[230616]CAPE: Camera View Position Embedding for Multi-View 3D Object Detection
Object detection
Abstract
- 현재 queury based method의 문제: glboal 3D PE 를 이용해서 -> 이미지들과 3D space간 기하학적 상관관계를 유추한다는 점
- 이렇게 하면, camera extrinsics의 변화로 인한 view transformation을 학습하기 어렵다.
- CAPE(CAmera view Position Embedding)
- 기여 1: 3D PE를 global coordinate system에서 하지 말고,
local camera view coordinate에서 하자.- 이렇게 하면 3D PE가 camera extrinsic에 무관해진다.
- 기여 2: 아래 기법으로 3D object detection 성능을 높임. -> nuScenes dataset 기준 61.0% 의 NDS와 52.5%의 mAP 로, SOTA 성능을 냄.
- 지난 frame의 object queries를 이용하여 temporal modeling을 함.
- ego motion을 인코딩
- 기여 1: 3D PE를 global coordinate system에서 하지 말고,
Introduction
-
-
기존 방식 (
2D images -> 3D global space)- 직관적
- global space에서의 (
query embeddings와3D position-aware multi-view features의 interaction )은 성능을 하락시킨다. 그 이유는 아래 2가지와 같다. - 이유 1
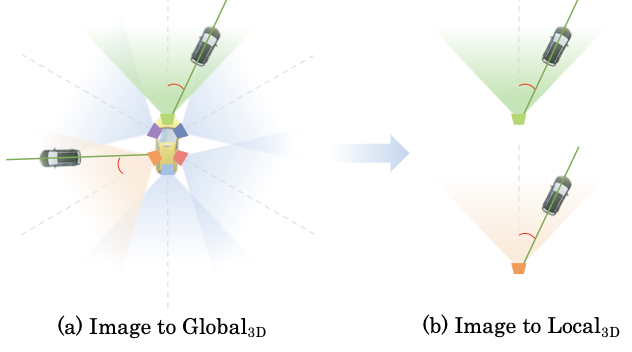
- 각 카메라 좌표계를 3D local space로 정의하면, view transformation은
2D image -> localtransformation과local-> globaltransformation을 결합시킨다. - 따라서 네트워크는 글로벌 시스템에서 3D 예측을 위해 고차원 임베딩 공간에서 다양한 카메라 extrinsic 파라미터를 구분해야 하지만, 로컬에서 글로벌로의 관계는 단순한 rigid 변환입니다.
- 각 카메라 좌표계를 3D local space로 정의하면, view transformation은
- 이유 2
2D 이미지에서 3D 로컬 공간으로의 변환에 대한 view-invarinat 특성>3D 글로벌 공간으로 직접 변환하는 것보다 학습하기 쉽다고 믿습니다.- 예를 들어, 두 개의 뷰에서 두 차량이 이미지 특징에서 유사한 모습을 가지더라도 네트워크는 Figure 2 (a)에서 보여지듯이 다른 뷰 변환을 학습해야 합니다.
-
-
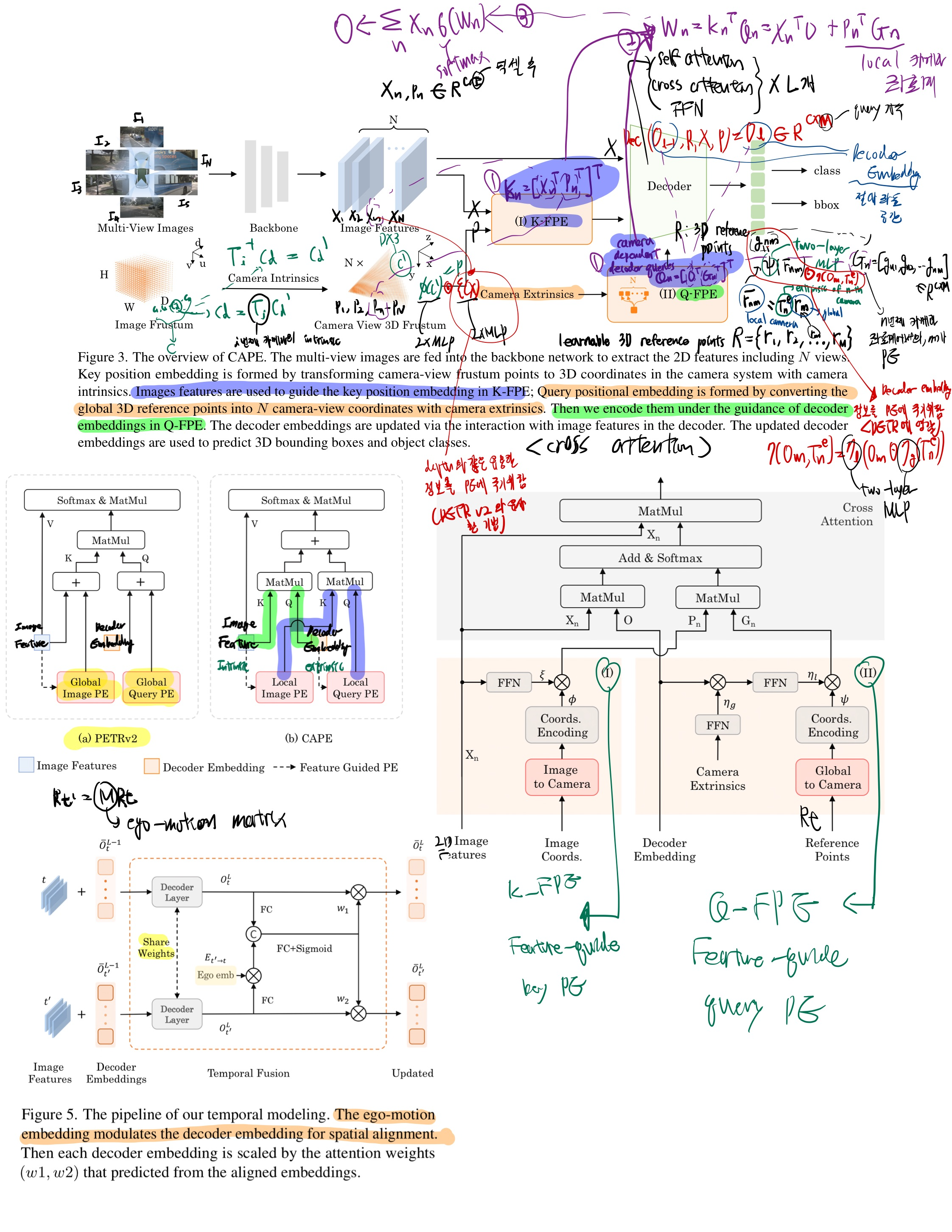
특히, key 3D PE(포지션 임베딩)에 대해서는, 카메라 intrinsic 파라미터만을 사용하여 카메라 시스템에서 카메라 원뿔을 3D 좌표로 변환한 다음, 간단한 MLP 레이어를 통해 인코딩합니다.
-
query 3D PE에 대해서는, 글로벌 공간에서 정의된 3D 기준점을 카메라 extrinsic 파라미터만을 사용하여 로컬 카메라 시스템으로 변환한 후, 간단한 MLP 레이어를 통해 인코딩합니다.
-
[25, 28]에서 영감을 받아 key와 qeury에 대해, 이미지 특징과 디코더 임베딩의 안내로 3D PE를 얻습니다.
-
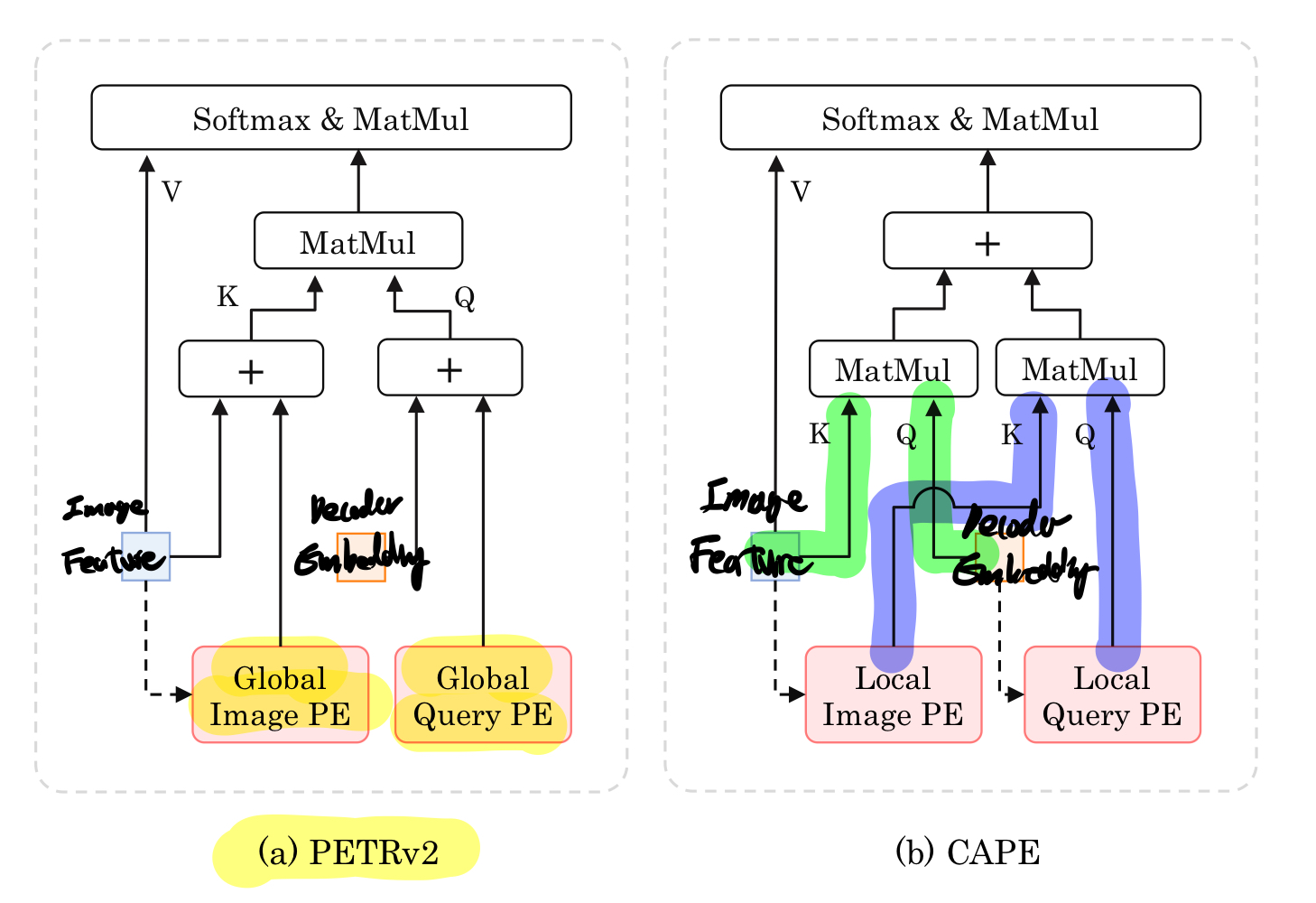
3D PE는 로컬 공간에 있지만 출력 쿼리는 글로벌 좌표계에서 정의되기 때문에, 서로 다른 표현 공간에서 임베딩이 혼합되지 않도록 Figure 1(b)에 나타난 양방향 어텐션 메커니즘을 채택합니다.
-
우리는 더 나아가 CAPE(CAmera view Position Embedding)를 확장하여 다중 프레임의 시간 정보를 통합하여, 3D 객체 검출 성능을 향상시킨 CAPE-T라는 이름의 방법을 제안합니다.
-
[11, 19]에서는 ego-motion을 사용하여 expicit BEV feature을 왜곡시키거나 or ego-motion을 postion embedding에 인코딩하는 것과는 다르게,
- 우리는 각 프레임에 대해 분리된 객체 쿼리 세트를 사용하고, ego-motion을 인코딩하여 쿼리를 통합합니다.
Related work
DETR-based 2D Detection
- DETR의 많은 후속 연구들 [5, 15, 22, 47, 52]은 훈련 단계에서의 수렴 속도 문제를 해결하기 위해 초점을 맞추고 있습니다.
- 예를 들어, Conditional DETR [28]은 어텐션의 항목들을 -> 공간 및 콘텐츠 항목으로 분리하여,
- cross 어텐션에서의 노이즈를 제거하고 빠른 수렴을 이끌어냅니다.
Monocular 3D Detection
- 이러한 방법은 크게 두 가지 범주로 나눌 수 있습니다:
- 순수 이미지 기반 방법
- 객체의 표면적 크기와 기하학적 제약 조건에 따라 깊이 정보를 학습합니다.
- 이는 8개의 키포인트 또는 핀홀 모델 [1,14,16,20,23,27,30,42]에 의해 제공
- detph-guided 방법
- 훈련 단계에서 포인트 클라우드 및 깊이 이미지와 같은 추가 데이터 소스가 필요 [?, 7, 35, 36, 49].
- Pseudo-LiDAR [45]는 픽셀을 pseudo 포인트 클라우드로 변환한 다음 -> LiDAR 기반 검출기 [8, 26, 39, 49]에 입력합니다.
- DD3D [31]는 pre-training 패러다임이 pseudo-LiDAR 패러다임을 대체할 수 있다고 주장합니다.
- 순수 이미지 기반 방법
Multi-View 3D Detection
-
최근에는 몇 가지 방법들 [10, 19, 33, 37, 38]이 explicit BEV 맵을 사용하여 글로벌 시스템에서 객체를 인식하려고 시도합니다.
- LSS [33]는 깊이 분포를 예측하여 뷰 변환을 수행하고 이미지를 BEV로 변환
- BEVFormer [19]은 사전에 그리드 모양의 BEV 쿼리를 통해 공간 및 시간 정보를 활용
- BEVDepth [18]는 포인트 클라우드를 깊이 지도로 활용하고 카메라 파라미터를 깊이 서브 네트워크에 인코딩
-
일부 방법들은 DETR [3] 패러다임을 따라 implicit BEV 특징을 학습
- 이러한 방법들은 주로 3D 희소 객체 쿼리를 초기화하고 어텐션을 사용하여 2D 특징과 상호작용하면서 직접적으로 3D 객체 검출을 수행
- 예를 들어, DETR3D [46]는 3D reference points에서 투영된 2D 특징을 샘플링하고 , 그 후 로컬 교차 어텐션을 통해 쿼리를 업데이트
- PETR [24]은 글로벌 시스템에서 3D 포지션 임베딩을 제안하고 그 후 글로벌 교차 어텐션을 통해 쿼리를 업데이트
- PETRv2 [25]는 PETR을 temporal modeling과 결합하여, PE에 ego-motion을 통합
-
CAPE는 이미지 공간과 로컬 3D 공간에서 어텐션을 수행하여 뷰 변환의 차이를 제거
-
CAPE는 단일 뷰 접근 방식의 장점을 유지하며, 다중 뷰 이미지에서 제공되는 기하학적 정보를 활용할 수 있음
View Transformation
3D scene에서 글로벌 뷰에서 로컬 뷰로의 뷰 변환은 detection 작업의 성능을 향상시키는 효과적인 방법입니다.- 이는 모든 뷰를 정렬하여 정규화하는 것으로 간주할 수 있으며, 학습 절차를 크게 용이하게 만들 수 있습니다.
- 몇 가지 LiDAR 기반 3D 검출기 [9, 29, 34, 39, 40]는 두 번째 단계에서 객체의 전역 좌표 대신 로컬 좌표를 추정하여 ROI feature을 완전히 추출할 수 있습니다.
- 예를 들어, PointRCNN [39]은 더 정확한 regression를 위해
- canonical(정규) 시스템에서의 canonical(규범적인) 3D 박스 세밀 refinement을 제안합니다.
- 포인트 클라우드의 데이터 변동성을 줄이기 위해 AziNorm [6]은 데이터 전처리 단계에서 일반적인 정규화를 제안합니다.
- 이러한 방법들과는 달리, 우리의 방법은
카메라-뷰 포지션 임베딩을 사용하여, 다중 카메라로 인해 발생하는 extrinsic 변동성을 제거하기 위해 뷰 변환을 수행합니다.
Our Approach
Architecture
Experiments
Dataset
- nuScenes
- 700/150/150
training / validation / testingvideo scene sets - 카메라 6개
- video scene 마다 20초 길이 (0.5초 마다 3d annotation이 제공됨)
- 700/150/150
Implementation Details
- 우리는 PETR [24]를 따라 결과를 보고합니다.
- 우리는 여덟 개의 헤드를 가진 멀티헤드 어텐션에서 여섯 개의 트랜스포머 레이어를 쌓습니다.
- 다른 방법들 [12, 24, 46]을 따라, CAPE는 검증 데이터셋에서 사전 훈련된 모델 FCOS3D [44]와 테스트 데이터셋에서 사전 훈련된 모델 DD3D [31]을 초기화로 사용하여 훈련됩니다.
- 데이터 증강으로 일반적인 크롭, 리사이징, 뒤집기를 사용합니다.
- 총 배치 크기는 GPU 당 한 개의 샘플로 구성되며, λ = 0.1로 현재 프레임과 이전 프레임 사이의 손실 가중치를 균형잡기 위해 설정하고, λcls = 2.0으로 분류와 회귀 사이의 손실 가중치를 균형잡기 위해 설정합니다.
- 검증 데이터셋 설정에서는,
- CAPE를 8개의 A100 GPU에서 24 에포크 동안 훈련하며, 시작 학습률은 2e−4로 코사인 에닝 정책에 따라 감소됩니다.
- 테스트 데이터셋 설정에서는,
- 빠른 수렴을 위해 denoise [50]를 채택합니다.
- CBGS를 사용하여 단일 프레임 설정에서 24 에포크를 훈련한 후,
- CAPE의 단일 프레임 모델을 CAPE-T의 다중 프레임 훈련을 위한 사전 훈련 모델로 로드하고 CBGS 없이 60 에포크 동안 훈련합니다.
Comparision with State-of-the-art
- CAPE 와 CAPE-T 모두 성능이 좋다. CAPE는 SOTA이다.
- CAPE는 NDS에서 61.0%, mAP에서 52.5%를 달성합니다.
- 우리는 LiDAR를 지도로 사용하는 것이 mATE 지표를 크게 개선할 수 있다는 점을 지적하며, 따라서 (LiDAR 지도 여부에 상관없이) 방법들을 함께 비교하는 것은 공정하지 않습니다.
- 그럼에도 불구하고, LiDAR를 지도로 활용하는 현대적인 방법들과 비교했을 때도
- CAPE는 NDS에서 BEVDepth [18] 대비 1.0%, mAP에서 2.2% 우수한 결과를 보이며 BEVStereo [17]와 비교하여 비슷한 결과를 달성합니다.
Ablation Studies
- 모든 단일 프레임 실험에서는 1600 × 900 해상도를 사용하고 모든 다중 프레임 실험에서는 800 × 320 해상도를 사용합니다.
Effectiveness of camera view postion embedding
- Tab 4에서 우리가 제안한 카메라 뷰 포지션 임베딩의 효과성을 검증합니다.
- Setting(a)에서는 간단히 PETR을 특성 안내 포지션 임베딩과 함께 사용하여 기준선으로 채택합니다.
- Setting(b)에서는 3D 포지션 임베딩과 양방향 어텐션 메커니즘을 사용하여 LiDAR 시스템에서의 성능을 0.5% 개선할 수 있습니다.
- Setting(c)에서는 양방향 어텐션 메커니즘 없이 카메라 3D 포지션 임베딩을 사용하면 모델이 수렴하지 않고 NDS가 2.5%만 됩니다.
- 이는 카메라 시스템에서의 3D 포지션 임베딩이 LiDAR 시스템에서의 출력 쿼리와 분리되어야 함을 나타냅니다.
- 카메라 뷰 포지션 임베딩을 사용할 때 가장 우수한 성능을 달성할 수 있습니다.
- LiDAR 시스템에서의 3D 포지션 임베딩과 공정한 비교를 위해, 카메라 뷰 포지션 임베딩은 NDS에서 1.4%, mAP에서 2.4% 향상됩니다 (Setting(b) 및 (d) 참조).
Effectiveness of feature-guided position embedding
- Tab. 5는 쿼리와 키에서 특성 안내 포지션 임베딩의 효과를 보여줍니다.
- PETRv2 [32]의 FPE와는 달리, 여기서의 K-FPE는 글로벌 좌표 시스템이 아닌 로컬 카메라-뷰 좌표 시스템에서 형성됩니다.
- Setting(a)와 (b)와 비교하면 Q-FPE가 위치 정확도를 향상시키는 것을 확인할 수 있으며(mAP와 mATE의 개선을 참조), 그러나 로컬 뷰 어텐션에서의 이미지 외형 정보의 부족으로 인해 mAOE에서 방향 성능이 감소합니다.
- Setting(a)와 (c)와 비교하면 K-FPE를 사용하면 NDS에서 1.6% 향상 및 mAOE에서 4.2% 향상이 있으며, 이는 이미지 외형 특징에서 더 정확한 깊이 및 방향 정보에 기인합니다.
- Setting(c)와 (d)와 비교하면 Q-FPE를 추가하면 NDS와 mAP에서 각각 1.6%와 1.9%의 이득을 가져옵니다.
- Q-FPE에 의한 이득은 입력 쿼리에 의해 고차원 임베딩 공간에서 3D 앵커 포인트가 정교화되기 때문입니다.
- Q-FPE와 K-FPE를 함께 사용하는 것이 가장 우수한 성능을 달성할 수 있습니다.
Effectiveness of the temporal modeling approach
- Tab. 6에서 각 프레임에 대해 쿼리 세트를 사용하는 필요성을 보여줍니다.
- 쿼리를 다른 프레임으로 분해하면 NDS에서 0.9% 향상 및 mAP에서 0.8% 향상될 수 있음을 관찰할 수 있습니다.
- 다중 그룹 디자인을 사용하면 한 개의 객체 쿼리가 각각의 프레임에서 하나의 인스턴스에 해당하도록 할 수 있으며, 이는 DETR 기반 패러다임에 적합합니다.
- 유사한 결론은 2D 인스턴스 분할 작업에서도 관찰됩니다 [48].
- 여러 개의 쿼리 그룹을 사용하기 때문에 이전 프레임에 대한 보조 지도를 추가하여 프레임 간의 객체 쿼리를 더 잘 정렬할 수 있습니다.
- 동시에, 이전 프레임에서 생성된 참값은 오버피팅을 방지하기 위한 데이터 증강의 일종으로 처리될 수 있습니다.
- 이전 손실을 채택하면 mAP가 0.5% 증가하며, 이는 다중 프레임에 대한 지도의 유효성을 입증합니다.
- Setting(a)와 (c)와 비교하면, 우리의 시간 모델링 접근 방식은 검증 데이터셋에서 NDS에서 1.4% 향상 및 mAP에서 1.2% 향상될 수 있습니다.
Effectiveness of different fusion approaches
- 퓨전 모듈은 시간 모델링을 위해 다른 프레임들을 퓨전하는 데 사용됩니다.
- Tab. 7에서 일부 일반적인 퓨전 접근 방식을 시간적 퓨전에 대해 탐색합니다.
- 우리는 먼저 간단한 퓨전 접근 방식 "MLP로 연결"을 시도하고, 쿼리를 공유하는 것과 비교했을 때 52.7%의 NDS를 달성하여 0.5% 개선되었습니다.
- 각 프레임의 쿼리들이 유사한 의미 정보를 가지고 있고 다른 위치 정보를 가지기 때문에, 채널 어텐션에서 영감을 받은 퓨전 모델을 제안합니다.
- Tab. 7에서 볼 수 있듯이, 우리의 제안된 퓨전 접근 방식 "채널 어텐션"은 간단한 연결 연산보다 더 높은 성능을 달성합니다.
- 우리는 이 성능 향상이 모델에 추가되는 매개변수의 증가에서 온 것이 아니라는 주장을 제기합니다.
- 우리 모델에는 세 개의 완전히 연결된 레이어만 추가되었습니다.
- 쿼리들은 각 프레임의 시스템에서 정의되고 프레임 간에 ego motion이 발생하기 때문에, ego-motion 행렬을 고차원 임베딩으로 인코딩하여 현재 프레임의 시스템에 있는 쿼리를 정렬할 수 있습니다.
- ego-motion 임베딩을 사용하면 우리의 퓨전 접근 방식이 NDS에서 0.6% 향상 및 mAP에서 0.8% 향상될 수 있습니다.
Visualization
- 우리는 Figure 6에서 8개의 헤드 중 4개의 헤드에 대한 어텐션 맵의 시각화를 보여줍니다.
- 소프트맥스 정규화 작업 이후의 어텐션 맵을 표시합니다.
- 각 행에서 위에서 아래로 로컬 뷰 어텐션 맵, 글로벌 뷰 어텐션 맵 및 전체적인 어텐션 맵이 각각 표시됩니다.
- 시각화 결과에서 우리는 세 가지 결론을 얻고 그려냅니다.
- 첫째, 로컬 뷰 어텐션은 주로 객체의 이웃인 앞, 중간 및 하단과 같은 부분을 강조하는 경향이 있습니다.
- 반면 글로벌 뷰 어텐션은 이미지 전체에 더 많은 관심을 기울이는데, 특히 지면 평면과 같은 유형의 객체에 집중합니다(Figure 6(a) 참조).
- 이 현상은 로컬 뷰 어텐션과 글로벌 뷰 어텐션이 서로 보완적인 관계에 있다는 것을 나타냅니다.
- 둘째, Figure 6(a)와 (c)에서 볼 수 있듯이, 전체적인 어텐션 맵은 로컬 뷰 어텐션 맵과 매우 유사한 것을 확인할 수 있습니다.
- 이는 로컬 뷰 어텐션 맵이 글로벌 뷰 어텐션보다 우위에 있는 것을 의미합니다.
- 셋째, 우리는 전체적인 어텐션 맵이 세밀한 방식으로 전경 객체에 집중되는 것을 관찰할 수 있으며, 이는 뛰어난 위치 지역화 정확성을 시사합니다.
Robustness Analysis
- 이 섹션에서는 카메라 extrinsic 간섭에 대한 우리의 방법의 견고성을 평가합니다.
- 카메라 extrinsic 간섭은 calibration error, 차량의 흔들림 등으로 인해 피할 수 없는 딜레마입니다.
- 공정한 비교를 위해 PETRv2 [25]에 따라 다른 노이즈 수준의 회전에 대한 외부 간섭을 모방합니다.
- 구체적으로, 특정 범위 내에서 각도를 무작위로 샘플링한 다음 생성된 노이즈 회전 행렬을 추론 중인 카메라 외부 성분에 곱합니다.
- Fig.7에서 PETRv2와 CAPE-T의 메트릭 mAP의 성능 하락을 제시합니다.
- 외부 간섭에 직면할 때, 우리의 방법은 PETRv2 [25]와 비교하여 모든 노이즈 수준에서 더 견고한 성능을 보입니다.
- 예를 들어, 노이즈 수준 설정 Rmax = 4에서 CAPE-T는 1.31% 하락하는 반면, PETRv2는 2.39% 하락합니다.
- 이는 카메라-뷰 포지션 임베딩의 우수성을 보여줍니다.
Conclusion
Limitation and future work
temporal fusion을 long-term 으로 하다보니계산량과 메모리 사용량이 너무 많아졌습니다.
