DBSCAN (Density-based spatial clustering of applications with noise)
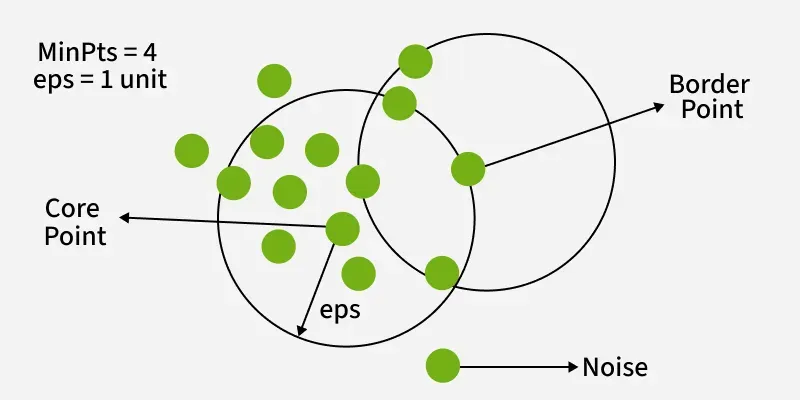
아래 두 핵심 파라미터
(Epsilon): 핵심 포인트(Core Point) 판정 기준으로 탐색 반경을 의미
(Minimum Points): 내에 모여 있어야 하는 최소 데이터 포인트의 개수
포인트 종류
| 포인트 종류 | 분류 조건 | 역할 및 특징 |
|---|---|---|
| 핵심 점 (Core Point) | 자신의 반경 내에 개 이상의 데이터가 존재 | 군집의 중심 역할을 하며, 서로 연결되어 군집을 확장해 나감 |
| 경계 점 (Border Point) | 자신의 반경 내 데이터가 미만이지만, 다른 핵심 점의 반경 내에 속함 | 주로 군집의 외곽선을 형성함 |
| 노이즈 (Noise Point) | 핵심 점도 아니고 경계 점도 아님 (밀도가 낮은 지역에 고립) | 분석 과정에서 이상치(Outlier)로 취급되어 배제될 수 있음 |
코드
import numpy as np
def custom_dbscan(X, eps, min_pts):
"""
DBSCAN 알고리즘의 동작 과정을 보여주는 커스텀 함수입니다.
:param X: 2차원 데이터 배열 (numpy array)
:param eps: 탐색 반경 (\epsilon)
:param min_pts: 핵심 점이 되기 위한 최소 이웃 수 (MinPts)
:return: 각 데이터 포인트의 군집 라벨 리스트
"""
n_points = X.shape[0]
# 라벨 초기화: 0은 '방문하지 않음(Unvisited)'을 의미합니다.
# 노이즈는 -1, 정상 군집은 1, 2, 3... 으로 부여할 예정입니다.
labels = np.zeros(n_points)
cluster_id = 0 # 현재 군집 번호
def get_neighbors(point_idx):
"""특정 점의 반경 eps 내에 있는 모든 이웃 점들의 인덱스를 반환합니다."""
distances = np.linalg.norm(X - X[point_idx], axis=1) # 유클리디안 거리 계산
return np.where(distances <= eps)[0]
# 1단계: 모든 데이터 포인트를 순회하며 탐색합니다.
for i in range(n_points):
# 이미 방문한 점(라벨이 0이 아님)은 건너뜁니다.
if labels[i] != 0:
continue
# 2단계: 이웃 탐색
neighbors = get_neighbors(i)
# 3단계: 핵심 점 판별
# 이웃의 수가 min_pts보다 적으면 노이즈(-1)로 임시 분류합니다.
if len(neighbors) < min_pts:
labels[i] = -1
continue
# 이웃의 수가 충분하다면 새로운 군집을 시작합니다.
cluster_id += 1
labels[i] = cluster_id
# 4단계: 군집 확장 (Cluster Expansion)
# 현재 점의 이웃들을 대기열(리스트)로 만들고 하나씩 확인합니다.
# numpy 배열을 리스트로 변환하여 동적으로 요소를 추가할 수 있게 합니다.
neighbors_list = list(neighbors)
j = 0
# BFS로 이웃 순회
while j < len(neighbors_list):
neighbor_idx = neighbors_list[j]
# 노이즈(-1)로 분류되었던 점이 핵심 점의 이웃으로 발견되면,
# 이 점은 경계 점(Border Point)이 되므로 현재 군집에 포함시킵니다.
if labels[neighbor_idx] == -1:
labels[neighbor_idx] = cluster_id
# 아직 방문하지 않은 점(0)이라면 현재 군집에 포함시키고, 이웃을 탐색합니다.
elif labels[neighbor_idx] == 0:
labels[neighbor_idx] = cluster_id
# 확장 중인 이웃 점의 이웃들도 확인합니다.
new_neighbors = get_neighbors(neighbor_idx)
# 이 이웃 점 역시 핵심 점 조건을 만족한다면,
# 그 점의 이웃들도 대기열에 추가하여 군집을 연쇄적으로 확장합니다.
if len(new_neighbors) >= min_pts:
# 중복을 피하기 위해 대기열에 없는 점만 추가할 수도 있지만,
# 단순화를 위해 전체를 이어 붙입니다. (이미 방문된 점은 위 조건문에서 걸러짐)
for n in new_neighbors:
if n not in neighbors_list:
neighbors_list.append(n)
j += 1
return labels
# 사용 예시 (가상의 데이터 적용)
# X_data = np.array([[1, 2], [2, 2], [2, 3], [8, 7], [8, 8], [25, 80]])
# labels = custom_dbscan(X_data, eps=3, min_pts=2)
# print("할당된 군집 라벨:", labels)
AngDDo