LDA
- Supervised learning으로 집단을 분류가 잘되는 방향으로 projection하여 차원을 축소
- pca: 분산을 최대화 하는 축으로 projection
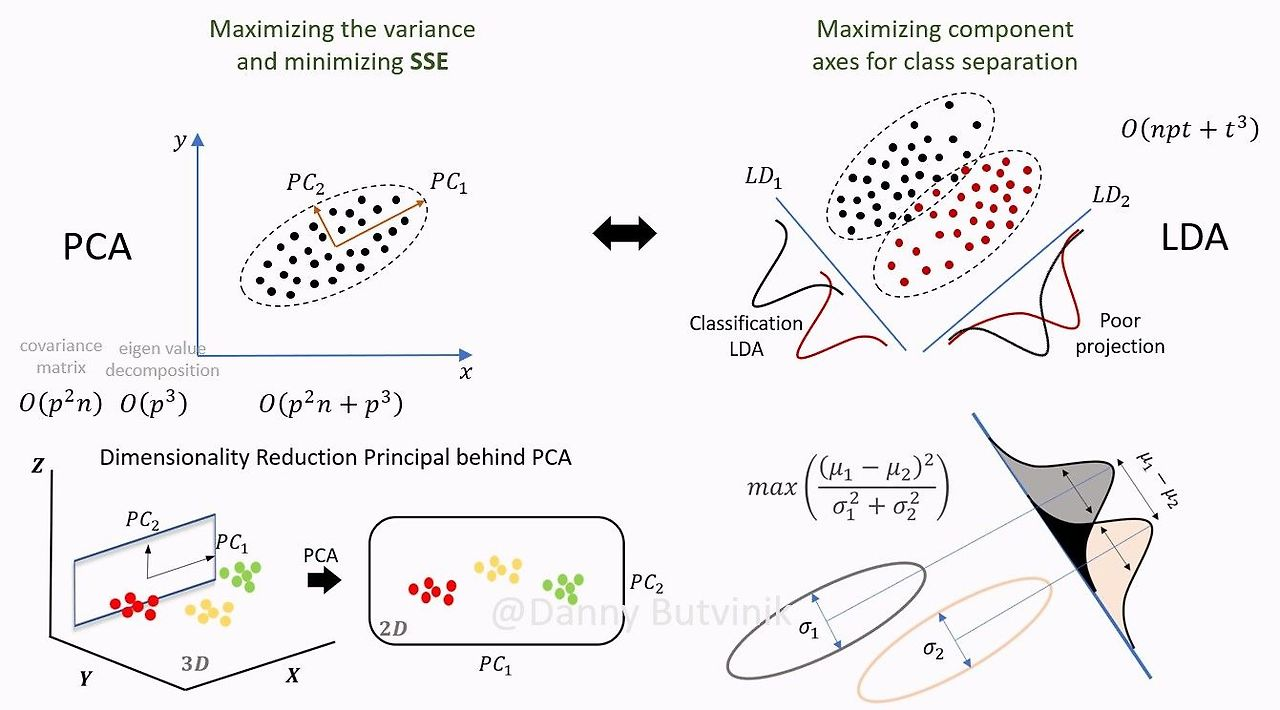
해석
- 데이터 를 새로운 축 에 투영(내적)한 값은
- 그룹간/ 그룹내의 투영된 값들의 분산을 계산
- 분자 ():각 그룹의 중심들이 떨어진 정도
- 분모 (): 같은 그룹끼리 뭉친 정도
코드
import numpy as np
# 데이터 형태 파악 (특성 4개)
n_features = X.shape[1]
class_labels = np.unique(y)
# Step 1: 클래스별 평균 벡터와 전체 평균 계산
mean_vectors = []
for cl in class_labels:
mean_vectors.append(np.mean(X[y == cl], axis=0))
overall_mean = np.mean(X, axis=0)
# Step 2: 클래스 내 산포 행렬 (S_W) 계산
S_W = np.zeros((n_features, n_features))
for cl, mv in zip(class_labels, mean_vectors):
class_sc_mat = np.zeros((n_features, n_features))
for row in X[y == cl]:
row, mv = row.reshape(n_features, 1), mv.reshape(n_features, 1)
class_sc_mat += (row - mv).dot((row - mv).T)
S_W += class_sc_mat
# Step 3: 클래스 간 산포 행렬 (S_B) 계산
S_B = np.zeros((n_features, n_features))
for i, mean_vec in enumerate(mean_vectors):
n = X[y == i, :].shape[0]
mean_vec = mean_vec.reshape(n_features, 1)
overall_mean_vec = overall_mean.reshape(n_features, 1)
S_B += n * (mean_vec - overall_mean_vec).dot((mean_vec - overall_mean_vec).T)
# Step 4: 고유값 분해 (S_W 역행렬과 S_B의 내적)
# 수학 공식: S_W^-1 * S_B
eig_vals, eig_vecs = np.linalg.eig(np.linalg.inv(S_W).dot(S_B))
# 고유값이 큰 순서대로 정렬 (설명력이 가장 높은 축을 찾기 위함)
eig_pairs = [(np.abs(eig_vals[i]), eig_vecs[:, i]) for i in range(len(eig_vals))]
eig_pairs = sorted(eig_pairs, key=lambda k: k[0], reverse=True)
# Step 5: 상위 2개의 고유벡터를 선택하여 변환 행렬 W 생성
W = np.hstack((eig_pairs[0][1].reshape(n_features, 1),
eig_pairs[1][1].reshape(n_features, 1)))
# 원래 데이터 X에 변환 행렬 W를 내적하여 데이터 투영
X_lda_manual = X.dot(W)
print("\n=== Numpy 수동 투영 결과 (W 행렬 적용) ===")
print(pd.DataFrame(X_lda_manual, columns=['LD1', 'LD2']).head())```
AngDDo