ANOVA with OLS
1. OLS 통계 검정?
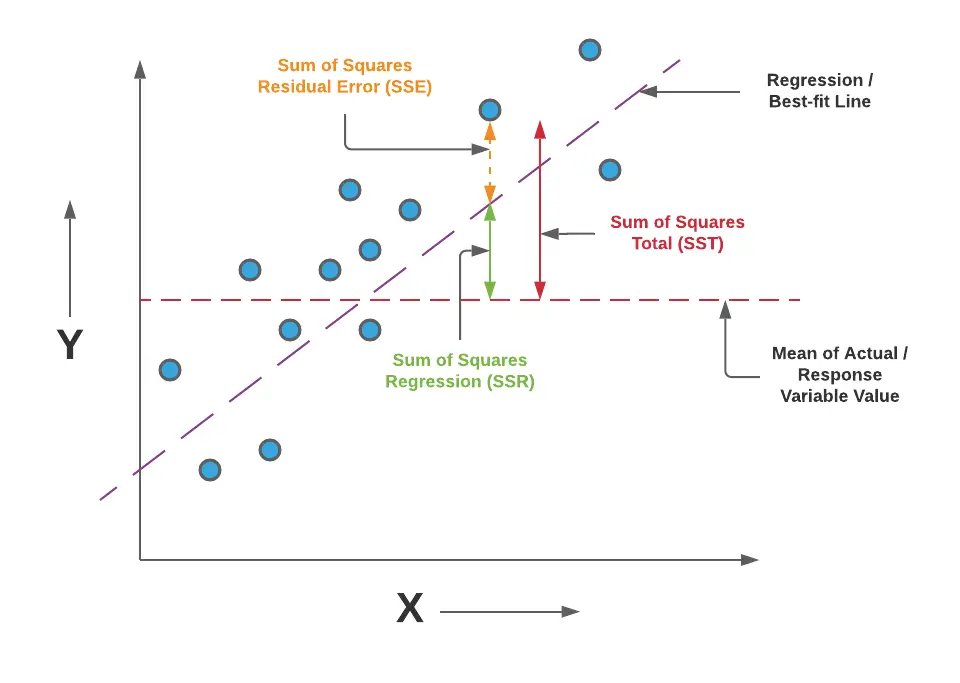
- 회귀식에서 결정된 기울기()가 우연히 발생하지 않았는지 판단하는 검정
- 우연히 발생햇다는 건
- 가설 설정
- H_0:
- H_1: (독립변수 X와 종속변수 Y 사이에는 아무런 선형 관계가 없다. 즉, 지금 나온 기울기는 우연히 발생한 것)
- LinearModel에 fit시키기 위해 Categorical Data는 Dummy변수화 시켜줌 (선형 종속 관계를 없애기 위해 DropFirst해줌)
from statsmodels.formula.api import ols
model = ols('Score ~ C(Method) + Hours', data=df).fit()
print(model.summary())ANOVA
-
SST = SSR + SSE
-
설명 가능한 에러 / 우연히 발생할 수 있는 에러(평균)
-
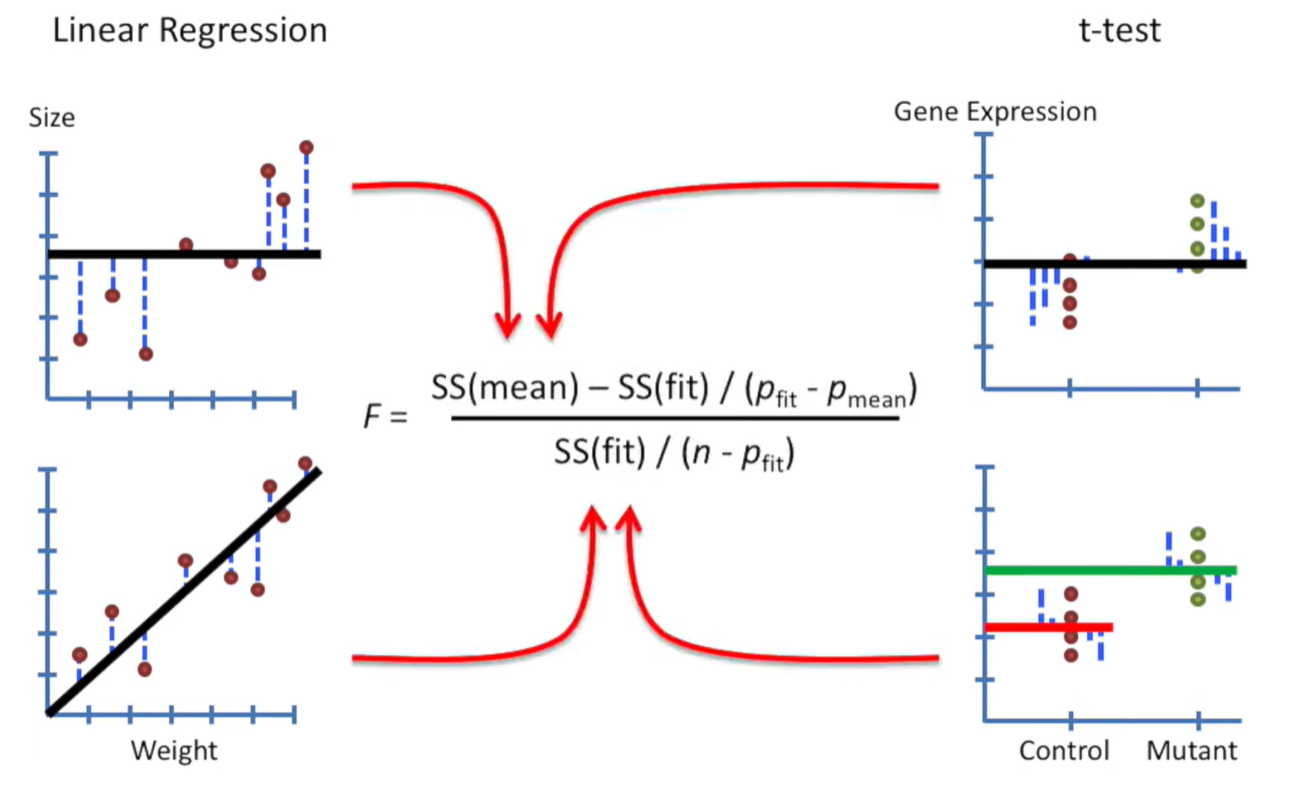
회귀분석 기울기의 테스트는 t-test
-
회귀계수 / SE (df=1)
-
R^2는 모델의 분산 설명력
-
모델이 설명하고 남은 오차는 ramdom해야함 -> 잔차도로 확인했을때 특정 패턴이 보이면 R^2는 무의미해짐 (전제가 맞지 않음)


AngDDo