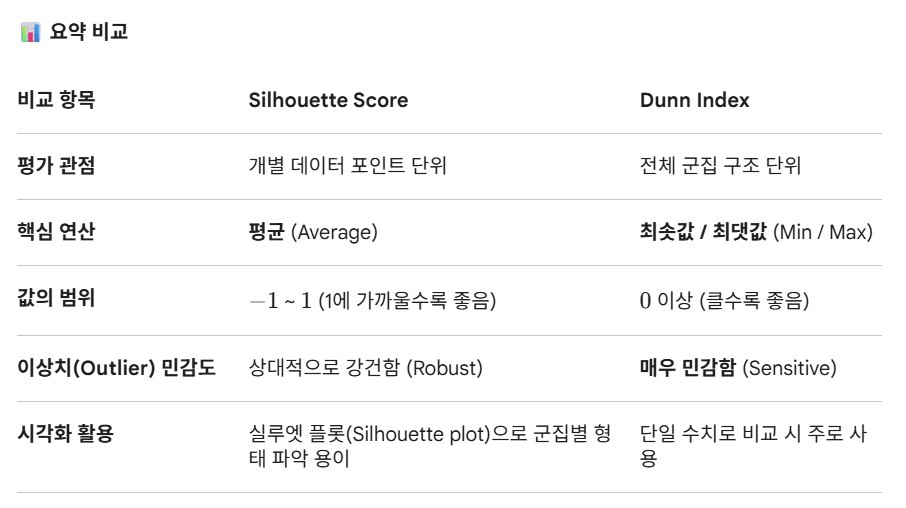
Shilhouette Score
1. Shilhouette Score
- Unsupervised-Clustering에서 군집이 얼마나 잘 묶였는지 평가하는 평가지표
- Dunn Index는 각각의 군집 구조를 단위로 대한 분리도를 측정
- 반면에 Shilhouette Score는 각각의 개별 데이터 포인트로 자신의 속한 군집과 얼마나 잘 결합, 얼마나 잘 분리되어 있는지를 거리의 평균으로 측정
- -1 ~ 1 사이의 값의 범위를 가지며 높을수록 좋음
- Dunn Index에 비해 이상치에 강건하여 Shilhouette Score로 많이 사용
2. 알고리즘
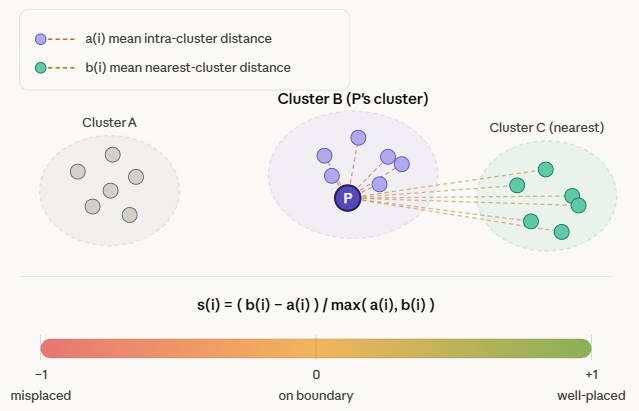
응집도
- 특정 데이터 포인터()가 얼마나 잘 뭉쳐 있는지 계산
- 가 속한 군집 내에 있는 모들 데이터 포인트들 사이의 거리를 계산하고 평균을 구함
분리도
- 데이터 포인트 가 다른 군집들과 얼마나 잘 떨어져 있는지를 계산
- 군집를 제외한 나머지 군집을 하나 선택 → 군집선택
- 데이터 와 군집에 속한 포인트들 사이의 거리 측정 및 평균구함
- 군집도 동일하기 구하고 , 중 작은 값을 선택
Shilhouette 계수 계산
- 모든 데이터 포인트에 대해서 $s(i)를 계산하여 평균냄
- 분자()는 직관적으로 0이면 이웃 군집과의 경계에 위치한 데이터 포인터라고 생각할 수 있음
- 정규화를 위해 로 나누어줌
코드
import pandas as pd
import numpy as np
# 임의의 데이터프레임 예시 (검증용)
# df = pd.DataFrame({'A': [...], 'B': [...], 'C': [...], 'LABEL': [...]})
X_COLS = ['A', 'B', 'C']
list_s = []
# 1. iterrows()로 수정 및 언패킹
for idx, data in df.iterrows():
x = data[X_COLS]
y = data['LABEL']
same_cluster_points = df.loc[df['LABEL'] == y, X_COLS].copy()
# 7. 클러스터 내 데이터가 자기 자신뿐인 경우 (분모 0 방지)
if same_cluster_points.shape[0] == 1:
list_s.append(0.0)
continue
# 2. .sum(axis=1) 추가
a = np.sum(np.sqrt(((same_cluster_points - x)**2).sum(axis=1))) / (same_cluster_points.shape[0] - 1)
b = 1e9
# 4. data['LABEL'] -> df['LABEL']로 수정
for label in df['LABEL'].unique():
if label != y:
# 5. X_COLS 컬럼만 가져오도록 수정
other_cluster_points = df.loc[df['LABEL'] == label, X_COLS].copy()
# 3. 타 클러스터 거리는 n-1이 아닌 n으로 나눔
dist = np.sum(np.sqrt(((other_cluster_points - x)**2).sum(axis=1))) / other_cluster_points.shape[0]
b = min(b, dist)
list_s.append((b - a) / max(a, b))
# 6. 리스트의 평균은 np.mean()으로 계산
final_silhouette_score = np.mean(list_s)
print(final_silhouette_score)

AngDDo