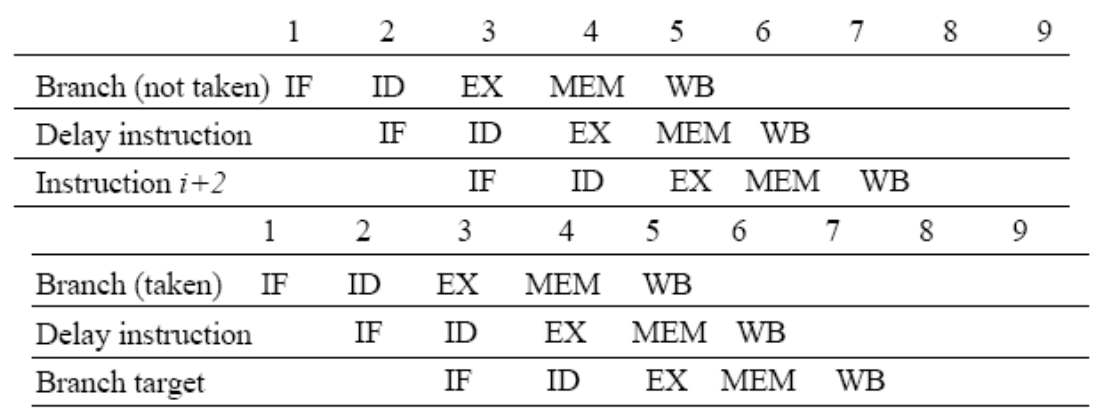
Delayed Branches
Compiler reorders instructions so that the next
instruction after the branch is:
– Useful in most cases
– Harmless both in taken and not taken case
– Disallow putting a branch in the delay slot
지연 분기(Delayed Branch)는 하드웨어가 어쩔 수 없이 겪어야 하는 1클럭의 시간 낭비(페널티)를, 아예 "이건 버그가 아니라 스펙(규칙)이야!"라고 선언해 버린 과거 RISC 설계자들의 천재적인 꼼수(트릭)입니다.
이전에 우리는 분기문(BEQ, BNEZ 등)을 만나면 주소와 조건을 알아낼 때까지 파이프라인에 1칸의 거품(Stall/NOP)이 생기는 것을 보았습니다. 설계자들은 이 1칸을 버리기 너무 아까웠습니다. 그래서 하드웨어에 다음과 같은 아주 특이한 절대 규칙을 만들어버립니다.
"분기 명령어 바로 밑에 있는 1줄(Delay Slot)은, 네가 점프를 하든 안 하든 무.조.건 실행해 줄게!"
이 마법의 1줄 공간을 지연 분기 슬롯(Branch Delay Slot)이라고 부릅니다.
1. 어떻게 작동할까? (컴파일러의 마법)
하드웨어가 "밑에 1줄은 무조건 실행할게"라고 판을 깔아주면, 똑똑한 소프트웨어(컴파일러)가 나서서 코드의 순서를 바꿉니다(Code Scheduling).
[원래 코드: 1클럭 낭비 발생]
DADDI R1, R2, R3 // 1. Independent math operation
BNEZ R4, Target // 2. Branch instruction
// Stall (Bubble) occurs here naturally![지연 분기 최적화 코드: 낭비 제로]
컴파일러가 분기문 위에 있던 연관 없는 명령어를 끌어내려서 분기문 바로 밑(Delay Slot)에 꽂아 넣습니다.
BNEZ R4, Target // 1. Branch instruction
DADDI R1, R2, R3 // 2. Delay Slot! Executed even if jumping to Target!결과: CPU는 BNEZ의 점프 목적지를 계산하는 1클럭 동안 멍때리지 않고, 밑에 있는 DADDI를 알차게 실행합니다. 점프를 하든 안 하든 DADDI는 원래 실행해야 했던 유용한 명령어이므로 성능이 1클럭 꽁짜로 향상됩니다!
2. Delay Slot을 채우는 3가지 전략
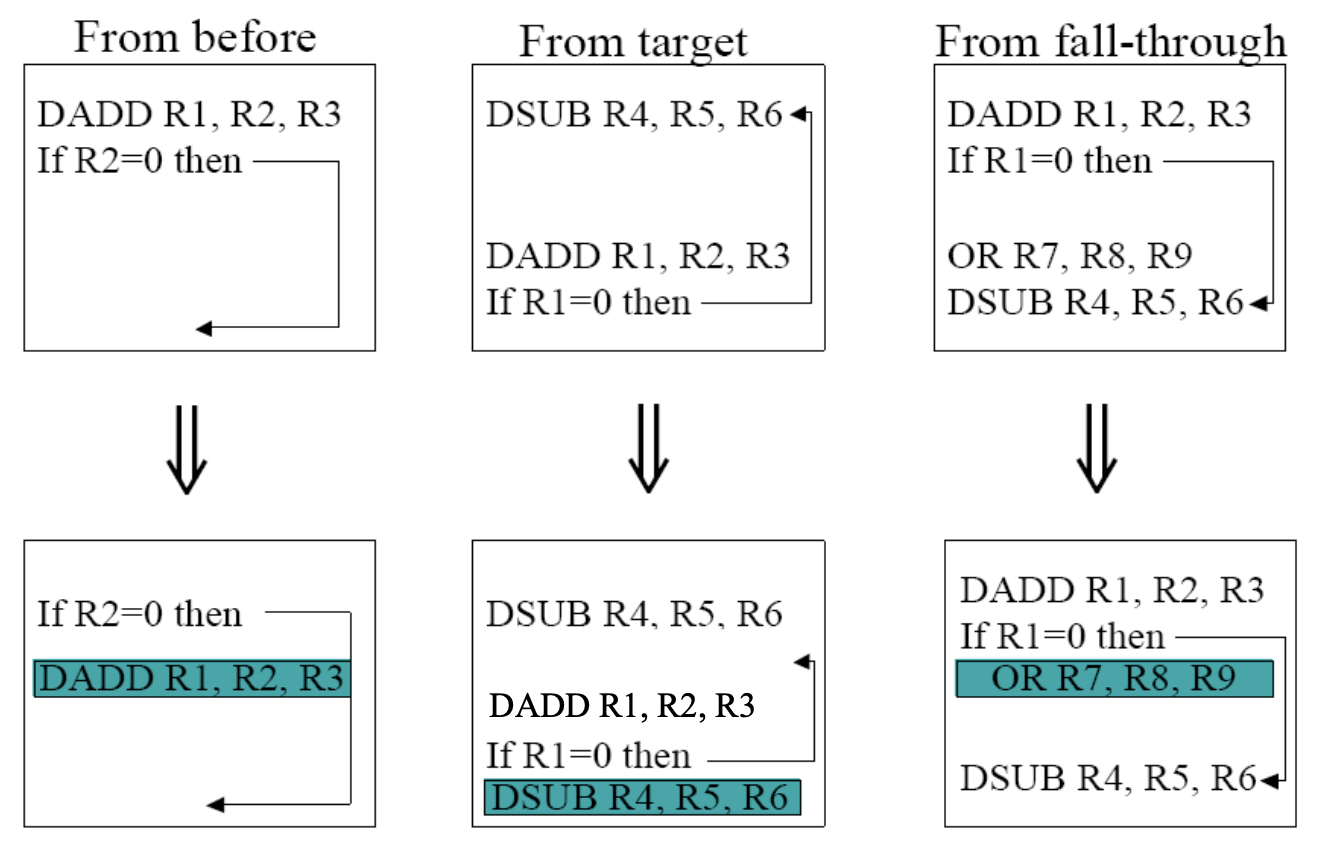
컴파일러가 이 빈칸을 채우기 위해 코드를 끌어오는 위치에는 3가지 전략이 있습니다.
분기문 이전에서 가져오기 (From Before):
가장 완벽하고 이상적인 방법입니다. 위 예시처럼 분기 조건(R4)에 영향을 주지 않는 명령어를 그냥 밑으로 내립니다. (항상 안전함)
"어차피 실행할 거, 순서만 살짝 바꾸자!"
가장 이상적이고, 가장 안전하며, 컴파일러가 1순위로 찾는 완벽한 전략입니다.
-
그림 설명: 원래 코드를 보면 If R2=0 then 분기문 위에 DADD R1, R2, R3 명령어가 있었습니다. 컴파일러는 이 DADD 명령어를 끌어내려서 분기문 바로 밑(Delay Slot)에 색칠된 박스처럼 끼워 넣습니다.
-
왜 안전할까? DADD 명령어는 R1을 계산하는 명령어이고, 분기문은 R2를 검사합니다. 서로 데이터 의존성이 전혀 없습니다! 어차피 분기문을 만나기 전에 실행됐어야 할 운명(?)이었으므로, 분기문 직후에 실행되더라도 프로그램 결과에 아무런 영향을 주지 않습니다.
목적지에서 가져오기 (From Target):
루프(Loop)처럼 '주로 점프할 것 같은(Taken)' 경우에 씁니다. 점프했을 때 도착할 곳의 첫 명령어를 미리 슬롯에 당겨옵니다. (단, 점프를 안 했을 때 그 명령어가 실행되어도 프로그램에 에러가 없어야 함)
"점프할 확률이 높네? 도착지에 있는 거 미리 하나 땡겨오자!"
분기문 위에서 도저히 가져올 만한 명령어를 못 찾았을 때 쓰는 두 번째 전략입니다. 주로 for문이나 while문처럼 "점프(Taken)할 확률이 아주 높은 경우"에 사용합니다.
-
그림 설명: 코드를 보면 점프해서 도착하는 타겟 위치(화살표의 끝부분)에 DSUB R4, R5, R6 명령어가 대기하고 있습니다. 컴파일러는 이 타겟 명령어를 복사해서 분기문 바로 밑 슬롯에 끼워 넣습니다.
-
주의할 점 (엄격한 조건): 이 전략은 점프를 안 하고 직진(Fall-through)하게 되었을 때 문제가 생기지 않아야만 쓸 수 있습니다. 점프 안 할 건데 엉뚱하게 DSUB가 실행되어버리니까요. 그래서 컴파일러는 "어차피 직진해도 R4 값은 금방 다른 값으로 덮어씌워지니까, 여기서 실수로 한 번 빼기 연산해도 티 안 나네!"라고 확신할 때만 이 방법을 씁니다.
다음 줄에서 가져오기 (From Fall-through):
if문처럼 '주로 점프 안 할 것 같은(Not Taken)' 경우에 씁니다. 점프 안 했을 때 실행될 명령어를 당겨옵니다.
"점프 안 할 확률이 높네? 원래 하려던 거 미리 하나 땡겨오자!"
이 전략은 예외 처리(if (error) 등)처럼 "점프를 안 하고 직진(Not Taken)할 확률이 아주 높은 경우"에 주로 사용합니다.
-
그림 설명: 점프를 안 했을 때 정상적으로 실행될 바로 다음 줄 명령어가 OR R7, R8, R9입니다. 이 명령어를 당겨와서 지연 슬롯에 채워버립니다.
-
주의할 점 (엄격한 조건): 이것도 반대로, 점프(Taken)를 해버렸을 때 문제가 생기지 않아야만 쓸 수 있습니다. 점프해서 다른 곳으로 갈 건데 OR 연산이 억지로 한 번 실행되기 때문입니다. 타겟 목적지에서 R7 레지스터가 쓰이지 않거나, 어차피 초기화될 예정이라 오류가 안 날 때만 안전하게 쓸 수 있습니다.
NOP 채우기 (최후의 수단):
도저히 위 3가지 방법으로 채울 안전한 명령어를 못 찾으면, 어쩔 수 없이 NOP를 넣습니다. (이러면 결국 Stall과 똑같이 1클럭을 낭비하게 됩니다.)
Example 1
Assume the processor has the 5 classic pipeline stages, and the branch outcome is computed out at the end of EX stage. Using the techniques such as shuffling instructions, and adjusting displacement to reduce the hazard penalties in the following instruction sequence
Loop: LD R1, 50(R2)
ADD R3, R4, R1
MUL R6, R1, R3
ST R6, 60(R2)
ADD R4, R4, #10
SUB R2, R2, #4
BNEZ R2, Loopwe need to consider both data hazard and control hazard
문제에서 주어진 'adjusting displacement(변위/오프셋 조정)'이라는 힌트가 이 퍼즐을 푸는 가장 중요한 열쇠입니다
1. 원본 코드의 문제점 (해저드 분석)
먼저 현재 코드가 겪고 있는 두 가지 큰 병목 현상을 찾아야 합니다.
-
Load-Use Hazard: LD R1 직후에 R1을 재료로 쓰는 ADD R3가 오기 때문에 무조건 1사이클 스톨이 발생합니다.
-
Control Hazard: BNEZ의 결과가 EX 단계의 끝에서야 나옵니다. 즉, 결과를 기다리는 동안 파이프라인에는 2사이클의 페널티(지연 슬롯)가 발생합니다.
2. 마법의 스케줄링 (해결 과정)
Step 1: Load-Use 스톨 채우기 & 변위 보정 (Adjusting Displacement)
LD와 ADD 사이의 빈칸 1개를 채우기 위해 밑에 있는 명령어를 끌어올려야 합니다.
-
ADD R4, R4, #10을 끌어올리면 원래 옛날 R4 값을 써야 했던 ADD R3 연산이 망가집니다. (불가능)
-
따라서 독립적인 SUB R2, R2, #4를 LD 바로 밑으로 끌어올립니다.
-
변위 보정(핵심!): R2 값이 원래 순서보다 4만큼 일찍 작아졌습니다. (예: 원래 R2가 100이었다면 96으로 미리 줄어듦). 기존에 160번지(100+60)에 저장하던 ST R6, 60(R2)가 똑같은 160번지에 저장되려면, 줄어든 R2(96)에 맞춰 오프셋을 60에서 64로 늘려주어야 합니다!
Step 2: 분기 페널티(Branch Penalty) 가리기
EX 단계에서 결과가 나오므로, 분기문 뒤에는 2칸의 빈 공간(Delay Slots)이 생깁니다. 하드웨어가 억지로 거품을 넣기 전에, 어차피 실행했어야 할 명령어인 ADD R4와 앞서 변위를 보정한 ST R6를 BNEZ 밑으로 과감하게 내려버립니다.
- 최종 최적화 코드 (Optimized Code)
위의 논리를 바탕으로 완벽하게 재배치된 코드입니다
Loop: LD R1, 50(R2) // Load data into R1
SUB R2, R2, 4 // Moved up to hide Load-Use stall. R2 is updated early!
ADD R3, R4, R1 // R1 is ready, no stall here
MUL R6, R1, R3 // Calculate R6
BNEZ R2, Loop // Branch. Outcome evaluated at the end of EX
ST R6, 64(R2) // Delay slot 1: Offset adjusted (60+4=64) due to early SUB
ADD R4, R4, 10 // Delay slot 2: Maintains its original order relative to ST