Korean Hate Speech Detection
Project Overview
Pretrained된 모델을 Fine-Tuning해 Hate Speech Classification (한국어로 된 혐오 / 공격적인 댓글)을 분류하는 모델을 학습시키려고 합니다
Pretrained Model
KcElectra-base
KcElectra는 네이버 뉴스 댓글과 대댓글을 수집해 tokenizer와 electra 모델을 pretrain한 모델로, 짧은 길이의 댓글을 분류하고, 신조어/비속어를 많이 포함한 Korean Hate Speech Detection 데이터 셋에 가장 적합하다고 판단되어 사용하였습니다.
Dataset
Kaggle에 올라온 Korean-Hate-Speech-Detection 데이터 셋을 사용하였습니다.
https://www.kaggle.com/competitions/korean-hate-speech-detection/

데이터 셋은 기본적으로
- Comments: 댓글 원본
- Contain_gender_bias: T/F
- Bias: gender / others / none
- Hate: hate / offensive / none
으로 구성되어 있으며, 이중 (Comments, Hate) Column만 사용합니다.
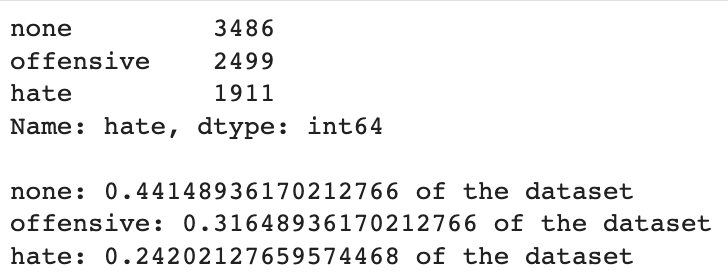
Since the 'minority' of the dataset (hate) is above 20% of the total data count (13.3%) off from being a fully balanced dataset, I will proceed with current data distribution.
Preprocessing
Stemming/stopword removal will not be done as it is not effective in hate speech detection.
Only,
- Chinese Characters
- Special Characters other
- URL
- HTML
will be removed
Hate Label:
- 0 [1,0,0]: None
- 1 [0,1,0]: Offensive
- 2 [0,0,1]: Hate
Processed Output Example

Model

Training Details
- Optimizer: AdamW
- Loss Function: CrossEntropyLoss
Hyper Parameters
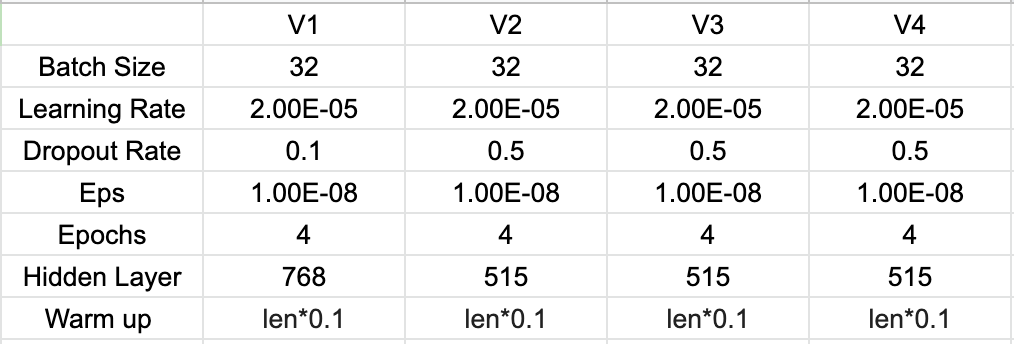
- V3: When preprocessing the data, only erased html/url while keeping all special characters and punctuations (with v2 settings)
- V4: KcElectra-base -> "monologg/koelectra-base-v3-discriminator"
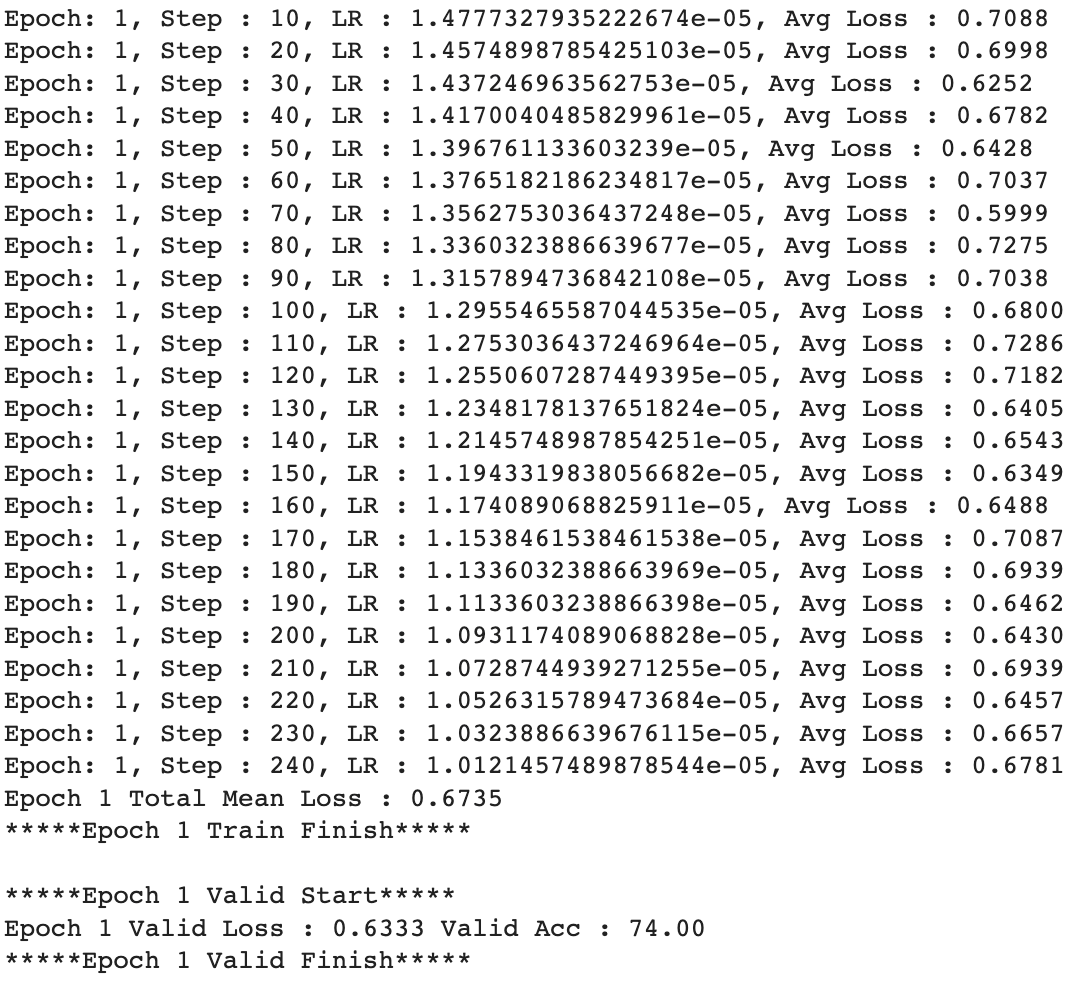
Best Model
Out of all models, V2 epoch 1 had the highest validation accuracy of 74%
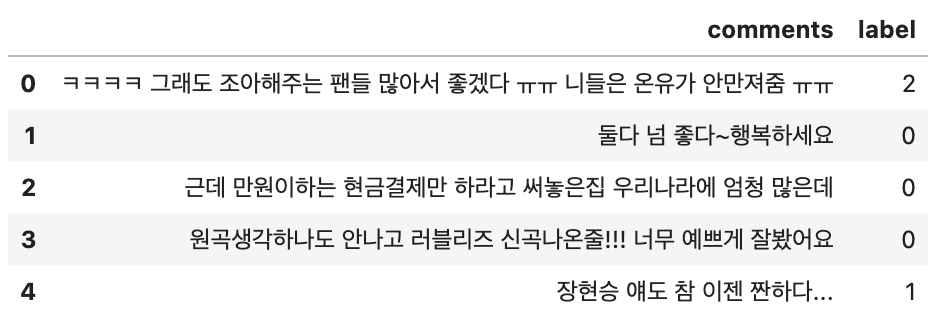
Sample Prediction Output
Kaggle Competition Submission
주어진 Test Set의 데이터 셋은 문장에 대해 Label이 표시되지 않은 데이터를 포함하고 있어 체점이 제출 형식으로 이루어 집니다.
제출시 Kaggle Competition 이 부여하는 점수가 어떻게 측정되는지 확실하지 않으나 0.66421점으로 표시되었습니다.
Reference
Pretrained model used: beomi/KcELECTRA-base
- @misc{lee2021kcelectra, author = {Junbum Lee}, title = {KcELECTRA: Korean comments ELECTRA}, year = {2021}, publisher = {GitHub}, journal = {GitHub repository}, howpublished = {\url{https://github.com/Beomi/KcELECTRA}} }
Dataset Used:
- Korean Hate Speech Dataset Train Data: labeled train.tsv
- Validation Data: dev.tsv
- Test Data: test.no_label.tsv @ https://github.com/kocohub/korean-hate-speech.git
