Object tracking
1.[230602]Unified Transformer Tracker for Object Tracking
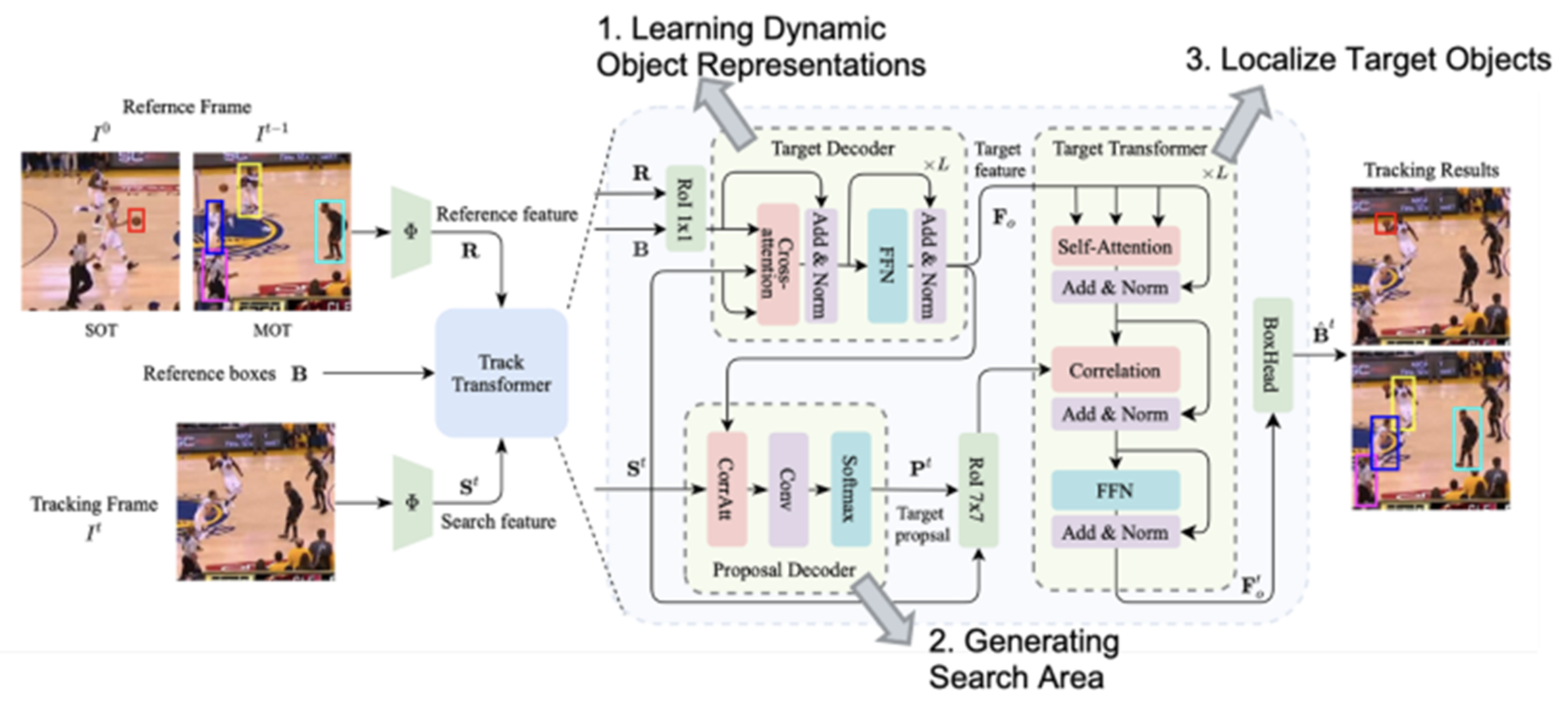
SOT, MOT 에 대한 각각의 방법론은 다른 training datasets / 각 task의 tracking objects의 다름 때문에 서로 적용되기 어렵다.Unified Transformer Tracker(UTT) 제안다른 시나리오에서의 tracking 문제들의
2.[230602] Siamese Network
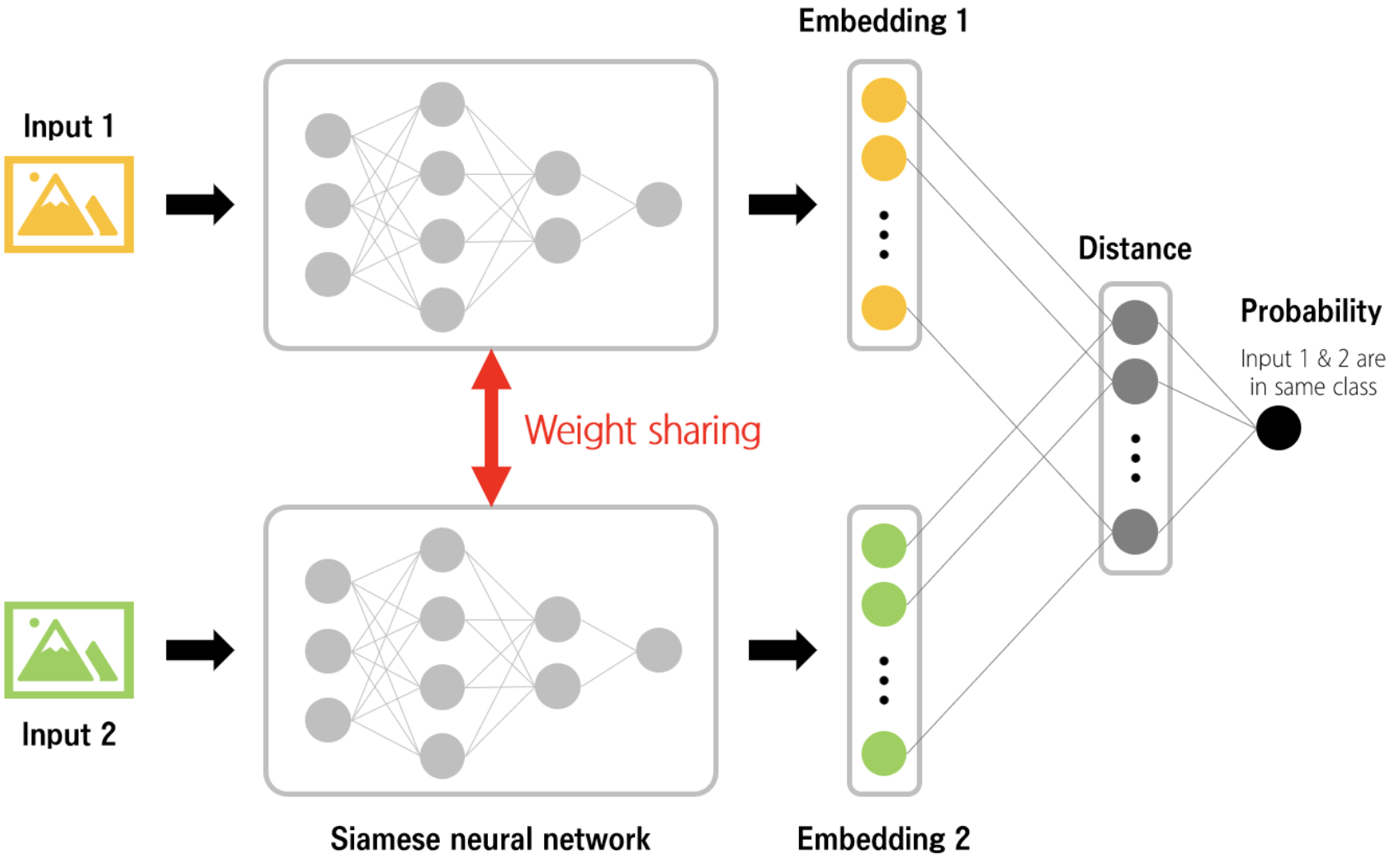
샴 네트워크(Siamese Network)는 "Siamese Neural Networks for One-shot Image Recognition"라는 논문에서 처음 소개되었습니다. 이 논문은 한 번의 학습으로 새로운 클래스에 대한 이미지 인식 작업에서 좋은 성능을 달성
3.[230602] Visual Object Tracking 대회 (2021년까지의 정보)
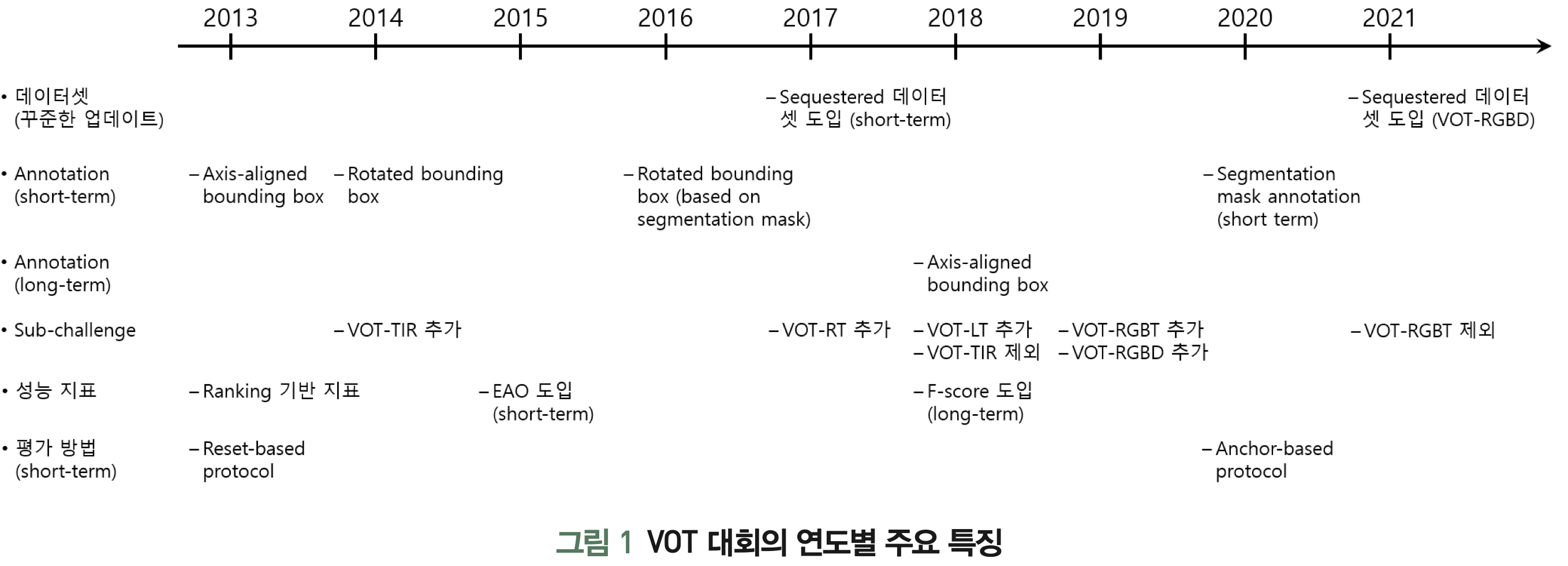
매년 ICCV나 ECCV 에서 열리는 워크샵을 통해 개최되고 있다.VOT dataset을 제공함. 하지만 아래와 같이 다른 dataset들도 tracking을 위해 많이 사용되고 있음OTBTrackingNetLaSOTGOT-10kVOT-RT: real-time 제약이
4.[231006] VOS 종류
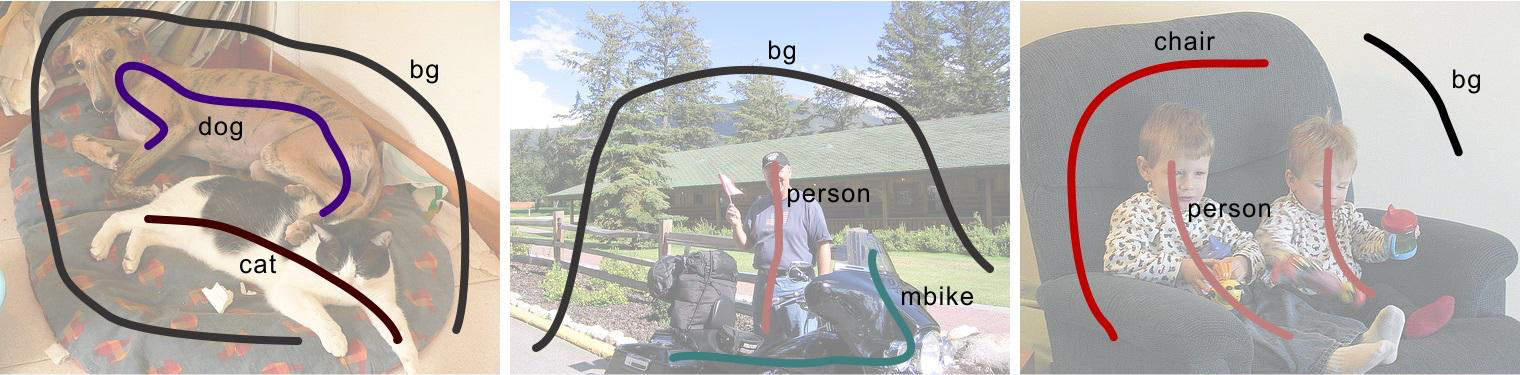
first-frame annotation 이 user로부터 제공됨.input이 user prompt (scribbles 등, segmentation mask보다 훨씬 단순한 형태)인 경우prompt가 text인 경우첫 프레임에 구체적인 Mask가 주어지지 않음. aim
5.[231006] Track Anything: Segment Anything Meets Videos, arXiv’2304
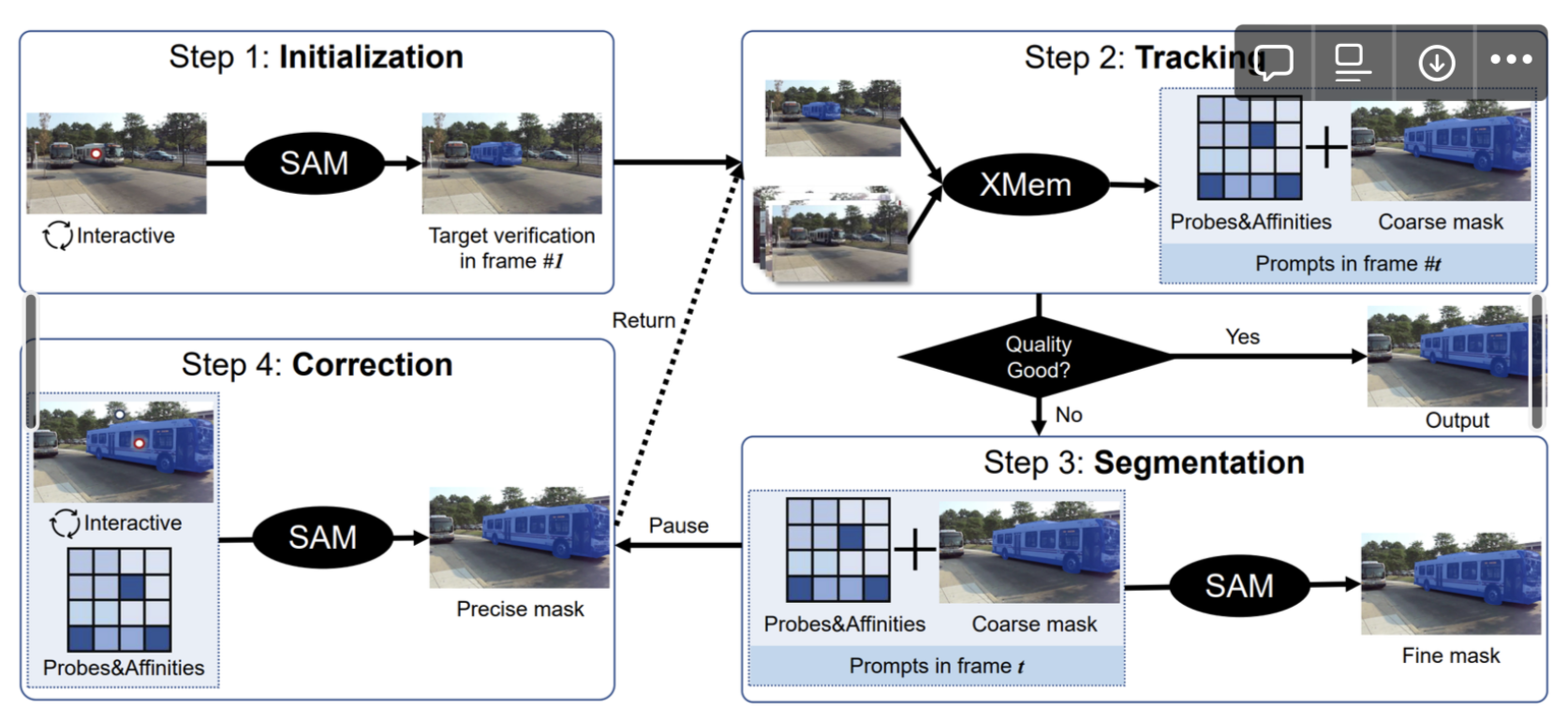
SAM은 temporal correspondence의 부족으로 video에서는 impressive한 성능을 내지 못했음.(1) SAM을 비디오 레벨로 끌어올렸고, (2) one-pass interaction이라 매우 쓰기 쉽고, (3) SOTA 성능 달성비디오 첫 번째
6.[231006] XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model
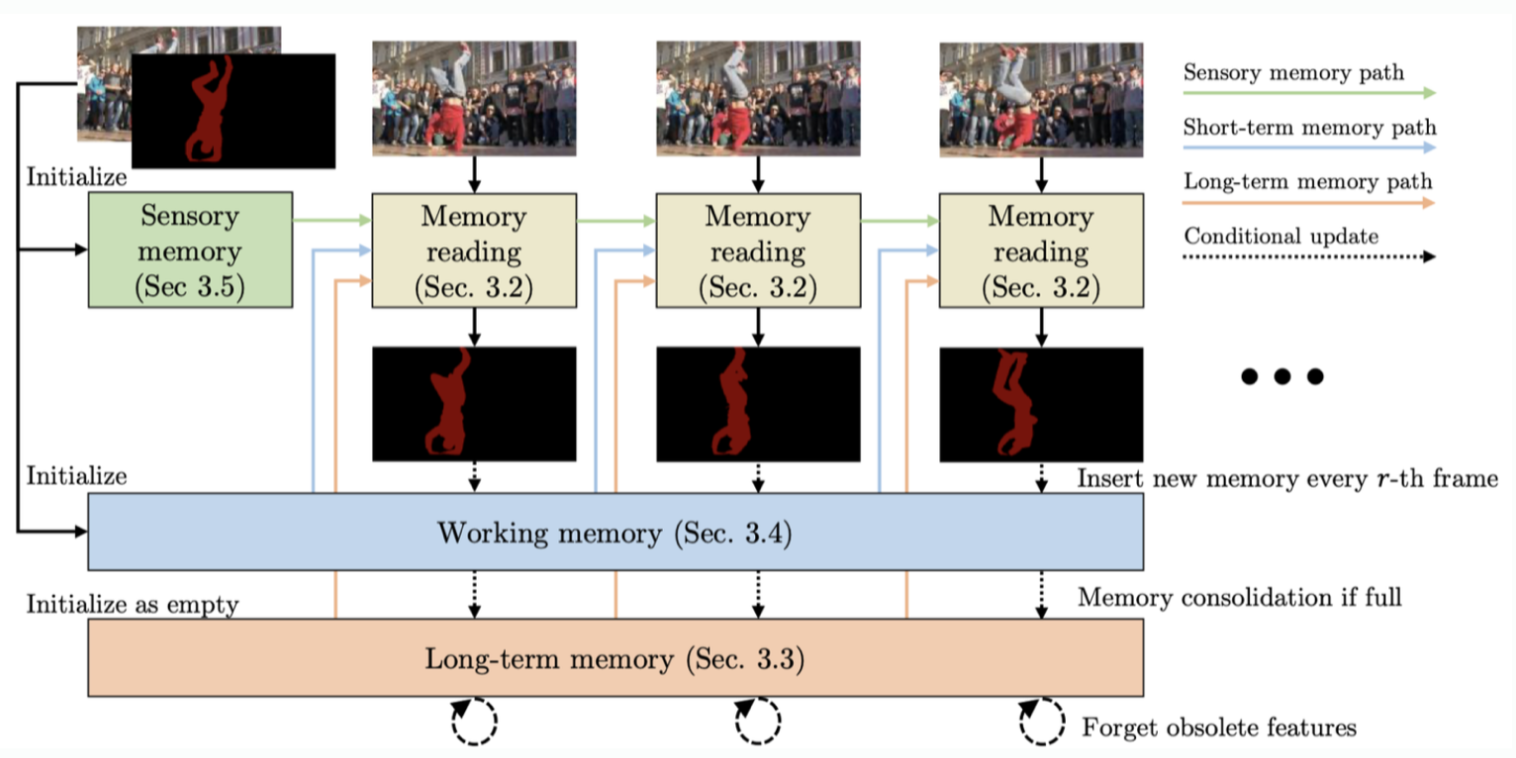
Vanila semi-supervised object tracking.기존 Video Object Segmentation (VOS) 연구들은 하나의 feature memory만 사용했었음.1분 이상의 긴 video를 처리하기에 하나의 feature memory로는 충분