정의: 딥러닝 모델의 파라미터 수와 연산량(FLOPs)을 줄이면서도, 원본 모델의 정확도(Accuracy)를 최대한 유지하는 기술입니다.
목적: 모바일 기기나 임베디드 시스템(Edge Device)처럼 메모리와 연산 능력이 제한된 환경에서 모델을 효율적으로 실행하기 위함입니다.
1.Pruning (가지치기)
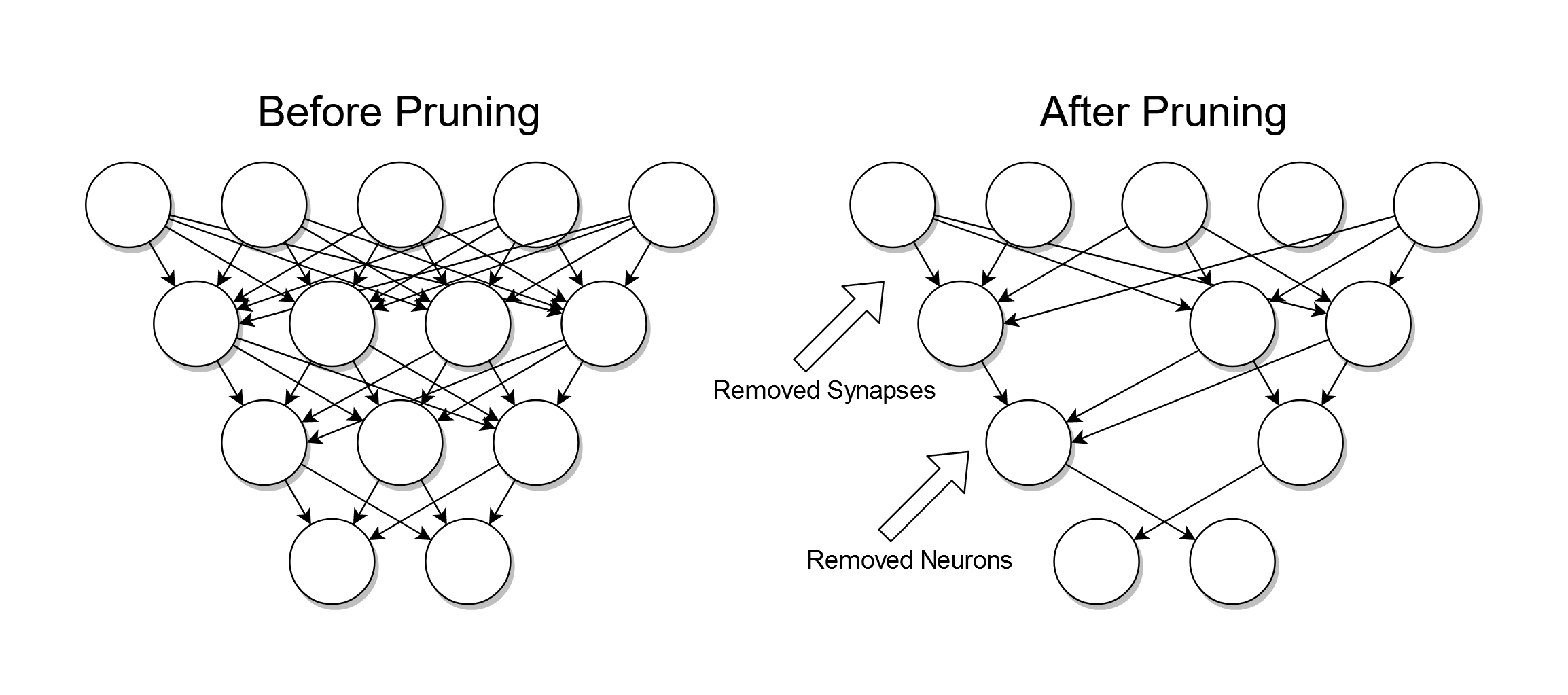
신경망에서 중요하지 않은 가중치(Weight)나 뉴런(Neuron)을 제거하여 모델의 크기를 줄이는 기법입니다. 사람의 뇌가 성장하면서 불필요한 시냅스를 정리하는 것과 유사합니다.
A.magnitude pruning (크기 기반 가지치기)
- 개념: 가중치 행렬(Weight Matrix)에서 절댓값(magnitude)이 특정 임계값(threshold)보다 작은 가중치를 0으로 만들거나 제거하는 가장 직관적인 방법입니다.
- 원리: 가중치 값이 0에 가까우면 해당 연결이 출력에 미치는 영향이 미미하다고 가정합니다.
- 장점: 구현이 매우 간단하고 계산 비용이 적습니다.
- 단점: 단순히 크기만 보고 자르기 때문에, 작지만 네트워크 구조상 중요한 역할을 하는 가중치가 제거될 위험이 있어 정확도 손실이 발생할 수 있습니다.
B.Interative Pruning Methods (반복적 가지치기)
- 개념: 한 번에 많이 자르는 대신, '학습(Train) -> 가지치기(Prune) -> 재학습(Retrain/Fine-tuning)' 과정을 여러 번 반복하는 방법입니다.
- 과정:
- 네트워크를 학습시킵니다.
- 하위 k%의 가중치를 가지치기(Pruning)합니다.
- 남은 가중치로 모델을 다시 학습(Fine-tuning)시켜 떨어진 정확도를 복구합니다.
- 원하는 압축률에 도달할 때까지 2~3번을 반복합니다.
- 장점: 한 번에 자르는 것보다 훨씬 더 높은 압축률에서도 정확도를 잘 유지합니다. (The Lottery Ticket Hypothesis와 관련이 깊습니다.)
2.Quantization (양자화)
모델의 가중치나 연산 정밀도를 기존의 32-bit Floating Point(FP32)에서 더 적은 비트 수(예: 16-bit, 8-bit, 1-bit)로 줄이는 기법입니다.
A.Deterministic binarization(결정론적 이진화)
- 개념: 가중치를 확률적으로 결정하지 않고, 특정 기준에 따라 +1 또는 -1의 두 가지 값으로만 고정하는 방식입니다. (예: BinaryConnect)
- 수식 예시:
- 이면
- 이면
- 효과: 32비트 실수를 1비트로 줄이므로 메모리 사용량을 이론상 32배 줄일 수 있으며, 곱셈 연산을 덧셈/뺄셈으로 대체하여 하드웨어 속도를 극적으로 높입니다.
B.Binary Sheme/Fixed Method
-
Binary Weight Networks: 가중치만 이진화(+1, -1)하고 활성화 함수(Activation)는 그대로 두거나, 둘 다 이진화(XNOR-Net)하는 등 다양한 '스킴(Scheme)'이 존재합니다. 이를 통해 정확도와 효율성 사이의 균형을 맞춥니다.
-
Fixed-Point Quantization (고정 소수점 양자화): 소수점 위치를 고정하여 정수(Integer) 연산처럼 처리하는 방식입니다. 부동 소수점(Floating Point) 연산보다 하드웨어에서 훨씬 빠르고 전력을 적게 소모합니다.
3.Knowledge Distillation
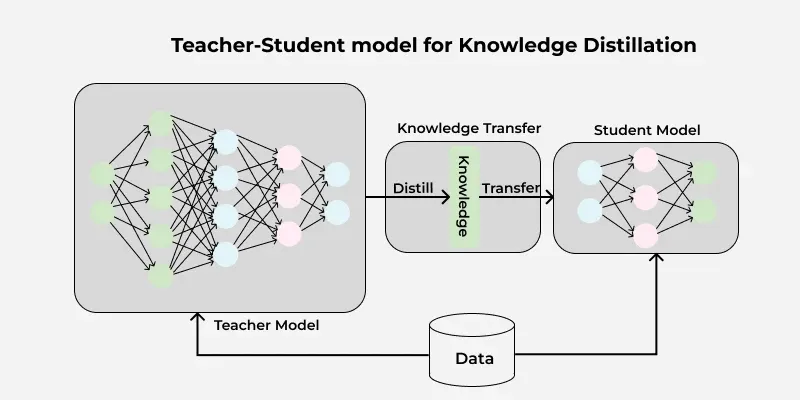
크고 복잡한 모델(Teacher)이 학습한 지식을 작고 가벼운 모델(Student)에게 전달하여 학습시키는 방법입니다.
- 구조:
- Teacher Network: 미리 학습된 고성능의 거대 모델. (정답을 잘 맞춤)
- Student Network: 경량화 대상인 작은 모델.
- 원리 (Soft Targets):
- Teacher 모델은 단순히 정답(One-hot vector)만 알려주는 것이 아니라, '오답이지만 정답과 유사한 클래스'에 대한 확률 정보(Soft probablities)까지 Student에게 알려줍니다.
- 예: "이 사진은 개(Dog)야"라고만 하는 대신, "이건 개(90%)인데, 고양이(9%)랑도 좀 비슷하고, 자동차(1%)랑은 전혀 안 닮았어"라고 가르쳐 주는 식입니다.
- Loss Function: Student는 실제 정답(Hard label)과 Teacher의 출력(Soft label)을 동시에 학습하여, Teacher의 일반화 능력을 모방하게 됩니다.

Design Verification engineer