Output feature map)은 PE 외부로 나가지 않고 PE 내부의 레지스터에 계속 누적(Accumulate locally)됩니다.
결과적으로 데이터(특히 외부 메모리) 이동을 최소화하고, 내부 연산기끼리 데이터를 효율적으로 돌려쓰는 구조를 채택했다는 것이 핵심입니다.
Accelerator Architecture: Computation
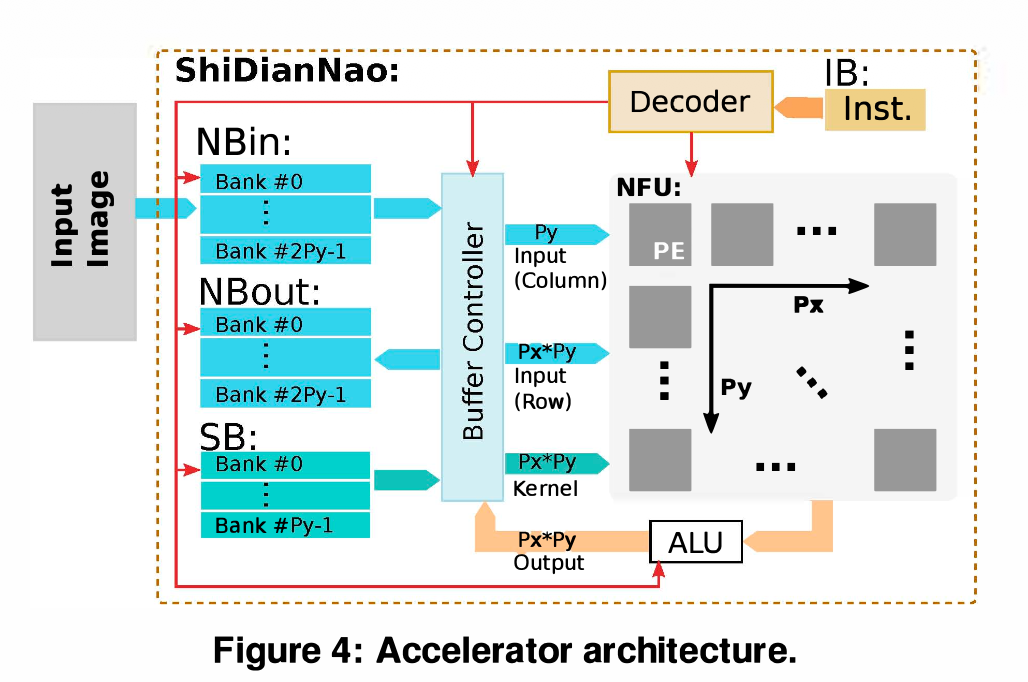
연산 유닛의 기본 설계 방향 (Overview & Datapath)
-
Main Components: 가속기는 크게 두 개의 연산 유닛(NFU, ALU)과 데이터 저장을 위한 버퍼들(NBin/NBout for neurons, SB for synapses, IB for instructions)로 구성됩니다.
-
16-bit Fixed-Point Arithmetic (16비트 고정소수점 연산): * 일반적인 32-bit floating-point(부동소수점) 대신 16-bit fixed-point를 사용합니다.
현실적인 이유: 신경망에서 정확도 손실(Accuracy loss)은 무시할 수 있는 수준인 반면, 하드웨어 면적은 6.1배 줄어들고 에너지 효율은 7.33배나 높아지기 때문입니다.
NFU (Neural Functional Unit) 핵심 구조
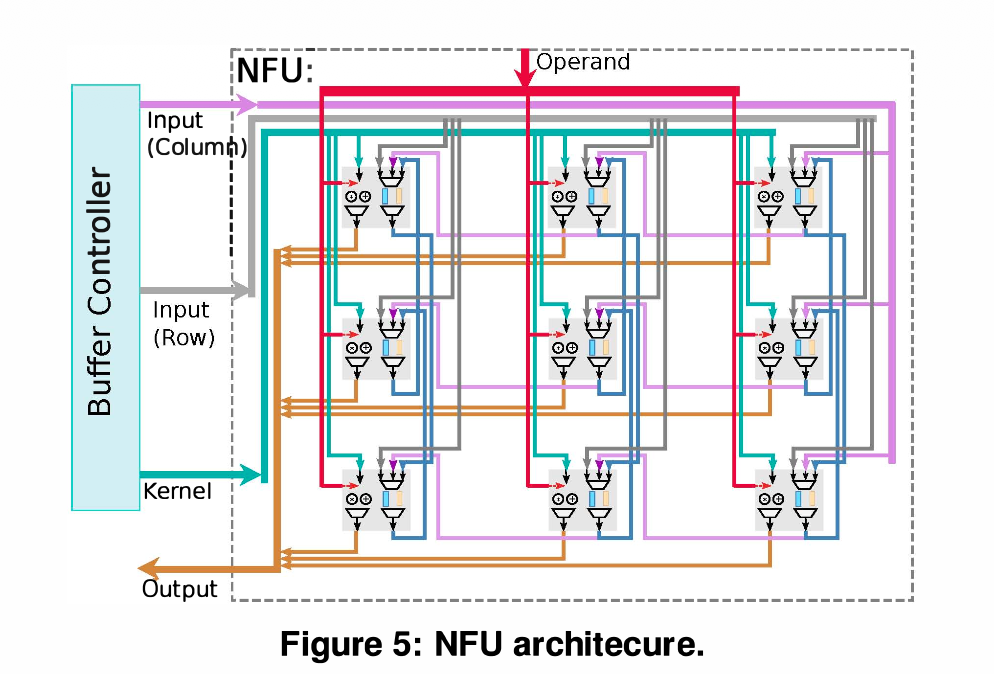
이전 모델인 DianNao가 2D 이미지를 1D Vector로 다뤄 비효율적이었던 것을 개선하여, 철저하게 2D 구조에 맞춰 설계되었습니다.
2D Mesh of PEs: 개의 Processing Elements (PEs)가 2D 배열로 구성됩니다.PE Mapping Strategy (설계상의 중요한 타협점):
- 초기 아이디어의 한계: 하나의 Output neuron을 계산하기 위해 커널 크기()만큼의 PE 블록을 통째로 할당하면, 뉴런 간 데이터를 공유하기 위해 거대한 MUX mesh(복잡한 라우팅 로직)가 필요해지고 다양한 커널 크기에 대응하기 어렵습니다.
- ShiDianNao의 선택: 1개의 Output neuron을 단 1개의 PE에 할당합니다. 대신 하나의 PE가 시간에 따라 여러 Input neurons/Synapses를 번갈아 가며 처리하는 Time-share 방식을 채택하여 로직 복잡도를 대폭 낮췄습니다.
- PE의 역할: 곱셈과 덧셈(MAC, 합성곱용), 단순 덧셈(Average pooling용), 비교기능(Comparator, Max pooling용)을 수행합니다.
Inter-PE Data Propagation (PE 간 데이터 전달 메커니즘)
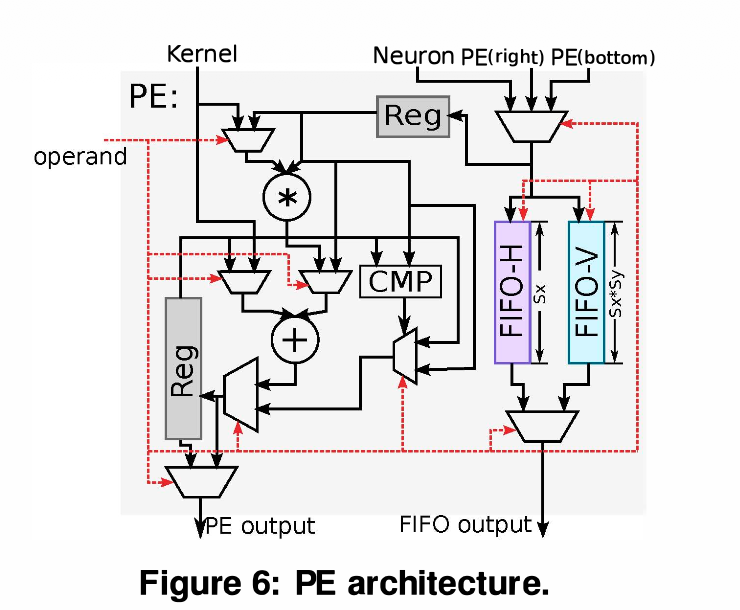
하드웨어 설계 시 가장 뼈아픈 문제인 Internal bandwidth (내부 대역폭) 병목을 해결하기 위한 이 논문의 핵심 아이디어입니다.
-
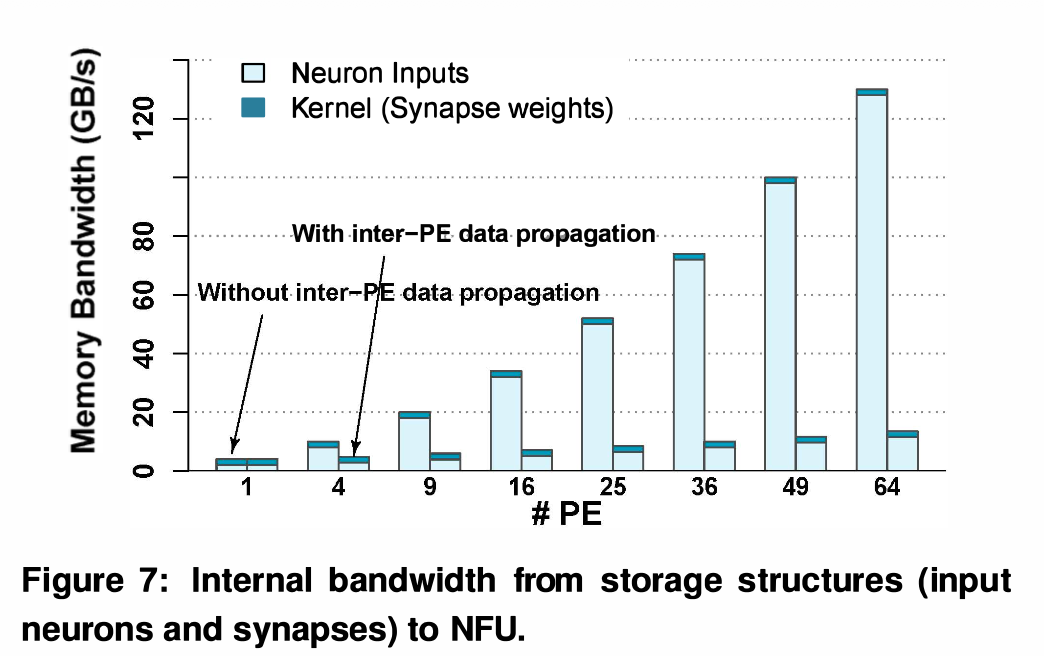
Bandwidth Bottleneck: CNN은 윈도우가 슬라이딩할 때 이전 데이터와 엄청나게 많이 겹칩니다(Overlapping). 이 겹치는 데이터를 매번 SRAM(NBin)에서 새로 읽어오면 막대한 대역폭(예: 25개 PE 기준 >52 GB/s)이 요구되어, 배선 오버헤드(Wiring overhead)와 성능 저하를 유발합니다.
-
FIFO 기반 Data Reuse: * 각 PE 내부에 수평(FIFO-H) 및 수직(FIFO-V) 버퍼를 둡니다.
- PE가 SRAM이나 오른쪽/위쪽 PE로부터 데이터를 받으면, 이를 즉시 자신의 왼쪽(Left neighbor)과 아래쪽(Lower neighbor) PE로 전달(Propagate)합니다.
- 결과적으로 메모리에서 데이터를 한 번만 읽고 PE들끼리 돌려쓰게 되어 SRAM Bandwidth 요구량을 극적으로 줄였습니다.
ALU (Arithmetic Logic Unit)
NFU가 처리하지 못하는 복잡한 연산을 담당하는 가벼운 보조 유닛입니다.
- 수행 연산: 나눗셈(Division) 및 tanh, sigmoid 같은 비선형 활성화 함수(Non-linear activation functions).
- Piecewise Linear Interpolation (구간 선형 보간):
- 복잡한 지수 연산 등을 하드웨어로 직접 구현하면 비용이 큽니다.
- 대신 함수 구간을 잘게 쪼개어 형태의 1차 함수로 근사(Approximation)합니다.
- 계수()는 레지스터에 미리 저장해 두고, 단순한 곱셈기 하나와 덧셈기 하나만으로 복잡한 활성화 함수를 매우 값싸게 계산해 냅니다.
Accelerator Architecture: Storage
이 섹션은 연산기(NFU)에 데이터를 병목 없이 공급하기 위해 SRAM을 어떻게 물리적으로 쪼개고 구성했는지를 설명합니다. 구조적 한계를 극복하기 위한 하드웨어 설계 기법들이 포함되어 있습니다.
DRAM의 완전한 배제 (On-chip SRAM 탑재):
- 모델 전체 크기가 작다는 CNN의 특성을 활용해, 288KB 용량의 On-chip SRAM만으로 모든 파라미터와 명령어를 수용합니다. 외부 메모리 의존성을 아예 끊어버렸습니다.
SRAM Partitioning & 맞춤형 Read Widths:
- 하나의 큰 메모리 블록(Monolithic SRAM)을 쓰지 않고, 데이터의 용도에 맞춰 버퍼를 세 개(NBin, NBout, SB)로 물리적으로 분할했습니다.
- 각 버퍼의 포트(Port) 사이즈, 즉 Read widths를 데이터 특성에 맞게 다르게 설정하여 불필요한 전력 소모를 막았습니다.
Ping-Pong Buffering 기법 적용:
- NBin(입력용)과 NBout(출력용)이 레이어 연산이 끝날 때마다 서로의 역할을 바꿉니다(Swap). 메모리 간에 데이터를 복사해서 넘겨줄 필요 없이 포인터(또는 MUX 제어)만 바꿔서 파이프라인의 다음 단계로 곧바로 넘어가는 전형적인 하드웨어 최적화 기법입니다.
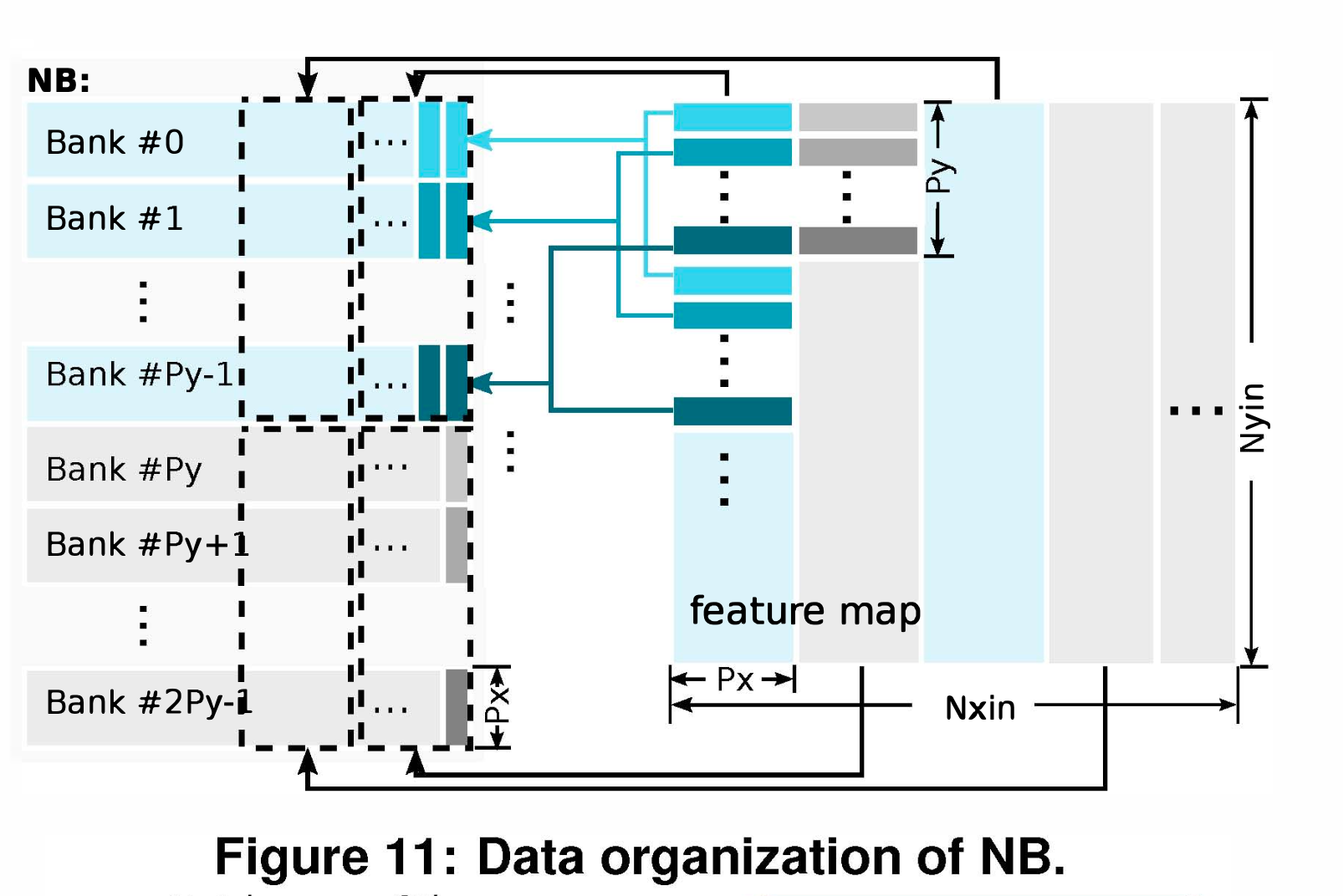
다중 Bank 구성 (Multi-banked architecture):
- NFU 내부의 2D Mesh 구조에 한 번에 데이터를 쏴주기 위해 메모리를 여러 개의 Bank로 쪼갰습니다.
- NBin/NBout은 개의 뱅크를 가지고, 뱅크 하나당 단위로 데이터를 출력합니다. 이는 앞서 다룬 Inter-PE data propagation을 타이밍에 맞춰 지원하기 위한 필수적인 데이터 패스(Datapath) 설계입니다.
Accelerator Architecture: Control
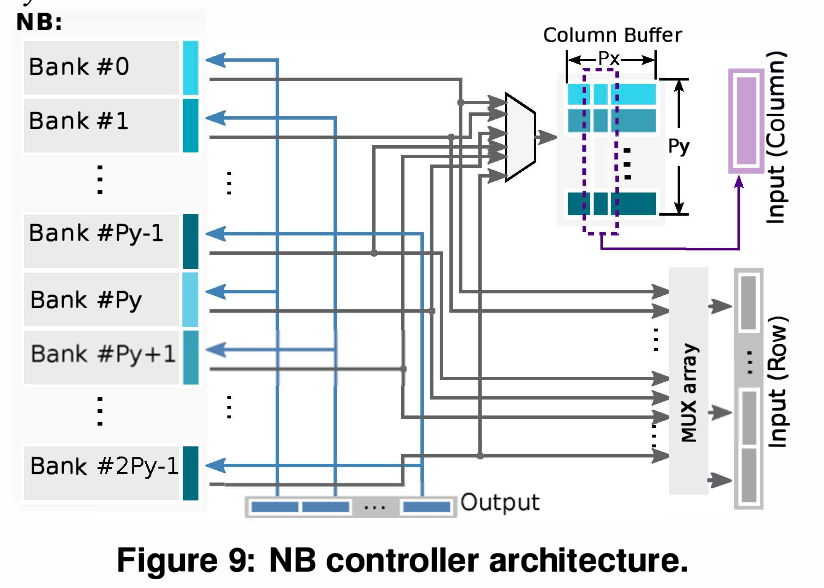
Buffer Controller (메모리 접근 최적화)
-
Problem: CNN은 레이어 종류(Conv, Pooling, FC)에 따라 데이터에 접근하는 방식(Access pattern)이 모두 다릅니다.
-
Solution (다양한 Read Modes 지원): 단일한 읽기 방식 대신, Sliding window의 형태나 보폭(Step size)에 맞춰 데이터를 필요한 만큼만 쏙쏙 뽑아올 수 있도록 6가지의 특화된 Read modes를 구현했습니다. 불필요한 데이터를 읽느라 낭비되는 전력과 시간을 막아줍니다.
-
Write Mechanism: PE에서 계산이 끝날 때마다 하나씩 메모리에 쓰는 것이 아니라, 내부에 Register array를 두고 결과를 모았다가 한 번에 블록 단위(Data block)로 메모리에 쓰는 방식(Burst write와 유사한 개념)을 사용해 병목을 줄였습니다.
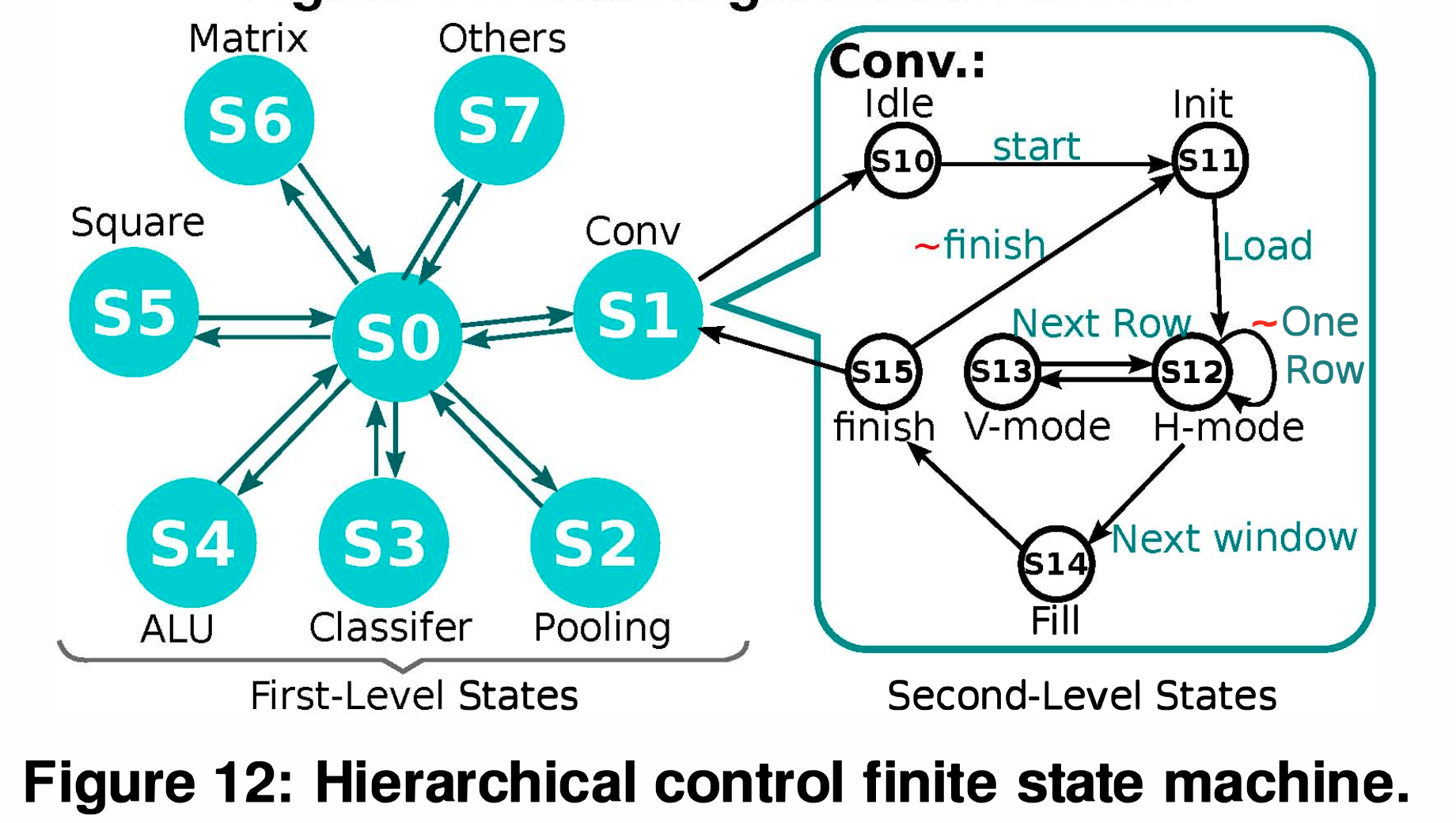
Control Instructions (제어 메모리 최적화 - 가장 중요한 포인트)
-
Problem: 매 클럭마다 모든 제어 신호(Cycle-by-cycle control signals)를 메모리에 저장해두고 꺼내 쓰면, Instruction SRAM 용량이 무려 600KB 이상 필요해집니다 (이는 데이터를 담는 SRAM 용량보다 커지는 주객전도의 상황입니다).
-
Solution (HFSM 도입): Hierarchical Finite State Machine (HFSM)을 도입했습니다. CNN 연산은 매우 '반복적'이고 패턴이 일정하다는 점을 역이용한 것입니다.
-
명령어 메모리에는 세세한 컨트롤 신호를 저장하지 않고, "현재 레이어 종류(상위 상태)와 현재 진행 단계(하위 상태)"라는 압축된 정보(61-bit)만 저장합니다.
-
칩 내부의 작은 Decoder가 이 압축된 상태 정보를 바탕으로 다음 단계에 필요한 실제 제어 신호들을 알아서 생성해 냅니다.
-
-
Result: Instruction storage 요구량을 600KB에서 단 1KB로 획기적으로 압축했습니다.
CNN Mapping
Convolutional Layer (합성곱 계층)
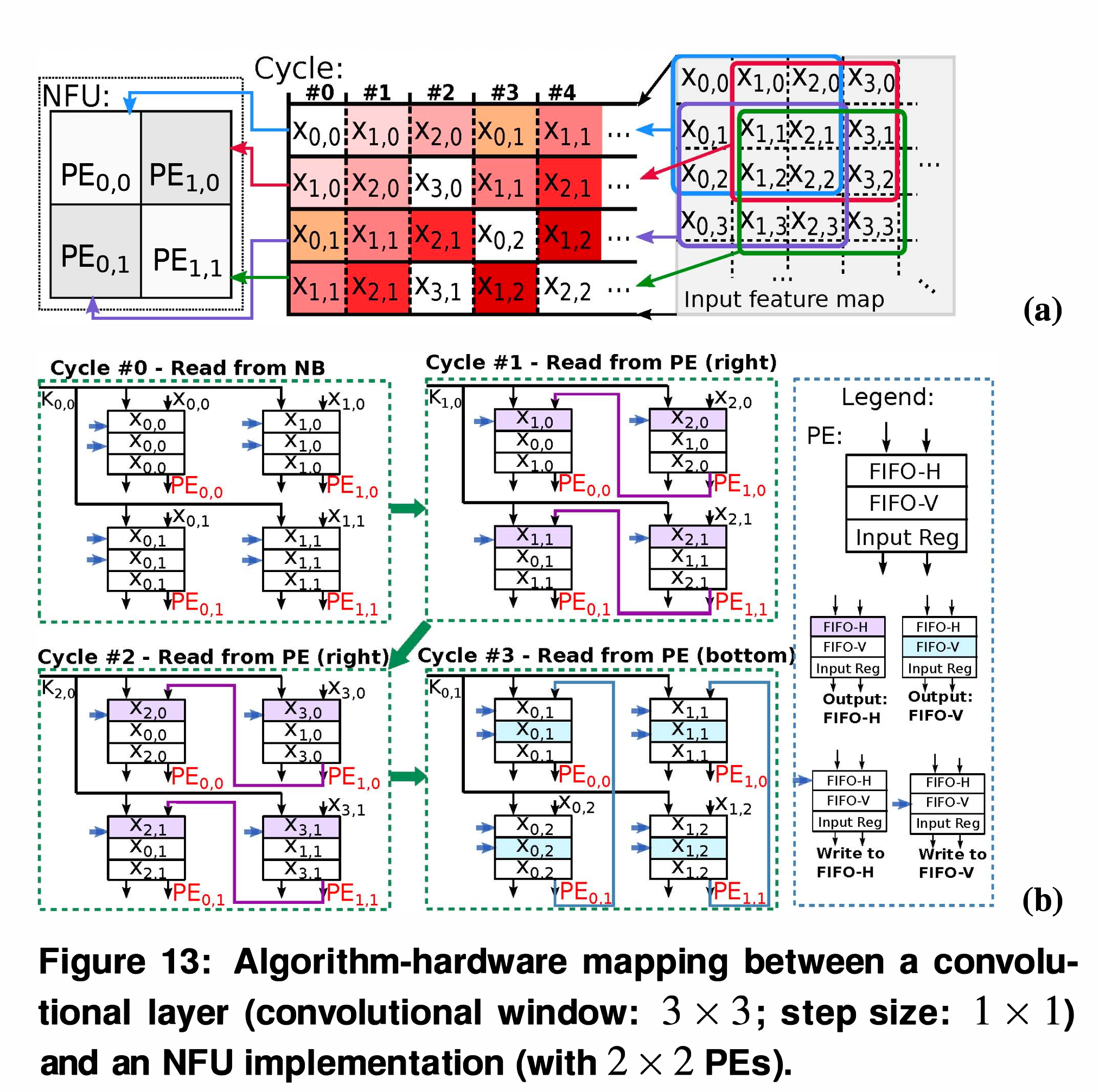
연산기가 낭비 없이 돌아가도록 데이터 재사용(Data reuse)을 극대화하는 것이 핵심입니다.
-
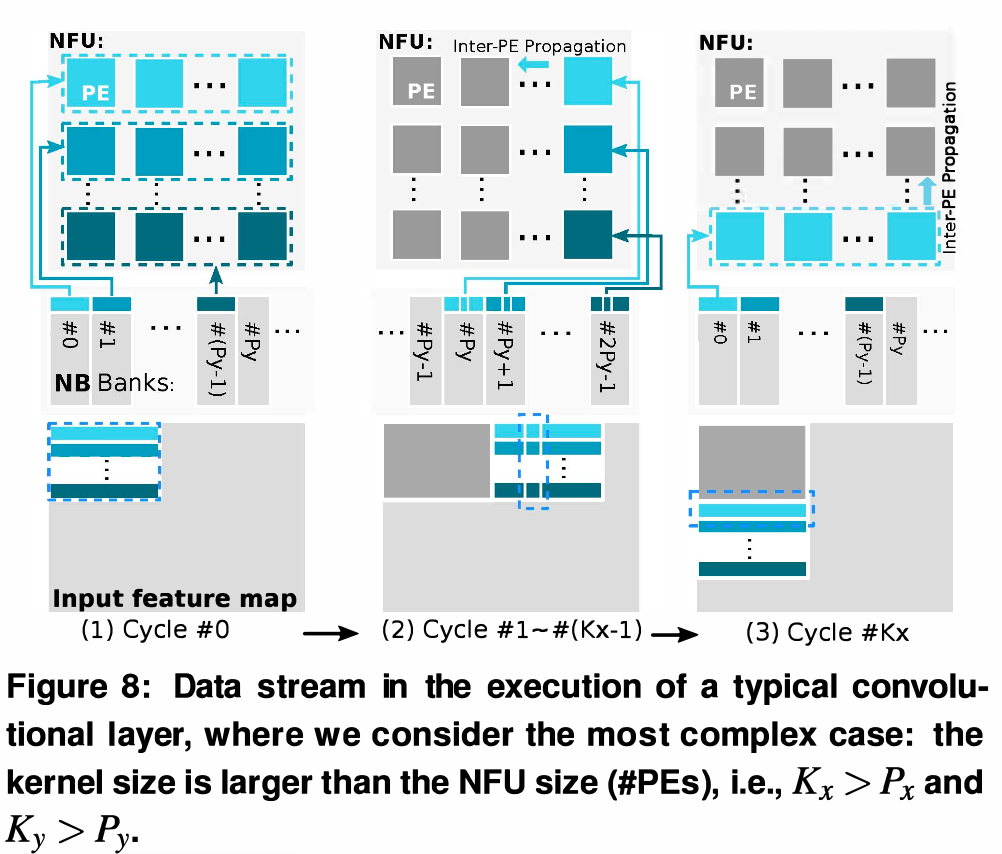
Mapping Strategy: 1개의 PE (Processing Element)는 1개의 Output neuron 연산을 끝까지 전담합니다.
-
Inter-PE Data Propagation (핵심 메커니즘): * 윈도우가 슬라이딩할 때 인접한 뉴런들끼리 입력 데이터가 엄청나게 겹칩니다. 이를 매번 NBin (SRAM)에서 읽어오면 병목이 발생합니다.
- Cycle #0: 모든 PE가 메모리에서 데이터를 읽고 연산한 뒤, 값을 내부 FIFO-H(수평)와 FIFO-V(수직)에 저장합니다.
- Cycle #1~#2: PE들이 메모리에 접근하지 않고, 옆 PE의 FIFO-H에서 데이터를 넘겨받아 연산합니다 (마치 Shift Register처럼 동작).
- Cycle #3: 아래쪽 PE가 윗쪽 PE의 FIFO-V에서 데이터를 넘겨받아 연산합니다.
-
현실적인 효과: 이 방식을 통해 NBin을 읽는 횟수를 극적으로 줄여, Internal bandwidth 요구량을 최대 73%까지 감소시킬 수 있습니다.
Pooling Layer (풀링 계층)
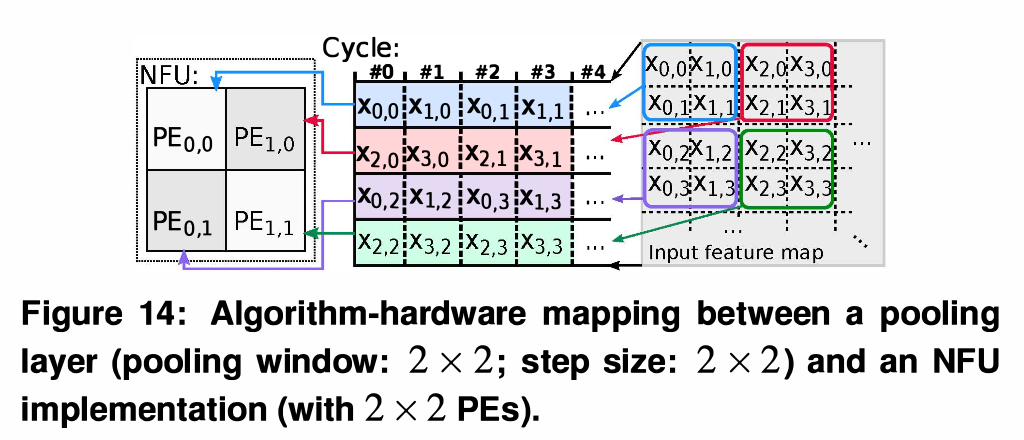
-
Mapping Strategy: Convolutional layer와 유사하게 1 PE가 1 Output neuron을 전담합니다.
-
No Data Reuse: 대다수의 Pooling layer는 윈도우가 겹치지 않게(Non-overlapping) 건너뜁니다. 따라서 PE 간에 데이터를 넘겨주는 Inter-PE propagation이 발생하지 않으며, 각 PE는 단순히 정해진 Step size에 맞춰 NBin에서 데이터를 직접 읽어옵니다.
Classifier Layer (분류기 / Fully Connected 계층)
이 아키텍처가 가진 가장 치명적인 메모리 병목 지점입니다.
-
No Weight Sharing: 합성곱 계층과 달리, 분류기 계층은 시냅스 가중치(Synaptic weights)를 전혀 공유하지 않습니다.
-
Execution Flow: 매 사이클마다 모든 PE가 1개의 동일한 Input neuron을 공유받지만, 가중치는 각 PE마다 별개의 값(Different synaptic weights)을 SB (Synapse Buffer)에서 읽어와야 합니다.
-
현실적인 제약: 가중치를 공유하지 않기 때문에 모델 전체 가중치의 대부분(예: LeNet-5의 경우 약 97%)을 이 계층이 혼자 차지하게 됩니다. 칩 내부의 제한된 SRAM 공간을 가장 압박하는 주범입니다.
8.4 Normalization Layers (정규화 계층)
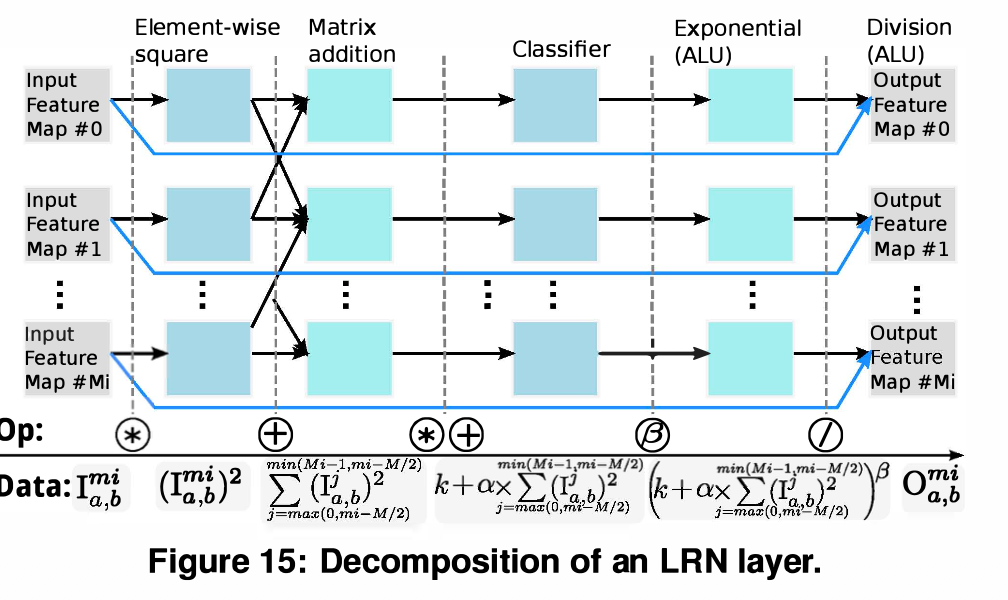
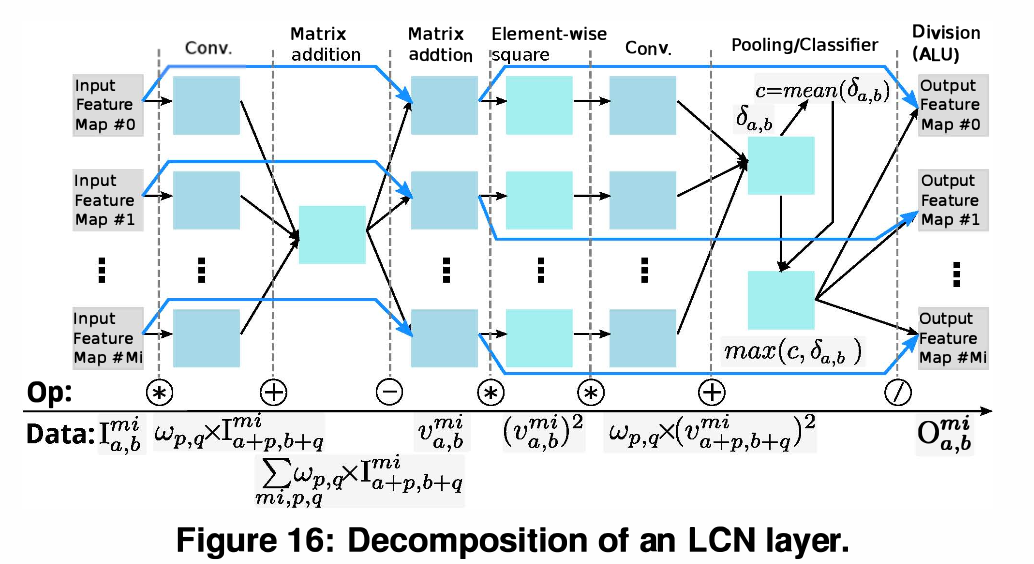
-
Sub-layer Decomposition (연산 분해): LRN, LCN 같은 복잡한 정규화 계층은 하드웨어로 한 번에 구현하기 매우 까다롭습니다.
-
Execution Flow: 이를 Convolutional, Pooling, Classifier와 같은 기본 계층 동작으로 잘게 쪼개어 NFU에서 처리합니다. 나머지 복잡한 행렬 덧셈이나 요소별 제곱(Element-wise square)은 NFU가, 지수 연산이나 나눗셈(Divisions)은 보조 연산기인 ALU가 분담하여 처리하게 됩니다.
Result
Layout Characteristics (레이아웃 및 하드웨어 스펙)
-
SRAM Capacity: 가속기 내부 SRAM의 총 용량은 288 KB입니다 (NBin 64 KB, NBout 64 KB, SB 128 KB, IB 32 KB). 이는 모델을 모두 담기 위해 이전 세대인 DianNao보다 SRAM을 11.1배나 늘린 수치입니다.
-
Area (면적): 메모리를 11배 넘게 늘렸음에도 불구하고, 전체 칩 면적(Area)은 4.86 mm²로 DianNao 대비 3.52배 증가하는 데 그쳤습니다. 매우 컴팩트한 설계입니다.
2. 10.2 Performance (성능 및 현실적 한계)
① 압도적인 범용 칩(CPU/GPU) 대비 성능
- CPU 대비 46.38배, GPU 대비 28.94배 빠름.
- GPU의 비효율성: GPU는 2,496개의 막대한 하드웨어 스레드(Hardware threads)를 가졌지만, 비전 인식에 쓰이는 작은 CNN kernels를 여기에 매핑하면 스레드를 다 채우지 못하고 놀게 됩니다. 즉, GPU 입장에서는 작업 단위가 너무 작아 Underutilization(자원 활용도 저하)이 발생합니다.
② 이전 가속기(DianNao) 대비 성능 (1.87배 향상)
- Off-chip memory accesses(외부 메모리 접근)를 완전히 제거했기 때문입니다.
- Inter-PE data reuse(PE 간 데이터 재사용) 메커니즘으로 2D 데이터의 지역성(Locality)을 극대화했기 때문입니다.
③ 현실적인 한계점 (Simple Conv 벤치마크에서의 성능 저하)
-
무조건 만능인 것은 아닙니다. 10개 중 1개 벤치마크(Simple Conv)에서는 오히려 구형인 DianNao보다 성능이 떨어졌습니다.
-
원인 (PE Idle 현상): ShiDianNao는 한 번에 하나의 Output feature map만 계산합니다. 만약 맵 크기가 5x5로 매우 작다면, 8x8(64개)로 구성된 PEs 중 나머지 39개는 계산할 데이터가 없어 Idle(대기) 상태로 놀게 됩니다.
-
설계적 타협 (Trade-off): 여러 개의 Feature maps를 동시에 계산하도록 PE에 복잡한 Control logic을 추가할 수도 있었지만, 그러면 프로그래밍 모델이 너무 망가지기 때문에 쿨하게 성능 저하를 감수하는 쪽을 택했습니다.
④ Real-time Processing (실시간 처리 능력)
- 640x480 해상도의 비디오 프레임을 처리하는 데 약 50 ms가 걸려, 초당 20 프레임(20 fps)의 실시간 처리가 가능합니다.
3. 10.3 Energy (에너지 효율성)
이 논문의 가장 강력한 무기인 에너지 효율을 보여주는 파트입니다.
GPU 대비 4688.13배, DianNao 대비 63.48배 더 높은 에너지 효율을 달성했습니다.
-
DRAM의 부재가 만든 기적: 구형 DianNao는 전체 에너지의 95% 이상을 DRAM과 데이터를 주고받는 데 낭비했습니다. 반면 ShiDianNao는 DRAM 접근이 없으므로, 내부 SRAM buffers가 소비하는 전력은 단 11.43%에 불과하고 나머지 87.29%의 에너지가 온전히 로직 연산(Logic)에만 사용됩니다.
-
만약 DianNao가 외부 메모리 접근 비용이 0원인 '완벽한 가상 환경(DianNao-FreeMem)'에 있다고 억지로 가정하더라도, Inter-PE data propagation 설계 덕분에 여전히 ShiDianNao가 1.66배 더 효율적입니다.
요약하자면, "SRAM 용량을 늘려 DRAM을 없애고 PE끼리 데이터를 돌려 쓰게 만들었더니, GPU보다 수천 배 전력을 덜 먹으면서도 연산은 30배 빨라졌다. 다만, 출력 맵 크기가 하드웨어 PE 배열보다 작으면 연산기가 놀면서(Idle) 비효율이 발생한다는 구조적 한계는 감수해야 한다."로 완벽하게 정리할 수 있습니다.
핵심 요약
이 섹션은 기존 아키텍처들의 구조적 단점을 꼬집으며 ShiDianNao의 우수성을 증명하는 논리적 빌드업입니다.
Cloud/Server Computing의 한계:
- 영상 데이터를 서버로 보내서 연산하면 Latency(지연 시간)가 길어지고 QoS가 떨어짐 엣지 단(Sensor 옆)에서 연산해야 함.
CPU / GPU의 한계:
- Flexibility(범용성)는 좋지만 트랜지스터 낭비가 심해 Energy-efficiency가 최악임.
기존 Systolic Array 가속기 (NeuFlow 등)의 한계:
- 2D 연산은 잘하지만 구조가 너무 뻣뻣함(Rigid). 윈도우 크기나 Stride가 바뀌는 다양한 CNN parameters에 대응하지 못하고, 높은 Memory bandwidth를 요구함.
Host Processor + FPGA (또는 DMA 기반)의 한계:
- 결국 호스트 프로세서의 개입이 필요하거나 메인 메모리(DRAM)와 데이터를 주고받아야 해서 전력 소모가 큼.
이전 모델 (DianNao)의 한계:
- 범용성에 초점을 맞추다 보니 2D 이미지를 1D Vector로 쭉 펴서 연산함. 이로 인해 2D 데이터 고유의 공간적 Locality(지역성)를 살리지 못하고 불필요한 메모리 접근이 발생함.
ShiDianNao의 2가지 핵심 차별점 (Core Novelty):
- Zero Main Memory Access: CNN 연산 도중 DRAM 접근을 완전히 0으로 만듦.
- High Flexibility: 경직된 Systolic Array와 달리, 61-bit HFSM instruction을 통해 다양한 커널 크기와 레이어 설정을 유연하게 지원함.
