Tomasulo's Algorithm의 핵심 철학
가장 중요한 차이점은 Dynamic Register Renaming(동적 레지스터 이름 변경)을 하드웨어 레벨에서 구현했다는 점입니다.
-
Eliminates WAR & WAW hazards without stalling: 스코어보딩에서는 앞사람이 다 읽을 때까지, 혹은 다 쓸 때까지 파이프라인 전체를 멈추고 기다려야(Stall) 했습니다. 하지만 Tomasulo는 레지스터 이름을 내부적으로 바꿔치기(Renaming)하여, 진짜 데이터 의존성(True Data Dependence, RAW)이 아닌 가짜 의존성(Name Dependence)인 WAR와 WAW를 완벽하게 제거합니다.
-
명령어들은 멈추지 않고 계속 Issue 단계로 진입할 수 있습니다.
핵심 하드웨어 컴포넌트 분석 (다이어그램 매칭)
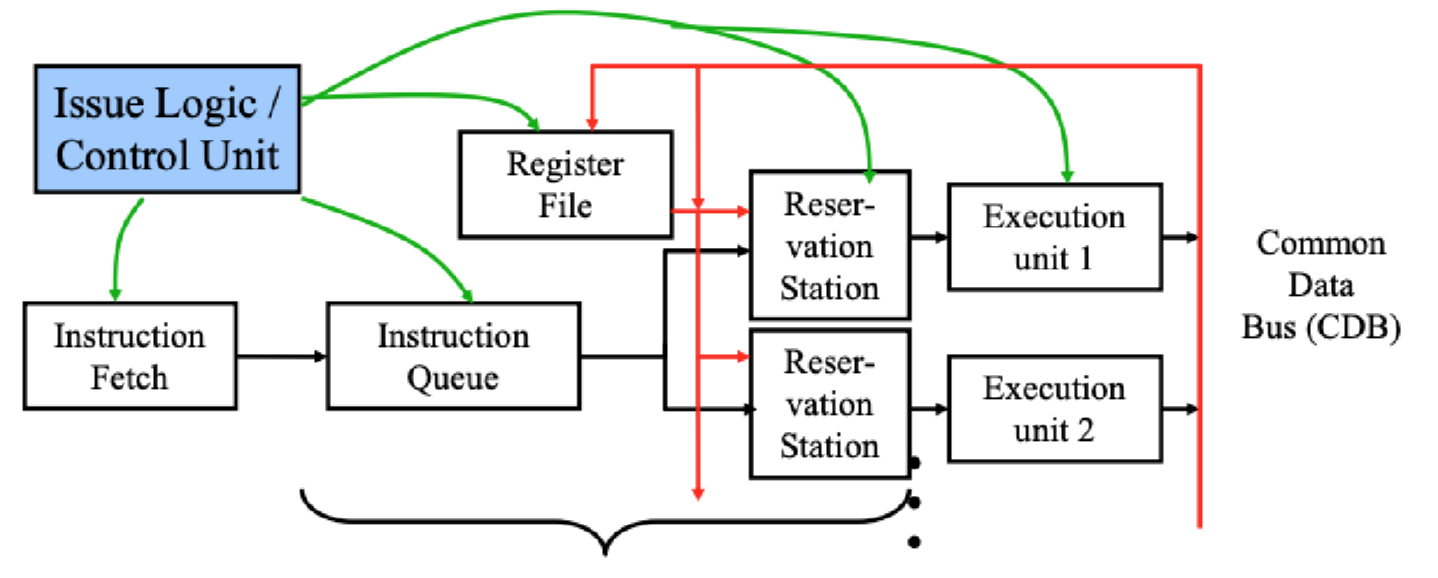
A. Reservation Stations (RS)
-
역할: Execution unit(연산기) 바로 앞에 달려 있는 대기실(Buffer)입니다.
-
특징: 명령어가 Issue 되면 Register File이 아니라 이 RS로 들어갑니다. 만약 재료(Operand)가 준비되어 있으면 바로 RS에 값을 복사해 두고, 준비되어 있지 않다면 "누가 이 재료를 만들어줄 것인가(Tag)"를 적어놓고 기다립니다.
-
Renaming의 실체: 이 RS 자체가 임시 레지스터 역할을 합니다. 즉, 목적지 레지스터(Destination Register)로 향해야 할 값들이 RS의 이름(Tag)으로 매핑되면서 Dynamic Register Renaming이 완성됩니다.
B. Common Data Bus (CDB)
-
다이어그램의 굵은 빨간색 선입니다.
-
역할: 연산이 끝난 결과를 Register File뿐만 아니라, 그 값을 애타게 기다리고 있는 모든 Reservation Stations로 직접 쏴줍니다 (Broadcast).
-
특징: 스코어보딩에서는 반드시 Register File에 값을 쓰고 나서 다음 명령어가 그걸 읽어가야 했습니다. 하지만 CDB를 통하면 Direct forwarding (Bypass)이 가능해져서, RAW 해저드로 인한 지연(Penalty)이 획기적으로 줄어듭니다.
C. Distributed Hazard Detection
-
스코어보드는 하나의 거대한 중앙 통제소(Issue Logic)가 모든 장부를 관리했습니다.
-
Tomasulo는 Distributed(분산된) 방식을 씁니다. 각 RS가 CDB를 계속 쳐다보고 있다가(Snooping), 자기가 기다리던 Tag가 적힌 데이터가 지나가면 알아서 낚아채서 연산을 시작합니다. 각 연산기(Functional Unit)가 스스로 해저드를 관리하는 독립적인 형태입니다.
Simple FPU using Tomasulo’s Algorithm
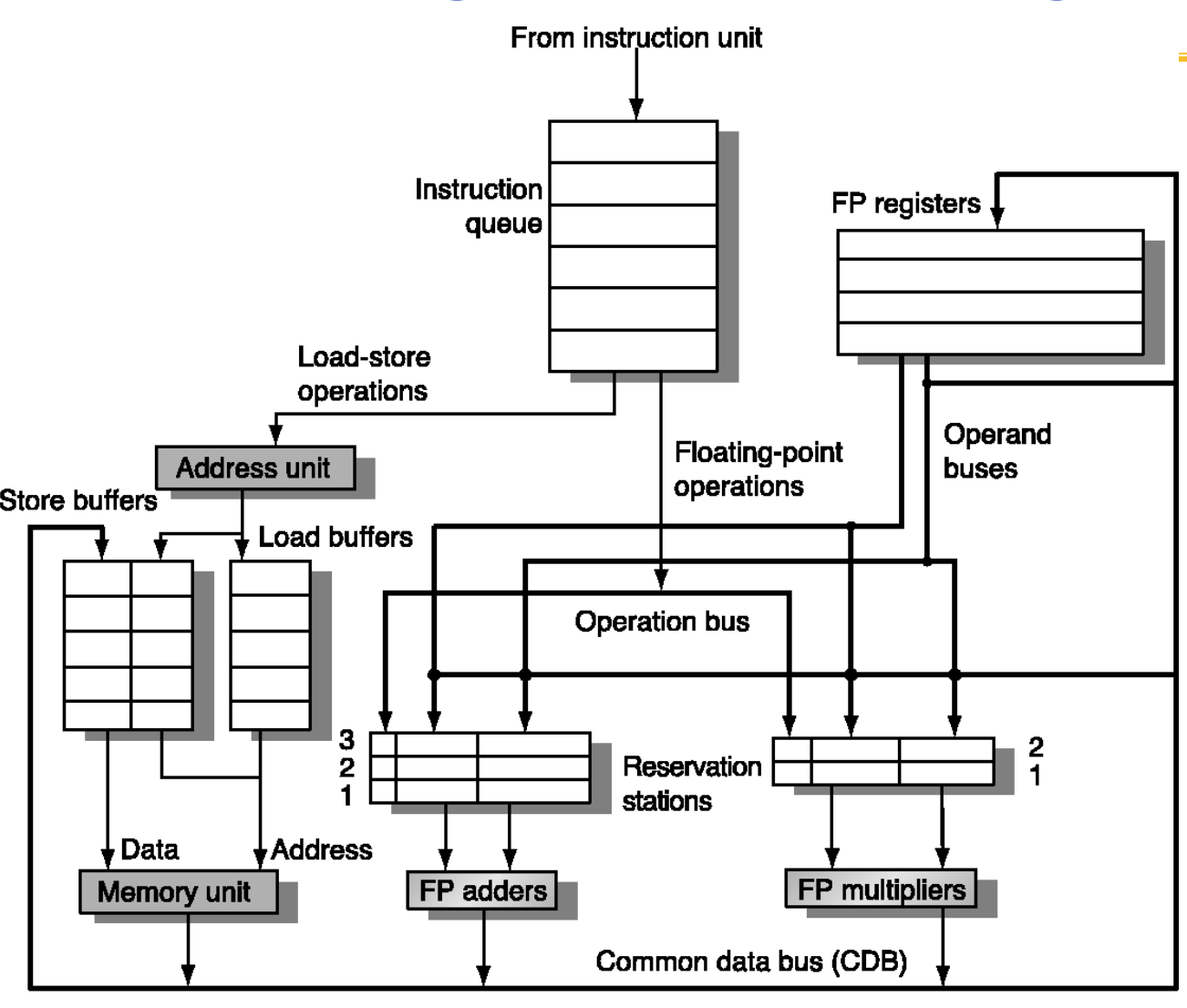
서론: Load-Store Queue는 무시해라!
교수님이 처음 시작할 때 "Left part(왼쪽 부분)는 보지 마라"라고 하셨죠? 다이어그램 왼쪽의 Address unit과 Store/Load buffers 부분은 메모리 최적화를 위한 큐(Queue)인데, 원리 이해가 목표인 이 수업에서는 복잡하니까 과감히 생략(just leave it there)하겠다고 하신 겁니다. 우리는 철저히 오른쪽의 Reservation Stations와 Execution Units만 보면 됩니다.
1단계: Issue (명령어 발행 & 레지스터 이름 바꾸기)
Tomasulo에서 가장 복잡하고 중요한 단계입니다. 교수님이 "Issue in-order"라고 강조하셨듯, 이 단계는 무조건 줄을 서서 순서대로 들어갑니다.
-
동작 1: 빈자리 찾기 (Structural Hazard 체크)
명령어가 들어오면, 자기가 필요한 연산기(예: FP Adder) 앞에 있는 대기실인 Reservation Station (RS)에 빈자리(Slot)가 있는지 확인합니다. 빈자리가 없으면 들어가지 못하고 멈춥니다(Stall). -
동작 2: Register Renaming (핵심!)
빈자리가 있다면, 그 명령어의 '결과를 저장할 목적지 레지스터(Destination Register)'의 이름을 아예 '방금 배정받은 RS의 이름'으로 바꿔버립니다. (예: F4 레지스터 대신 Add1이라는 RS 이름을 씁니다.) 이렇게 하면 WAW, WAR 해저드가 완벽하게 사라집니다. -
동작 3: 재료 챙기기 (Read Operands 통합)
스코어보드에는 Read operands라는 단계가 따로 있었죠? Tomasulo는 그게 없습니다! * Issue 단계에서 만약 재료(Source Operand)가 이미 완성되어 Register File에 있다면, 그 값(Value) 자체를 RS의 Vj, Vk 칸에 바로 복사해 옵니다.
만약 재료가 아직 누군가 만들고 있는 중이라면, 그 재료를 만들 RS의 이름(Tag)을 Qj, Qk 칸에 적어두고 기다립니다.
2단계: Execute (연산 실행)
이 단계부터는 순서에 상관없이(Out-of-order) 각자 알아서 뜁니다.
- 동작: 무한 대기하다가 조건 맞으면 돌격!
RS 안에서 기다리던 명령어는, 자기에게 필요한 두 가지 재료(Operands)가 모두 준비될 때까지 기다립니다. (이것이 RAW 해저드를 해결하는 방법입니다.) 재료가 다 모이면, 즉시 연산기(Functional Unit)로 들어가서 덧셈, 곱셈 등 실제 계산을 시작합니다.
교수님 멘트 요약: "Execute out-of-order. Wait until operands are ready (RAW hazard)." (순서 상관없이 실행한다. 재료가 다 모일 때까지 기다린다.)
3단계: Write Result (결과 뿌리기 & Direct Forwarding)
연산기가 요리를 끝냈을 때, 결과를 어떻게 배달하는지가 스코어보딩과 완전히 다릅니다.
-
동작 1: Common Data Bus (CDB) 방송
연산이 끝나면 그 결과값을 CDB (Common Data Bus)라는 빨간색 고속도로에 쏩니다. -
동작 2: Register File 업데이트
해당 결과값을 기다리고 있던 원래 목적지 레지스터(Register File)에 값을 씁니다. -
동작 3: RS로 직접 배달 (Direct Forwarding)
이게 제일 중요합니다! 아까 Issue 단계에서 "앞사람이 요리 끝내길 기다리며 RS에 이름표(Tag)만 적어두고 대기하던 명령어들" 기억나시나요? CDB를 통해 결과값이 날아가면, 이 대기하던 RS들이 "어? 내가 찾던 값이다!" 하고 낚아채서 자기의 빈칸(Vj 또는 Vk)을 채웁니다. Register File을 거치지 않고 바로 쏴주기 때문에 엄청나게 빠릅니다.
교수님 멘트 요약: "Write the result to the register file AND the corresponding reservation station slot who is waiting for you via Common Data Bus." (CDB를 통해 레지스터 파일과 널 기다리던 RS에 동시에 결과를 써라.)
Tomasulo Algorithm Table
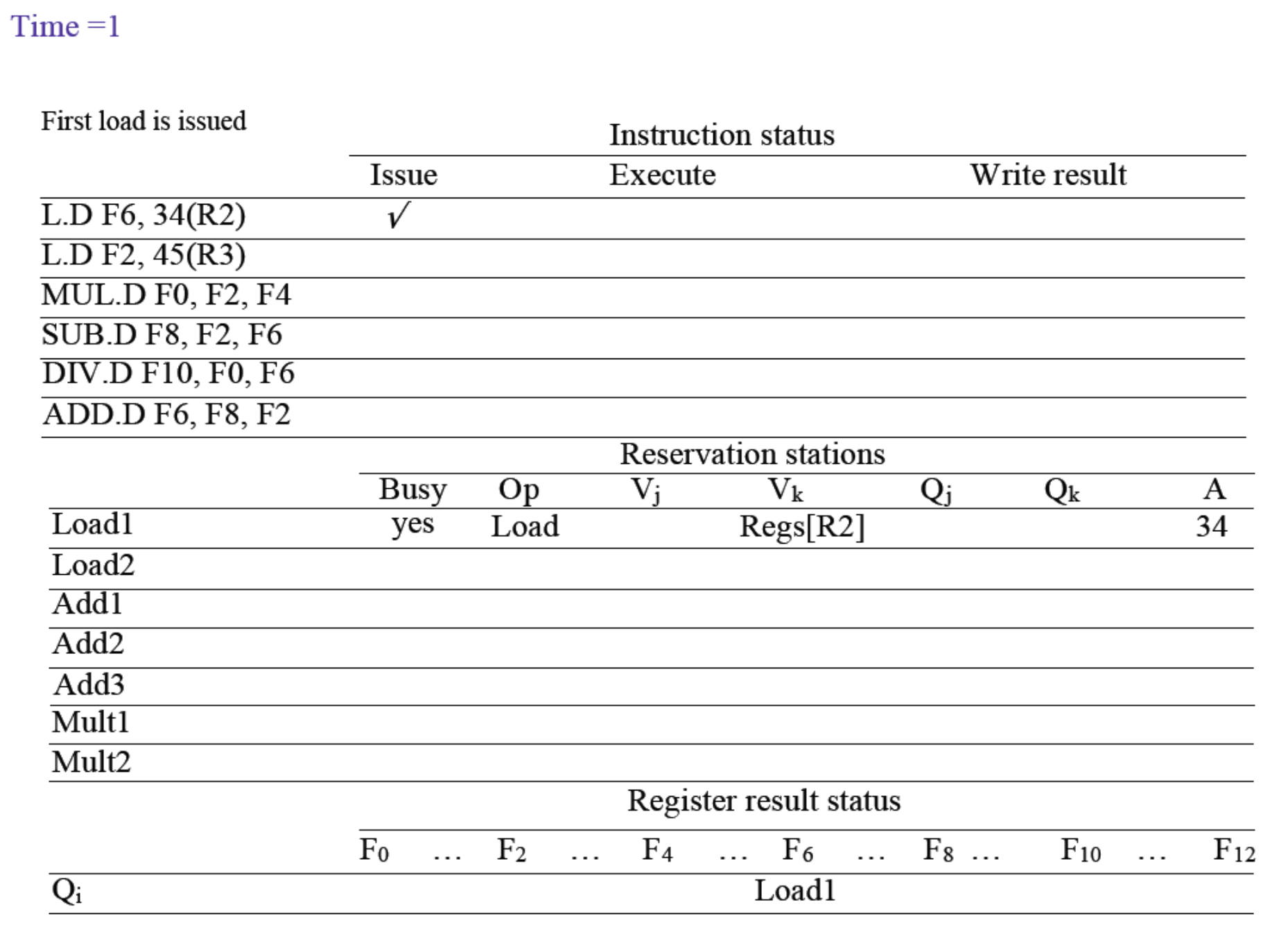
1. Instruction Status (명령어 상태)
현재 파이프라인에 들어온 명령어들이 3단계(Issue, Execute, Write result) 중 어디에 머물러 있는지를 추적하는 장부입니다. 스코어보딩과 달리 Read operands 단계가 없다는 점을 다시 한번 상기하시기 바랍니다.
2. Reservation Station Fields (RS 슬롯 내부 필드)
연산기 앞 대기실(RS)의 한 칸(Slot)이 어떤 정보들을 들고 있는지 보여줍니다. 여기가 Tomasulo 알고리즘의 심장부입니다.
-
Busy:
해당 RS 슬롯이 현재 사용 중인지(Occupied) 나타냅니다 (Yes/No). 명령어가 Issue 될 때 Yes가 되고, Write result를 마치고 퇴근할 때 No가 됩니다. -
Op (Operation):
수행해야 할 연산의 종류입니다 (예: ADD.D, MUL.D). -
Vj, Vk (Values of S1 & S2):
연산에 필요한 첫 번째, 두 번째 재료의 실제 값(Value)입니다.
명령어가 Issue 될 때 이미 Register File에 값이 완성되어 있거나, 대기하던 중 CDB를 통해 값을 전달받으면 이 칸에 그 값을 적습니다. -
Qj, Qk (Tags of the RS slots that will produce S1, S2):
- 아직 재료가 준비되지 않아서 기다려야 할 때, "도대체 누구(어떤 RS)한테서 그 값을 받아야 하는가"를 뜻하는 이름표(Tag)입니다.
- 시험장 핵심 함정: V 칸과 Q 칸은 절대 동시에 채워지지 않습니다. 재료를 이미 구했으면 V에 값이 들어가고 Q는 비워둡니다. 반대로 누군가를 기다려야 하면 V는 비워두고 Q에 그 사람의 이름표(예: Add1, Mult2)를 적습니다.
-
A: A(Address) 필드는 Issue 단계에서는 명령어의 Offset을 보관하고, Execute 단계에서는 계산이 완료된 Effective Address를 담아두는 전용 버퍼 역할을 합니다.
Issue 단계 (현재 사진):
해당 명령어의 Immediate 값 (여기서는 메모리 오프셋인 34)이 먼저 A 필드에 기록됩니다. 동시에 Base Register인 R2의 값은 Vk 필드(Regs[R2])로 읽어옵니다.
Execute 단계 (이후 동작):
실제 데이터를 가져오려면 정확한 메모리 주소를 계산해야 합니다. 이후 실행 단계의 첫 번째 스텝(Address Calculation)에서, 하드웨어는 Vk에 들어있는 R2의 실제 값과 A에 임시로 저장해둔 34를 더합니다. 연산이 완료되면 그 결과인 최종 Effective Address(유효 주소)를 다시 A 필드에 덮어쓰게 됩니다.
3. Register Result Status (레지스터 결과 상태)
이 장부는 Register Renaming (동적 레지스터 이름 변경)이 물리적으로 기록되는 곳입니다.
Qi:
-
현재 각 레지스터(예: F0, F2, F4...)에 "가장 마지막으로 값을 덮어쓸 예정인 RS의 이름표"를 적어두는 필드입니다.
-
예를 들어 ADD.D F2, F4, F6 명령어가 Add1이라는 RS 슬롯에 Issue 되었다면, Register Result Status 테이블의 F2 레지스터 밑에 Add1이라고 덮어씁니다.
-
이후에 들어오는 명령어들이 F2를 재료로 쓰려고 하면, Register File을 보는 게 아니라 이 장부를 보고 "아, 내가 필요한 값은 Add1이 만들어줄 예정이구나" 하고 자기 RS의 Qj나 Qk 칸에 Add1이라고 적고 기다리게 됩니다
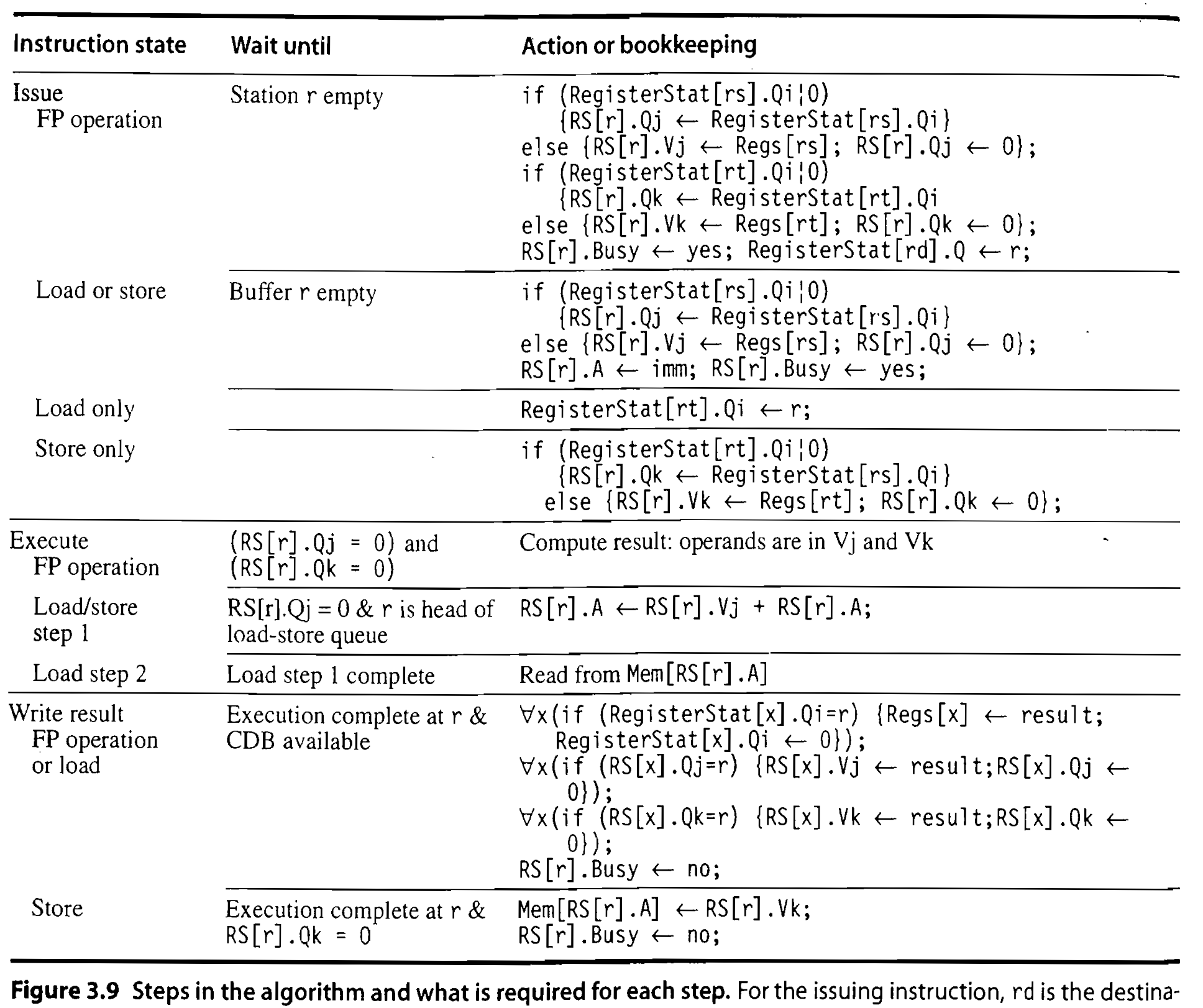
1. 근본적인 질문: 왜 레지스터에 쓸 때 '확인'을 해야 할까?
Figure 3.9의 Write result 칸을 보면, 결과를 레지스터에 쓰기 전에 if (RegisterStat[x].Qi = r) 이라는 확인 절차를 거칩니다.
교수님의 질문은 이것입니다. "계산을 다 끝냈으면 그냥 목적지 레지스터(예: F4)에 확 써버리면 되지, 왜 굳이 장부를 확인해서 내 이름표(Qi)가 아직 남아있는지 체크해야 할까?"
2. 교수님의 예시 완벽 시뮬레이션 (L.D vs MUL.D)
교수님이 드신 예시를 따라가 봅시다. 똑같이 F4 레지스터를 목적지로 하는 명령어 두 개가 연속으로 들어왔습니다.
앞선 명령어: L.D F4, ... (결괏값으로 10을 만들어낼 예정)
뒤따른 명령어: MUL.D F4, ... (결괏값으로 20을 만들어낼 예정)
[Issue 단계의 장부 덮어쓰기]
- L.D가 먼저 Issue 됩니다. 레지스터 장부(RegisterStat)의 F4 칸에 "이제 F4는 내가(Load1) 만들어 줄 거야"라고 이름표를 붙입니다.
- 바로 다음 사이클에 MUL.D가 Issue 됩니다. 얘도 목적지가 F4네요! 그러면 F4 칸의 이름표는 Load1에서 Mult1로 덮어쓰기(Overwrite) 됩니다.
[Write Result 단계의 딜레마]
- 시간이 흘러 앞선 L.D 명령어가 계산(10)을 끝내고 드디어 F4 레지스터에 10을 쓰러 왔습니다.
- 이때 장부를 확인해보니, F4 칸의 이름표(Qi)는 자기 이름(Load1)이 아니라 Mult1이 적혀있습니다.
- 내 이름표가 아니므로(RegisterStat[x].Qi != r), L.D는 F4 레지스터에 10을 쓰지 못하고 버려야 합니다 (throw this value).
3. 만약 확인 안 하고 그냥 써버리면 생기는 대참사
교수님이 "만약 그냥 10을 써버리면 어떻게 되느냐"고 역질문하셨죠.
- L.D 뒤에 엄청 늦게 들어온 어떤 뺄셈 명령어(SUB.D Fx, F4, ...)가 있다고 칩시다.
- 이 뺄셈 명령어는 당연히 가장 최신 명령어인 MUL.D가 만든 최신 값(20)을 읽고 싶어 합니다.
- 그런데 눈치 없는 L.D가 뒤늦게 레지스터에 10을 덮어써 버리면, 뺄셈 명령어는 20 대신 10을 읽어가서 계산을 완전히 망치게 됩니다.
- 이것이 바로 WAW 해저드입니다! Tomasulo는 장부 이름표(Qi)를 확인하는 로직 하나로 이 대참사를 완벽하게 막아낸 것입니다.
4. 찐막 의문: 그럼 10을 기다리던 애들은 어떡해요?
여기서 분명히 의문이 드실 겁니다. "아니, 레지스터에 안 쓰고 10을 버려버리면, 곱셈 말고 진짜로 Load1의 10을 애타게 기다리던 애들은 굶어 죽나요?"
바로 여기서 Figure 3.9 코드의 진가가 드러납니다.
레지스터(Regs[x])에 값을 쓰는 코드 바로 밑에, RSx 장부를 뒤져서 값을 쏴주는 코드가 따로 두 줄 더 있죠?
- L.D는 F4 레지스터 업데이트는 깔끔하게 포기합니다.
- 대신, Common Data Bus (CDB)라는 고속도로를 통해 대기실(RS) 전체에 "나 Load1인데, 값 10 나왔어!" 라고 동네방네 방송을 때립니다 (notify the other pending instructions).
- 그러면 Load1을 기다리며 대기실에 죽치고 있던 명령어들이 그 10을 쏙쏙 주워가서 연산을 시작합니다.
최종 요약
"목적지 레지스터에 값을 쓸 때 장부를 확인하는 이유는, 내 뒤에 똑같은 레지스터를 쓰는 명령어(WAW)가 들어와서 내 이름표를 덮어썼는지 확인하기 위해서입니다. 덮어써졌다면 레지스터 업데이트는 포기하고 버리되, 나를 기다리는 RS 슬롯들에게는 CDB를 통해 값을 정상적으로 전달해 줍니다."
Tomasulo's Algorithm Pseudo-code
1. Issue (명령어 발행)
명령어가 파이프라인에 진입하여 Reservation Station (RS)을 할당받고, Register Renaming을 수행하는 단계입니다. 이 단계는 반드시 In-order로 진행됩니다.
A. FP operation (부동소수점 연산)
Wait until: Station r empty
- 필요한 연산기(Functional Unit)의 RS에 빈자리(r)가 있을 때까지 대기합니다. (자리가 없으면 Structural Hazard로 Stall 발생)
Action (Operand rs 확인): if (RegisterStat[rs].Qi != 0)
- 첫 번째 Source Operand(rs)를 만들어줄 앞선 명령어가 아직 계산 중인지 Register 장부(RegisterStat)를 확인합니다.
- 계산 중이라면(!= 0), 해당 RS의 Tag를 내 RS의 Qj에 적어두고 대기합니다. (RS[r].Qj <- RegisterStat[rs].Qi)
- 계산이 끝나 값이 이미 있다면(else), 실제 Value를 Vj에 복사하고 Qj는 0으로 비웁니다.
Action (Operand rt 확인):
- 두 번째 Source Operand(rt)에 대해서도 위와 완전히 동일한 논리로 Qk 또는 Vk를 채웁니다.
Action (Register Renaming): RegisterStat[rd].Qi <- r
- 명령어의 Destination Register(rd) 장부에 현재 할당받은 RS의 이름(r)을 덮어씁니다. 이것이 WAW, WAR 해저드를 제거하는 Register Renaming의 핵심입니다.
B. Load or store (메모리 접근 연산)
- Wait until: Buffer r empty (Load/Store 버퍼에 빈자리가 있을 때)
- Action (Base Register 확인): Base Register(rs)의 값을 가져오기 위해 FP 연산과 똑같이 RegisterStat을 확인하여 Qj 또는 Vj를 채웁니다.
- Action (Address 계산 준비): 명령어에 포함된 Immediate 값(Offset)을 RS[r].A에 저장합니다.
C. Load only / Store only 세부 동작
- Load only: 메모리에서 값을 읽어와 Destination Register(rt)에 써야 하므로, RegisterStat[rt].Qi에 자신의 버퍼 이름(r)을 덮어써서 Register Renaming을 수행합니다.
- Store only: 레지스터의 값을 메모리에 써야 합니다. 저장할 데이터가 들어있는 Register(rt)가 준비되었는지 확인하여, 대기해야 하면 Qk에 Tag를 적고, 준비되었다면 Vk에 Value를 가져옵니다.
2. Execute (실행)
재료가 모두 준비되면 실제 연산을 수행하는 단계입니다. 이 단계부터는 Out-of-order로 진행됩니다.
A. FP operation
Wait until: (RS[r].Qj = 0) and (RS[r].Qk = 0)
- Qj와 Qk가 모두 0이라는 것은 기다릴 Tag가 없고 Vj와 Vk에 실제 Value가 모두 준비되었다는 뜻입니다. (RAW 해저드 해결)
Action: Vj와 Vk의 값을 가지고 계산(Compute result)을 수행합니다.
B. Load / Store step 1 (Effective Address 계산)
Wait until: RS[r].Qj = 0 & r is head of load-store queue
- Base Register(rs)의 값이 준비되어야 하고(Qj = 0), 동시에 메모리 접근 순서가 꼬이지 않도록 Queue의 가장 앞(head)에 있어야 합니다.
Action: 준비된 Base Address(RS[r].Vj)와 Issue 단계에서 저장해둔 Offset(RS[r].A)을 더해서 최종 Effective Address를 계산하고, 다시 RS[r].A에 덮어씁니다.
C. Load step 2 (메모리 읽기)
- Wait until: Step 1(주소 계산)이 완료되어야 합니다.
- Action: 계산된 주소(RS[r].A)를 이용해 메모리에서 실제 Data를 읽어옵니다.
3. Write result (결과 쓰기)
계산된 결과를 Common Data Bus (CDB)를 통해 레지스터와 대기 중인 RS에 Broadcast하는 단계입니다.
A. FP operation or load
-
Wait until: Execution이 완료되고, CDB를 다른 명령어가 쓰고 있지 않아야(CDB available) 합니다.
-
Action (Register File 업데이트): (if (RegisterStat[x].Qi = r))
- 모든 Register(x)를 뒤져서, 자신을 기다리고 있는 Register가 있는지 확인합니다. 내 이름표(r)가 온전히 남아있다면 값을 쓰고 Qi를 0으로 초기화합니다. 만약 다른 명령어가 덮어써서 이름표가 다르다면(WAW 해저드), 값 쓰기를 포기합니다. -> Elemininate data dependence
-
Action (Direct Forwarding): (if (RS[x].Qj = r)) 및 Qk 확인 -> data broadcasting
- 모든 RS(x)를 뒤져서, 나를 기다리며 Qj나 Qk에 내 이름표(r)를 적어둔 명령어가 있는지 확인합니다.
- 발견하면 해당 RS의 Vj 또는 Vk에 결과 Value를 직접 꽂아주고, Qj/Qk를 0으로 비워줍니다.
-
Action (RS 비우기): 자신의 RS 사용이 끝났으므로 RS[r].Busy <- no로 변경하여 자리를 반납합니다.
B. Store
- Wait until: Execution(주소 계산)이 완료되고, 메모리에 저장할 실제 데이터(RS[r].Qk = 0)가 준비되어야 합니다.
- Action: RS[r].A 주소의 메모리에 RS[r].Vk 값을 씁니다. (Store는 메모리에 쓰는 명령어이므로 CDB를 사용하지 않습니다.) 이후 RS를 반납합니다.
