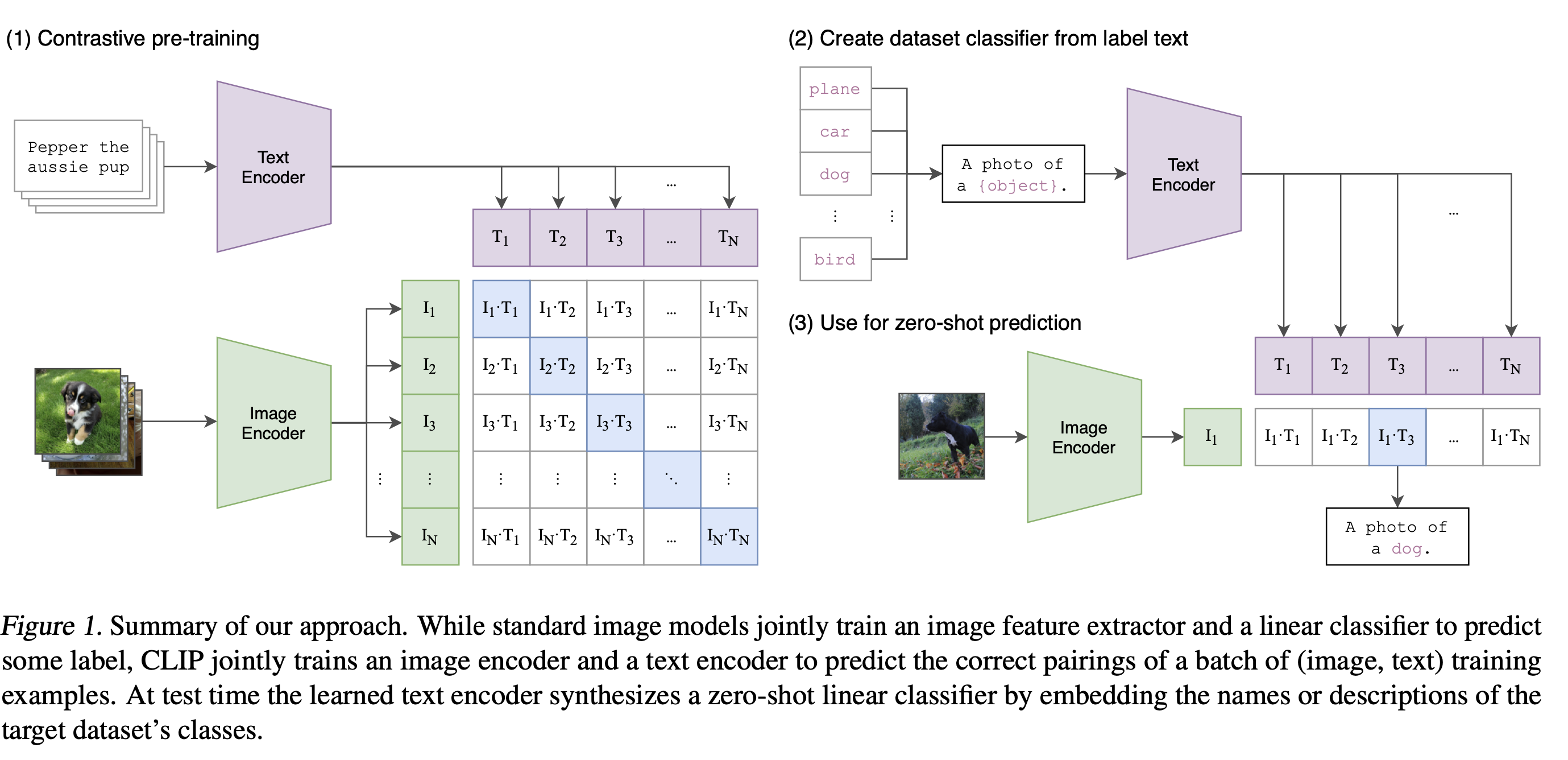
- CLIP(http://proceedings.mlr.press/v139/radford21a/radford21a.pdf), ALIGN, Florence 논문들
- 해당 모델들은 image encoder와 text encoder가 있고, web에서 수집한 거대 image-text 데이터셋(noisy한 이미지-텍스트 설명을 활용)을 사용해 image feature, text feature를 뽑아냄
- 학습 가능한 텍스트 타워를 도입하여 자유 형식 텍스트를 인코딩
- 이미지와 쌍을 이루는 텍스트를, 샘플 배치의 다른 텍스트와 대조하여 공동으로 최적화
- 그리고 같은 pair의 image feature와 text feature를 최대한 유사하게 만드는 방식으로 모델을 학습
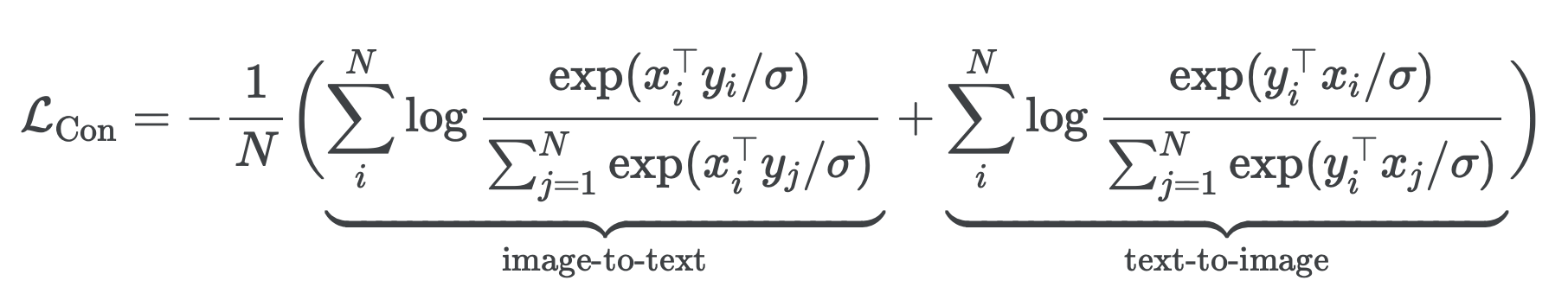
- 여기서 xi와 yj는 i번째 쌍에 있는 이미지와 j번째 쌍에 있는 텍스트의 정규화된 임베딩
- N 은 배치 크기
- 이렇게 되면 image feature와 text feature는 embedding space를 공유
- 이러한 특징을 통해 image-text retrieval(https://velog.io/@hsbc/이미지-도메인-task-정리), zero-shot image classification이 가능해집니다. (crossmodal alignment 능력)
- 이미지 latent vector와 가까운 거리에 있는 text latent vector을 찾아, 그 text로 분류한다.
- 단점
- 이러한 모델은 융합된 이미지와 텍스트 표현을 학습하기 위한 공동 구성 요소가 없기 때문에,
- visual question answering (VQA) (https://velog.io/@hsbc/이미지-도메인-task-정리)과 같은 비전-언어 공동 이해 task에 직접 적용할 수 없다.
- multi-modal input task에 적용하기 어렵다.
- 이러한 모델은 융합된 이미지와 텍스트 표현을 학습하기 위한 공동 구성 요소가 없기 때문에,

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것