- https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Vinyals_Show_and_Tell_2015_CVPR_paper.pdf
- https://arxiv.org/pdf/2108.10904.pdf
- https://arxiv.org/pdf/2205.01917.pdf
- 해당 구조는 generative pretrain 방식으로 multimodal representation을 배우게 하는 구조
- 일반적인 비전과 multimodal 표현을 학습하기 위해 인코더-디코더 모델을 사용한 생성적 사전 학습(https://velog.io/@hsbc/Generative-Pre-training)을 탐구
- 생성적 접근 방식 (일명 captioner)은 세부적인 세분성(granularity)을 목표
- 모델이 y의 정확한 토큰화된 텍스트를 autoregressive하게 예측해야 한다.
- 사전 학습 중에 모델은 이미지를 인코더 입력에 넣고, 그 결과값을 text의 일부와 함께 디코더의 입력으로 넣어줍니다.
- 디코더는, 이미지에 대한 나머지 text 를 예측합니다.
- 표준 인코더-디코더 아키텍처에 따라 이미지 인코더는 latent 인코딩 능력 (ex. ViT나 ConvNets 사용)을 제공
- 텍스트 디코더는 forward autoregressive factorization 하에서 쌍을 이루는 텍스트 y의 조건부 likelihood를 최대화하는 방법을 학습
- 디코더 출력에 Language Modeling (LM) loss (또는 PrefixLM)을 적용한다.
- 인코더-디코더는 계산을 병렬화하고 학습 효율성을 최대화하기 위해 teacher-forcing으로 학습된다.
- Teacher-Forcing
- Teacher-forcing은 모델 학습 과정에서 사용되는 기법으로, 모델이 다음 단어를 예측할 때 실제 이전 단어들(즉,
정답 시퀀스)을 입력으로 사용하는 방식 - 이 방법은 모델이 잘못된 예측을 할 경우, 그 오류가 후속 단어의 예측으로 전파되는 것을 방지하고,
- 정답 라벨링 토큰들을 학습 Input으로 사용하기 때문에 batch 연산이 가능해져 학습을 더 빠르고 효율적으로 만듦
- 하지만, 학습 시간과 실제 사용 시간의 차이로 인해, 모델이 학습 중에는 보지 못한 오류를 처리하는 데 어려움을 겪을 수 있습니다.
- Teacher-forcing은 모델 학습 과정에서 사용되는 기법으로, 모델이 다음 단어를 예측할 때 실제 이전 단어들(즉,
- Teacher-Forcing
- 장점
- 다운스트림 task의 경우 디코더 출력을 multimodal 이해 task를 위한 공동 표현으로 사용할 수 있다.
- 단점
- 특정 이미지와 그에 대응하는 텍스트 사이의 정밀한 매칭을 자동으로 식별하는 데는 비효율적일 수 있기 때문에, crossmodal alignment task에 대한 실현 가능성과 효율성이 떨어진다.
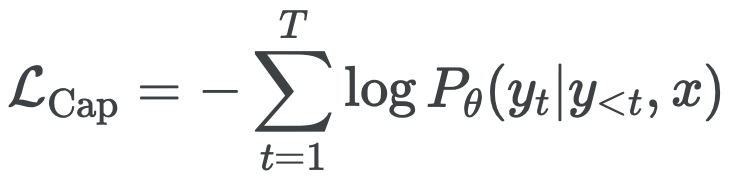


모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것