1. 왜 FP 파이프라인이 따로 필요할까? (구조의 확장)
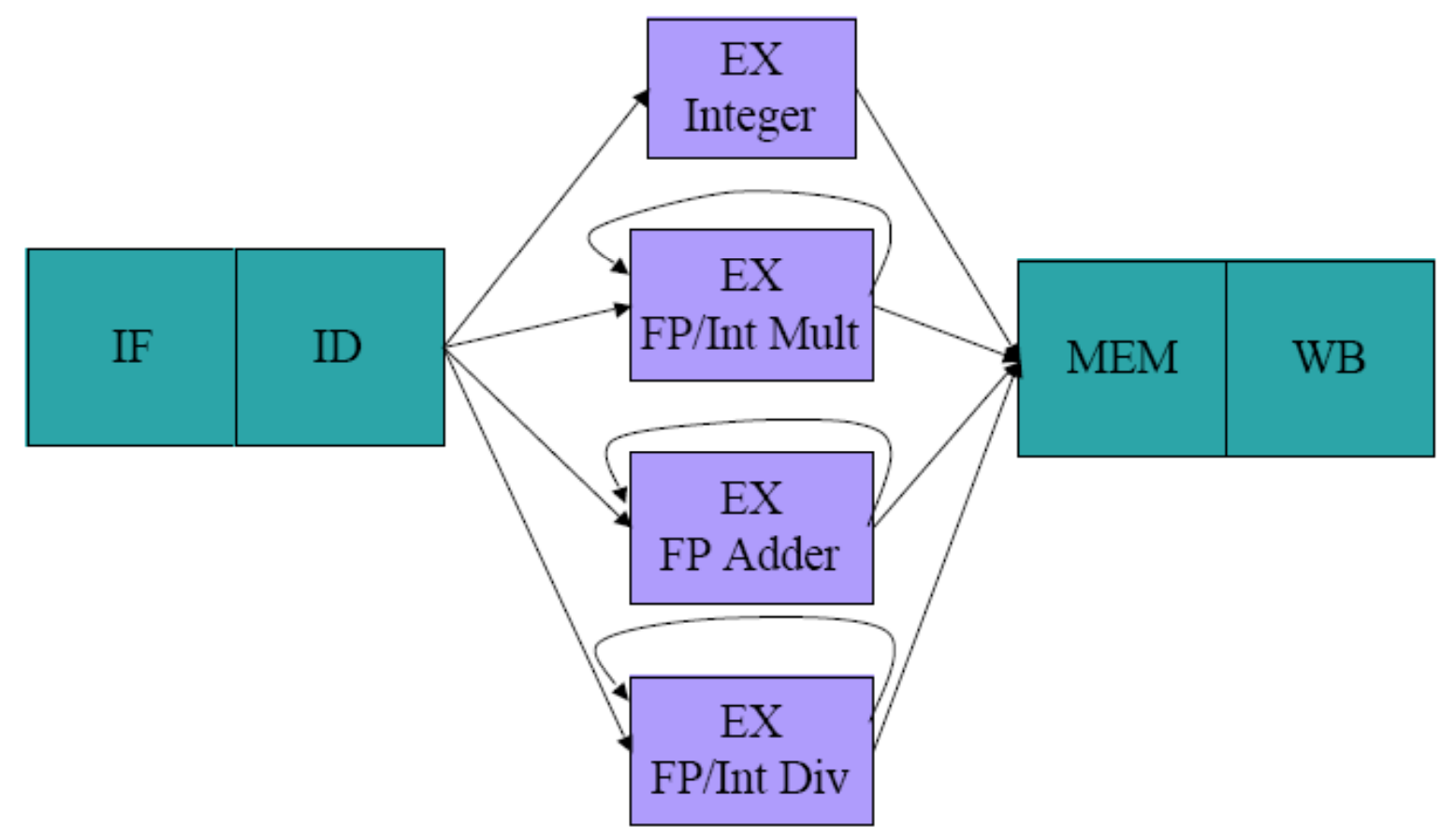
FP operations are long and cannot be completed in 5 cycles (EX lasts more than 1 cycle)
• Simply imagine that EX stage is duplicated for FP
기존 정수 연산(덧셈, 뺄셈 등)은 실행(EX) 단계가 단 1클럭(사이클) 안에 끝났습니다. 하지만 소수점 연산(곱셈, 나눗셈 등)은 도저히 1사이클 안에 끝낼 수 없을 만큼 무겁습니다.
해결책: 파이프라인의 IF와 ID 단계를 공통으로 거친 후, 명령어의 종류에 따라 각기 다른 길(EX Integer, EX FP Adder, EX FP Mult, EX FP Div)로 갈라지는 다차선 도로를 만듭니다.
- EX 단계의 파이프라이닝: 긴 EX 단계를 그냥 통째로 두는 것이 아니라,
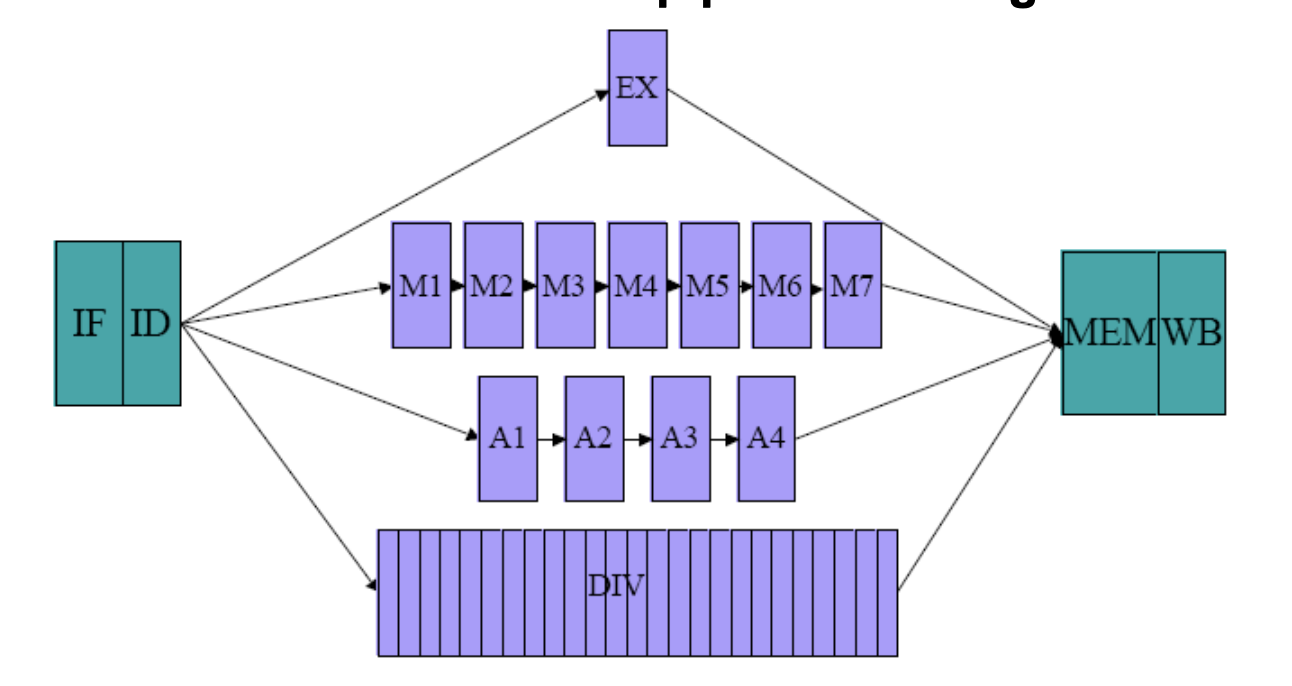
곱셈기(M1~M7)나 덧셈기(A1~A4) 내부도 여러 단계로 잘게 쪼개서(Pipelined) 매 클럭마다 새로운 명령어를 받을 수 있게 만듭니다. 단, 1사이클을 넘기는 FP 연산의 특성상 EX 단계가 옆으로 길게 늘어지게 됩니다.
2. 성능을 측정하는 두 가지 핵심 단어
1. Latency (지연 시간)
: "내 결과물은 언제 나와?"
정의: Produce a result(결과를 만드는 명령어)와 Use the result(그 결과를 쓰는 명령어) 사이에 기다려야 하는 사이클(Stall)의 수입니다.
직관적 이해: 내 차가 세차장에 들어간 순간부터, 세차가 다 끝나서 내가 다시 차를 몰고 나갈 수 있을 때까지 걸리는 총 대기 시간입니다.
하드웨어 적용: ADD.D F2, F4, F6 (F2를 계산함)
SUB.D F8, F2, F10 (F2가 필요함)
덧셈기(FP Adder)가 계산을 끝내고 F2에 값을 뱉어낼 때까지, 뒤따라오는 SUB.D는 파이프라인 안에서 하염없이 멈춰서(Stall) 기다려야 합니다. 이때 기다리는 사이클 수가 바로 Latency입니다.
(데이터 해저드, 즉 RAW Hazard와 직접적으로 연결되는 개념입니다.)
2. Initiation Interval (시작 간격)
: "다음 놈은 언제 들어갈 수 있어?"
정의: 같은 종류(Given type)의 연산 두 개를 연속으로 밀어 넣을 때(Issuing), 그 두 연산 사이에 반드시 띄워야 하는 사이클 수입니다.
직관적 이해: 앞차가 세차장 터널에 진입한 후, 그다음 차가 터널에 진입하기 위해 기다려야 하는 시간입니다. (앞차가 완전히 끝날 때까지 기다릴 필요 없이, 터널 안으로 조금만 들어가면 다음 차도 바로 꼬리를 물고 들어갈 수 있죠?)
하드웨어 적용:
만약 덧셈기(FP Adder) 내부가 완벽하게 파이프라인화(Fully pipelined) 되어 있다면? 앞의 덧셈이 안 끝났어도 다음 클럭에 바로 다음 덧셈 명령어를 밀어 넣을 수 있습니다. 이때 Initiation Interval = 1이 됩니다.
(구조적 해저드, 즉 Structural Hazard와 직접적으로 연결되는 개념입니다.)
Latency, Initiation interval Table

1. Latency + 1 = Execute Latency
(대기 시간 vs 실제 실행 시간)
표에 적힌 Latency와 실제 하드웨어가 작동하는 시간(Execute Latency)은 다릅니다. 이 차이를 완벽히 이해해야 타이밍 다이어그램에서 칸 수를 정확히 칠할 수 있습니다.
Execute Latency (실제 실행 시간): 명령어 하나가 Functional Unit(연산기) 방 안에 들어가서 작업이 완전히 끝날 때까지 걸리는 총 클럭(Cycle) 수입니다.
Latency (표에 적힌 숫자): 앞 명령어의 결과를 바로 뒷 명령어가 쓰려고 할 때(Data Dependency), 완벽한 Forwarding을 쓴다고 가정해도 어쩔 수 없이 멍때리며 기다려야 하는 스톨(Stall) 칸 수입니다.
[왜 +1을 할까? - FP Add 예시]
표에서 FP add의 Latency는 3입니다.
- 공식에 따라 Execute Latency는 cycles입니다. 즉, 덧셈기 방은 A1, A2, A3, A4 이렇게 4단계로 쪼개져 있습니다.
- 1번째 클럭에 덧셈을 시작하면 4번째 클럭에 작업이 끝납니다.
- 뒷 명령어가 이 값을 쓰려면 앞 명령어가 4단계까지 다 끝날 때까지 기다려야 하므로, 파이프라인 상에서 정확히 3칸을 쉬어야(Stall 3번) 값이 딱 맞아떨어지게 전달됩니다.
- Integer ALU를 보세요. Latency가 0이죠? Execute Latency가 1이라서 1클럭 만에 끝나니까, 기다릴 필요(Stall)가 0칸인 겁니다.
2. Initiation Interval : Pipelined vs Unpipelined
이건 하드웨어 자원 충돌(Structural Hazard)을 판별하는 절대적인 기준입니다. 아까 제가 비유한 '세차장 터널'을 떠올리시면 됩니다.
A. Initiation Interval = 1 👉 Pipelined (파이프라인화 됨)
-
적용 부품: FP add, FP/Int multiply
-
의미: 하드웨어 내부가 여러 단계로 잘게 쪼개져 있습니다. 앞 명령어가 연산을 다 끝내지 않았더라도, 매 클럭(Cycle)마다 새로운 명령어를 연산기에 계속 밀어 넣을 수 있습니다(Issue). * 결과: 덧셈이나 곱셈 명령어가 연달아 100개가 들어와도, 이 부품 안으로 들어가기 위해 입구에서 줄 서서 기다리는 Structural Hazard는 발생하지 않습니다.
B. Initiation Interval ≠ 1 👉 Unpipelined (파이프라인화 안 됨)
-
적용 부품: FP/Int divide (표에서 값: 25)
-
의미: 나눗셈기 하드웨어는 너무 복잡해서 내부를 쪼개지 못하고 하나의 거대한 통짜 블록으로 만들었습니다.
-
결과: 한 번 명령어가 들어가면 작업이 완전히 끝날 때까지 문을 굳게 닫아버립니다. 표에서 FP divide의 Latency가 24니까 실제 실행 시간(Execute Latency)은 25죠? 문이 닫혀있는 그 25 cycles 동안에는 절대로 다음 나눗셈 명령어가 이 방에 들어갈 수 없습니다! 이때 어마어마한 Structural Hazard 스톨이 발생합니다.
FP Pipeline의 특징
-
"Because DIV unit is not pipelined, structural hazards can occur"
- 나눗셈기는 Initiation interval이 1이 아니기 때문에, 앞 명령어가 끝날 때까지 뒷 명령어가 들어가지 못하고 꽉 막히는 Structural hazard가 발생합니다.
-
"Stalls for RAW hazards will be longer due to long latency"
- FP 연산은 실행 시간(Execute Latency)이 길죠? 덧셈만 해도 4클럭이 걸립니다. 따라서 앞의 결과값이 나올 때까지 뒤따라오는 명령어가 ID stage에서 멍때리며 기다려야 하는 Stall 칸수도 Integer보다 훨씬 길어집니다.
-
"Instructions don’t reach WB in order, so WAW hazards are possible"
- 명령어마다 끝나는 시간이 다르다 보니, 늦게 출발한 빠른 명령어(예: ADD)가 일찍 출발한 느린 명령어(예: DIV)보다 먼저 끝나버리는 Out-of-order completion이 발생합니다. 이 때문에 순서가 뒤집혀서 값이 덮어씌워지는 WAW hazard가 생깁니다.
-
"Because instructions have varying running times, number of register writes in a cycle can be >1"
- 이것도 Structural hazard의 한 종류입니다! 시작은 다르게 했지만, 끝나는 타이밍이 우연히 딱 겹쳐서 동시에 여러 명령어가 WB stage(레지스터 쓰기)로 쏟아져 들어오는 상황입니다. 쓰기 포트(Write port)는 보통 1개라 충돌이 납니다.
Data Hazard
RAW (Read After Write) - "어디서든 일어나는 국민 해저드"
- 발생: Integer pipeline (O), FP pipeline (O)
- 이유: 앞 명령어가 쓴(Write) 데이터를 뒷 명령어가 읽어야(Read) 하는 가장 기본적인 데이터 흐름입니다. 파이프라인의 종류를 가리지 않고 무조건 발생합니다.
WAW (Write After Write) - "순서가 뒤집혀야만 발생"
- 발생: Integer pipeline (X), FP pipeline (O)
- 이유: 일반적인 5-stage Integer pipeline은 모든 명령어가 똑같이 5칸을 지나가므로 무조건 들어온 순서대로 끝납니다(In-order completion). 절대 순서가 역전되지 않으므로 WAW는 발생 불가능합니다! 하지만 슬라이드 내용처럼 끝나는 시간이 제각각인 FP pipeline에서는 순서가 뒤집혀서 발생합니다.
WAR (Write After Read) - "읽기도 전에 써버리는 시간 여행"
- 발생: Standard Integer/FP pipeline (X), 오직 Out-of-order execution (O)
- 이유: 일반적인 파이프라인에서는 무조건 ID stage(2단계)에서 값을 먼저 읽고, 한참 뒤인 WB stage(마지막 단계)에서 값을 씁니다. 즉, '읽기'가 무조건 '쓰기'보다 먼저 일어나게 하드웨어가 설계되어 있습니다. 따라서 뒤따라오는 명령어가 앞 명령어보다 먼저 값을 써버리는 WAR는 일반적인 In-order 파이프라인(Integer/FP 모두)에서는 절대 발생하지 않습니다. 아주 복잡한 Out-of-order CPU에서만 발생합니다.
Example

치명적인 오개념: "L.D는 F2를 쓰는(Read) 게 아닙니다!"
"L.D도 F2를 쓰는데 그 결과가 ADD.D가 끝나야 나오잖아?" 라고 하셨죠. 이것이 바로 교수님이 파놓은 가장 완벽한 함정입니다.
L.D F2, 0(R2)의 진짜 의미: "메모리(R2 주소)에서 값을 읽어와서, 도착지인 F2 레지스터에 덮어써라(Write)!"
즉, 마지막 L.D는 ADD.D가 계산한 F2 값을 기다릴(Read) 필요가 전혀 없습니다.
자기 갈 길만 가면 되기 때문에 EX 단계(메모리 주소 계산)를 당장 실행해도 아무 문제가 없습니다. 왜 13, 14, 15에서 멈춰 섰을까? (WAW Hazard 방어)
자, 이제 아까 우리가 그토록 강조했던 WAW Hazard (순서 역전의 대참사)를 타임라인에 그대로 대입해 보겠습니다.
만약 저 stall 3칸이 없었다고 상상해 봅시다.
- I3 (ADD.D F2): 엄청 느린 덧셈기에서 끙끙대다가 cc 17에 F2에 값을 씁니다(WB).
- I4 (L.D F2): 스톨 없이 쌩쌩 달렸다면? 12클럭에 ID, 13에 EX, 14에 MEM, 그리고 cc 15에 F2에 값을 씁니다(WB).
- 대참사 발생: 프로그램 순서상 L.D가 맨 마지막 명령어이므로, 최종적으로 F2에는 메모리에서 방금 가져온 신선한 값이 들어있어야 합니다. 그런데 L.D가 15클럭에 값을 예쁘게 써놨더니, 굼벵이처럼 뒤늦게 도착한 ADD.D가 17클럭에 자기의 옛날 계산 결과로 F2를 덮어씌워 버립니다!
1. 첫 번째 문장의 의미: "바보 같은 코드지만 하드웨어는 방어해야 한다"
ADD.D로 뼈 빠지게 계산해서 F2에 넣어놓고, 바로 다음 줄에서 L.D로 메모리에서 값을 가져와 F2에 덮어버리죠? 프로그래머가 보기엔 "왜 이딴 쓸데없는 짓을 해?" 싶겠지만, 실제 CPU에서는 브랜치 예측(Branch Prediction)이 틀렸거나 컴파일러가 최적화를 꼬아놓았을 때 이런 코드가 흔하게 들어옵니다.
공대식 룰: "코드가 바보 같아도, 하드웨어는 무조건 최신 값(L.D의 값)이 레지스터에 남도록 방어해야 한다!"
2. 첫 번째 해결책 (Approach 1): 무식하지만 확실한 '강제 대기'
"One approach is to delay writing stage of the later instruction"
이게 바로 우리가 방금 전 타임라인에서 본 [14, 15, 16 클럭의 Stall 3칸]의 정체입니다!
나중에 들어온 놈(L.D)이 먼저 끝나버릴 것 같으니까, 하드웨어가 멱살을 잡고 WB stage를 지연(delay)시키는 겁니다. 먼저 들어온 ADD.D가 17클럭에 쓰기를 끝낼 때까지 강제로 기다리게 한 뒤, 18클럭에 최신 값을 덮어쓰게 만드는 방식입니다.
WAW: stall at memory stage"
라고 필기하신 게 바로 이 뜻입니다. "다른 건 다 하게 내버려 두고, 메모리 단계로 넘어가기 직전 문 앞에서 대기시킨다!"
- 표(Timeline): EX 끝내고 MEM 가기 직전에 stall 3칸
- 이론(Concept): 나중에 온 놈이 먼저 쓰기(WB)를 해버리는 순서 역전(WAW)을 막기 위해
- 교수님 필기(Hint): 그 멈추는 위치가 바로 Memory stage 앞이다!
3. 두 번째 해결책 (Approach 2): 똑똑한 하드웨어의 '쓰레기통 직행'
"Another approach is to stamp the result of the earlier instruction and don’t write it into memory or register"
이건 시간을 낭비하는 Stall을 없애버리는 최신 하드웨어의 똑똑한 방식입니다.
나중에 들어온 L.D를 멈추지 않고 쌩쌩 달리게 냅둡니다. 그럼 15클럭쯤에 F2에 최신 값을 싹 써버리겠죠?
그리고 한참 뒤인 17클럭에 굼벵이 ADD.D가 계산을 끝내고 자기 값을 F2에 쓰려고(WB) 할 때, 하드웨어가 이렇게 말합니다.
"야, 네가 계산한 값은 이미 유통기한 지났어(stamped). 어차피 L.D 값이 최신이니까 네 값은 레지스터에 쓰지 말고 그냥 버려(don't write / drop)!"
즉, 과거 명령어의 WB stage 자체를 무효화(Nullify)해버리는 기술입니다.
프로세서는 data hazard 가 있을지 어떻게 예상할까
1. Register Comparison
파이프라인의 각 단계(Stage) 사이에는 명령어의 정보를 임시로 저장하는 창고인 Pipeline Register(IF/ID, ID/EX, EX/MEM 등)가 있습니다. 하드웨어는 매 클럭마다 이 창고에 들어있는 '레지스터 번호'를 서로 비교(Compare)합니다.
현재 ID stage(해독 단계)에 막 들어온 명령어: "나는 F2랑 F4를 읽을 거야! (Source Registers)"
현재 EX나 MEM stage를 지나가고 있는 앞 명령어: "나는 계산 다 끝나면 F2에 값을 쓸 거야! (Destination Register)"
Hazard Detection Unit 내부에는 비교기(Comparator) 회로가 잔뜩 들어있습니다. 만약 앞 명령어가 쓰려는 목적지 번호(Destination)와 뒷 명령어가 읽으려는 출발지 번호(Source)가 일치(Match)하면?
👉 하드웨어는 즉각 "삐빅! 겹쳤다! RAW Hazard 발생!" 이라는 신호(Control signal)를 뿜어냅니다.
2. 해저드를 발견했을 때의 행동 강령 (Action)
겹친다는 걸 알았으니 이제 해결을 해야겠죠? 하드웨어는 두 가지 무기를 꺼냅니다.
무기 A: Forwarding Unit (하이패스 열어주기)
단순한 연산(ADD, MUL 등)이라서 앞 명령어가 이미 값을 계산해 놨다면, 굳이 스톨을 걸지 않고 Forwarding Multiplexer(MUX)를 조작해서 값을 뒤로 휙 던져줍니다. "야, 메모리나 레지스터 갈 필요 없어! 이거 방금 계산한 따끈따끈한 값이니까 바로 써!"
무기 B: Hazard Detection Unit의 스톨 (Stall / Bubble)
가장 악명 높은 Load-Use Hazard 같은 상황입니다.
앞 명령어가 L.D F2, 0(R1)인데, 아직 메모리에서 값을 가져오지도 않았습니다(MEM stage 진입 전). 그런데 바로 뒤따라오는 ADD.D가 ID stage에서 F2를 내놓으라고 난리를 칩니다. 이때 Hazard Detection Unit이 강력한 통제에 들어갑니다.
얼음 (Freeze): PC(Program Counter)와 IF/ID 레지스터의 업데이트를 막아버립니다. (명령어들이 더 이상 앞으로 전진하지 못하게 멱살을 잡습니다.)
공기 주입 (Bubble/NOP): ID/EX 레지스터 쪽으로는 아무런 의미 없는 껍데기 명령어인 NOP (No Operation)을 쏴서 보냅니다. 이게 바로 우리가 타임라인에서 그리는 텅 빈 Stall 칸의 진짜 정체입니다!
