MobileNet (모바일넷) 개요
정의: 구글이 2017년에 발표한 모바일 및 임베디드 비전 애플리케이션을 위한 효율적인 모델입니다.
목표: 제한된 리소스(CPU, 배터리 등) 환경에서 Latency(지연 시간)를 줄이고 크기를 작게 만드는 것입니다.
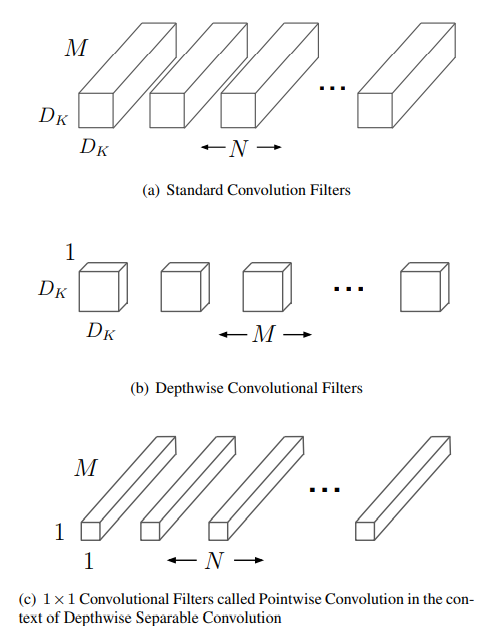
기존 방식: Standard Convolution (무거운 방식)
기존의 컨볼루션은 "공간(위/아래/양옆)"과 "채널(깊이)" 정보를 한 번에 섞어서 계산합니다.
설명: 3x3x3(R,G,B) 필터가 한 덩어리로 움직입니다.
문제점: "이미지의 모양"을 찾는 일과 "색깔(채널)을 섞는 일"을 동시에 하려니 계산량이 엄청나게 많습니다.
[입력: 3채널(R,G,B)] [필터: 3채널짜리 두꺼운 필터]
┌── R ──┐ ┌── R ──┐
├── G ──┤ x ├── G ──┤ ==> [출력: 1장]
└── B ──┘ └── B ──┘
(모두 섞임) (한 덩어리로 계산)MobileNet 방식: Depthwise Separable Convolution
MobileNet은 이 작업을 두 단계(Step 1, Step 2)로 쪼개서 수행합니다. 이렇게 하면 계산량이 약 9배 줄어듭니다.
1. 핵심 아이디어: Depthwise Separable Convolution
기존의 표준 Convolution(Standard Convolution)을 두 단계로 분리하여 연산량을 극적으로 감소시킵니다.
Step 1: Depthwise Convolution (공간적 특징 추출)
-
기존: 입력 채널 전체를 한꺼번에 합쳐서 계산합니다.
-
MobileNet: 각 입력 채널(Channel)마다 별도의 필터를 적용합니다.
- 예: 입력 채널이 3개(R, G, B)라면, 필터도 3개를 사용하여 각각 따로따로 Convolution을 수행합니다.
- 채널 간의 관계는 고려하지 않고, 오직 공간적인(Spatial) 특징만 추출합니다.
┌── R ──┐ x ┌── Filter R ──┐ ==> [R 특징맵]
├── G ──┤ x ├── Filter G ──┤ ==> [G 특징맵]
└── B ──┘ x ├── Filter B ──┤ ==> [B 특징맵]
(얇은 필터 3개)Depthwise (따로따로!) 채널을 섞지 않고, 각자 자기 짝꿍하고만 계산합니다.
Step 2: Pointwise Convolution (채널 간 특징 결합)
- 동작: 1x1 Convolution을 수행합니다.
- 역할: Depthwise Convolution으로 나온 결과물들을 채널 방향으로 합쳐주는(Linear Combination) 역할을 합니다.
- 이를 통해 채널 간의 관계(Cross-channel correlation)를 학습합니다.
[R 특징맵]
[G 특징맵] x [1x1x3 꼬치 필터] ==> [최종 출력: 1장]
[B 특징맵]Pointwise (이제 섞자!) 1x1 크기의 아주 작은 점(Point) 필터로 꼬치 꿰듯 뚫어서 합칩니다.
2. 연산량 비교 및 감소 효과
입력 크기가 이고, 출력 채널이 , 커널 크기가 일 때:
A. Standard Convolution 연산량
(모든 채널과 커널을 한 번에 계산하므로 곱셈 횟수가 많음)
B. Depthwise Separable Convolution 연산량
(Depthwise 비용 + Pointwise 비용)
C. 결론 (Efficiency)
두 식을 나누어 보면, 연산량은 대략 다음 비율로 줄어듭니다.
- 보통 커널을 사용하므로, 입니다.
- 따라서 기존 대비 약 8~9배의 연산량 감소 효과를 얻으면서도 정확도는 크게 떨어지지 않습니다.
3. 하이퍼파라미터 (Hyperparameters)
MobileNet은 상황에 따라 모델의 크기와 속도를 조절할 수 있는 두 가지 파라미터를 제공합니다.
- Width Multiplier ():
- 네트워크의 채널 수(Channel width)를 전체적으로 비율만큼 줄입니다. (예: 0.75, 0.5)
- 모델을 더 얇게(thinner) 만듭니다.
- Resolution Multiplier ():
- 입력 이미지의 해상도(Resolution)를 줄입니다.
- 연산량은 해상도의 제곱에 비례해서 줄어듭니다.

4. 발전 과정 (참고)
- MobileNet V1: Depthwise Separable Convolution 도입 + ReLU 사용.
- MobileNet V2: Inverted Residuals (채널을 확장했다가 다시 줄이는 구조)와 Linear Bottleneck 도입으로 정보 손실 최소화.
- MobileNet V3: AutoML(MnasNet)을 통해 아키텍처를 검색(NAS)하고, h-swish 활성화 함수 도입.
