Introduction
- SAM은 temporal correspondence의 부족으로 video에서는 impressive한 성능을 내지 못했음.
Contribution
- (1) SAM을 비디오 레벨로 끌어올렸고,
- (2) one-pass interaction이라 매우 쓰기 쉽고,
- (3) SOTA 성능 달성
Related Work
VOS (Video Object Segmentation)
XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model, ECCV’22
특징
- 비디오 첫 번째 프레임의 target object에 대한 mask가 주어지면, 이어지는 모든 프레임에서 target object를 segmentation하는 task.
- Unified feature memory store를 사용하는 기존 연구의 한계를 극복하기 위해 Atkinson-Shiffrin memory model을 사용.
- Atkinson-Shiffrin memory model
- 이 모델은 정보가 감지되어 처리되는 방식과 기억의 단계별 이동을 설명하며, 센서리 메모리에서 시작하여 단기기억으로 이동하고, 필요한 정보가 장기기억으로 전환되는 과정을 나타냅니다.
- 정보 처리를 세 단계로 나누어 설명: 각 단계는 센서리 메모리, 단기기억, 장기기억
- 센서리 메모리 (Sensory Memory)
- 정보 처리의 첫 번째 단계로, 외부 자극(시각, 청각 등)이 감지될 때 발생
- 센서리 메모리는 아주 짧은 시간 동안 정보를 유지하는 역할
- 이 정보는 매우 일시적이며, 주의를 기울이지 않으면 금방 사라짐.
- 센서리 메모리는 입력 정보를 유지하고 초기 처리를 위해 사용
- 단기기억 (Short-Term Memory, STM)
- 센서리 메모리에서 선택된 정보는 단기기억으로 이동
- 단기기억은 한 번에 일정한 양의 정보를 보관할 수 있는 용량이 제한된 저장소
- 정보는 여기서 잠시 동안 유지되며, 작업 메모리 또는 작업 공간으로도 불림
- 주의를 기울이고 있는 동안에만 정보가 단기기억에 유지되며, 잠시 후에 사라질 수 있음
- 이 단계에서 정보를 조작하거나 다른 정보와 연결할 수 있음
- 장기기억 (Long-Term Memory, LTM)
- 정보가 단기기억에 머무른 후, 장기기억으로 이동할 수 있음
- 장기기억은 더 오래 지속되는 저장소이며, 용량에는 거의 제한이 없음
- 장기기억은 개인의 지식, 경험, 습득한 스킬 등을 저장하는 곳
- 정보가 장기기억에 들어가면 오랜 기간 동안 유지될 수 있으며, 필요할 때 다시 불러올 수 있음
단점
- 첫 번째 프레임에서 precise mask가 필요함.
- (long video일 경우에는 특히나) tracking이나 segmentation failure에 취약함.
Interactive VOS
Modular Interactive Video Object Segmentation: Interaction-to-Mask, Propagation and Difference-Aware Fusion, CVPR’21
- Interactive VOS task: VOS + user interaction
- 유저가 만족할때까지 segmentation 결과를 반복해서 수정할 수 있음.
- 첫 번째 프레임에서만큼은 정교한 mask를 필요로하던 VOS와 달리, scribbles 수준의 user input만으로 VOS가 가능했기 때문에 주목을 받음.
- 또한, interactive하기 때문에 비디오 중간에 발생하는 tracking이나 segmentation failure를 보정할 수 있음.
- 하지만 많은 round를 거쳐야 고품질의 결과를 얻을 수 있어 real-world application에 사용하기엔 효율성이 떨어지는 단점이 존재.
Method
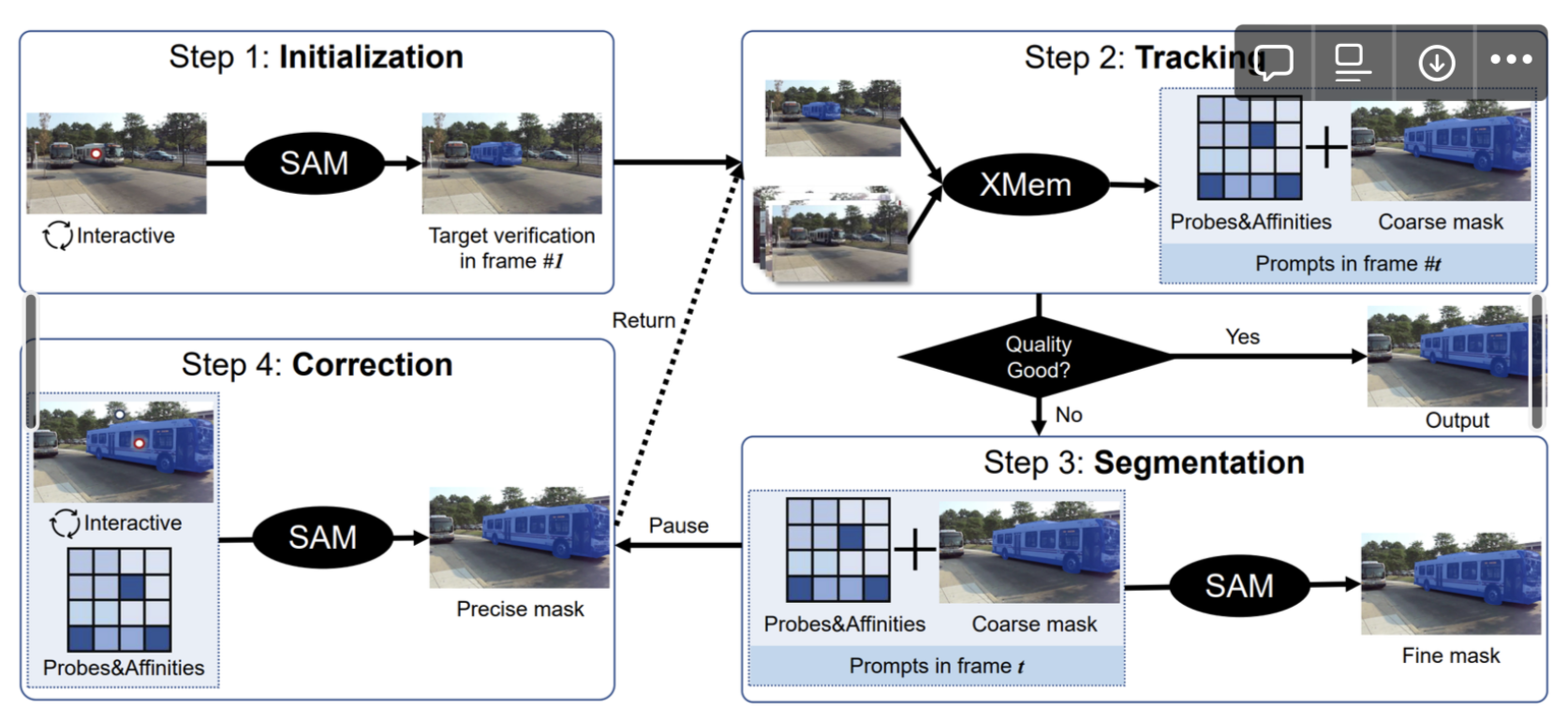
- User가 클릭해서 target object를 알려주면 SAM이 segmentation 함.
- XMem이 다음 frame에서 target object를 찾아 segmentation 함.
- (optional) XMem 결과가 좋지않으면, SAM에게 맡겨 더 정확하게 segmentation 함.
- SOTA VOS 모델들 돌려보면 갈수록 mask가 coarse해지더라.
- 즉, long video 일수록 mask quality를 높게 유지하는 것이 어렵다.
- 따라서, SAM을 이용해 coarse mask를 fine mask로 보정하는 이 과정이 중요하다.
- XMem의 probes와 affinity를 point prompts로, predicted mask를 mask prompt로 사용.
- (optional) 여전히 결과가 맘에 들지 않으면 user가 직접 개입할 수 있음.
- with positive & negative clicks
한계점
- (a) VOS가 짧은 video를 주로 다루고있기 때문에 긴 비디오에서는 잘 못함.
- (b) Object structure가 너무 복잡하면 잘 못함 (e.g., bicycle wheels).

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것