Control Hazards
근본적인 문제: 분기문(Branch)의 딜레마
파이프라인은 명령어를 쉬지 않고 연속해서 가져와야(Fetch) 속도가 빠릅니다. 그런데 if문 같은 분기명령어(Branch)를 만나면 다음 두 가지를 알아내기 전까지는 다음 명령어를 제대로 가져올 수 없습니다.
Target Address (목적지 주소): 그래서 어디로 점프할 건데?
Branch Outcome/Condition (조건 결과): 진짜로 점프를 할 거야, 말 거야?
이 두 가지를 알아낼 때까지 멍때리거나(Stall), 잘못 가져온 걸 버리는(Flush) 과정에서 발생하는 성능 저하(Penalty)를 줄이기 위해 다음 3가지 '정적(Static)' 기법을 사용합니다.
Static Techniques to Reduce Branch Penalties
• Freeze or flush the pipeline
• Predict not taken
• Predict taken
NOP (No-Op): 아무것도 안 하고 1사이클을 낭비하는 명령어입니다. 분기문으로 인해 잘못 가져온 명령어들을 지워버릴 때(Flush) 이 NOP로 덮어씌워서 없는 셈 칩니다.
No-op
NOP (No Operation), 일명 '노옵'은 말 그대로 "아무 연산도 하지 말고 그냥 한 턴 쉬어라!"라고 CPU에게 내리는 특별한 명령어입니다.
Freeze or Flush the Pipeline

"Holding or Deleting any instructions after the branch until the branch destination is known"
가장 무식하지만 안전한 방법입니다. 교차로에서 어디로 갈지 확실해질 때까지 일단 파이프라인을 멈추고(Freeze) 숨을 참는 것입니다.
- 하드웨어 구조상 무조건 다음 명령어(PC+4) 하나는 가져오게 되는데, 그걸 지워버리고(Flush) 확실한 결정이 날 때까지 기다립니다.
- 장점: 구현이 아주 쉽습니다.
- 단점: 점프를 하든 안 하든 매번 파이프라인이 멈추기 때문에 엄청난 시간(사이클) 낭비가 발생합니다.
Predict Not Taken
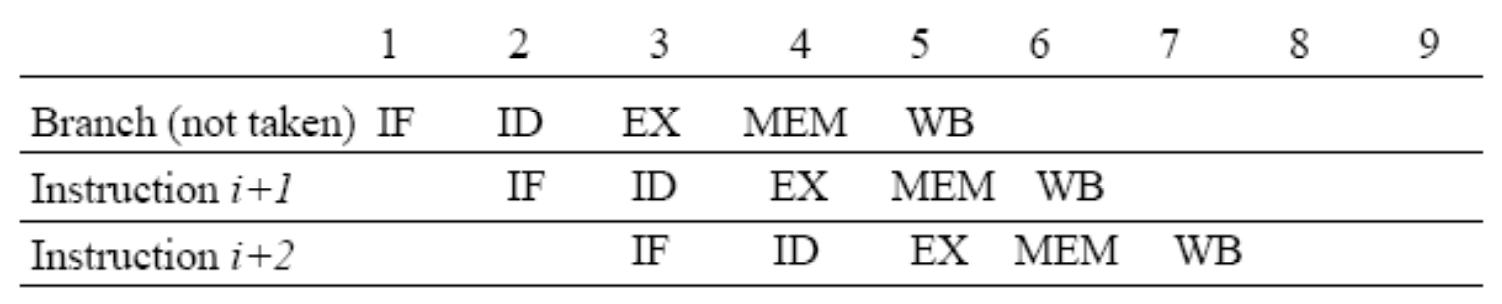
"Treat every branch as not taken. If taken, turn next instruction into noop"
"에이, 설마 점프하겠어? 일단 직진하자!"라고 무조건 예측하는 방법입니다. 분기 명령어가 계산을 하는 동안, 파이프라인은 쉬지 않고 바로 밑에 있는 명령어(PC+4, PC+8)들을 계속 가져옵니다.
- 예측 성공 (Not Taken, 점프 안 함): 직진하는 게 맞았으니 멈춤 없이 100% 성능을 냅니다. (페널티 0)
- 예측 실패 (Taken, 점프 함): 앗, 꺾었어야 했네요! 직진하면서 미리 가져왔던 명령어들을 전부 NOP(아무것도 안 하는 명령어)로 덮어씌워서 무효화(Flush)시키고, 진짜 목적지에서 다시 명령어를 가져옵니다. (페널티 발생)
Predict Taken

"Treat every branch as taken, continue fetching instructions from the target address"
이번엔 반대로 "무조건 점프할 거야!"라고 예측하고, 목적지 주소(Target Address)에서 명령어를 미리 가져오는 방법입니다.
"This would make sense if we knew branch target before branch outcome" (목적지 주소를 점프 여부보다 먼저 알 때만 의미가 있다)
"In our pipeline it doesn’t make sense as we know branch target at the same time as branch outcome" (우리 파이프라인에선 둘을 동시에 알게 되므로 이 방법이 의미가 없다)
이유: "점프할 거야!"라고 예측했으면 당장 목적지에서 명령어를 가져와야 합니다. 그런데 목적지 주소 계산과 조건 평가가 똑같이 EX 단계에서 끝난다면? 목적지 주소를 모르는데 어떻게 미리 가져올 수 있을까요? 결국 주소를 알 때까지 파이프라인이 멈춰야 하므로 Freeze 기법과 다를 바가 없어집니다.
Example
Assume that the branch target address is
computed in ID, the branch condition is evaluated
in EX
자, 이제 교수님이 던져주신 하드웨어 조건입니다. 주소(Target)는 2단계(ID)에서 나오고, 진짜 뛸지 말지(Condition)는 3단계(EX)에서 나옵니다. 이때 타임라인이 어떻게 되는지 그려볼까요?
1. CC1 (IF): Branch 명령어 가져옴.
2. CC2 (ID): Branch 명령어 해독 중. (하드웨어는 일단 PC+4를 가져옵니다). 이때 Target Address 획득!
3. CC3 (EX): Branch 조건 계산 중. 이때 진짜 점프 여부(Condition) 획득!
[3가지 기법의 페널티 비교]
1. Freeze:
CC2에 가져온 PC+4 지우고, CC3에서 멍때림. CC4에 최종 결과대로 가져옴. 점프하든 안 하든 2사이클 페널티.

2. Predict Not Taken:
CC2에 PC+4 가져옴. CC3에 PC+8 가져옴.
- 안 뛰면(예측 성공): 그대로 진행. 0사이클 페널티.

- 뛰면(예측 실패): 잘못 가져온 2개 비우고 CC4에 타겟 가져옴. 2사이클 페널티.
CC3 끝에서 점프해야 한다는 걸 깨달았습니다. 미리 가져온 2개를 버리고 CC4에 진짜 타겟으로 달려갑니다.

3. Predict Taken
: CC2에 PC+4 가져옴 (아직 타겟 주소를 모르니까 어쩔 수 없음). CC2 끝에서 타겟 주소를 알았으니 CC3에 '타겟 명령어'를 미리 가져옴!
-
뛰면(예측 성공): CC2 끝에서 타겟 주소를 알아내어 CC3에 타겟을 가져왔고, 이 판단이 맞았습니다! (CC2에 억지로 가져왔던 PC+4 딱 1개만 버립니다.

-
안 뛰면(예측 실패): 뛴다고 믿고 CC3에 타겟까지 가져왔는데, CC3 끝에서 "안 뛰는 거네!"라고 깨닫습니다. 억지로 가져왔던 PC+4와, 잘못 예측한 Target을 모두 버리고, 다시 PC+4부터 올바르게 가져옵니다.

Performance Degradation Due to Control Hazards
이런 잦은 페널티(거품)들 때문에 CPU의 평균적인 속도(CPI)가 느려지는 것을 계산하는 공식입니다.
즉, 위에서 구한 페널티(1칸, 2칸)에 "점프를 얼마나 자주 하는가(Branch Frequency)"를 곱해서 실제 성능이 얼마나 깎였는지(Degradation)를 평가하는 것입니다.
Example
Assume a deeper pipeline where it takes 3 pipeline stages until branch target is known and 1 more to evaluate branch condition. Find the effective addition to CPI assuming the following frequencies of branches and the following branch penalties
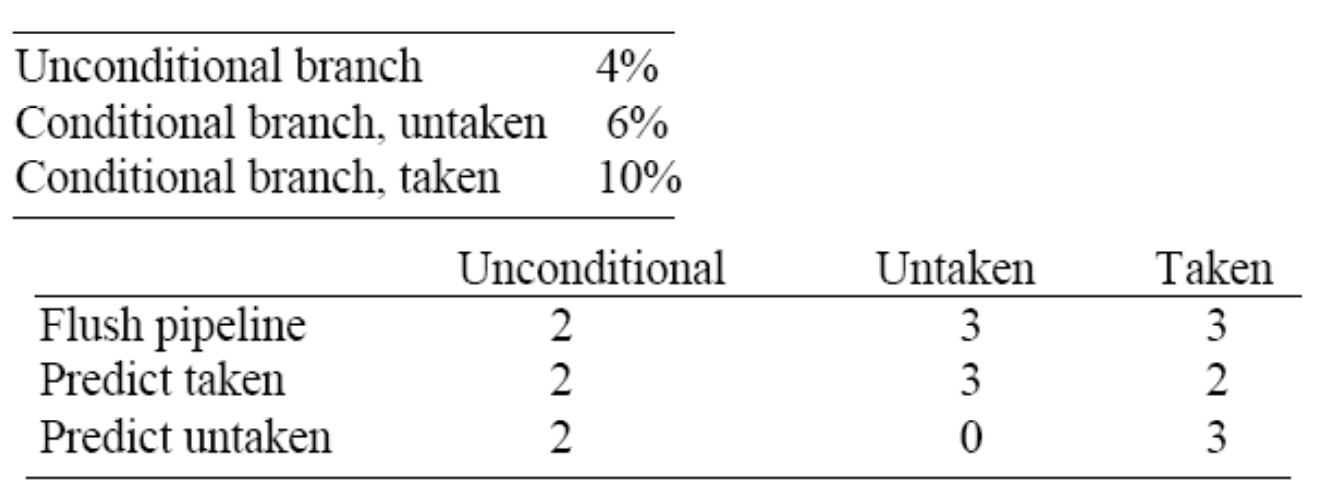
(mid term 시험에서는 아래 테이블 제공안한다. 알아서 계산해서 찾아야함)
가로축 (열): 명령어의 "실제 정답(상황)" 입니다.
세로축 (행): 하드웨어가 선택한 "찍기 전략(예측)" 입니다.
1단계: 시험장에서 페널티 테이블(Penalty Table) 직접 그리기
문제의 핵심 하드웨어 조건을 먼저 뜯어봅시다.
"takes 3 pipeline stages until branch target is known and 1 more to evaluate branch condition"
- 타겟 주소(Target Address): 3단계 끝에서 알아냄. (즉, 4번째 사이클부터 타겟 명령어를 가져올 수 있음)
- 조건 평가(Condition): 4단계 끝에서 알아냄. (즉, 4단계 끝이 되어야 내가 맞게 예측했는지 틀렸는지 확정됨)
1. Unconditional 열 (실제 상황: 무조건 점프하는 명령어)
무조건 점프하는 명령어(Jump)는 애초에 "뛸까? 말까?"(조건)를 고민할 필요가 없습니다. 오직 "어디로 뛰지?(타겟 주소)"만 3단계 끝에서 알아내면 됩니다.
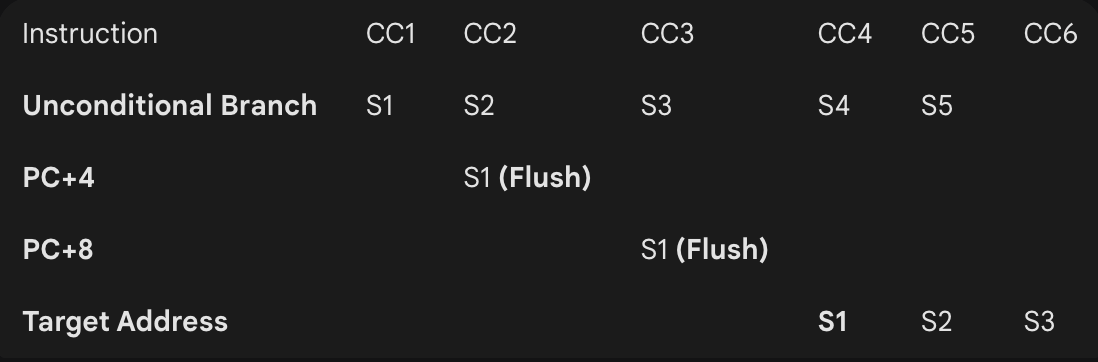
-
Predict taken 전략: 무조건 뛰니까 어차피 예측 성공! 하지만 주소를 몰라서 2칸(2단계, 3단계) 낭비 👉 페널티 2
-
Predict untaken 전략: 무조건 뛰는 명령어인데 안 뛴다고 찍는 바보 같은 상황입니다. 하지만 이 명령어는 조건 판단을 안 하므로, 주소가 나오는 3단계 끝에서 무조건 목적지로 뜁니다. 👉 페널티 2
-
Flush pipeline 전략: 타겟 주소가 나올 때(3단계 끝)까지 숨참고 대기. 👉 페널티 2
결론: 무조건 점프는 조건(Condition) 평가를 4단계까지 기다릴 필요가 없기 때문에, 무슨 전략을 쓰든 3단계 끝에서 상황이 종료되어 모두 2사이클 페널티를 받습니다.
2. Untaken 열 (실제 상황: 조건부 점프인데, "결과적으로 안 뜀")
가로축이 '안 뜀'이 정답인 상황입니다. 회원님이 쓰신 예측 성공/실패 논리가 여기서 정확히 맞아떨어집니다!
-
Predict untaken 전략 (예측 성공): 안 뛴다고 뚝심 있게 직진했는데, 실제 정답도 안 뜀! 👉 페널티 0

-
Predict taken 전략 (예측 실패): 뛴다고 찍고 엉뚱한 짓을 했는데, 4단계 끝에서 "안 뛰는 거였네!" 깨달음. 쓰레기통에 3칸 버림. 👉 페널티 3

-
Flush pipeline 전략: 4단계 끝에서 정답이 나올 때까지 무작정 대기. 👉 페널티 3
3. Taken 열 (실제 상황: 조건부 점프인데, "결과적으로 뜀")
가로축이 '뜀'이 정답인 상황입니다.
- Predict taken 전략 (예측 성공): 뛴다고 예측했고 진짜로 뜀! (주의: 페널티 0이 아닙니다!) 뛴다고 예측은 했지만, 타겟 주소가 3단계 끝에서야 나오기 때문에 그 전까지 2칸(2, 3단계)은 어쩔 수 없이 낭비함. 👉 페널티 2

-
Predict untaken 전략 (예측 실패): 안 뛴다고 직진했는데, 4단계 끝에서 "뛰는 거였네!" 깨달음. 직진한 3칸 다 버림. 👉 페널티 3

-
Flush pipeline 전략: 4단계 끝에서 정답 나올 때까지 무작정 대기. 👉 페널티 3
2단계: Effective Addition to CPI (추가 CPI) 계산하기
이제 직접 만든 표의 페널티 숫자와, 문제에서 주어진 빈도(Frequency)를 곱해서 더해주기만 하면 끝납니다. 이 값이 바로 제어 해저드 때문에 성능이 깎이는(추가되는 CPI) 수치입니다.
[주어진 빈도 조건]
- 무조건 점프 (Unconditional): 4% (0.04)
- 조건부 점프, 안 뜀 (Untaken): 6% (0.06)
- 조건부 점프, 뜀 (Taken): 10% (0.10)
각 전략별로 계산해 보겠습니다.
- Flush pipeline (대기 전략)
- 계산:
- 결과:
- Predict Taken (점프 예측 전략)
- 계산:
- 결과:
- Predict Untaken (점프 안 함 예측 전략)
- 계산:
- 결과:
최종 정답:
Predict Untaken 기법을 썼을 때 추가되는 CPI가 0.38로 가장 낮습니다. (성능 저하가 가장 적음)
만약 이상적인 파이프라인의 CPI가 1.0이라면, 이 기법을 썼을 때 실제 CPU의 CPI는 1.38이 됩니다.
TIP
- unconditonal = target -1
- untaken, donditon untakedn is always 0
- Branch outcome -1
