Example 1
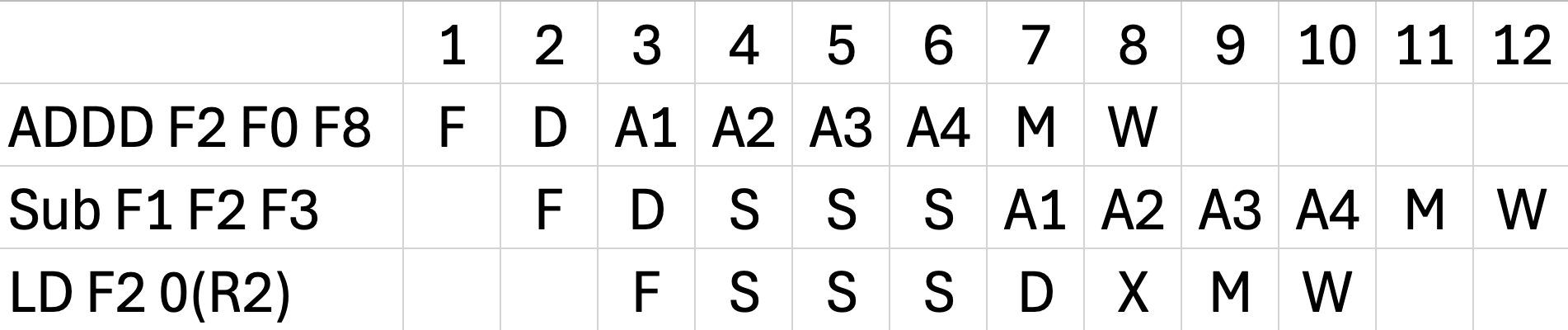
WAW (Write After Write) Hazard 성립조건
-> "반드시 같은 레지스터(Same Destination Register)에 값을 써야 한다!"
그래서 SUB, LD는 각자 F1, F2 다른값에 쓰므로 WAW 가 아니다
ADDD, LD가 WAW 후보가 될 수 있는데, cc8 에 끝나고, cc10에 순차적으로 끝나므로 WAW가 아니다
Example 2
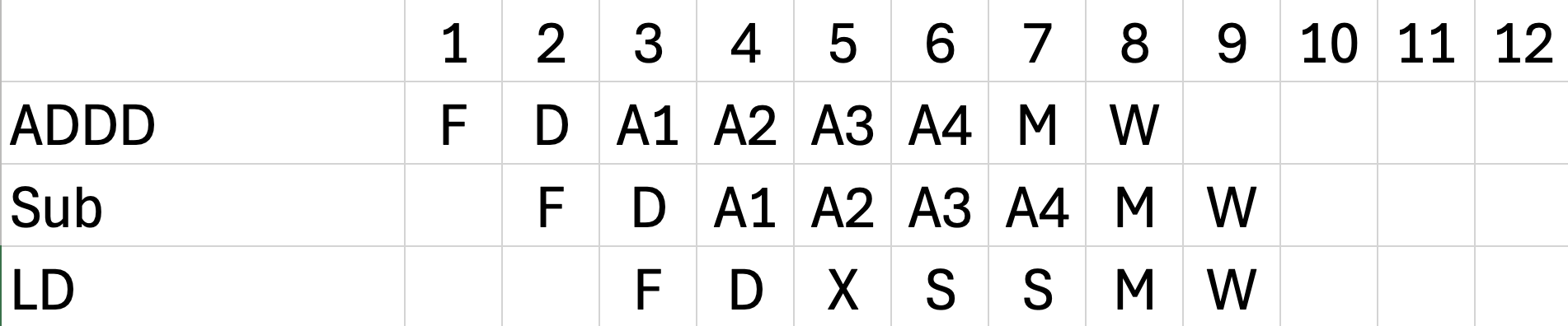
부동소수점 파이프라인(FP Pipeline)에서는 실행 시간이 제각각이라, 데이터 해저드(WAW)를 피하려고 스케줄을 조정하다가 쓰기 포트 충돌(Structural Hazard)이라는 또 다른 폭탄을 터뜨릴 수 있다!"
EX 2 스토리
1. LD의 양보 (WAW Hazard 방어)
- LD는 원래 쌩쌩 달려서 7번 클럭이면 W를 끝낼 수 있는 아주 빠른 녀석입니다.
- 하지만 만약 맨 위의 ADDD와 같은 방(예: F2)을 쓴다면? 아까 우리가 배운 대로 WAW Hazard를 막기 위해 ADDD가 쓰기(W)를 끝내는 8번 클럭 이후로 스케줄을 미뤄야 합니다.
- 그래서 LD는 눈물을 머금고 5번, 6번 클럭에서 2칸의 스톨(S, S)을 먹으며 9번 클럭에 W를 하려고 계획을 바꿨습니다.
- 우연한 타이밍의 일치 (Structural Hazard 폭발)
- 그런데 아뿔싸! LD가 일정을 미뤄서 도착한 9번 클럭에는, 처음부터 자기 페이스대로 느릿느릿 4단계 연산(A1~A4)을 거쳐온 Sub 명령어가 마침 W를 하려고 대기 중이었습니다.
- 일반적인 CPU의 부동소수점 레지스터 파일(FP Register File)은 쓰기 포트(Write Port)가 1개뿐입니다. 문이 하나인데 두 놈이 동시에 쓰겠다고 밀고 들어오니 하드웨어가 뻗어버리는 Structural Hazard가 발생한 것입니다.
Write Port Structural Hazards In FP MIPS Pipeline
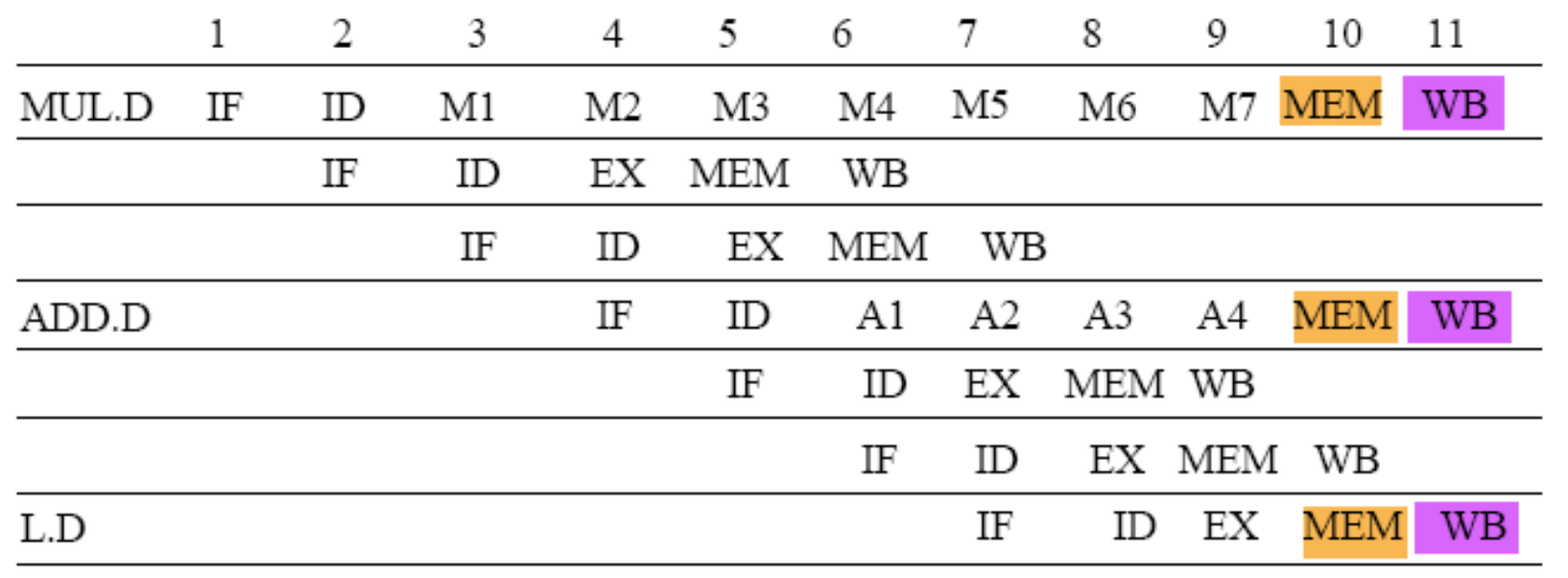
1. 문제 상황 인식
표의 CC 10, 11을 보세요. MUL.D, ADD.D, L.D 세 마리가 정확히 같은 클럭에 WB (Write-Back)를 하겠다고 겹쳐버렸죠? 쓰기 포트(Write Port)는 1개인데 말입니다. (이게 바로 Write Port Hazard 입니다.)
문제는 프로세서가 CC 10이 되어서야 "어? 겹쳤네?" 하고 깨달으면 이미 하드웨어가 뻗어버린 뒤라는 겁니다. 따라서 명령어들이 파이프라인에 진입하는 초반, 즉 ID stage에서 이 미래의 대참사를 미리 예측하고(Detect), 여기서부터 아예 멈춰 세워야(Stall) 합니다.
2. 해결책: Shift Register
이걸 해결하기 위해 하드웨어가 쓰는 무기가 바로 Shift Register 입니다. 쉽게 말해 "미래의 WB 포트 예약 장부"입니다.
- 12자리의 2진수 비트(0 또는 1)로 되어 있습니다.
- 왼쪽부터 [1클럭 뒤, 2클럭 뒤, 3클럭 뒤... 12클럭 뒤]에 WB 포트가 비어있는지(0), 예약되어 있는지(1)를 나타냅니다.
- 매 클럭(CC)이 지날 때마다 시간이 흐르므로, 전체 비트를 왼쪽으로 한 칸씩 이동시킵니다(Shift).
- 충돌하면 추가 안하고, 다음 사이클 진행
3. 암호 해독
CC2
- 상황: MUL.D가 ID stage에 들어왔습니다.
- 계산: 표를 보니 MUL.D는 CC 11에 WB를 합니다. 지금이 CC 2니까, 9클럭 뒤에 포트가 필요하네요! ()
- 행동: 장부의 왼쪽에서 9번째 자리에 예약(1)을 겁니다.
- 장부 상태: 0000 0000 1000
CC3
- 상황: 시간이 1클럭 흘렀습니다. 기존 장부는 왼쪽으로 한 칸 쉬프트 됩니다. (0000 0000 1000 ➡️ 0000 0001 0000)
- 계산: 첫 번째 Integer 명령어가 ID에 들어왔습니다. CC 6에 WB를 하네요. 지금이 CC 3니까, 3클럭 뒤에 포트가 필요합니다. ()
- 행동: 장부의 왼쪽에서 3번째 자리에 예약(1)을 추가합니다.
- 장부 상태: 0010 0001 0000
CC4
- 상황: 장부 한 칸 쉬프트 ➡️ 0100 0010 0000
- 계산: 두 번째 Integer 명령어가 ID에 들어왔고, CC 7에 WB를 합니다. 3클럭 뒤에 포트가 필요합니다. ()
- 행동: 3번째 자리에 예약을 추가합니다.
- 장부 상태: 0110 0010 0000
CC5 (클라이맥스: 대참사 감지!)
- 상황: 장부 한 칸 쉬프트 ➡️ 1100 0100 0000 (지금 예약된 곳은 1번째, 2번째, 그리고 6번째 자리입니다.)
- 계산: 자, 대망의 ADD.D가 ID stage에 들어왔습니다. 표를 보니 CC 11에 WB를 합니다. 지금이 CC 5니까 6클럭 뒤에 포트가 필요합니다. ()
- 행동: 장부의 6번째 자리를 확인해 봅니다.결과: 어랏? 6번째 자리에 이미 1이 들어있네?! (CC 2에서 MUL.D가 예약해 놓은 겁니다!)
- 판정: 프로세서는 즉각 "삐빅! Write Port Hazard 감지! ADD.D는 예약 불가! 당장 ID stage에서 Stall 해!!" 라고 명령을 내립니다.
CC6
- 이전 장부: 1100 0100 0000
- 현재 장부: 1000 1000 0000
(맨 왼쪽의 1은 이미 자기 차례가 와서 WB를 끝내고 나간 명령어입니다.) - ADD.D의 재도전
아까 튕겨서 아직 ID stage에 갇혀있는 ADD.D가 다시 하드웨어에게 묻습니다. "저 이번 클럭에 출발하면 6클럭 뒤(CC 12)에 WB 할 건데, 지금 자리 있나요?" 하드웨어는 장부의 6번째 자리를 확인합니다.
장부를 보세요! 1000 1000 0000 -> 6번째 자리가 0으로 비어있습니다 - CC #6 최종 장부: 1000 1100 0000
Real MIPS R4000 Pipeline
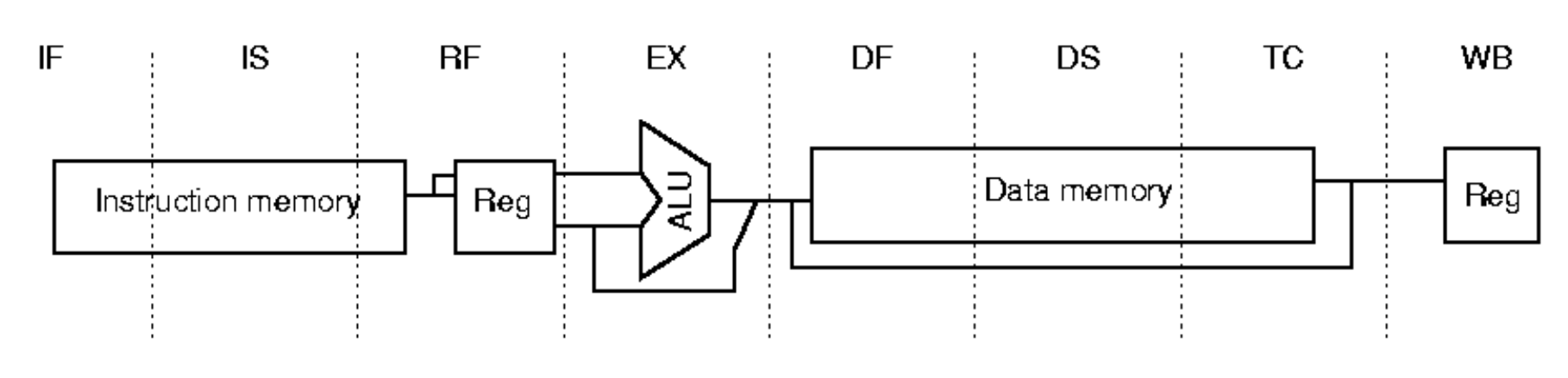
1. R4000은 왜 8단계로 쪼갰을까? (Superpipelining)
가장 근본적인 질문(What if)부터 던져봅시다. 5단계로 잘 쓰던 걸 왜 굳이 8단계로 늘렸을까요?
바로 Clock cycle time을 미친 듯이 줄여서, 프로세서의 동작 속도(Clock frequency)를 극한으로 끌어올리기 위해서입니다. (이것을 Superpipelining이라고 부릅니다.)
하지만 쪼개면 쪼갤수록, 각 단계의 작업은 짧아지지만 해저드가 발생했을 때 기다려야 하는 스톨(Stall) 칸 수는 무자비하게 늘어납니다. 이게 시험 포인트입니다!
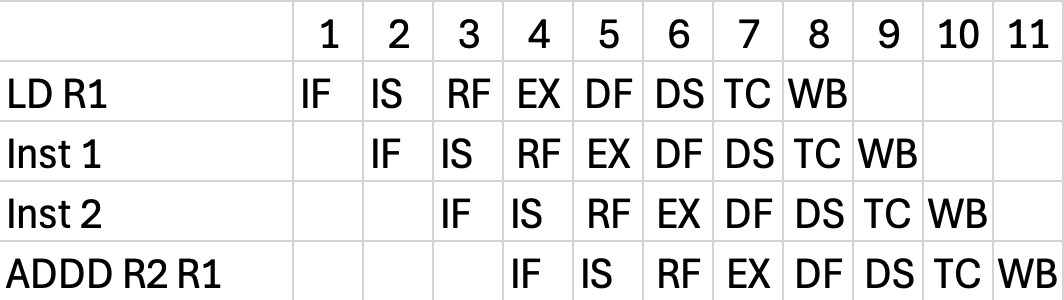
2. 5-Stage vs 8-Stage 완벽 맵핑
새로운 8개를 외울 필요가 전혀 없습니다. 기존 5단계가 어떻게 쪼개졌는지만 비교(Compare)하세요.
-
IF ➡️ IF, IS (Instruction Fetch를 2칸으로!)
- 이유: 명령어 캐시(I-Cache)에서 명령어를 가져오는 게 너무 느려서 1클럭 안에 안 끝납니다. 그래서 First half, Second half로 2클럭에 걸쳐서 가져옵니다.
-
ID ➡️ RF (Register Fetch)
- 기존의 해독(Decode)과 레지스터 읽기, 그리고 우리가 아까 뽀갰던 Hazard check를 여기서 수행합니다.
-
EX ➡️ EX (Execution)
- 여긴 똑같습니다. ALU 연산하고 메모리 주소(EA) 계산합니다.
-
MEM ➡️ DF, DS, TC (Memory를 무려 3칸으로!)
- 이유: 데이터 캐시(D-Cache)에서 값을 읽고 쓰는 것도 너무 느려서 쪼갰습니다.
- DF, DS: 데이터 캐시 접근의 첫 번째, 두 번째 파트. (DS가 끝나야 진짜 데이터가 튀어나옵니다!)
- TC (Tag Check): 캐시에서 가져온 게 진짜 내가 찾던 데이터가 맞는지(Hit/Miss) 확인하는 통제소입니다.
-
WB ➡️ WB (Write-Back)
- 결과값을 레지스터에 씁니다.
Branch
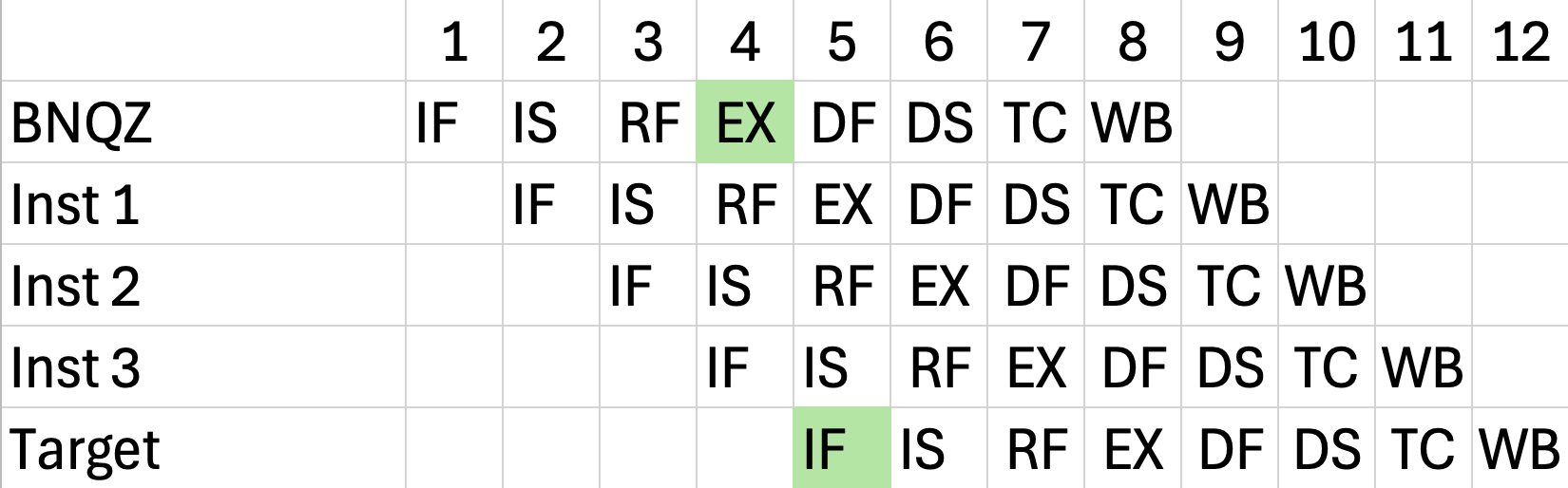
조건이 맞는지(True/False) 계산하고 타겟 주소를 계산하는 작업이 EX 단계(CC 4)가 되어서야 비로소 끝난다는 것입니다.
프로세서가 무조건 실행해 버리는 저 3칸의 공간을 3 Branch Delay Slots라고 부릅니다.
똑똑한 컴파일러는 프로그램 코드를 싹 뒤져서, 브랜치 결과와는 아무 상관 없는 '진짜 유용한 명령어 3개(Inst 1, 2, 3)'를 찾아내어 저 슬롯 안에 예쁘게 스케줄링(Scheduling) 해 넣습니다.
그 결과! 하드웨어는 단 1클럭의 멈춤(Stall)도 없이 파이프라인을 100% 효율로 꽉꽉 채워서 돌릴 수 있게 된 것입니다.
ILP (Instruction-Level Parallelism)
- 하나의 프로그램 안에서 여러 개의 명령어(Multiple instructions)를 동시에(Simultaneously) 실행해서 성능을 뽑아내는 것을 ILP라고 합니다.
- 사실 우리가 지금까지 배운 일반적인 파이프라인(명령어들이 1클럭 간격으로 겹쳐서 실행되는 것)도 기본적인 ILP를 하고 있는 겁니다
- 한계점: 하지만 일반 파이프라인은 아무리 완벽하게 돌아가도, 1클럭에 명령어 딱 1개만 파이프라인에 집어넣을 수 있습니다. 즉, 꿈의 성능인 (1 명령어당 1클럭)을 절대 뛰어넘을 수 없습니다.
한계 돌파를 위한 두 가지 무기 (Chapter 3의 핵심)
교수님이 기말고사에서 집중적으로 물어볼 두 가지 '사기급' 기술입니다.
A. Out-of-order execution (순서 밖 실행) & Speculation (추측 실행)
앞에서 길이 막히면 얌전히 스톨(Stall)하고 기다리던 착한 파이프라인은 잊으세요.
Out-of-order: "앞 명령어가 데이터 기다리느라 멈췄어? 그럼 뒤에 있는 명령어 중 의존성 없는 놈 먼저 끄집어내서 연산해버려!" (우리가 아까 배웠던 WAR, WAW 해저드가 여기서 폭발적으로 발생합니다.)
Speculation: "브랜치(Branch) 결과가 3클럭 뒤에 나온다고? 안 기다려! 그냥 갈 확률이 높은 쪽으로 '추측(Speculate)'해서 미리 다 실행시켜버려!"
B. Multiple-issue & Superscalar (물량 쏟아붓기)
지금까지 파이프라인은 1차선 도로였습니다. 이걸 2차선, 3차선 도로로 확장하는 겁니다.
Multiple-issue: 1클럭에 명령어를 1개가 아니라 2개, 3개, 4개씩 한꺼번에 파이프라인 입구(ID stage)에 밀어 넣습니다.
Superscalar: 이런 Multiple-issue 데이터 패스를 갖춘 마이크로아키텍처를 부르는 명칭입니다. (우리가 쓰는 인텔 펜티엄이나 애플 실리콘 칩들이 다 이렇습니다.)
Pipeline Performance 공식
이 슬라이드에서 시험에 나올 가장 중요한 수학 공식입니다. 교수님이 이 공식에 숫자를 던져주고 계산하라고 할 겁니다.
Ideal CPI (이상적인 CPI): 스톨이 하나도 없을 때의 기본 CPI입니다.
- 일반 파이프라인:
- 3-way Superscalar (1클럭에 3개씩 밀어 넣음): (이때는 CPI보다 IPC (Instructions Per Cycle) = 3이라는 표현을 더 많이 씁니다. 1클럭당 3개 완료!)
- Real CPI (현실의 CPI): 이상적인 수치에, 오늘 우리가 밤새 뜯어본 그 지긋지긋한 구조적, 데이터, 컨트롤 해저드 때문에 발생한 스톨(Stalls) 칸 수를 모조리 더한 값입니다.
