[25,1] VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
[video] foundation model
목록 보기
5/9
논문 4줄 요약
- 고품질의 이미지-recaption 데이터셋을 만드는 pipeline을 제시했고, 고품질의 image-text데이터가 많으면, 비디오-text 데이터가 적어도 video LLM의 성능이 좋을 수 있다고 주장
- ViT based Encoder에 2D rotary positional embedding 기법을 적용해서, input으로 다양한 임의의 해상도 image를 받을 수 있는 아키텍쳐 구조와 훈련법을 제시함
- video token 중, 앞, 현재, 뒷 프레임과 비교했을 때, 1-norm거리가 0.1이하인 token은 제거하는 방식으로 -> 중복되는 의미의 이미지 token은 제거하여 계산 효율을 높였다고 함.
- 하지만, 위 논문은 바로 아래와 같은 3가지 한계점을 지니고 있음.
-1. 들어가기 전에: 본 논문의 한계
-1.1. 비디오 데이터의 품질과 다양성 부족
- 이로 인해, 다양한 비디오 도메인과 장르에서의 일반화 성능이 떨어진다.
-1.2. 실시간 처리 불가능
- 현재 모델 아키텍쳐는 실시간 비디오 처리 문제에 최적화되어 있지 않다. (자율주행이나 ive video 분석과 같은)
-1.3. audio나 speech 모달리티를 고려히지 못했음
- 하지만 이를 수용할만한 아키텍쳐나 훈련법을 철저하게 연구해야 할 것이다.
0. related work(~25.1 까지 연구 동향)
0.1. Multimodal LLMs for Native Video Understanding
- 비디오 길이 제한을 극복하기 위한 논문들
- LLM의 context window를 늘린 접근법도 있고,
- 시공간 차원에서 pooling 기법을 통해, video token compression 기술을 적용한 접근법
- Image Encoder 관련해서는,
- 대부분 연구에서는 Image-based Encoder을 사용했으나,
- 몇몇 연구에서는 video-specific encoder 을 사용했다. (시간적 의존성을 더 잘 포착하기 위함)
- 최신 연구들은, 비디오 뿐만 아니라, (별도의 encoder을 두는 방식으로) audio도 사용했다. 그리고 LLM decoder의 input으로 그들을 통합했다.
- 이러한 연구들은 video-audio dataset 기반 instruction tuning 기법을 사용했다.
- 더불어 최신 연구들은, real-time processing에 집중하였다.
- employing techniques like adaptive memory and incremental processing for tasks such as live event detection and real-time captioning.
- 보통 ViLM의 학습 방식은 아래와 같다. (우리 논문의 학습 방식과는 다르다.)
- alignment phase
- supervised fine-tuning (with instruction data)
0.2. Multimodal LLMs for General Video Understanding
- 0.1.과 다른 점은, 이미지와 비디오를 동시에 처리하는 연구를 의미한다.
- 과거 연구들은,
- 이미지 데이터를 기반으로 잘 학습하면, 적은 비디오 데이터 만으로도 비디오 이해 task에서 좋은 성능을 낼 수 있다는 것을 증명했다.
- Qwen2-VL 논문은, 이미지와 비디오를 동시에 처리할 수 있는 unified framework를 적용했다.
- 긴 비디오 input을 처리하기 위해 최근 연구둘은,
- Mamba와 transformer을 hybrid design한 모델 아키텍쳐를 적용하거나,
- 긴 비디오 데이터셋으로 학습시킨다.
- 최근 연구들은, text,image,video, audio, speech 모달리티를 전부 통합한다.
- Aria 라는 논문은 fine-grained mixture-of-experts 디코더를 이용해서,
- training과 inference를 더 계산 효율적으로 처리한다.
1. 논문의 철학: Image-Centric
- 이 논문은 아래의 철학이, 이미지와 비디오 language model의 성능 모두에 더 도움이 된다고 주장한다.
- 광대한 video-text 데이터셋 이용 X
- video-text 데이터셋은 종종 저품질이거나, annotate하기가 힘들기 때문
- 광대한
고퀄리티image-text 데이터셋 이용 O
- 광대한 video-text 데이터셋 이용 X
- 그래서, 고퀄리티 이미지-text 데이터를 만들었다.
1.1 고퀄리티 image-text 데이터셋(VL3-Syn7M) 만드는 pipeline
- 목표: image의 re-captioning
- COYO-700M 데이터의 이미지를 사용했고, 우리가 제안하는 아래 cleaning pipeline을 이용해 처리했다고 함
Aspect Ratio Filtering
- 너무 길거나 넓은 이미지는 제거한다.
Aesthetic(미적인) Score Filtering
- Aesthetic(미적인) Score model이 있어서, 이미지의 visual quality를 평가할 수 있다고 함.
- 이 점수가 낮으면 데이터셋에서 버린다고 함
정교하지 않은 captioning을 기반으로, Text-Image 유사도 계산
- BLIP2를 이용해서 이미지의 정교하지 않은 caption을 생성한 후,
- CLIP을 이용해서 이미지와 생성한 caption의 유사도를 비교합니다.
- 유사도가 낮은 이미지는 버립니다.
- 이를 통해, 해석가능하고 묘사 가능한 이미지만 남긴다고 합니다.
Visual Feature Clustering
- 여러 이미지들을 CLIP을 통과시킨 후, embedding space에서 KNN을 통해 중복되는 이미지들을 제거합니다.
- balanced distribution of semantic categories를 위해서 라고 합니다.
- 이렇게 구성하면, 다양한 visual content에 대해 일반화하는 모델 능력 향상을 기대합니다.
Image Re-caption
- 남은 이미지들을
InternVL2-8B를 이용해서 짧은 caption을 생성하고,InternVl2-26B를 이용해서 detailed caption을 생성합니다.
- 위 2개 데이터는 각각 다른 training stage에서 사용됩니다.
- 왜 internVL로 captioning 했는지는 Appendix A를 참고하세요.
2. Vision-Centric training paradigm
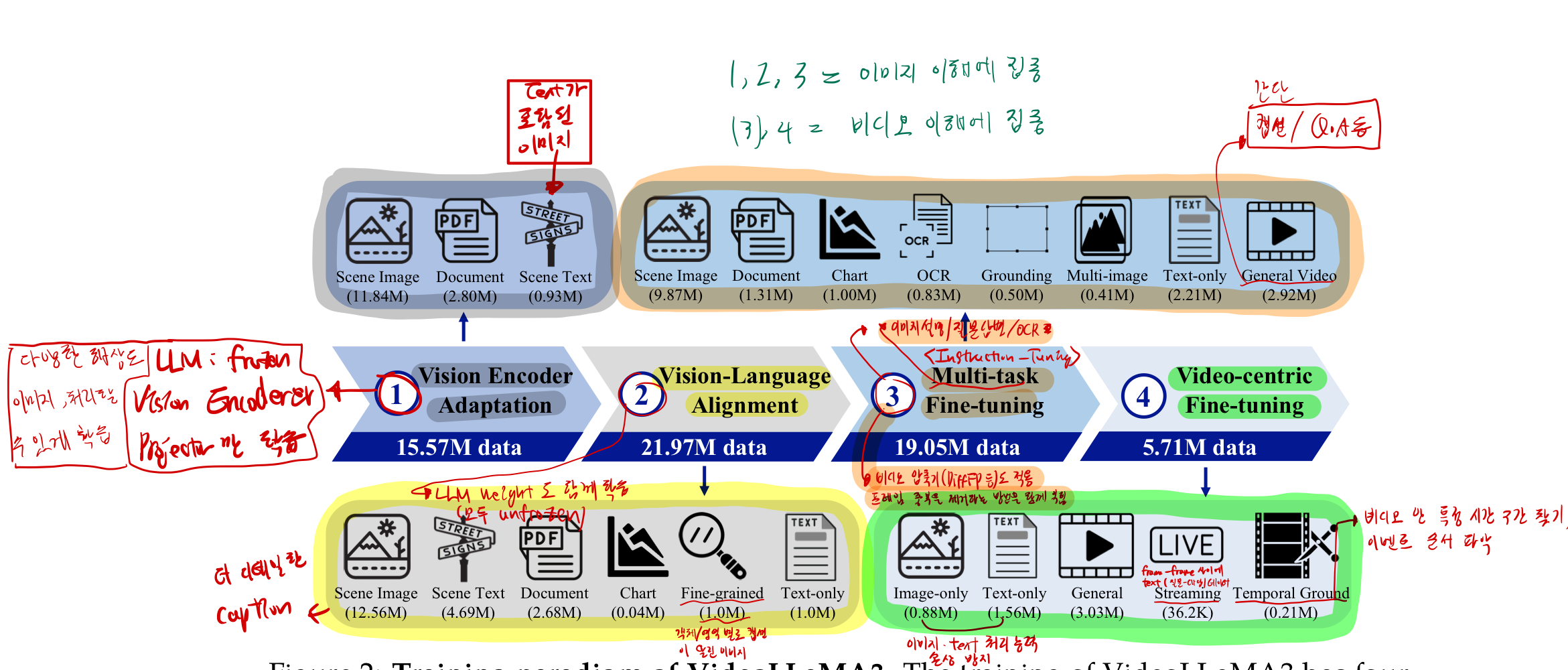
2.1. Vision Encoder Adaptation
- 목적
- vision encoder의 feature space를 LLM의 feature space와 align 시키기 위함
- 다양한 해상도의 이미지를 입력으로 받을 수있도록
- 정보
- pre-trained Vision Encoder와 Projector만 학습
- LLM weight는 frozen
- pre-trained Vision Encoder 학습
- 다양한 해상도의 이미지를 입력으로 받을 수 있게 fine-tuning
고정된 길이의 token을 출력하는게 아니라, 입력 size에 맞는 개수의 token을 출력하도록
2.2. Video-Language Alignment
- 데이터
- large-scale image-text data (다양한 유형 포함)
- Laion-OCR dataset 의 caption에 대해서는
- text content 뿐만 아니라,
- text 위치의 bounding box annotaiton까지 포함
2.3. Multi-task Fine-tuning
- 데이터
downstream task를 위한 image-text SFT(Supervised Fine Tuning) data- 이미지 설명/VQA/OCR 등
- 일반적인 video-text data
- VideoLLaMA2를 이용해서 생성
- 직접 만든 temporal grounding data
- 비디오 frame간 시간적 관계에 집중
- 이벤트를 잡아내거나, 시간에 따른 action flow를 이해하기 위함
2.4. Video centric Fine-tuning
- 비디오 이해 능력을 더 훨씬 더 증가시키는 단계
- 데이터
- 큰 규모의 고품질 video instruction tuning 데이터
- 여기에 추가로, LLAVA-VIDEO: VIDEO INSTRUCTION TUNING WITH SYNTHETIC DATA
의 pipeline을 이용해서, Qwen2-VL-72B 모델을 이용해서 - 다양한 dense captions와 VQA 를 re-captioning 했습니다.
- temporal, spatial 이해를 위함
- 물체 설명을 위함
- time-order understanding을 위함
3. Vision-Centric framework design
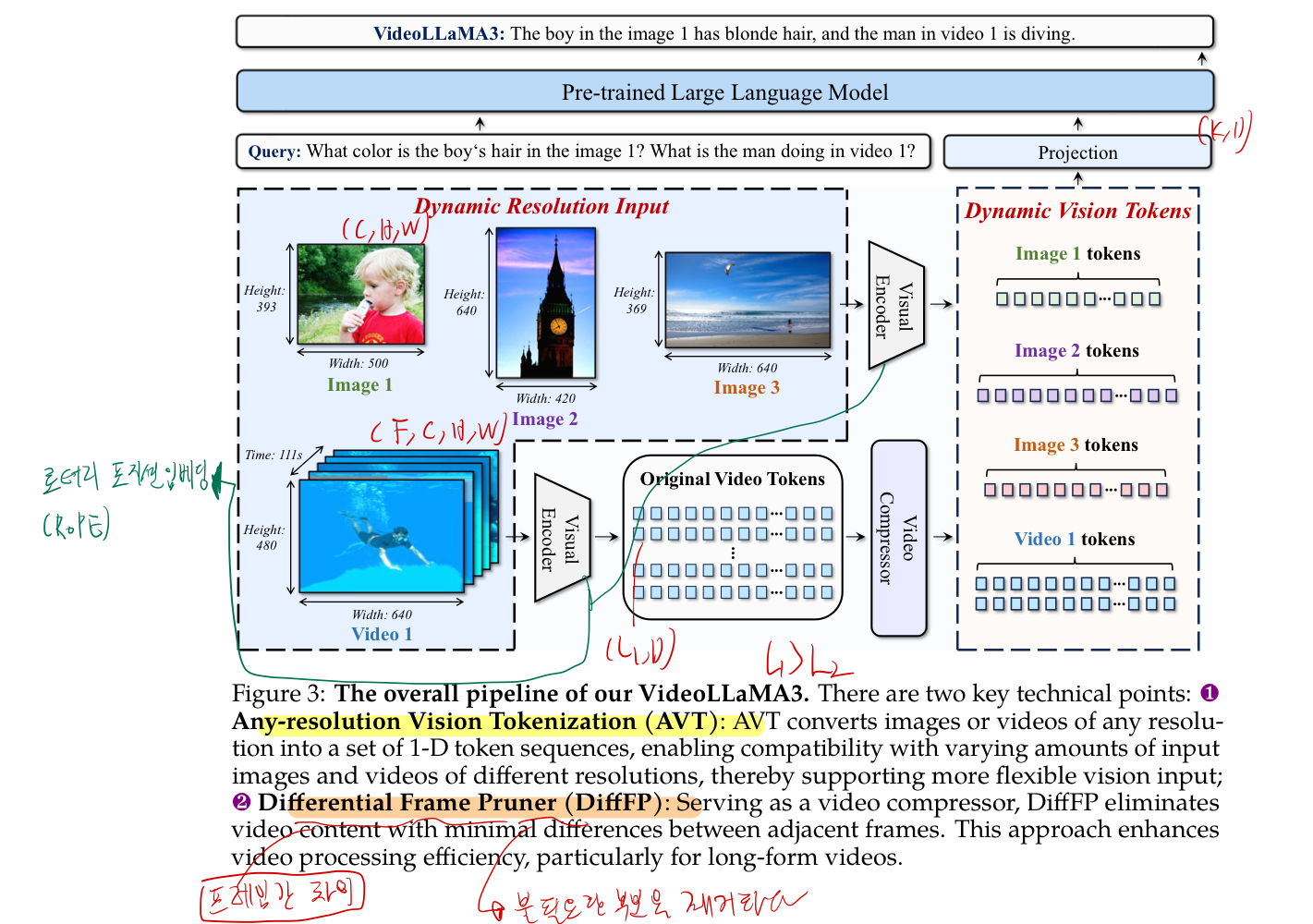
3.1. 다양한 해상도 이미지 수용 가능한 image encoder
- 과거 연구에서는, 일반적으로는,
pre-trained ViT-based Vision Encoder을 사용하여 visual inputs을 추출하는 연구가 많다.- 그로 인해, image encoder의 토큰 개수가 고정되어야만 했거나,
- 몇개 선택지 중에서 고를 수 있는 정도 였다.
- image를 고정된 해상도의 patches로 쪼개는 방법을 통해
- 하지만 이 방법들의 단점은
- 임의의 해상도를 받을 수 없다는 점
- vision token을 추출할 때, image 내의 위치 관계를 무시한다는 점
- 다양한 해상도 이미지 수용 가능한 image encoder는 아래 기술로 실현 가능하다.
- 일단, ViT-based Vision Encoder(논문에서는 SigLIP 에서 fine-tuning하는데, (단계 1: Vision Encoder Adaption 학습 단계에서 실시함)
- sigLIP을 쓰는 이유? Abalation study 해보니 젤 좋았다고 함
- ViT의 fixed positional embeddings -> 2D Rotary Position Embedding(RoPE) 로 대체
- Rotary Position Embedding(RoPE)
- 일단, ViT-based Vision Encoder(논문에서는 SigLIP 에서 fine-tuning하는데, (단계 1: Vision Encoder Adaption 학습 단계에서 실시함)
3.2. video input도 image encoder가 수용 가능하면서, 유사 중복 token은 제거하는 구조
- 들어가기전에 참고
- 비디오 input 시 계산량 줄이려고(context length를 일정 범위 이내로 제한하기 위해서), frame마다 2 by 2 spatial downsampling을 적용했다고 함 (bilinear interpolation을 통해)
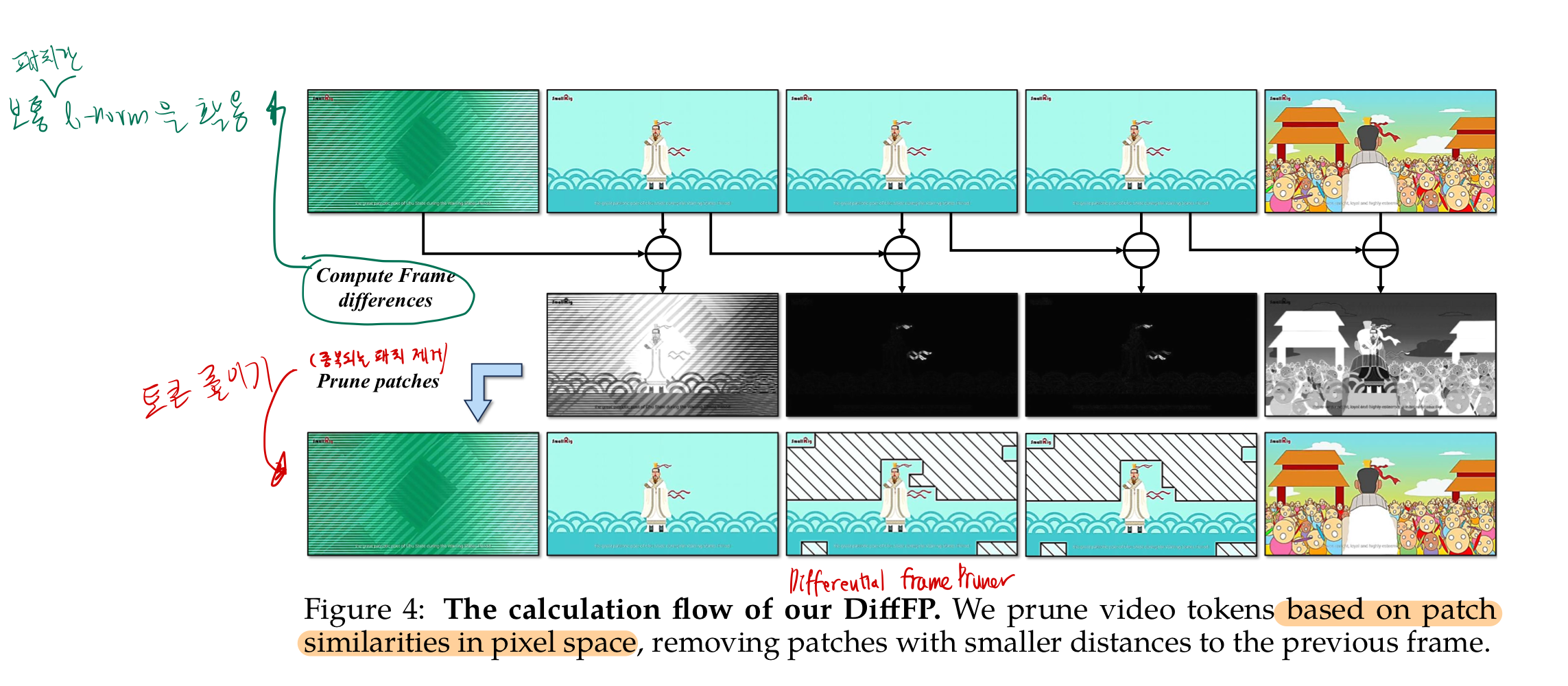
- 비디오 input이 들어왔을 때, 각 이미지 patch token의 유사도(1-norm distance기반)를 비교하여, 유사한 토큰은 제거함으로써 token개수를 줄인다. (연산량/메모리 효율화)
- pixel space에서, 시간적으로 연속된 patches를 비교한다고 합니다.
- 시간 축 기준으로, 더 최신의 시간 token은 남기고, 더 과거의 유사한 token은 날립니다. (threshold 0.1)
3.3. 그 외 구조
- LLM에 대해서는, Qwen2.5 model을 썼음
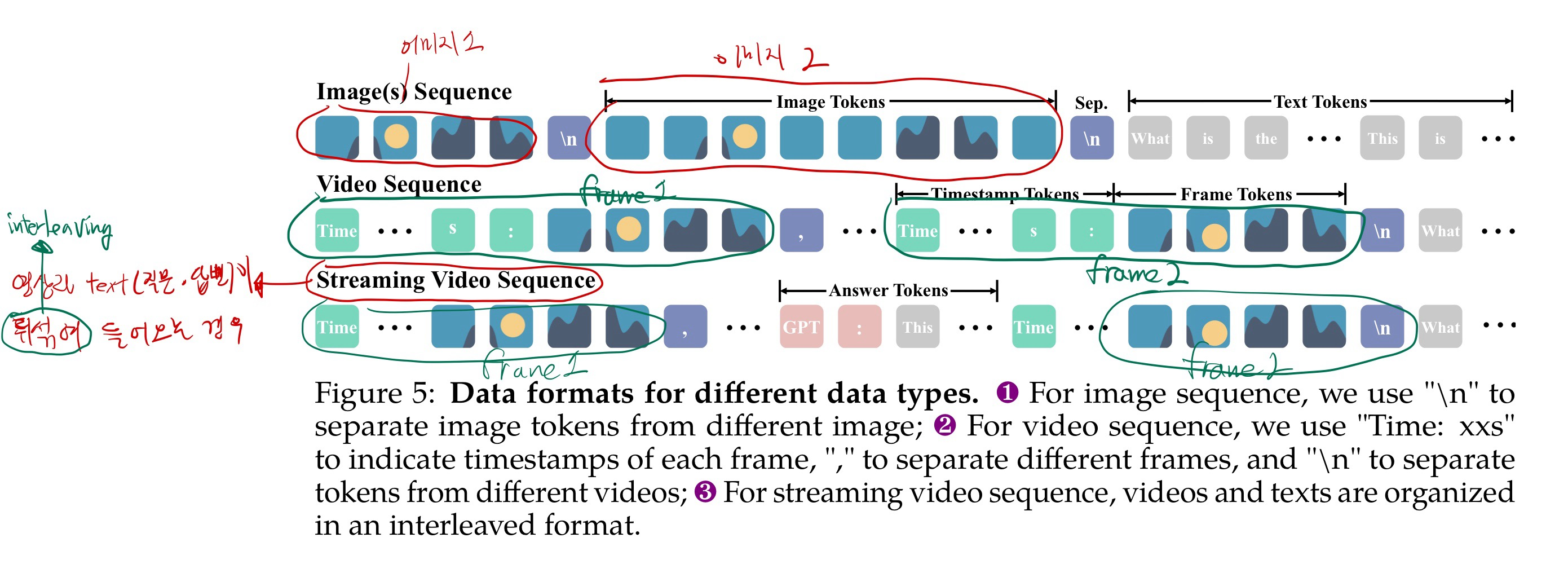
데이터 입력 포멧
4. Experiment 요약
- Vision Encoder Adaptation 단계에서:
- VideoLLaMA3-2B: 비전 인코더는 SigLIP의 사전 학습 가중치, LLM은 Qwen2.5-2B 가중치로 초기화.
- VideoLLaMA3-7B: 비전 인코더는 VideoLLaMA3-2B에서 파인튜닝한 SigLIP, LLM은 Qwen2.5-7B 가중치로 초기화.
- 프로젝터는 GELU 활성화 함수를 갖는
2층 MLP로 구현 - Differential frame pruner가 적용되어, 유사한 시각 토큰(임계값 0.1)을 제거하며,
비전 토큰은 2배로 다운샘플링됨. 영상 데이터는 FFmpeg를 이용해 1초당 1 프레임으로 샘플링하며,최대 180 프레임을 사용하여 대부분의 3분 미만 영상을 수용함.- 비디오 기반 평가에서는
일반 비디오 이해,장시간 비디오 이해,시간적 추론등 다양한 벤치마크를 통해 모델 성능을 검증함. - Ablation Study에서는 CLIP, DFN, SigLIP 세 가지 비전 인코더를 비교한 결과, 특히 텍스트가 포함된 세밀한 이해 작업에서 SigLIP이 우수함.
- 이에 따라 SigLIP이 기본 비전 인코더로 선택되고, 동적 해상도 입력에 적응하도록 추가 조정됨.
Appendix
A. 왜 internVL로 captioning?
아래는 두 논문이 re-captioning에 활용될 수 있는 구체적인 이유와 효과를 상세히 설명한 내용입니다.
1. InternVL ([31])
주요 특징 및 구체적 근거
- 멀티모달 정렬 강화:
InternVL 논문에서는 이미지와 텍스트 간의 정렬(Alignment)을 강화하기 위해, 대규모 이미지–텍스트 쌍을 대상으로 한 대비 학습(contrastive learning) 및 혼합 정렬 손실(mixed alignment losses)을 도입합니다.- 구체적 요소:
- 정렬 손실 설계: 이미지와 텍스트의 임베딩 공간을 정밀하게 맞추기 위한 새로운 손실 함수를 제안하여, 두 모달리티 간의 상호 연관성을 효과적으로 학습합니다.
- 동적 토큰 처리: 입력 이미지의 다양한 크기와 복잡성을 반영하기 위해, 동적 토큰화(dynamic tokenization) 기법을 적용하여, 이미지 내의 중요한 영역을 유연하게 표현합니다.
- 효과:
이러한 설계 덕분에 InternVL은 이미지의 핵심 내용과 세부 정보를 효과적으로 포착하여, 생성되는 캡션이 이미지의 실제 내용을 잘 반영하도록 도와줍니다.
- 구체적 요소:
2. [53] 논문
주요 특징 및 구체적 근거
- 모델 스케일 업과 정밀도 향상:
[53] 논문에서는 모델의 크기를 늘릴 때 발생할 수 있는 정보 손실과 학습 불안정을 최소화하기 위한 다양한 전략을 제시합니다.- 구체적 요소:
- 고급 정규화 및 최적화 기법: 모델의 각 레이어에서 파라미터 분포를 효과적으로 조정하고, 정규화 기법을 도입함으로써, 스케일이 큰 모델에서도 안정적 학습과 높은 표현 정밀도를 보장합니다.
- 아키텍처 확장 전략: 모델의 폭(width)과 깊이(depth)를 체계적으로 확장하면서, 세밀한 이미지 특징을 포착할 수 있도록 설계된 아키텍처 개선 방안이 포함되어 있습니다.
- 효과:
이러한 접근 방식은 더 큰 모델이 이미지의 미세한 시각적 특징까지 놓치지 않고 반영할 수 있게 해주며, 결과적으로 캡션 생성 시 풍부하고 정교한 설명을 가능하게 합니다.
- 구체적 요소:
Re-captioning에서의 활용 및 기대 효과
-
왜 선택했는가?
- InternVL ([31]): 이미지와 텍스트의 정렬을 극대화하는 정렬 손실 및 동적 토큰 처리 기법 덕분에, 간결하면서도 핵심을 잘 반영하는 짧은 캡션(VL3-Syn7M-short)을 생성하는 데 적합합니다.
- [53] 논문: 모델 스케일 업과 정밀도 향상 전략을 통해, 이미지의 세부 정보와 복잡한 내용을 놓치지 않고 상세하게 서술할 수 있는 캡션(VL3-Syn7M-detailed)을 생성하는 데 효과적입니다.
-
캡션 품질에 미치는 효과:
- 두 모델을 함께 사용하면, 학습 단계에서 요구되는 다양한 정보 수준(간단 요약과 세밀한 설명)을 모두 포괄할 수 있어, 멀티모달 모델이 보다 풍부한 시각적 정보를 학습할 수 있습니다.
- 이로 인해, 최종적으로 이미지 및 비디오 이해, 그리고 관련 다운스트림 태스크(예: 질문-답변, 문서 이해 등)에서 모델의 성능과 범용성이 크게 향상될 것으로 기대됩니다.
이와 같이, InternVL의 정렬 강화 기법과 동적 토큰 처리, 그리고 [53] 논문의 스케일 업 및 정밀도 향상 전략이 결합됨으로써, re-captioning 단계에서 이미지의 전반적 내용과 세밀한 디테일 모두를 효과적으로 캡션할 수 있는 데이터셋을 구축할 수 있으며, 이는 VideoLLaMA3의 전반적인 멀티모달 이해 능력을 크게 강화하는 데 기여합니다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것