[230804] DAB-DETR : Dynamic Anchor Boxes are Better Queries for DETR 논문 리뷰
Object detection
목록 보기
10/23
Abstract
왜 쓰는데?
-
2줄 요약
- decoder cross attention의 query-feature간 similarity 향상과, 기본 DETR 보다 학습 수렴 속도 개선한 점
- positonal attention map을, 직접 box의 w,h 정보를 통해 조절 가능하다.
-
사진에서 object detection을 하고 싶은데, DETR의 장점을 취하면서, 단점은 극복하기 위함
-
detr 장점
- direct set prediction
- 이렇게 함께 예측하면 객체들 사이의 관계나 상황을 더 잘 이해할 수 있습니다.
- 스케일 불변성
- 입력 이미지의 크기나 해상도에 상관없이 다양한 객체를 탐지하고 인식할 수 있는 스케일 불변성을 가지고 있습니다.
- NMS 사용 없이 겹침 처리 가능
- direct set prediction
-
detr 단점
- 학습 수렴 속도가 느리다.
- DETR의 쿼리는 학습 가능한 벡터들을 쿼리로 사용. “anchor-free”(위치나 형태에 대한 구체적인 정보 없음)
- 쿼리: 찾고자하는 대상인, 사람 / 축구공 들
- 그러므로, 쿼리가 keys 들에 대해, 너무 많은 주의 중심점들을 가질 수 있다. 이는 쿼리가 위치 정보를 명확하게 포함하고 있지 않기 때문이다.
- 학습 수렴 속도가 느리다.
-
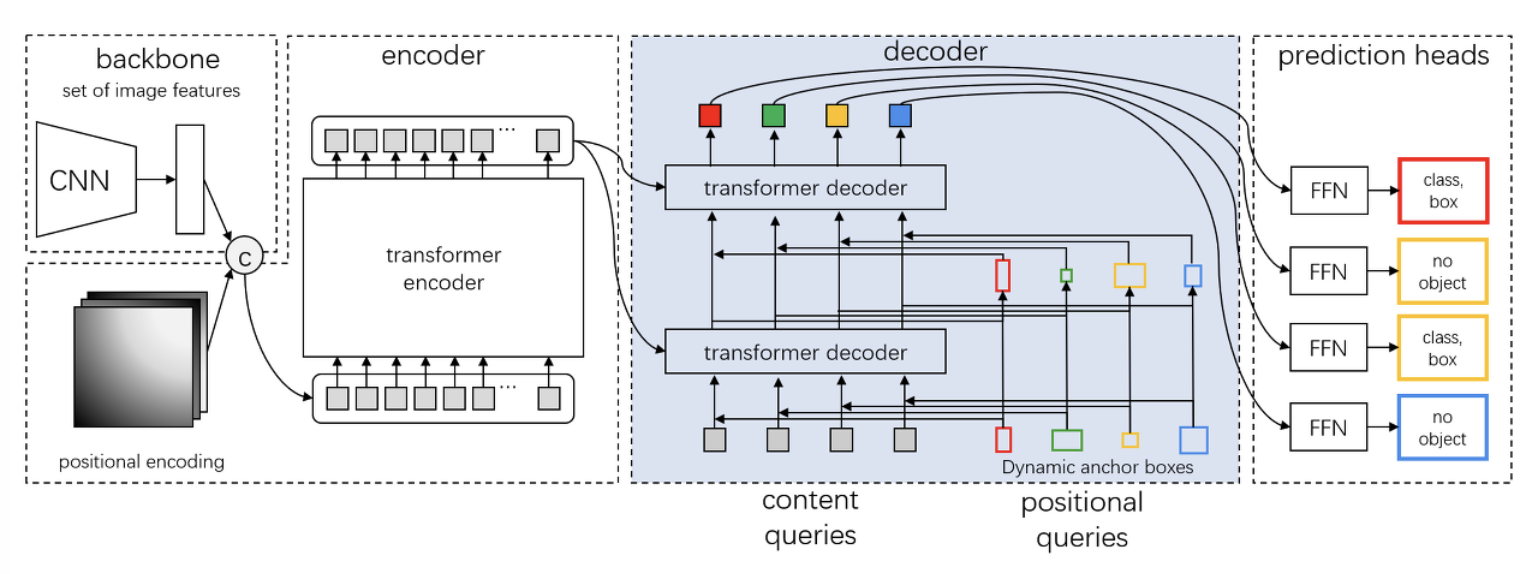
쿼리들(학습 가능한 벡터들)에 추가: 동적 앵커 박스를 도입 (물체의 위치를 예측하는 박스 x,y,w,h)
- 추가의 장점:
- 어떤 keys 에 더 집중해야할지에 대한 가이드를 줍니다.
- 새로운 디자인을 통해 박스의 너비와 높이 정보를 사용하여 위치 주의 맵을 조절할 수 있습니다. 이를 통해 DETR의 쿼리는 계층별로 연속적으로 적용되는 소프트 ROI (Region of Interest) 풀링 메커니즘으로 작동할 수 있음을 보여줍니다.
- 추가의 장점:
-
쿼리에 대한 더 깊은 이해를 통해, 동적 앵커 박스를 사용하는 새로운 쿼리 공식을 제시
- 쿼리는 positional 파트(훈련 가능한 쿼리)와 content 파트(디코더 임베딩)로 구성
- 4D 앵커 박스(x,y,w,h)를 사용한다.
- 앵커박스는 계층별로 동적으로 업데이트된다.
- 쿼리는 positional 파트(훈련 가능한 쿼리)와 content 파트(디코더 임베딩)로 구성
Introduction
- 제안
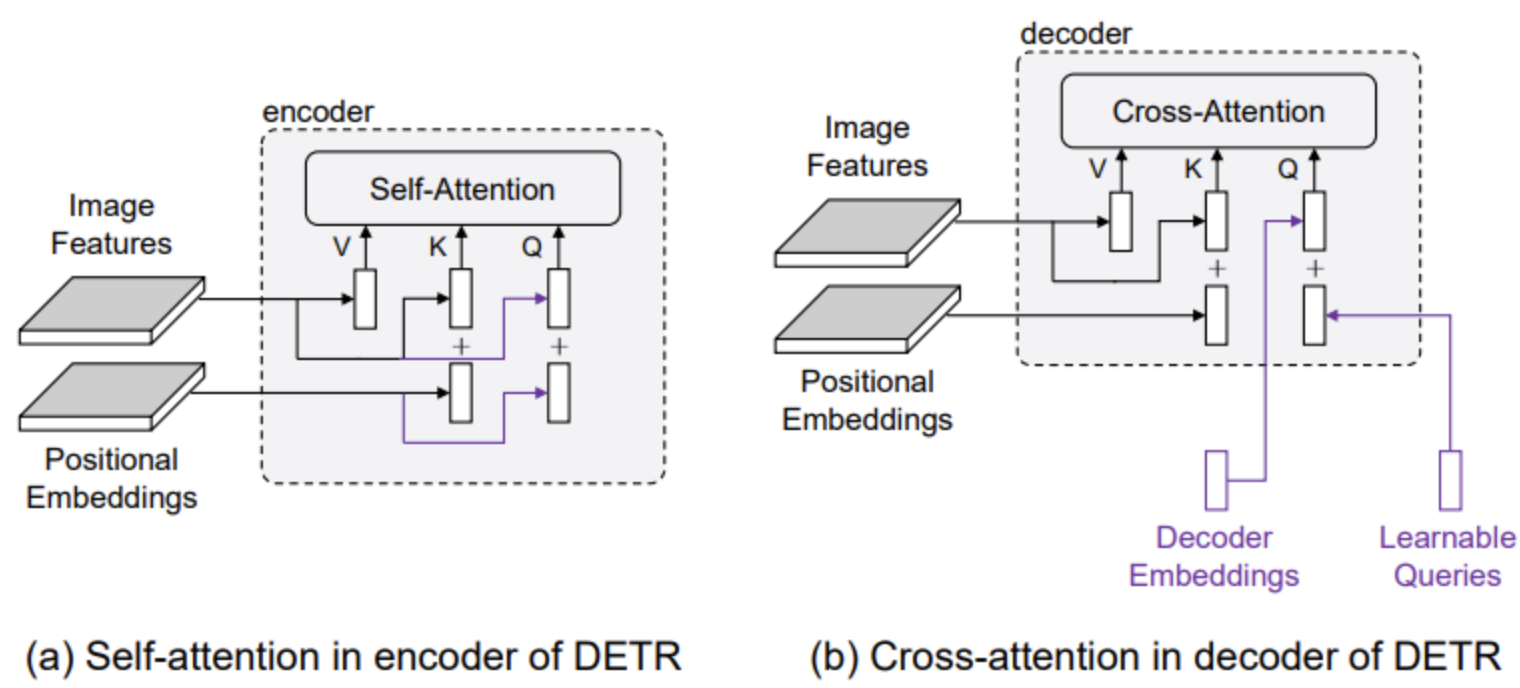
- cross attention은 쿼리를 content 부분(인코딩 된 이미지 feature)과 위치 부분(위치 임베딩)으로 구성된 키 세트와 비교하여 계산된다.
- 따라서 transformer 디코더의 쿼리는
- 내용과 위치 정보를 모두 고려하는 query-to-feature 유사성 측정에 기초한 feature map의 pooling feature로 해석될 수 있다.
- content 유사성은 의미론적으로 관련된 feature를 풀링하기 위한 것
- position 유사성은 쿼리 위치 주변의 feature를 풀링하기 위한 위치 제약 조건을 제공
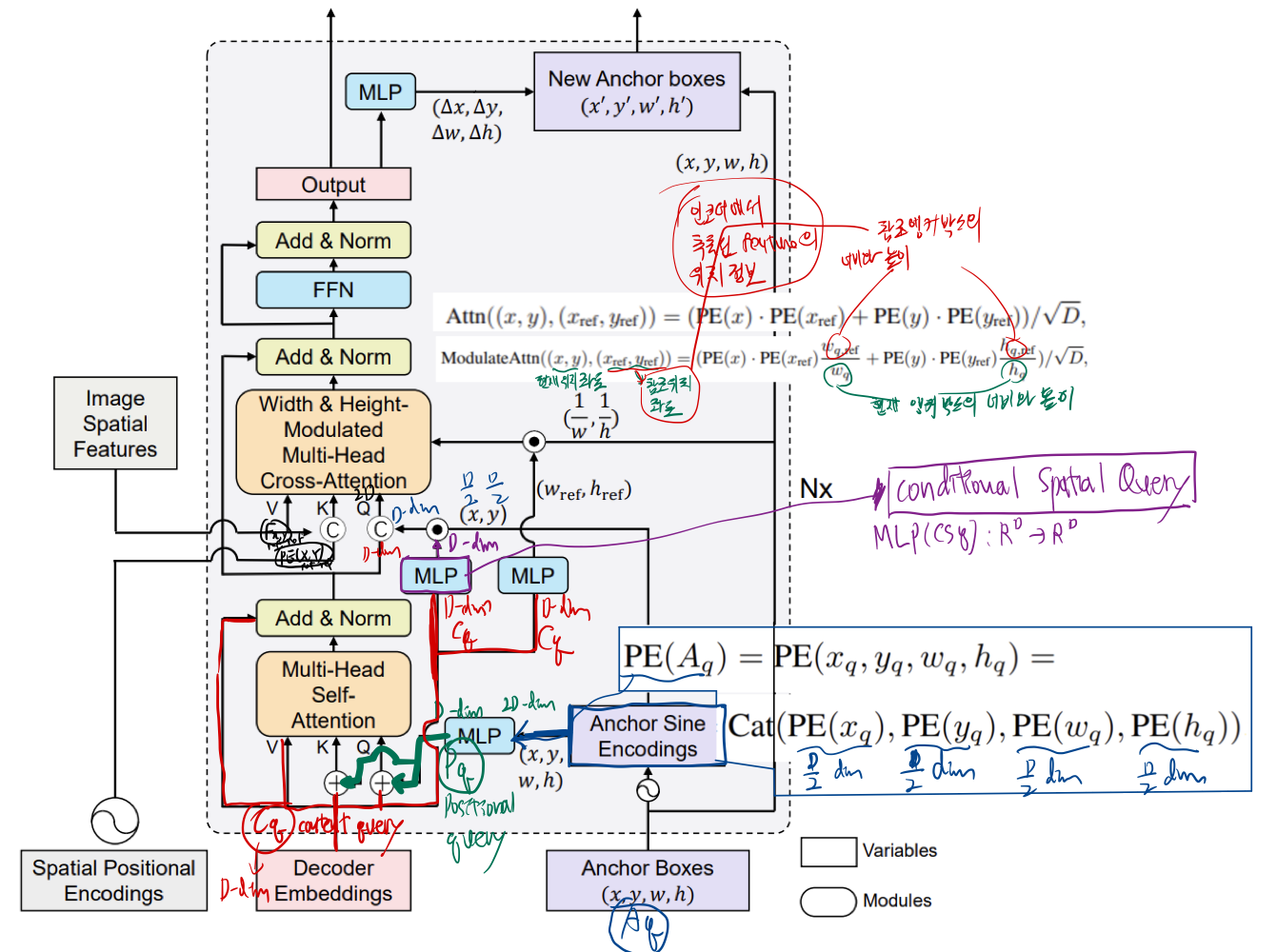
- 앵커 박스의 중심 위치(x,y)를 사용하여 중심 주변의 형상을 풀링하고,
- 박스 크기(w,h)를 사용하여 cross attention map을 조정하여 앵커 박스 크기에 맞출 수 있게 한다.
- 또한 좌표를 쿼리로 사용하기 때문에 앵커 박스를 계층별로 동적으로 업데이트할 수 있다.
related work
- 해당 논문의 특징
- 모델이 직접 4d anchor을 학습함
- 모델이 output 예측 시, relative coordinate를 reference anchor에 관해 예측함.
- 모델이 layer 별로 anchor와 query를 업데이트 함.
- attention이 object의 scale과 더 잘 맞도록 변형됨.


모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것