[230623] BEVHeight: A Robust Framework for Vision-based Roadside 3D Object Detection
Object detection
목록 보기
4/23
Abstract
- 최근의 자율 주행 시스템은 대부분 자차 센서에서의 인지 방법을 개발하는 데 초점을 맞추고 있지만, 사람들은 도로 가장자리 카메라를 활용하여 시각 범위를 넘어선 인지 능력을 확장하는 대체적인 접근 방식을 간과하기 쉽습니다.
- 우리는 최신 차량 비전 중심의 BEV 탐지 방법이 roadside 카메라보다 성능이 떨어진다는 사실을 발견했습니다.
- 이는 이러한 방법들이 주로 카메라 중심을 기준으로 깊이 복구에 초점을 맞추기 때문인데, 여기서 자동차와 ground 사이의 깊이 차이는 -> 거리가 증가함에 따라 빠르게 축소됩니다.
- 본 논문에서 우리는 이 문제를 해결하기 위해 간단하면서도 효과적인
dubbled BEVHeight라는 접근 방식을 제안합니다. - 본질적으로, 픽셀 단위의 깊이를 예측하는 대신에, 지면과의 높이를 회귀하여 거리에 무관한 수식을 얻어 카메라 기반 인지 방법의 최적화 과정을 용이하게 합니다.
- 도로 가장자리 카메라의 인기 있는 3D 탐지 벤치마크에서 우리의 방법은 이전의 비전 중심 방법들을 큰 폭으로 능가합니다.
- 코드는 https://github.com/ADLab-AutoDrive/BEVHeight 에서 확인할 수 있습니다.
Introduction
- 이를 해결하기 위해 사람들은 카메라와 같은 도로 지능 장치를 활용하여 이러한 가려짐 문제를 해결하고 인지 범위를 확장하여 위험한 상황에서의 대응 시간을 늘리는 도로 인지 시스템을 개발하기 시작했습니다 [5,11,28,34,36,37].
- 미래 연구를 위해 도로 지능 장치에 대한 두 개의 대규모 벤치마크 데이터셋 [36, 37]이 존재하며, 특정 기준선 방법의 평가를 제공합니다.
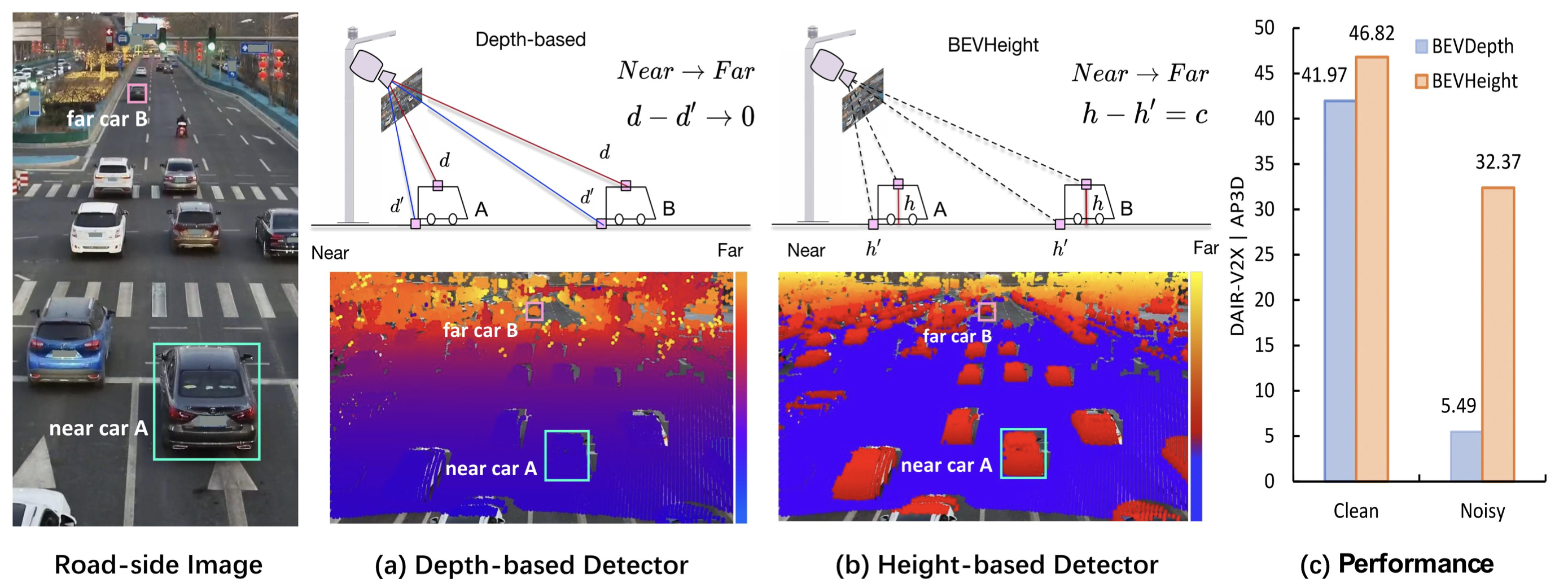
- Fig. 1에서 도로 이미지의 픽셀별 깊이를 시각화하고 현상을 관찰한 결과, 차량의 지붕과 가장 가까운 지면 사이의 두 점을 고려해보면, 이러한 깊이 d와 d'를 카메라 중심까지 측정한다면, 차량이 카메라에서 멀어질수록 깊이 차이인 d - d'가 급격히 감소한다는 것을 알 수 있습니다.
- 이로 인해 두 가지 잠재적인 단점이 생길 수 있다고 추측됩니다:
- i) 자율 주행 차량과 달리 roadside 장치는 데이터셋 간에 서로 다른 카메라 포즈를 가지기 때문에 깊이 회귀가 어렵다는 것,
- ii) 깊이 예측은 extrinsic parameter의 변경에 매우 민감한데, 실제 세계에서 이는 자주 발생
- 반면에 우리는 지면으로부터의 높이가, 차와 카메라 중심 사이의 거리와 관계없이 일정하나는 것을 알아냈다.
- 이를 바탕으로 우리는 BEVHeight라는 새로운 프레임워크를 제안하여 깊이 대신 픽셀별 높이를 예측합니다.
- 구체적으로, 우리의 방법은 먼저 각 픽셀에 대한 범주형 높이 분포를 예측하여 wedgy voxel space에서 적절한 높이 간격으로 풍부한 맥락 특성 정보를 투영합니다.
- our method firstly predicts categorical height distribution for each pixel
- to project rich contextual feature information to the appropriate height interval in wedgy voxel space.
- 이후에는 복셀 풀링 연산과 탐지 헤드를 통해 최종 출력 탐지 결과를 얻습니다.
- Followed by a voxel pooling operation and a detection head to get the final output detections.
- 또한, 우리는 하이퍼파라미터 조정 가능한 높이 샘플링 전략을 제안합니다.
- Besides, we propose a hyperparameter-adjustable height sampling strategy.
- 우리의 프레임워크는 포인트 클라우드와 같은 명시적 지도학습에 의존하지 않습니다.
- Note that our framework does not depend on explicit supervision like point clouds.
- 우리는 두 가지 인기 있는 도로 인지 벤치마크인 DAIR-V2X [37]와 Rope3D [36]에서 광범위한 실험을 수행했습니다.
- 카메라에 문제가 없는 전통적인 설정에서는, 우리의 BEVHeight가 모노큘러 3D 탐지기나 최근의 BEV 방법과 상관없이 모든 이전 방법을 능가하는 최첨단의 성능을 보여줍니다.
- 실제 시나리오에서는 도로 측면 장치의 extrinsic parameter가 유지보수 및 바람 때문에 변동할 수 있으므로,
- 과거의 방법들과 비교하여 우리는 깊이 대신 높이를 예측하는 이점을 보여주며 BEVDepth [15] 대비 26.88%의 개선 효과를 얻었으며, 이는 우리의 방법의 강건성을 더욱 입증합니다.
Related work
Roadside Perception
- 최근 몇몇 연구자들은 도로 시나리오에서의 3D 인지 작업을 촉진하기 위해 도로 데이터셋 [36,37]을 제시하였습니다.
- 자율 주행 차량 인지 시스템은 주변을 짧은 거리로만 관찰하지만, 지면에서 몇 미터 높이에 설치된 도로 카메라는 장거리 인지를 제공할 수 있습니다.
- 그러나 도로 장치에 장착된 카메라는
모호한 장착 위치와가변적인 extrinsic parameter를 가지기 때문에 현재 인지 모델에 중요한 도전 과제를 제기합니다.
Vision Centric BEV Perception
- 최근 인기 있는 방법은 트랜스포머 기반과 깊이 기반으로 나눌 수 있습니다.
- transformer based
- DETR3D [32]에 이어 트랜스포머 기반 탐지기들은 객체 쿼리 [4, 12, 17, 18, 25, 31]나 BEV 그리드 쿼리 [16]를 설계한 뒤 쿼리와 이미지 특징 사이의 교차 어텐션을 통해 뷰 변환을 수행
- depth based
- LSS [22]를 따른 깊이 기반 방법 [9, 10, 23]은 깊이 분포를 명시적으로 예측하고 3D 볼륨 특징을 구성하는 방식으로 작동합니다.
- 후속 연구들은 깊이 추정 정확도를 향상시키기 위해 LiDAR 센서 [15]나 다중 뷰 스테레오 기술 [14, 21, 33]에서 깊이 감독을 도입하며 최첨단 성능을 달성했습니다.
- 그러나 이러한 방법들을 roadside 인지에 적용할 때, 정확한 깊이 정보의 이점은 사라집니다.
- 도로 카메라의
복잡한 장착 위치와가변적인 extrinsic parameter로 인해 이들로부터 깊이를 예측하는 것은 어렵습니다.
- 도로 카메라의
Method
Problem Definition
- 도로 주변 인지 영역에서 사람들은 일반적으로 서로 다른 위치에 설치된 여러 개의 카메라에 의존하여 인식 범위를 확장합니다.
- This naturally encourages adopting those multi-view perception methods though the feature maps are not aligned geologically.
Comparing the depth and height
-
이전에 논의한 바와 같이, 최신 BEV 카메라 기반 방법은 먼저 특성을 버드아이뷰 공간으로 투영한 다음, 네트워크가 3D 위치 정보에 대해 암묵적으로 [16-18] 또는 명시적으로 [10, 14, 15] 학습하도록 합니다.
-
RGB-D 인식에서 이전 접근 방식을 참고하여, 하나의 단순한 접근 방식은 픽셀 단위의 깊이를 위치 인코딩으로 활용하는 것입니다.
-
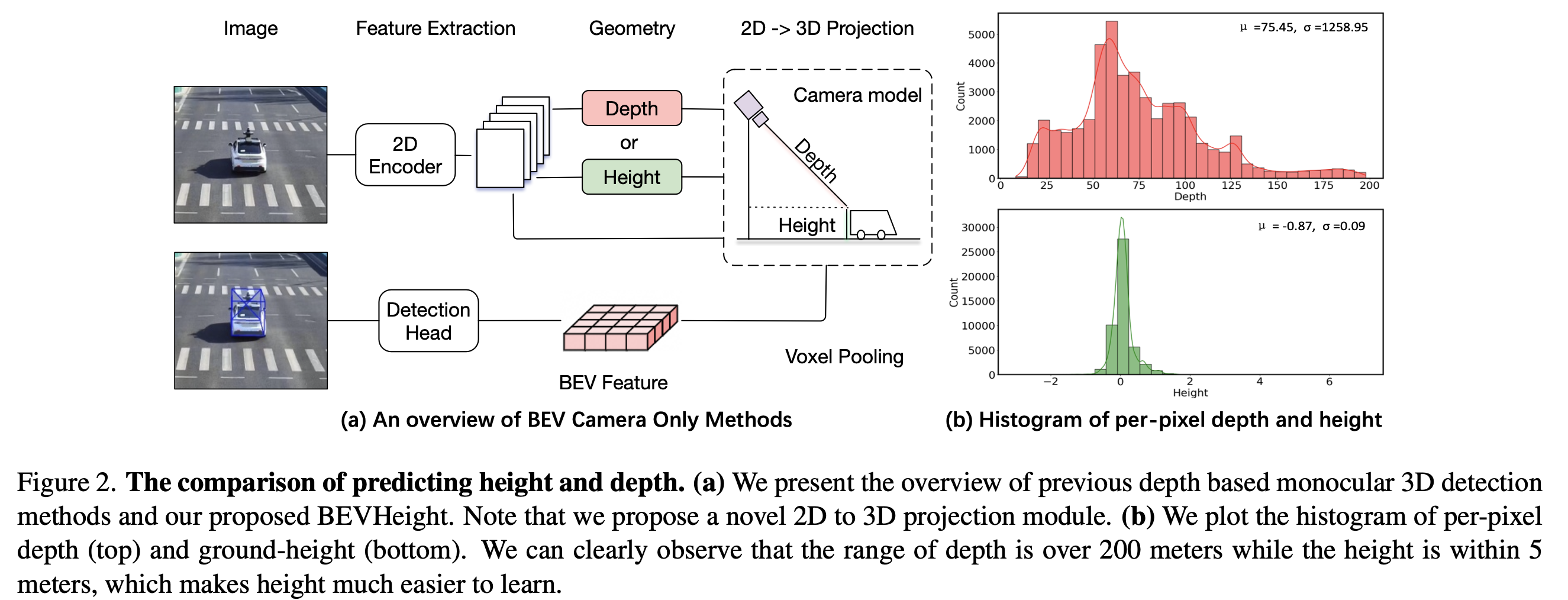
그림 2 (a)에서 현재 방법은 먼저 인코더를 사용하여 원본 이미지를 2D 특성 맵으로 변환합니다.
-
픽셀 단위의 깊이를 예측한 후, 각 픽셀 특성을 3D 공간으로 끌어올리고 복셀 풀링 기술을 사용하여 BEV 특성 공간에 압축합니다.
-
그러나 우리는 깊이를 사용하는 것이 자율 주행 시나리오에서 전방 카메라 설정에서는 최적이 아닐 수 있다는 것을 발견했습니다.
-
구체적으로, 우리는 DAIR-V2X-I [37] 데이터셋의 LiDAR 포인트 클라우드를 활용하여 이러한 포인트를 이미지에 투영한 다음, 픽셀 단위의 깊이 히스토그램을 그림 2 (b)에 표시합니다.
-
0에서 200미터까지 큰 범위를 관찰할 수 있습니다.
-
픽셀 단위의 높이를 그라운드에 대한 히스토그램으로 표시하고, 높이가 각각 -1m에서 2m까지 범위를 갖는 것을 명확히 관찰할 수 있습니다.
-
이는 네트워크가 예측하기에 더 쉬운 범위입니다.
-
그러나 실제로는 예측된 높이를 (깊이와 같이) 핀홀 카메라 모델에 직접 사용할 수 없습니다.
-
높이를 통해 2D에서 3D로 효과적으로 투영하는 방법은 아직 탐구되지 않았습니다.
Anlaysis when extrinsic parameter changes
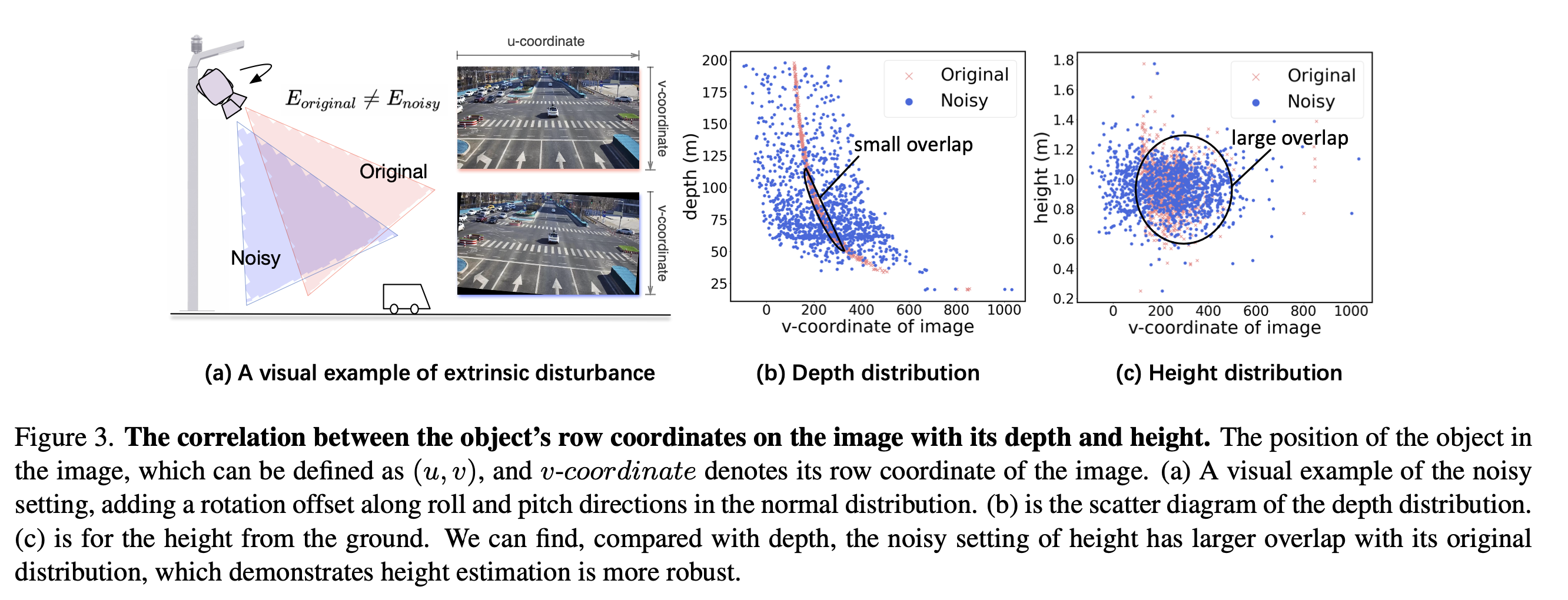
- 그림 3 (a)에서는 외부 장애물의 시각적 예시를 제공합니다.
- 높이 예측이 깊이보다 우수한 이유를 보여주기 위해 개체의 이미지상 행 좌표와 깊이, 높이 간의 상관관계를 보여주는 산점도를 그립니다.
- 각 그림은 하나의 인스턴스를 나타냅니다.
- 그림 3 (b)에서 보이는 대로, 깊이가 작은 개체는 작은 v 값을 가지는 것을 관찰할 수 있습니다.
- 그러나 외부 파라미터가 변경된다고 가정해보면, 같은 지표를 파란색으로 표시하고 깨끗한 설정과 크게 다른 값을 관찰할 수 있습니다.
- 이 경우, 즉 깨끗한 설정과 노이즈 설정 사이에는 작은 겹침만 있습니다.
- 이는 외부 파라미터가 변경될 때 깊이 기반 방법이 성능이 나쁜 이유라고 믿습니다.
- 반면, 그림 3 (c)에서 관찰할 수 있듯이, 분포는 외부 파라미터 변경에 관계없이 유사하게 유지되며, 즉 오렌지색과 파란색 점 사이에 큰 겹침이 있습니다.
- 이는 우리에게 깊이 대신 높이를 사용하는 것을 고려하도록 동기를 부여합니다.
- 그러나 높이를 직접 예측하는 것은 3D 좌표를 복원하기에는 작동하지 않습니다. 이후에는 이 문제를 해결하기 위해 새로운 높이 기반 투영 모듈을 제시합니다.
BEVHeight
Overall Architecture
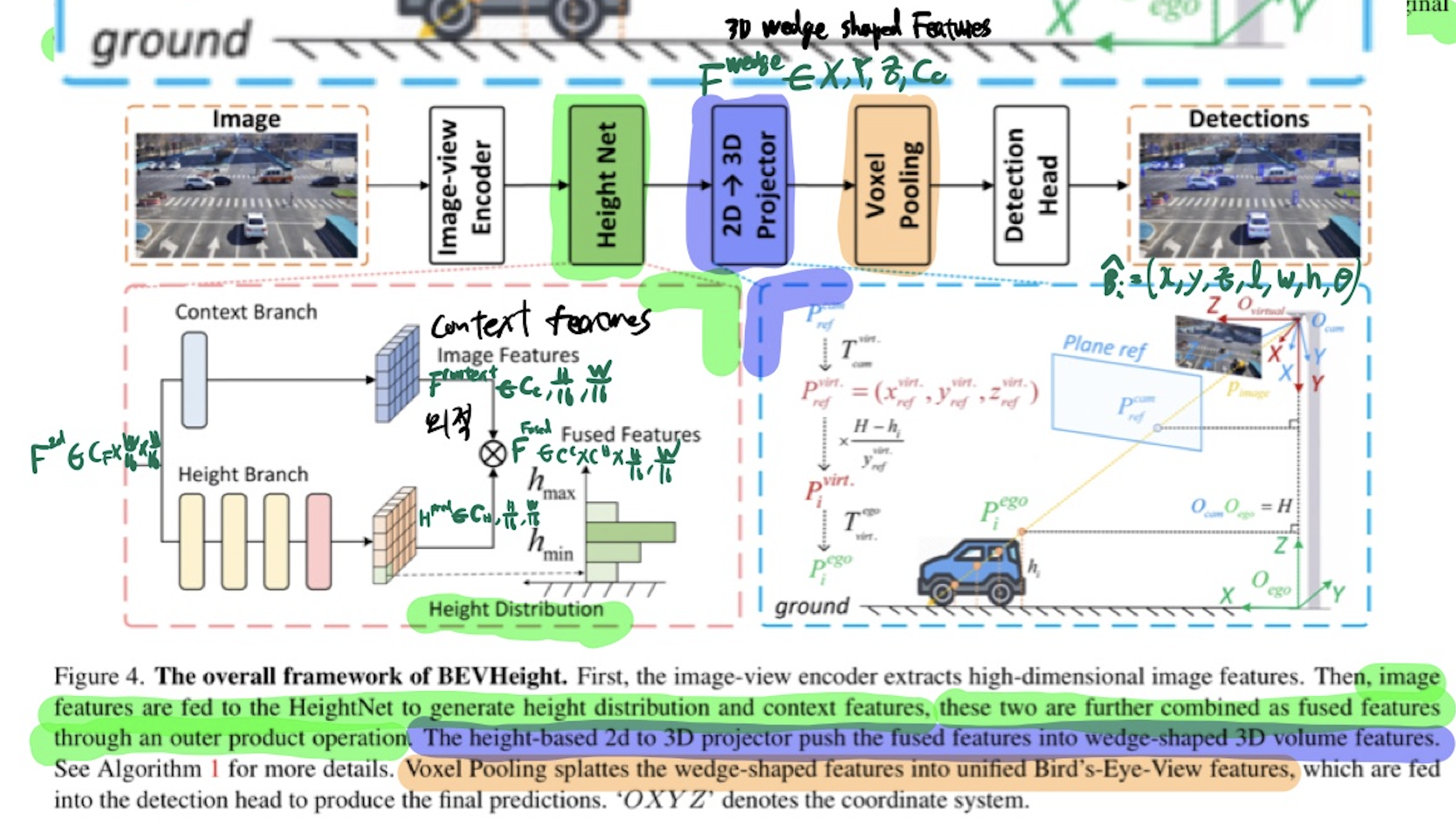
image-view encoder
- 2D backbone + FPN module
- 이미지로부터, 2D high-dimensoional multi-scale image features F_2d = C_f H/16 w/16 를 추출하기 위함.
HeightNet
- 높이의 bins-like distribution(H_pred = C_H H/16 W/16) 을 예측하기 위함.
- C_H: height bin의 수
- context features (F_context = C_C H/16 W/16) 를 예측하기 위함.
- F_fused(C_H C_C H/16 * W/16) 구하는 법
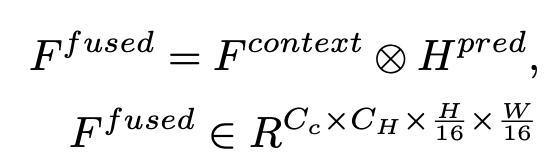
2D->3D Projector
- fused features (F_fused(C_H C_C H/16 W/16)) -> 3D wedge shaped features (F_wedge(XYZC_c) ego 좌표계)
- 이 과정에서, 높이의 bins-like distribution(H_pred = C_H H/16 W/16) 정보를 기반으로 구함.
Voxel Pooling
- 3D wedge shaped features (F_wedge(XYZ*C_c) -> BEV features along the height direction. (F_bev)
3D detection head
- F_bev를 convolution layers로 인코딩함. 그 후, 3D bounding boxes를 예측함.
HeightNet
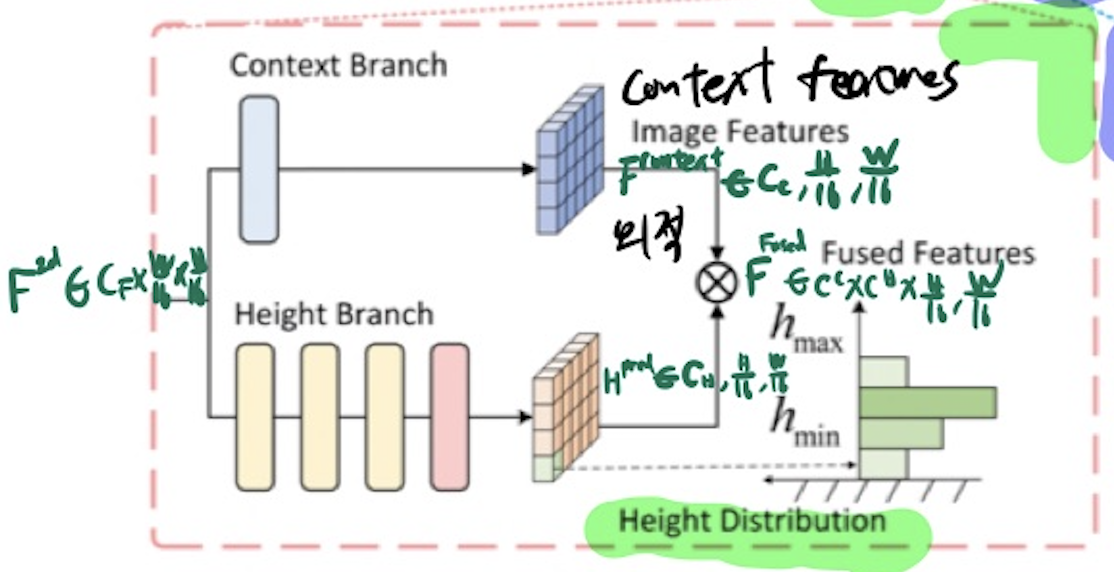
Motivated by the DepthNet in BEVDepth [15], we leverage aSqueeze-and-Excitation layerto generate the context featuresFcontextfrom the 2D image features F2d.- Concretely, we stack multiple
residual blocks[8] to increase the representation power and then use adeformable convolution layer[41] to predict the per-pixel height.- We denote this height module as Hpred.
- To facilitate the optimization process, we translate the regression task to use one-hot encoding,
- 즉, discretizing the height into various height bins.
- The output of this module is h ∈ C_H ×1×1 .
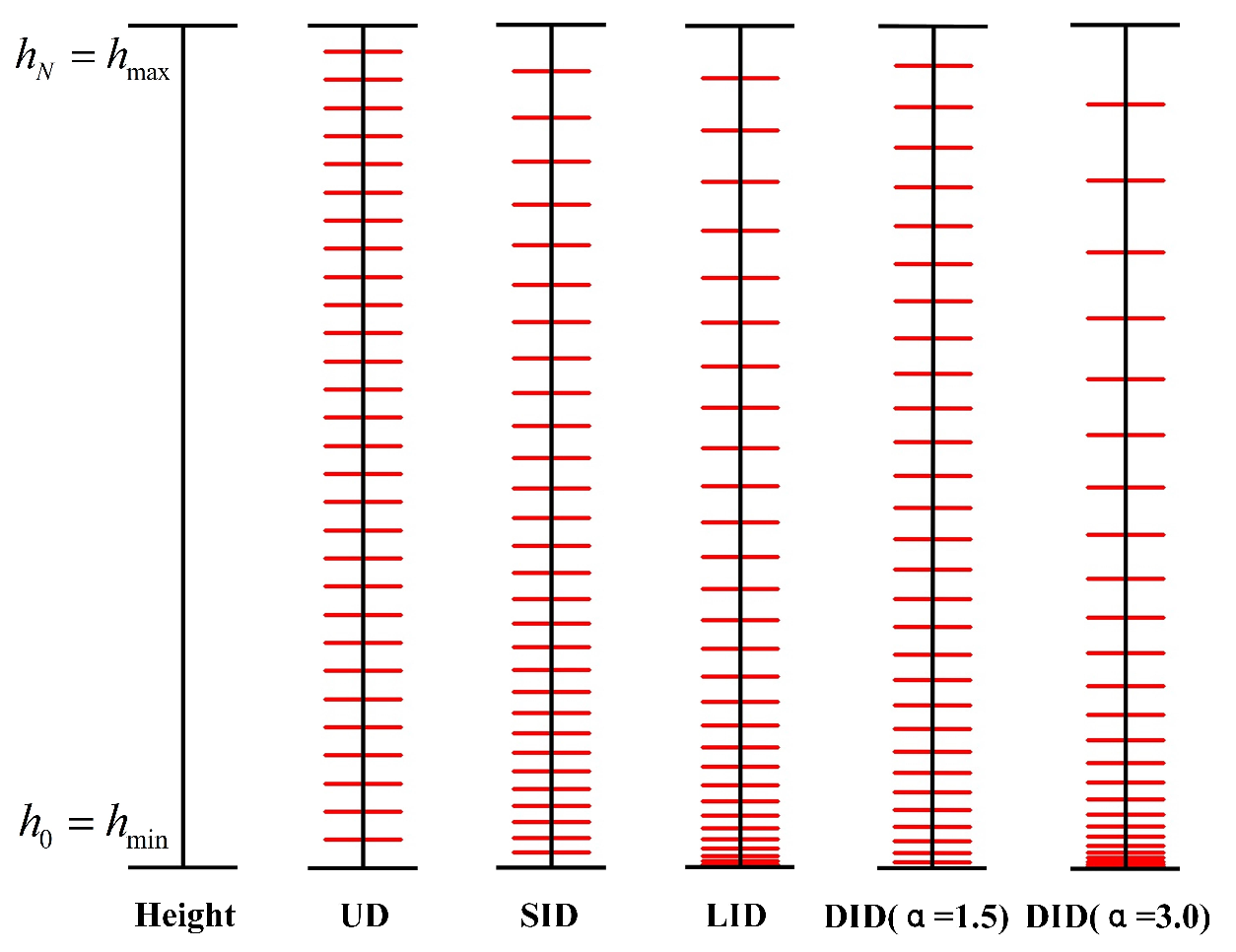
- Moreover, previous depth discretization strategies [6, 30] are generally fixed,
- thus not suitable for roadside height predictions.
- To this end, we present an dynamic discretization as follow:
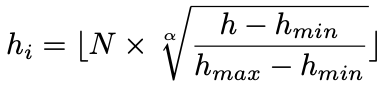
- h: continuous height value from ground
- h_min, h_max : 높이의 시작과 끝 range
- N: number of height bin
- h_i: i-th height bin.
- H: roadside camera의 높이.
- 알파: height bin을 얼마나 모을지에 대한 hyper parameter.
Height-based 2D-3D Projection module.
- 과거의 depth-based methods의 "lift" 방법과 달리, 우리의 방법은 높이만으로 3D 위치를 복원할 수 없다.
- fused features (F_fused(C_H C_C H/16 W/16)) -> 3D wedge shaped features (F_wedge(XYZC_c) ego 좌표계)
- 방법
- virtual coordinate system 만듦
- 원점은 camera 좌표계의 원점과 같다.
- Y축은 지면과 수직하다.
- special reference plane은 image plane과 고정된 거리 1을 가진 상태로 평행하다.
- image plane의 모든 각각의 점 p_image = (u,v) 마다, 우리는 reference plane(Plane_ref)의 연관점 P_ref를 고릅니다. (depth(d_ref)는 1입니다.)
- P_ref를
uvd space->camera coordinate로 변환 (intrinsic 이용해서)
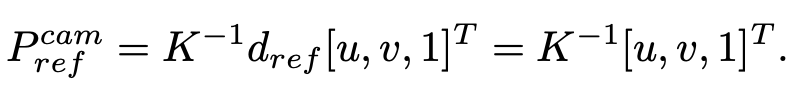
- 이제
camera coordinate->virtual coordinate
- virtual coordinate system 만듦
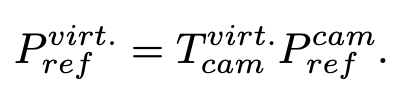
Experiments
Datasets
DAIR-V2X
- Yu et al. [37] introduces a large-scale, multi-modality dataset.
- Here, we focus on the DAIR-V2X-I, which only contains the images from mounted cameras to study roadside perception.
- contains around ten thousand images, where 50%, 20% and 30% images are split into train, validation and testing respectively.
- However, up to now, the testing examples are not yet published, we evaluate the results on the validation set.
- We follow the benchmark to use the average perception of the bounding box as in KITTI [7].
Rope3D
- [36].
- It contains over 500k images with three-dimensional bounding boxes from seventeen intersections.
Experimental Settings
- The input resolution is in (864, 1536).
- ResNet-101 [8] as the image-view encoder.
- For data augmentation, we follow [15] to use random scaling and rotation in the 2D space only.
- All methods are trained for 150 epochs with AdamW optimzer [19], where the initial learning rate is set to 2e − 4.
Comparing with SOTA
Results on the original benchmark
- DAIR-V2X-I 설정에서, 제안된 BEVHeight는 차량, 보행자 및 자전거 카테고리에서 각각 2.19%, 5.87%, 4.61%의 큰 폭으로 최신 방법들을 앞섭니다.
Results on noisy extrinsic parameters
- We follow [38] to simulate the scenarios that external parameters are changed
Specifically, we introduce a random rotational offset in normal distribution N (0, 1.67) along the roll and pitch directions as the mounting points usually remain unchanged. - During the evaluation, we add the rotational offset along roll and pitch directions to the original extrinsic matrix.
- The image is then applied with rotation and translation operations to ensure the calibration relationship between the new external reference and the new image.
- BEVFormer [16] drops from 50.73% to 16.35%. The decline of BEVDepth [15] is from 60.75% to 9.48%. Compared with the above methods, Our BEVHeight main- tains 51.77% from the original 63.49%.
Visualization Results.

Ablation Study
Analysis on Distance Error
Limitations and Analysis
- Though the motivation of our work is to address the challenges in the roadside scenar- ios, we nonetheless benchmark our methods on nuScenes to study the effectiveness.
- 여기서 입력 해상도는 (256, 704)로 설정됩니다.
- 우리는 BEVDepth와 동일한 설정을 따르며, 즉 학습은 24 epoch 동안 진행됩니다.
- Note that, we did not use other tricks such as class-balanced grouping and sam- pling (CBGS) strategy [40], exponential moving average or multi-frame fusion.
- we observe that our method falls behind the BEVDepth by around 0.02 in mAP met- rics.
- This shows that our method has limited performance on ego-vehicle settings.
- 먼저, our method does not assume the ground-plane is fixed(not time-varying), 이것이 자-차량 환경에서 깊이 기반 방법을 능가하지 못하는 이유는 아닙니다.
- 확인하기 위해, 우리는 지면 높이가 3.14m인 이동 트럭에 장착된 카메라에서 약 1만 3천 개의 시퀀스를 수집하고 nuScenes를 따라 3D 객체 박스를 주석으로 달았습니다.
- Tab. 5에서 우리는 우리의 BEVHeight가 깊이 기반 최신 기법을 크게 능가하는 것을 관찰하며, 이는 성능이 시간에 따라 변하는 지면이 아닌, 카메라 높이에 영향을 받는다는 것을 보여주고 자차량 환경에서 작동할 수 있음을 시사합니다.
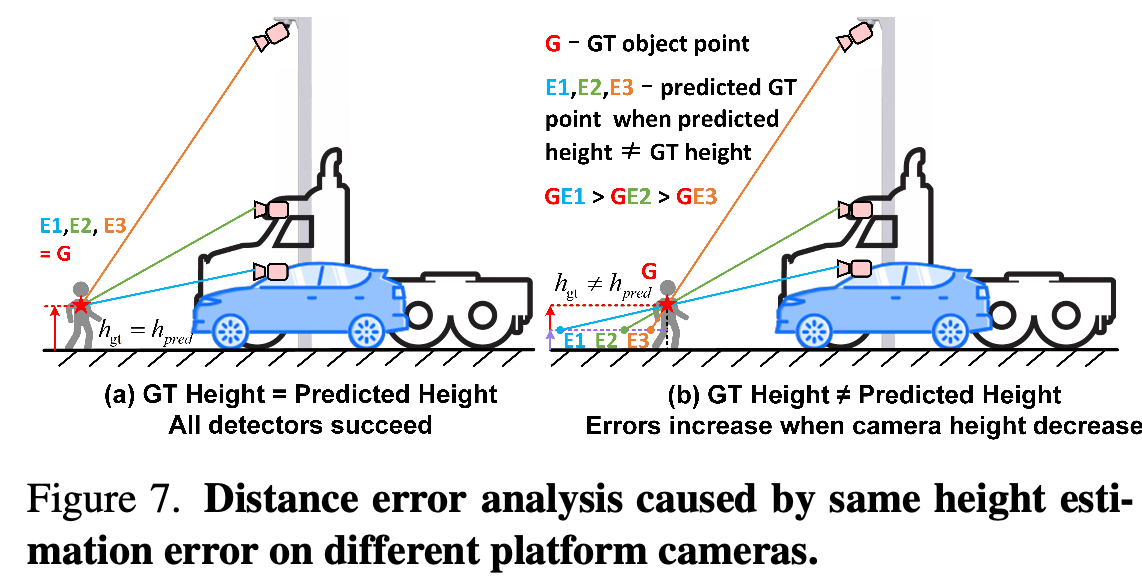
- 우리는 동일한 객체를 관찰하는 세 개의 카메라를 시각화하고 Fig. 7에서 감지 오류를 분석합니다.
- (a)는 높이 예측이 실제 값과 같을 때 모든 카메라에 대한 감지가 완벽한 것을 보여줍니다.
- (b)의 경우, 동일한 높이 예측 오류에 대해 예측 점과 실제 값 사이의 거리는 카메라 지면 높이의 역수 비례 관계에 있습니다.
- 이것이 BEVHeight가 nuScenes에서 동등한 성능을 달성하며, 카메라 높이가 1m 미만으로 증가할 때 BEVDepth [15]를 빠르게 능가하는 이유입니다.
Conclusion
- 우리는 도로 인지 영역에서 전경 객체와 배경 사이의 깊이 차이가 거리가 증가함에 따라 빠르게 축소된다는 것을 알아차렸습니다.
- 반대로, 우리는 픽셀별 높이가 거리와 관계없이 변하지 않는다는 사실을 발견했습니다.
- 이를 위해, 우리는 간단하면서도 효과적인 BEVHeight라는 프레임워크를 제안하여 먼저 높이를 예측한 다음 2D 특성을 3D 공간으로 투영하여 탐지기를 개선합니다.
- 다양한 실험을 통해, BEVHeight가 전통적인 깨끗한 설정에서 DAIR-V2X-I 벤치마크에서 BEVDepth보다 4.85%의 개선을 이루었으며,
- 외부 카메라 매개변수가 변경되는 견고한 설정에서는 26.88%의 개선을 이루었습니다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것