Boyer Moore 문자열 매칭 알고리즘
가장 많이 쓰이는 문자열 매칭 알고리즘 (Exact String Matching)들은
- Boyer-Moore
- Best for matching 'long search patterns'
- Pre-Analyzing 필요
- O(mn) - KMP (Knuth-Morris-Pratt)
- Best for matching 'small vocab'
- Pre-Analyzing 필요
- O(n) - Aho-Corasick
- Best for matching multiple occation of the 'same pattern'
- Analyze patterns only once, not for every search
- O(N+L+Z) - Z-Algoritms
- O(m+n)
등이 있다.
이중 Boyer-Moore Algorithm을 implement 해 보았다.
Boyer-Moore Heuristics
Boyer-Moore은 두 가지 heuristic의 조합으로 이루어져 있다.
- Bad Character Heuristic
- Good Suffic Heuristic
Bad Character Heuristic
Bad Character Heuristic works under two simple rules.
Once the text and the pattern we desire to match are aligned, each letter are compared from right most towards the left.
At the instance of a mismatch, the pattern may,
-
Shift right to match the mismatched character of the text with a character located further left
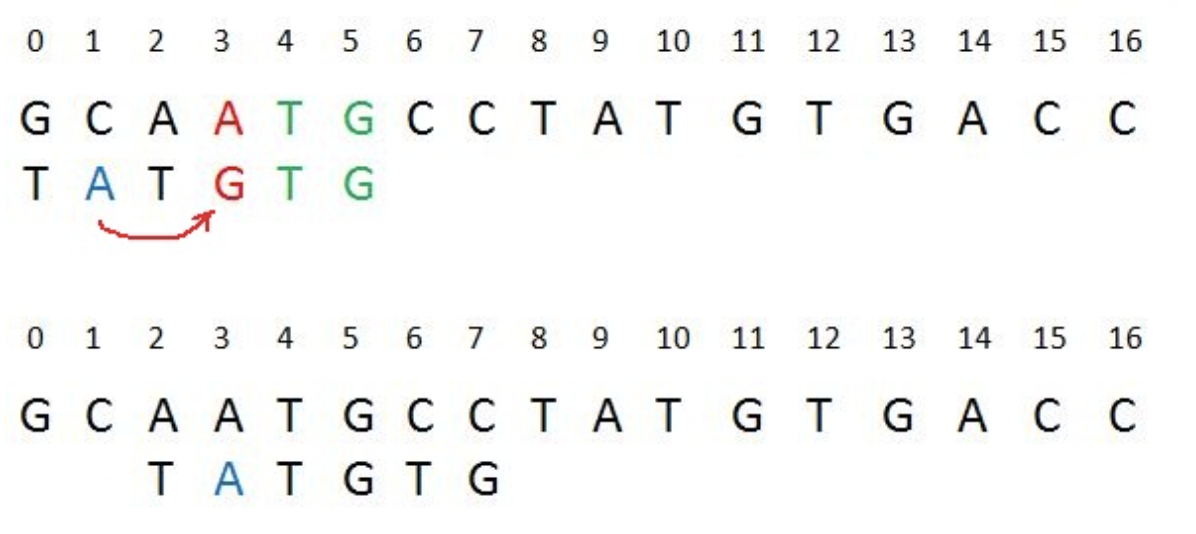
-
Or, move pass the mismatching character (if the pattern does not contain the mismatched character)
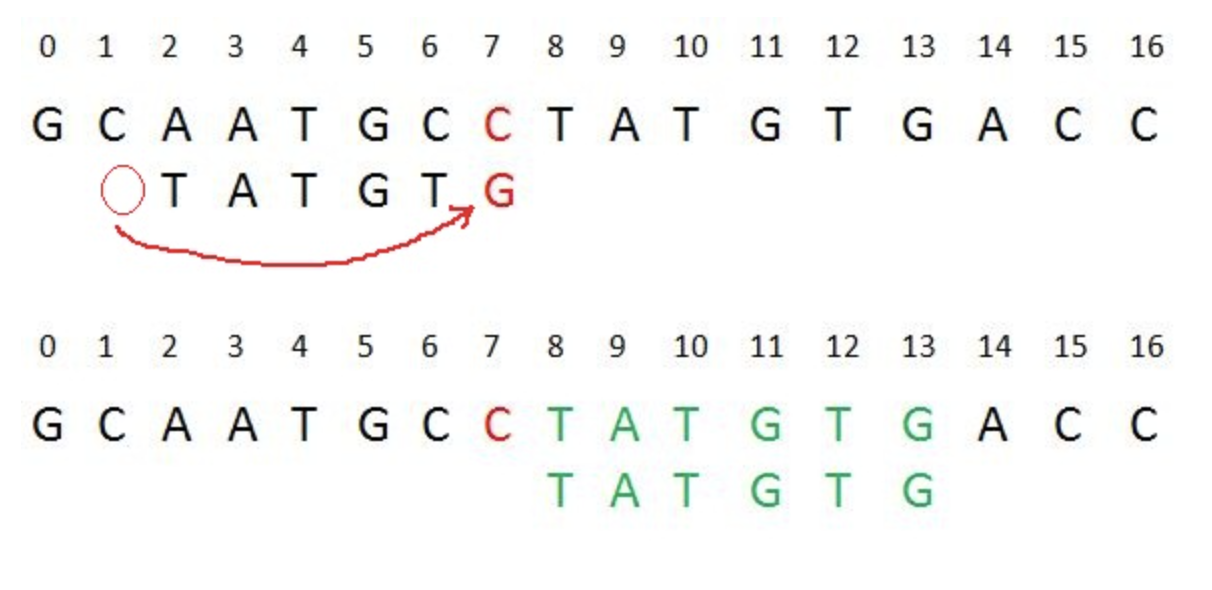
Good Suffix Heuristic
Good Suffix Heuristic, unlike bad character heuristic, works with the concept of prefix and suffix for determining the pattern's shift.
Again comparing pattern and text from right most location,
- Once a mismatch happens, if there exists an another instance of 'matched substring' (right of the mismatched character) within the pattern, the pattern shifts right to match the substring.
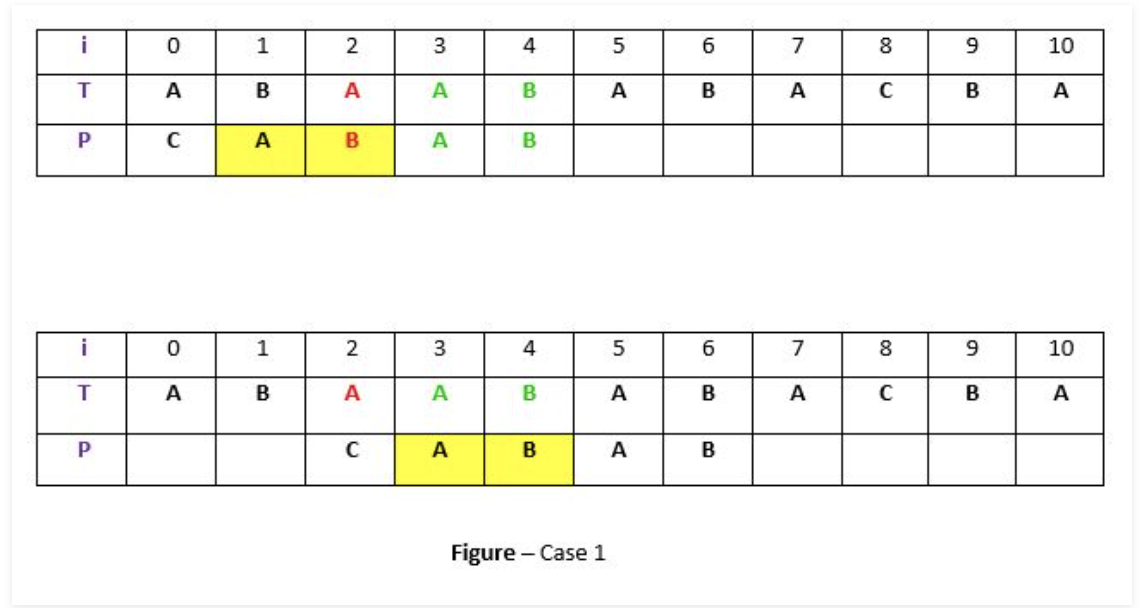
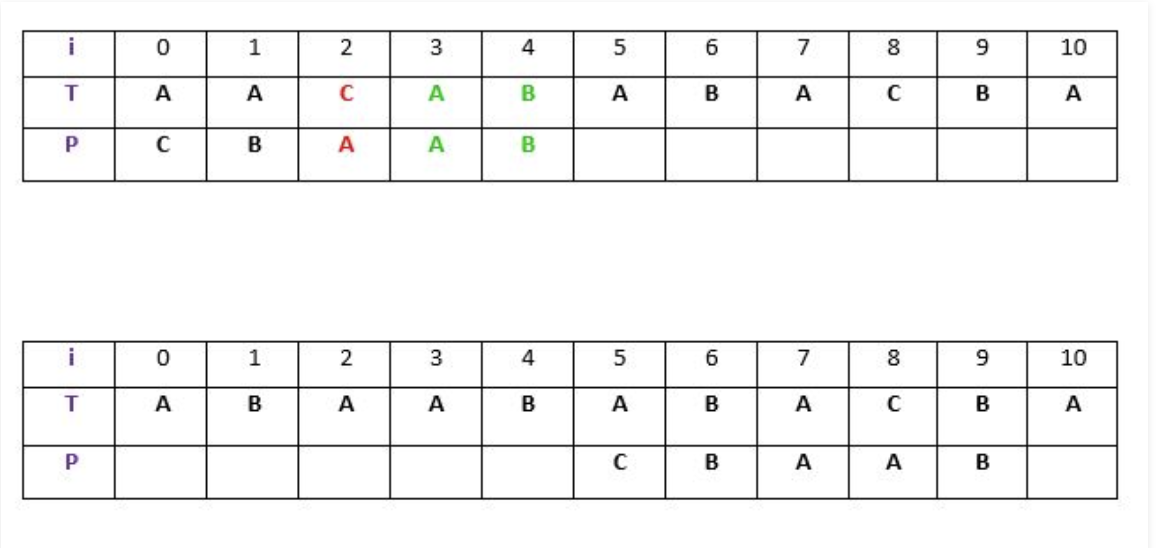
In the example, another instance of the matched substring (A B) exists within the pattern
- Second rule applied is to match the 'suffix' of the matched substring with a 'prefix' of the pattern.
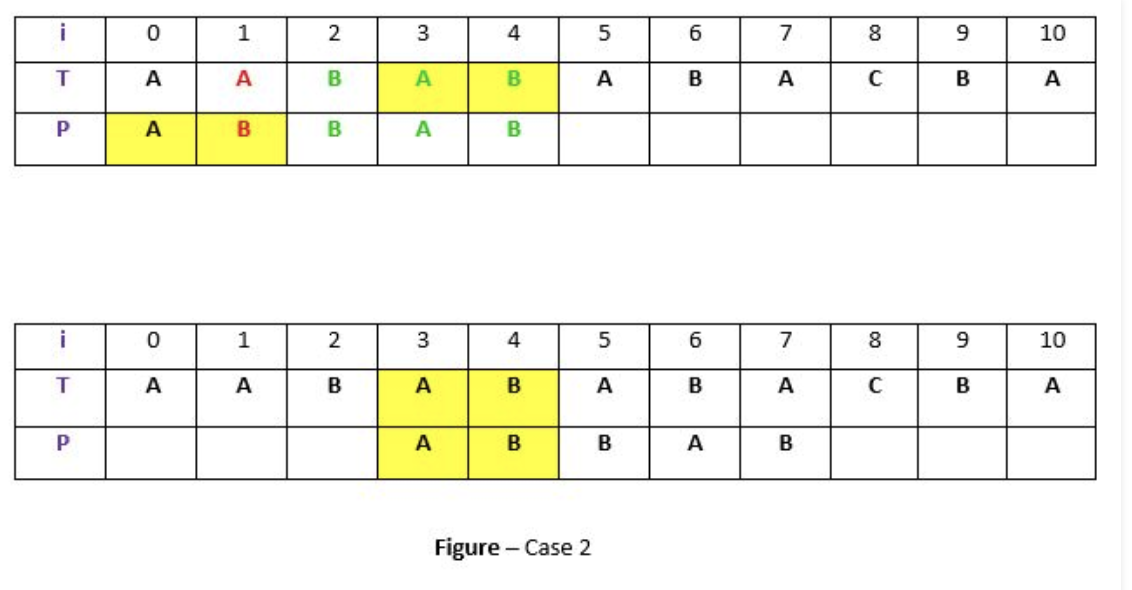
The second rule covers for instances when the 'matched substring' from previous rule, may be too long to find a second appearance within the pattern.
- Unlike in the bad suffix rule where the pattern skips over the mismatched character if no alternate may be found, the good suffix rule skips over the entire 'compared' substring of the text if the previous two rules does not work.
Preprocessing
To use bad character and good suffix heuristics, both algorithm requires pre-defined arrays which marks the range of jumping for each instances of the mismatch.
Bad Character

The pre-processed array for bad character defines a numerical value for the pattern to jump
(if there are more than one occation of a character, the right most occation of the character is the standard)
Good Suffix
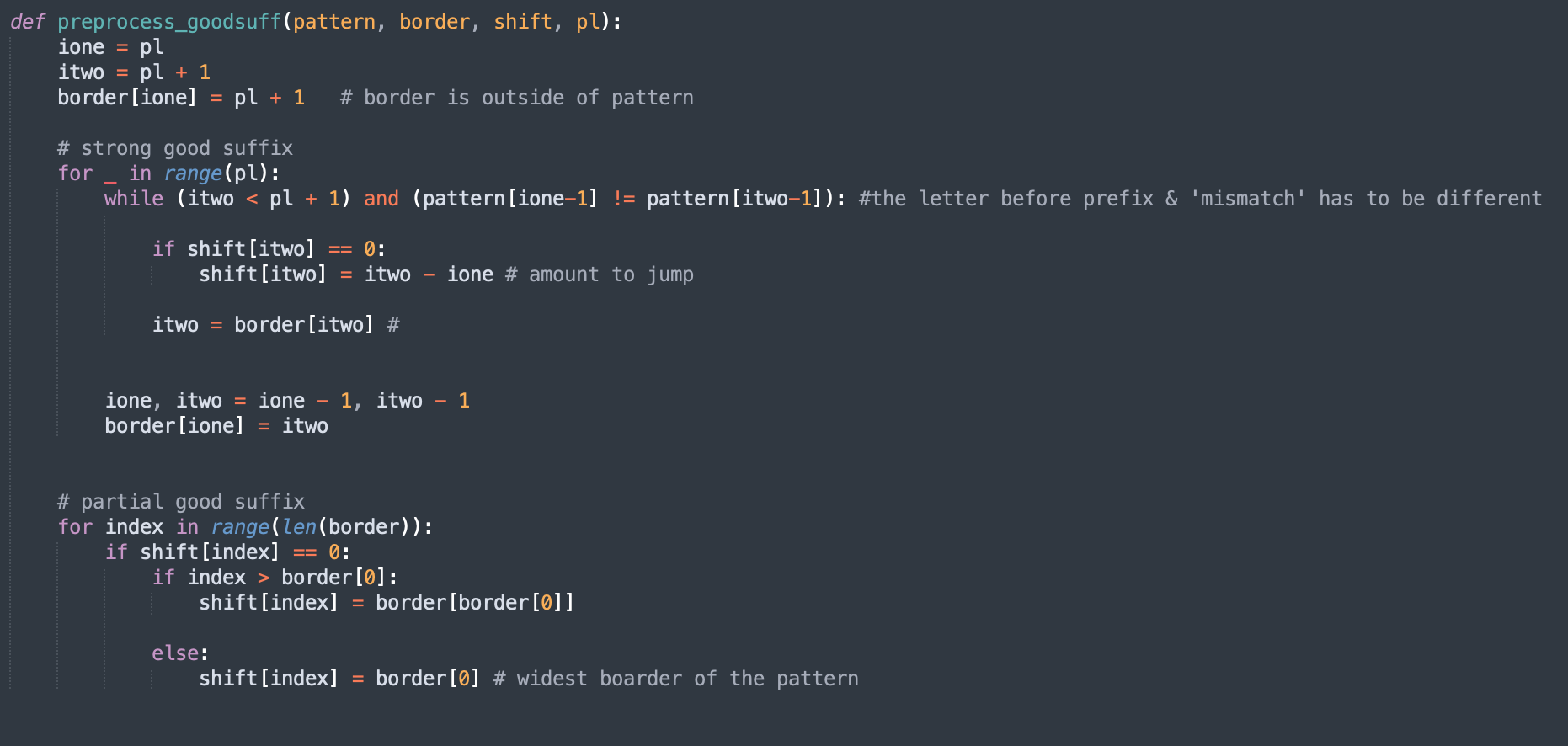
The preprocessing of good suffix requires two arrays (border and shift)
The each value of shift[i] indicates the value of which the pattern must shift when a mismatch happens at i-1
The border array contains the starting index of the widest border of each position of the pattern.
Main Algorithm
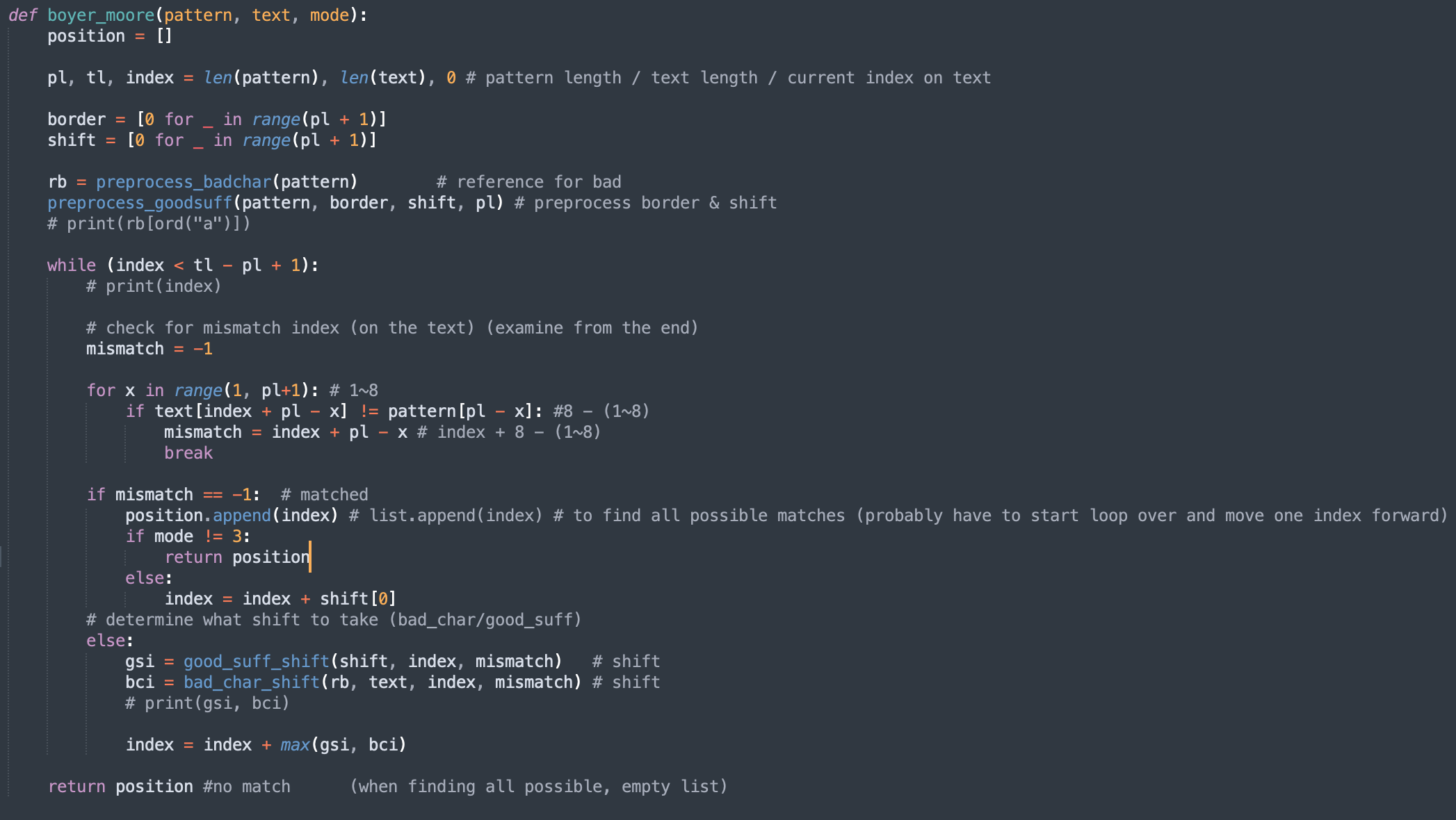
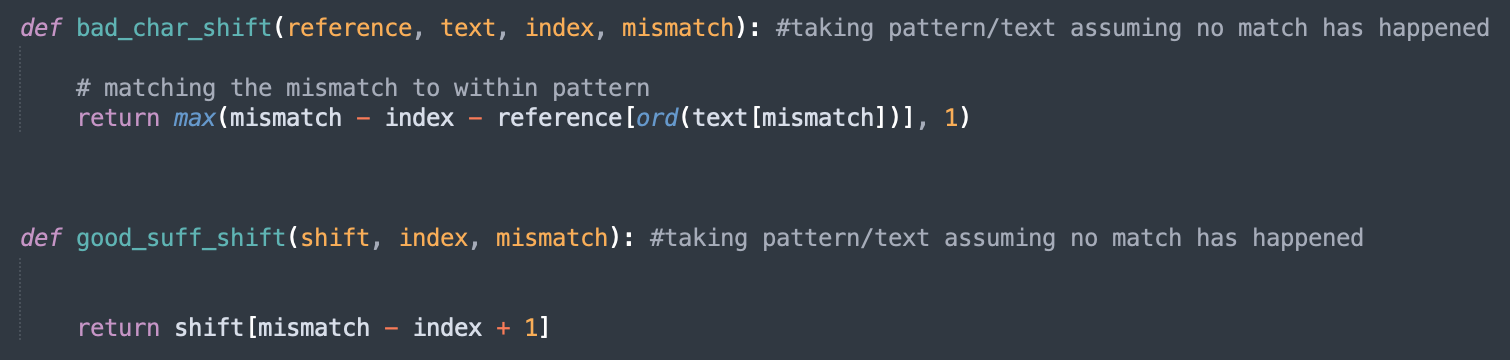
Both the good suffix heuristic and bad character heuristic was used for the algorithm
(Uses both heuristic and apply the biggest shift possible)
Input/Output
Input
- Array 1: list of patterns to be matched
- Array 2: list of texts to be matched

Mode 1
returns boolean (Yes/No) value if each pattern exists within the given string

Mode 2
returns the first index of each pattern's appearance within each given string

Mode 3
returns all index of each pattern's appearance within each given string

Reference
[1] https://www.geeksforgeeks.org/boyer-moore-algorithm-for-pattern-searching/
[2] https://www.geeksforgeeks.org/boyer-moore-algorithm-good-suffix-heuristic/
