[231006] XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model
Object tracking
목록 보기
6/6
Category
- Vanila semi-supervised object tracking.
Problem
- 기존 Video Object Segmentation (VOS) 연구들은 하나의 feature memory만 사용했었음.
- 1분 이상의 긴 video를 처리하기에 하나의 feature memory로는 충분하지 않음.
- Past frame representation을 memory에 저장하고 있고, attention을 통해 query해오는 것이 요즘 SoTA 방식 [2, 3, 4, 5, 6]
- 큰 GPU memory를 필요로하기 때문에, consumer-grade hardware에서는 1분 이상의 video를 처리하는 것이 현실적으로 힘듦.
- 긴 video를 처리하는데 특화된 방식도 있긴한데 [7, 8],
- feature memory에 저장할 때 feature를 압축해서 저장하는 방식으로 이루어지다보니, segmentation quality 저하를 감수하는 것임.
Previous works
- VOS는 크게 2가지로 나뉨.
1. Online-learning approach
- Test-time에 train/finetune 하는 방식 [3, 32, 49]으로, (1) inference가 느리고, (2) input에 sensitive하고, (3) training data가 많을수록 이득이 감소하는 단점이 있음.
- 최근에는 inference가 비교적 빠른 방법도 제안되었지만 [2, 34, 37, 42], 여전히 online adaptation이 필요함.
2. Tracking-based approach
- 더 많은 past frame을 feature memory에 쌓아둠으로써, long-term context 이해 능력을 높이려는 시도가 등장함 [13, 16, 21, 28, 36, 58, 64].
- 특히
STM [36]이 가장 인기를 끌었고, 이를 확장하는 연구가 계속 이루어짐 [8, 9, 18, 31, 33, 43, 44, 50, 54]. - XMem은 이것들 중 간단하면서도 효과적인
SCTN[9]을working memory로 사용할 것임. - AOT [60]는 attention mechanism을 transformer로 확장했으나, GPU memory explosion 이슈를 해결하지 못해 기각.
- AOT의 확장인
DeAOT가 XMem과 견줄만한 SoTA 인듯함- (
Segment and Track Anything,Track Anything in High Quality에서 사용).
- (
- AOT의 확장인
Method
Category
- Vanila semi-supervised object tracking.
Problem
- 기존 Video Object Segmentation (VOS) 연구들은 하나의 feature memory만 사용했었음.
- 1분 이상의 긴 video를 처리하기에 하나의 feature memory로는 충분하지 않음.
- Past frame representation을 memory에 저장하고 있고, attention을 통해 query해오는 것이 요즘 SoTA 방식 [2, 3, 4, 5, 6]
- 큰 GPU memory를 필요로하기 때문에, consumer-grade hardware에서는 1분 이상의 video를 처리하는 것이 현실적으로 힘듦.
- 긴 video를 처리하는데 특화된 방식도 있긴한데 [7, 8],
- feature memory에 저장할 때 feature를 압축해서 저장하는 방식으로 이루어지다보니, segmentation quality 저하를 감수하는 것임.
Previous works
- VOS는 크게 2가지로 나뉨.
1. Online-learning approach
- Test-time에 train/finetune 하는 방식 [3, 32, 49]으로, (1) inference가 느리고, (2) input에 sensitive하고, (3) training data가 많을수록 이득이 감소하는 단점이 있음.
- 최근에는 inference가 비교적 빠른 방법도 제안되었지만 [2, 34, 37, 42], 여전히 online adaptation이 필요함.
2. Tracking-based approach
- 더 많은 past frame을 feature memory에 쌓아둠으로써, long-term context 이해 능력을 높이려는 시도가 등장함 [13, 16, 21, 28, 36, 58, 64].
- 특히
STM [36]이 가장 인기를 끌었고, 이를 확장하는 연구가 계속 이루어짐 [8, 9, 18, 31, 33, 43, 44, 50, 54]. - XMem은 이것들 중 간단하면서도 효과적인
SCTN[9]을working memory로 사용할 것임. - AOT [60]는 attention mechanism을 transformer로 확장했으나, GPU memory explosion 이슈를 해결하지 못해 기각.
- AOT의 확장인
DeAOT가 XMem과 견줄만한 SoTA 인듯함- (
Segment and Track Anything,Track Anything in High Quality에서 사용).
- (
- AOT의 확장인
Method
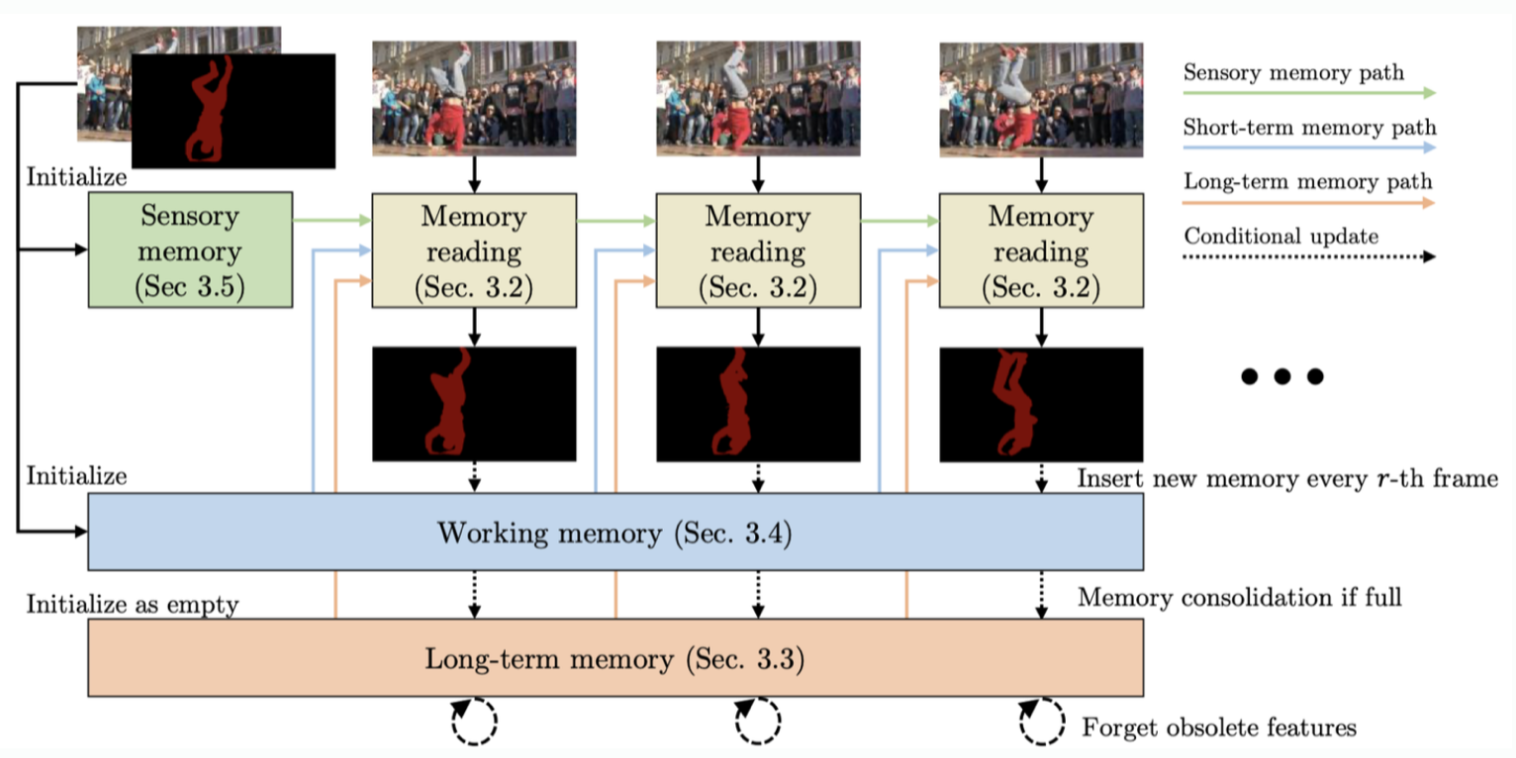
Overview
- “Memory reading”은 모든 memory store로부터 얻은 context info를 이용해 매 frame 마다 mask를 출력하는 역할을 맡음.
- “sensory memory”는 매 frame 마다 업데이트 되고, “working memory”는 매 r-th frame마다 업데이트 됨.
- “working memory”가 꽉차면 압축된 형태로 “long-term memory”로 이동하고, “long-term memory”도 꽉차면 (thousands of frames 처리 후에나 발생) 오래된 feature를 삭제함.
[3.2] Memory Reading
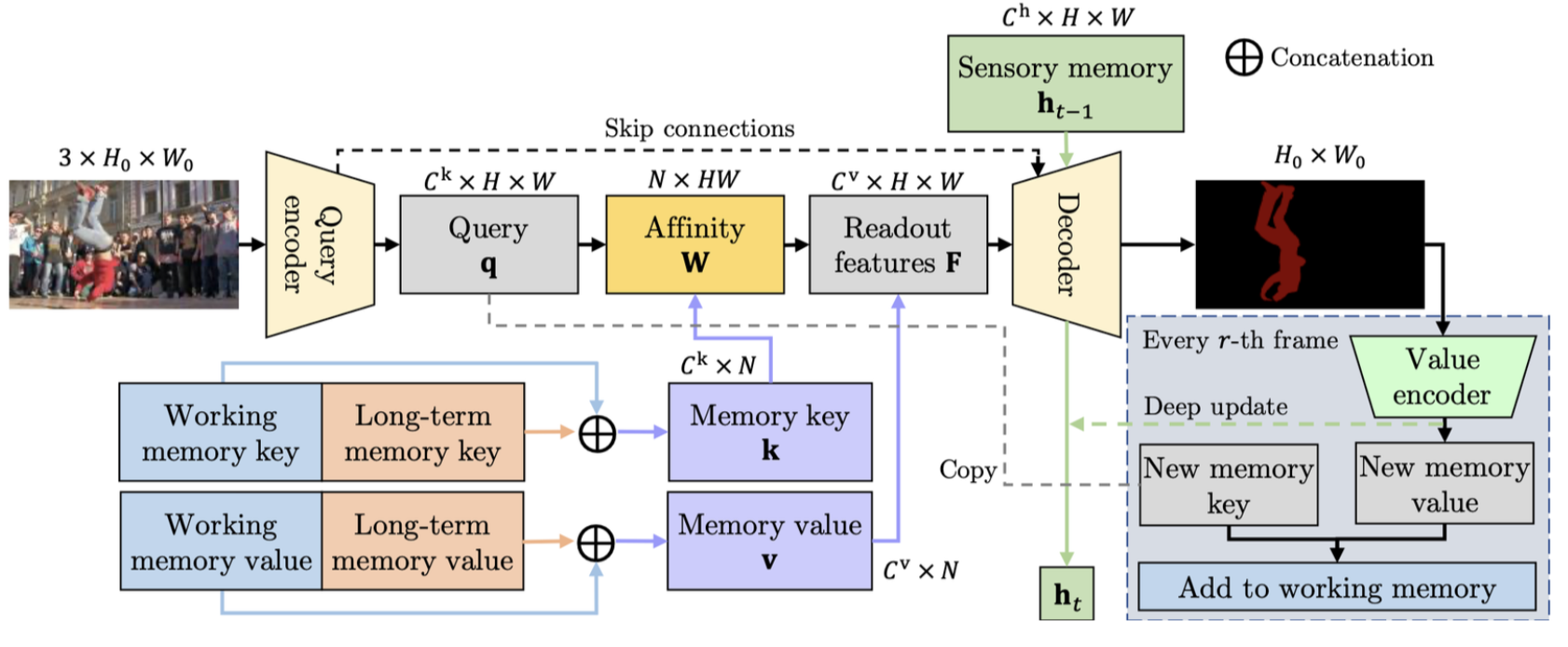
- 현재 프레임과 feature memory stores를 입력으로 mask를 출력하는 역할.
- query-key-value attention이 사용되는데, 현재 프레임이 query로, working memory와 long-term memory가 key-value로 사용됨.
- 현재 프레임을 기반으로 단기/장기 기억속에서 어떤 정보를 꺼내올지 판단!
- Affinity matrix는 query와 key의 유사도를 기반으로 계산되는데, 어떤 similarity funciton을 쓸지도 중요함.
- STM [36]에서 사용한 dot product보다, SCTN [9]에서 사용한 L2 distance가 더 안정적이지만, memory element의 중요도를 설정할 수 없는 등 표현력이 부족한 단점이 있음.
- 안정적이면서도 표현력도 좋은 similarity function인
anisotropic L2 distance를 제안함. 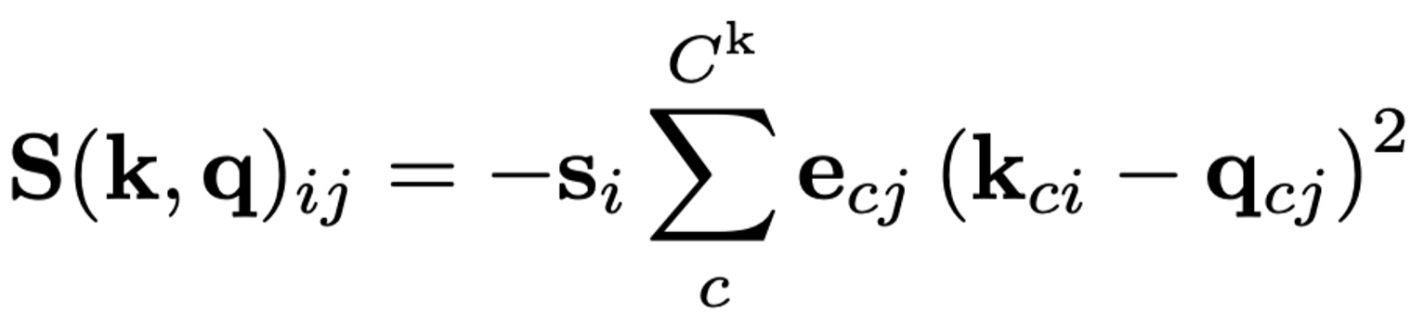
- 일 때, L2 distance와 같음.
- 와 는 학습 기반으로 정해짐
- 는 query encoder의 출력으로,
- 는 working/long-term memory에 저장
[3.5] Sensory Memory
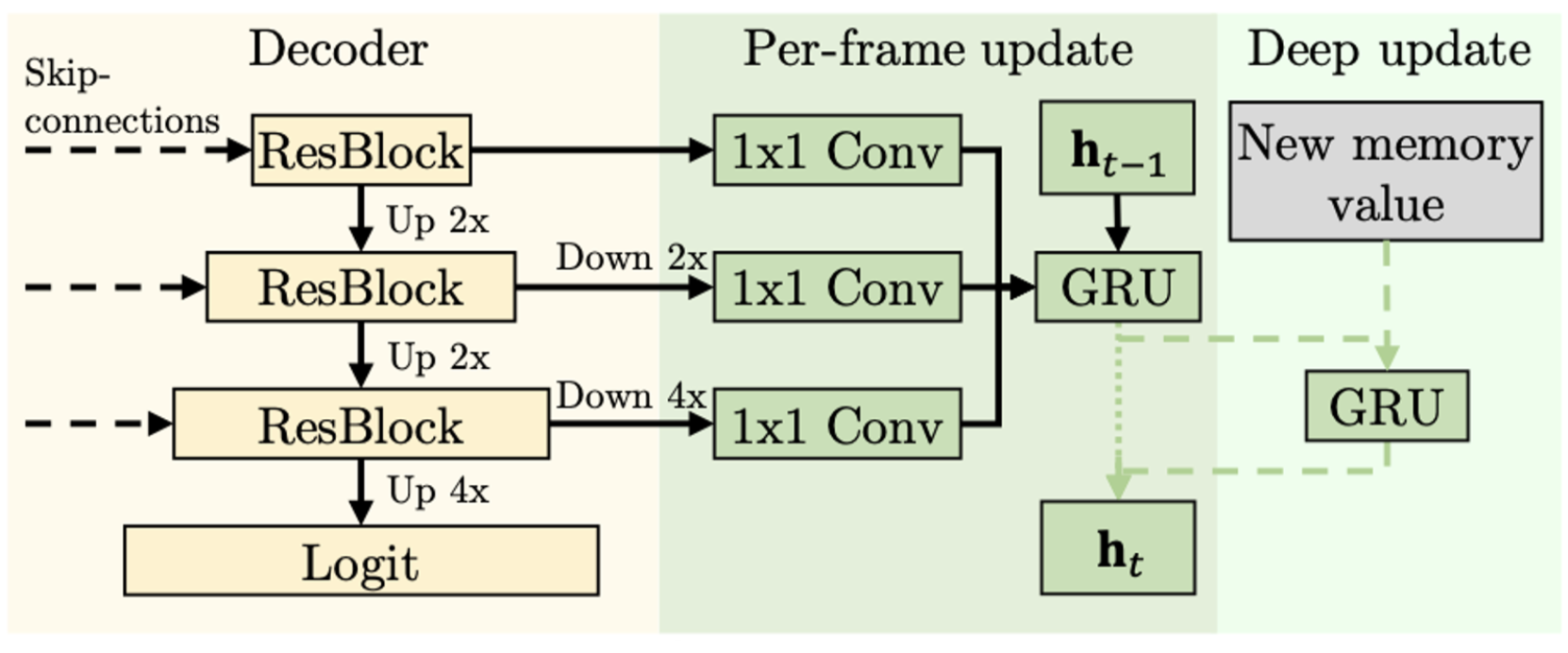
- 매 frame 마다, 입력 이미지의 pyramid CNN feature를 GRU로 인코딩.
- Deep update
- 매 r-th frame마다 업데이트된 working memory value를 인코딩하는 separate GRU가 있음.
- Deep update를 통해 working memory에 저장된 정보가 sensory memory에 중복으로 저장될 필요가 없게 해줌 - 너무 행복회로인듯
- 매번 업데이트 안하고 r-th 프레임마다 업데이트 해도, deep update를 안해도 성능이 유지됨
[3.4] Working Memory
- STCN [9] feature memory bank 그대로 가져다 씀.
- 매 r-th frame 마다, key는 query를 복사해서 만들고, value는 image와 mask로부터 생성하여 저장.
- Memory explosion을 방지하기 위해 적당히 차면 long-term memory로 보내버림.
[3.3] Long-term memory
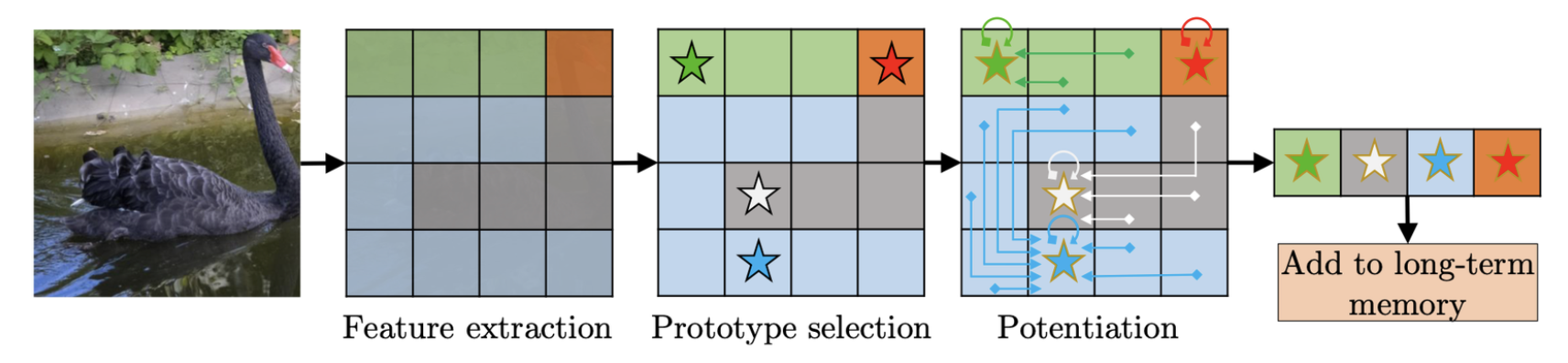
- Long-term memory에는 중요한 것만 넣어야 한다.
- 사람의 뇌를 모방한 prototype selection
: Affinity matrix 기준, 가장 자주 사용된 top-P memory element를 고름. - 6GB GPU memory 기준, 34000 프레임 정도 처리하면 메모리가 꽉차버린다.
- 마찬가지로 affinity matrix 기준, least-frequently-used (LFU) memory element를 제거한다.
- 실제로는 long-term memory의 크기를 10000 프레임으로 제한해 1.4GB 이상 차지 않게했음.
결과
- 긴 frame의 영상에도, 시간이 흘러도 성능이 유지된다. 속도도 유지된다.
- 한계
- 엄청 빠르거나, motion blur가 심한 경우 놓치기도 합니다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것