- TODO: https://herbwood.tistory.com/26 읽고 공부해보기
1. transformer VS CNN
1.1. transformer > CNN 인 부분
1.1.1. 더 긴 범위의 의미 파악
- Transformer는 시퀀스 데이터를 처리하는 뛰어난 능력을 가지고 있어, 이미지의 다양한 부분을 연결하여 전체적인 의미를 파악하는데 더 용이
1.1.2. 멀리 떨어진 관계 파악
- CNN은 일반적으로 가까이 있는 픽셀들 간의 관계를 파악하는 데 뛰어납니다.
- 반면에 Transformer는 멀리 떨어진 객체 간의 관계도 파악할 수 있어서, 넓은 영역에서의 객체 탐지와 관련된 문제를 더 잘 다룰 수 있음.
- 객체 탐지에서
먼 객체 간의 관계나 컨텍스트를 더 잘 이해할 수 있는 장점
1.1.3 전역적인 정보 고려
- CNN은 주로 작은 영역의 정보를 처리하고 그것을 조합해 전체 이미지의 의미를 이해
- 반면에 Transformer는 전역적인 정보를 고려하기 때문에, 전체 이미지에서 중요한 패턴이나 객체들의 분포를 더 잘 파악할 수 있습니다.
1.1.4. 객체의 순서 고려를 알아서 해줌
- 객체들의 위치나 순서는 중요한 정보가 될 수 있습니다.
- 예를 들어, 사진 속에 사람이 우산을 들고 걷는 모습이 있다면, 사람의 위치와 우산의 위치, 그리고 이 둘 사이의 관계가 중요한 정보가 됩니다.
CNN은 이미지의 공간적인 구조를 인식하는 데 강점이 있지만, 객체의 순서를 고려하지 않습니다.CNN은 이미지를 작은 영역으로 분할하여 처리합니다.이 작은 영역 안에서는 픽셀들 간의 관계를 잘 파악할 수 있지만, 이 작은 영역들 간의 관계나 객체들 간의 상대적인 위치와 순서를 고려하기 어렵습니다.(layer이 깊어질수록, 그냥 뭉쳐짐)예를 들어, 한 작은 영역 안에서는 눈과 입의 관계를 파악할 수 있지만, 얼굴 내의 여러 영역 간의 관계를 파악하기는 어려울 수 있습니다.- CNN은 이미지의 작은 영역을 독립적으로 처리하므로, 객체들 간의 순서 정보를 고려하지 않습니다.
하지만 Transformer는 순서를 고려하는 자연어 처리 분야에서 주로 사용되며, 객체 탐지에서도 객체들 간의 순서 정보를 놓치지 않고 활용할 수 있습니다.(Vision Transformer 생각해봐라.)예를 들어, 사람과 우산이 함께 등장하면 Transformer는 이들이 서로 어떤 관계로 묶일 수 있는지 파악하여 순서 정보를 활용할 수 있습니다.
1.1.5. 스케일 불변성
- Transformer는
입력 데이터의 크기나 해상도에 상관없이 다양한 크기의 객체를 감지하고 인식할 수 있는스케일 불변성을 가지고 있습니다.- Transformer가 입력 데이터를 작은 부분 단위로 분해하고, 이들의 상호 작용을 계산함으로써 이루어집니다.
- 즉, Transformer는 객체의 크기에 덜 민감하게 작동하며, 다양한 크기의 객체들을 효과적으로 처리할 수 있습니다.
- 이는 다양한 크기의 객체들을 효과적으로 처리하는데 도움이 됩니다.
1.2. transformer < CNN 인 부분
1.2.1 연산 복잡성 증가 / 메모리 사용량 증가 / 모델 복잡성
- Transformer는 대규모의 연산을 필요로 하기 때문에, CNN에 비해 더 많은 계산이 필요
- Transformer는 각 위치마다 다른 위치와의 상호 작용을 계산해야 하므로, 입력 데이터의 길이에 따라 메모리 사용량이 크게 증가할 수 있음
- 이로 인해 모델을 훈련하고 실행하는 데 더 많은 시간과 컴퓨팅 자원이 필요할 수 있음
- 입력 데이터(n)가 길어지면,
- query, key, value 를 생성하는데 필요한 연산이, 선형적으로 증가함.
- query, key, value 의 크기가 커져, 메모리 사용량이, 선형적으로 증가함
- attention energy를 만드는데 필요한 연산이, n_i^2 -> n_i+1^2 로 늘어남
1.2.2 공간적인 구조 파악 어려움
- CNN은
이미지의 공간적인 구조를 잘 파악하는 데 능숙한 반면, Transformer는 주로순서에 민감한 시퀀스 데이터를 다루는 데 강점
1.2.3 대규모 데이터 필요
- Transformer 모델은 많은 양의 데이터를 필요로 함
- 모델이 언어나 이미지의 다양한 패턴과 관계를 이해하기 위해서는 이에 대한 충분한 학습 데이터가 필요하며, 이를 구성하는 것이 어려울 수 있습니다.
2. 기존 Object detecter의 문제점
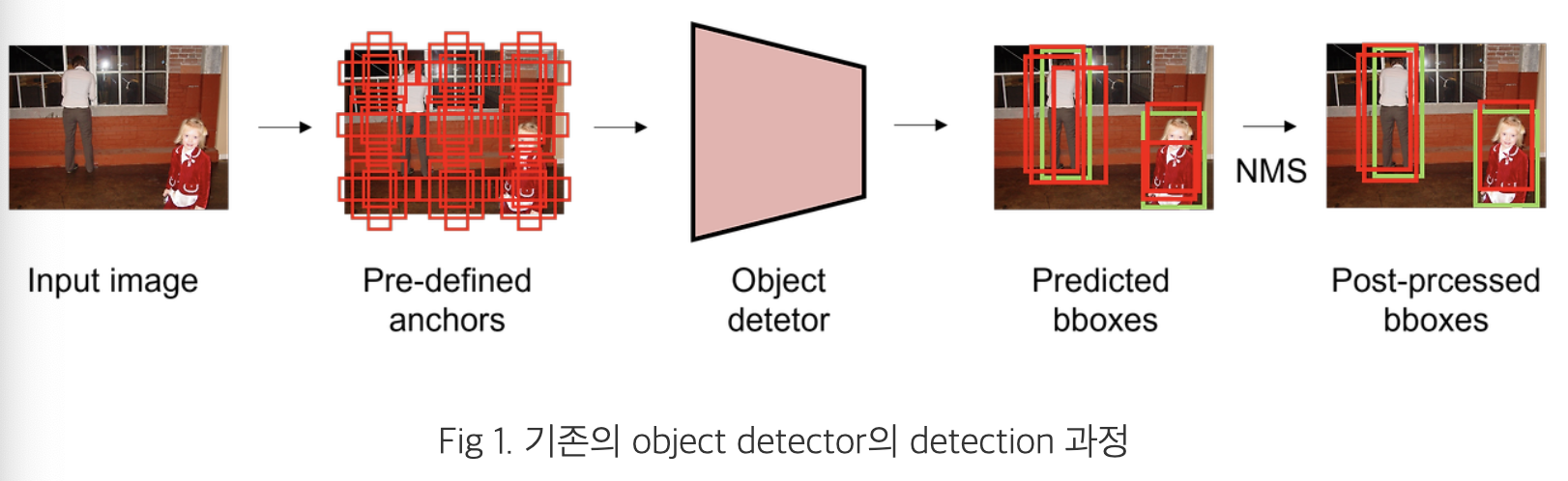
- pre-defined anchor를 사용합니다.
- 이미지 내 고정된 지점마다 다양한 scale, aspect ratio를 가진 anchor를 생성
- 이후 anchor를 기반으로 예측 bounding box를 생성
- Matching 시,
- ground truth와의 IoU 값이 특정 threshold 이상일 경우 positive sample으로,
- 이하일 경우 negative sample로 간주
- positive sample에 대해서만 bounding box regression을 수행
- 이처럼 threshold를 기준으로 독립적으로 prediction을 수행하기 때문에, 하나의 ground truth에 다수의 bounding box가 matching
- 이로 인해 예측한 bounding box와 ground truth의 관계가 many-to-one이 됩니다.
- 이러한 near-duplicate한 예측, redundant한 예측을 제거하기 위해
NMS(Non Maximum Suppression)과 같은 post-processing 과정이 반드시 필요
2. DETR의 장점
- 여러 크기의 직접 정의한 hand-crafted anchor를 사용하지 않습니다.
- object detection을
direct set prediction으로 간주하고 해결- 일반적인 객체 탐지 모델에서는,
- 사진 속에 개, 자동차, 나무 등 여러 객체가 있을 때,
- 모델은 개가 있는 곳의 위치와 클래스, 자동차가 있는 곳의 위치와 클래스를 각각 예측
- TODO: 정확히 이해 못했음.
- 객체를 묶음으로 예측하는 모델은 한 번에 "이미지 전체에 개, 자동차, 나무가 어떤 위치에 있을지"에 대한 정보를 예측 (DETR)
- 이 정보는 세 개의 객체가 각각 어디에 위치해 있는지를 동시에 고려하여 예측하는 것이죠.
- 이때 각 묶음은 여러 객체들의 위치와 클래스를 함께 표현하며, 이렇게 함께 예측하면 객체들 사이의 관계나 상황을 더 잘 이해할 수 있습니다.
- Non-maximum Suppression(NMS)를 사용하지 않음!
- NMS란?
- 객체 탐지에서 예측된 객체들 중에 겹치는 부분을 다듬는 기술
- 객체 탐지 모델은 종종 같은 객체를 여러 번 예측할 수 있음
- 예를 들어, 같은 자동차를 두 번 예측해서 하나는 왼쪽으로 살짝 겹치고 하나는 오른쪽으로 살짝 겹치는 상황이 될 수 있음
- NMS는 이런 겹치는 예측 중에서 가장 확률이 높은 예측을 선택하고, 나머지 겹치는 예측들을 제거하는 방법
- DETR에선 NMS 안씀
- DETR은 객체를 묶음으로 예측하는 방식을 사용 (1-1 매칭)
- 이것은 모든 객체를 개별적으로 예측하는 것이 아니라,
- 여러 개의 객체를 함께 예측함으로써 겹치는 문제를 자연스럽게 처리하려는 아이디어
- 예를 들어, 한 묶음에 자동차와 나무가 함께 예측된다면, DETR은 자동차와 나무의 위치를 서로 겹치지 않도록 조절하여 예측하려고 합니다.
- 그래서 겹치는 예측을 피할 수 있습니다.
- NMS란?
- 일반적인 객체 탐지 모델에서는,
3. DETR 논문 설명
- Vision transformer Transformer encoder decoder
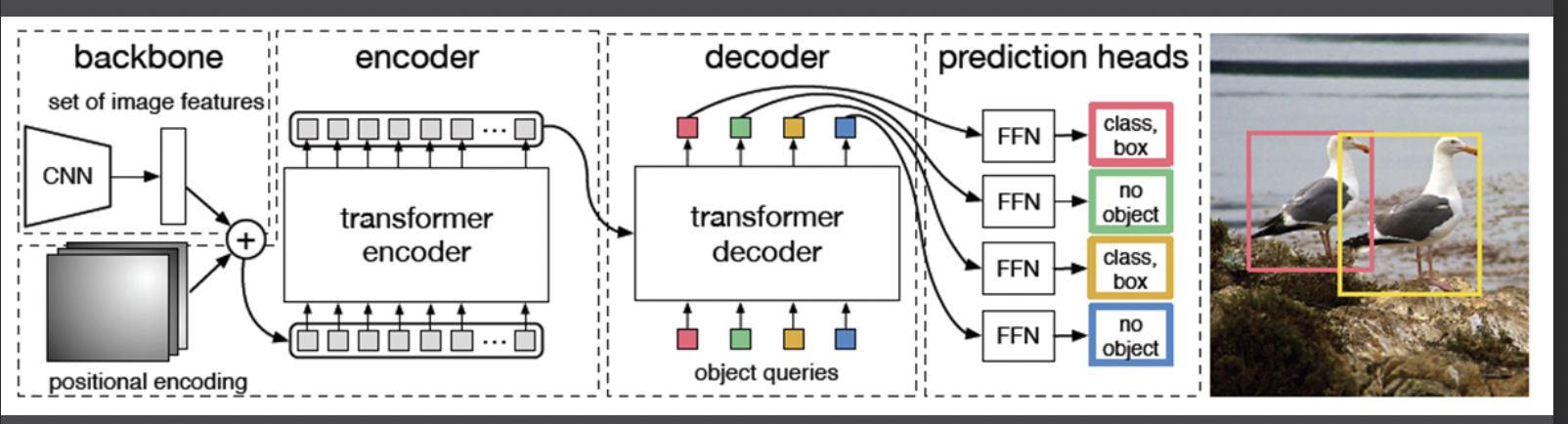
3.1. Transformer for NLP task vs DETR Transformer
- Transformer는 decoder에서 첫 번째 attention 연산 시 masked multi-head attention을 수행하는 반면,
- (Transformer는 auto-regressive하게 다음 token을 예측)
- DETR은 multi-head self-attention을 수행합니다.
- DETR은 입력된 이미지에 동시에 모든 객체의 위치를 예측하기 때문에 별도의 masking 과정을 필요로 하지 않음
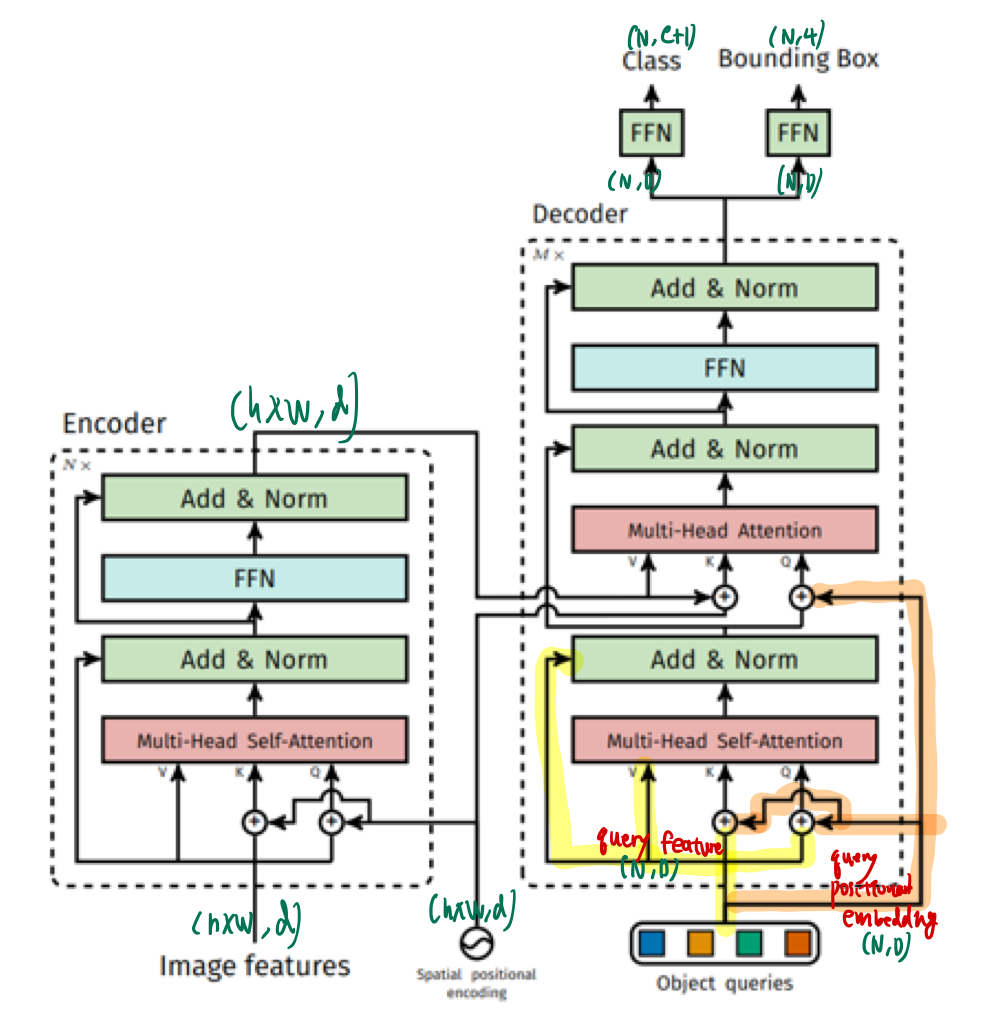
3.2. Encoder
- DETR은 원본이미지(
3, H0, W0)에서 CNN backbone으로 feature map을 추출(C, H, W)한 이후,- C = 2048
- H = H0/32
- W = W0/32
- 1x1 convolution layer를 거쳐 차원을 줄인 다음,
- spatial dimension을 flatten하여 encoder에 입력
3.2.1. Positional Encoding
-
-

-
기존 Transformer와 positional encoding에서 차이가 있습니다.
-
Transformer는 입력 embedding의 순서와 상관 없이 동일한 값을 출력하는 permutation invariant한 성질을 가졌기 때문에 positional encoding을 더해줍니다.
-
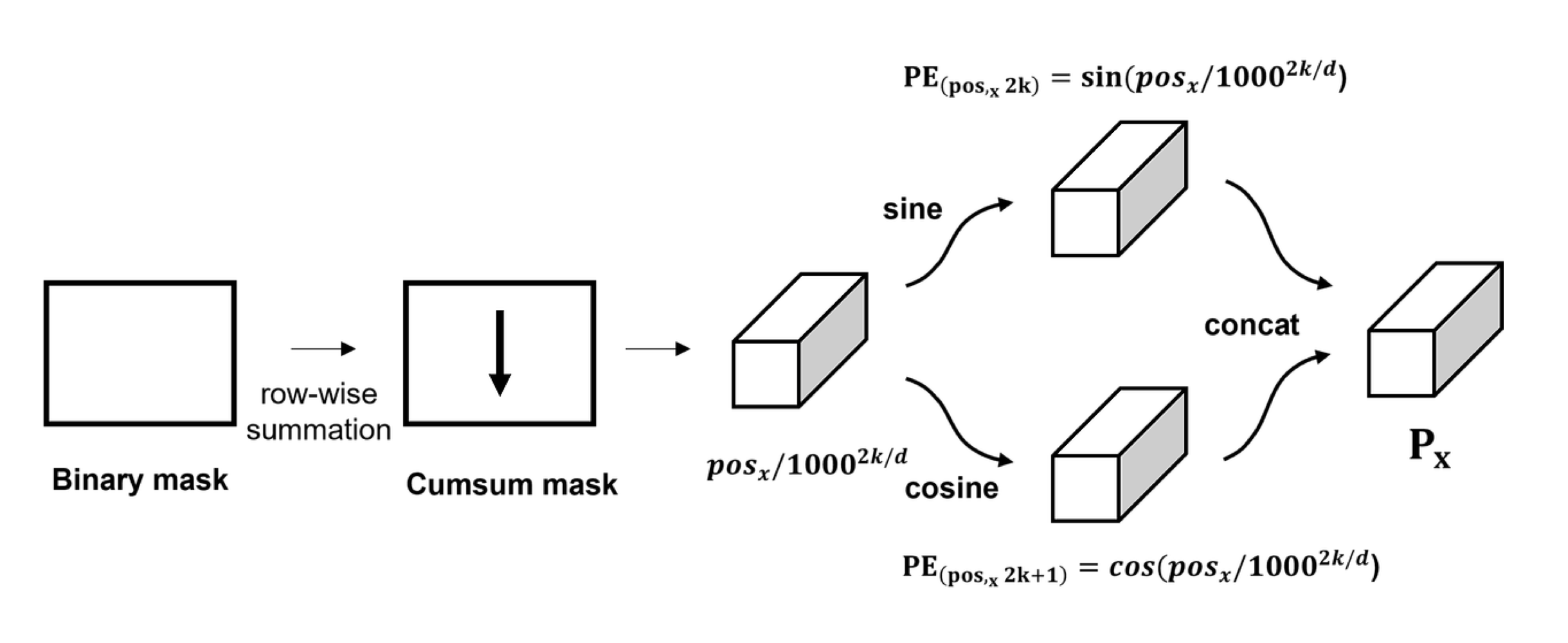
DETR은 x, y axis가 있는 2D 크기의 feature map을 입력받기 때문에
- 기존의 positional encoding을 2D 차원으로 일반화시켜
- spatial positional encoding을 수행합니다.
- 입력값의 차원이 d라고 할 때 x, y 차원에 대하여, row-wise, column wise로 d/2 크기로 sine, cosine 함수를 적용합니다.
- 이후 channel-wise하게 concat하여 d channel의 spatial positional encoding을 얻은 후 입력값에 더해줍니다.
3.2.2. Encoder output embedding
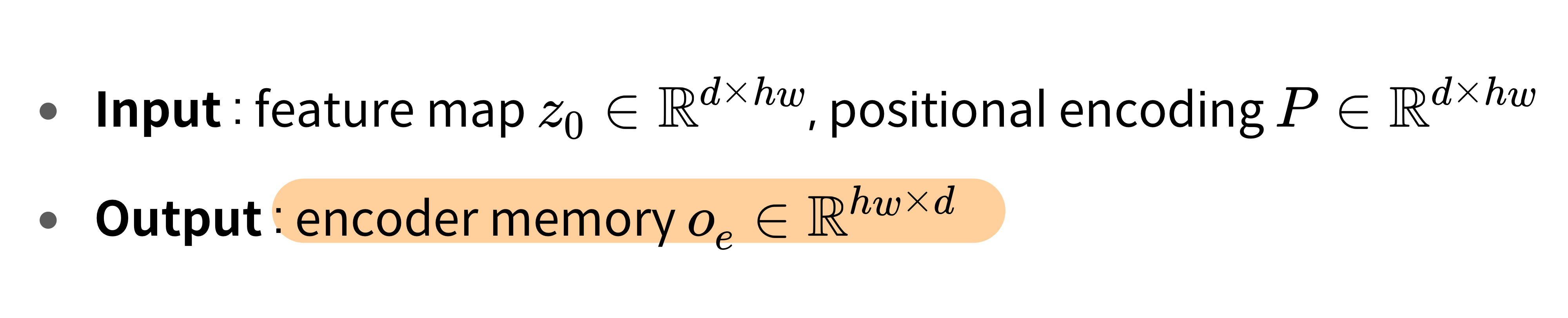
3.3. Decoder
3.3.1. query

- object query(
N*d)는 2개로 구성- object query feature (
N*d) - object query positional embedding (
N*d)
- object query feature (
object query feature- decoder에 initial input으로 사용되어, decoder layer를 거치면서 학습됩니다.
- 학습 시작 시 0으로 초기화(zero-initialized)
query positional embedding- decoder layer에서 attention 연산 시 모든 query feature에 더해집니다.
- learnable parameter
3.3.2. Decoder output embedding
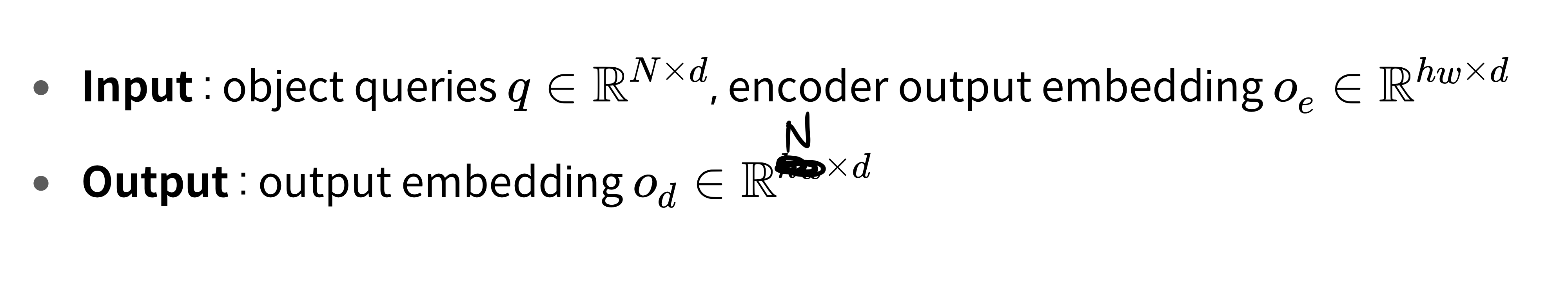
3.3.3 Class head / Bounding box head


3.4. Set prediction loss
3.4.1. Find Optimal Matching
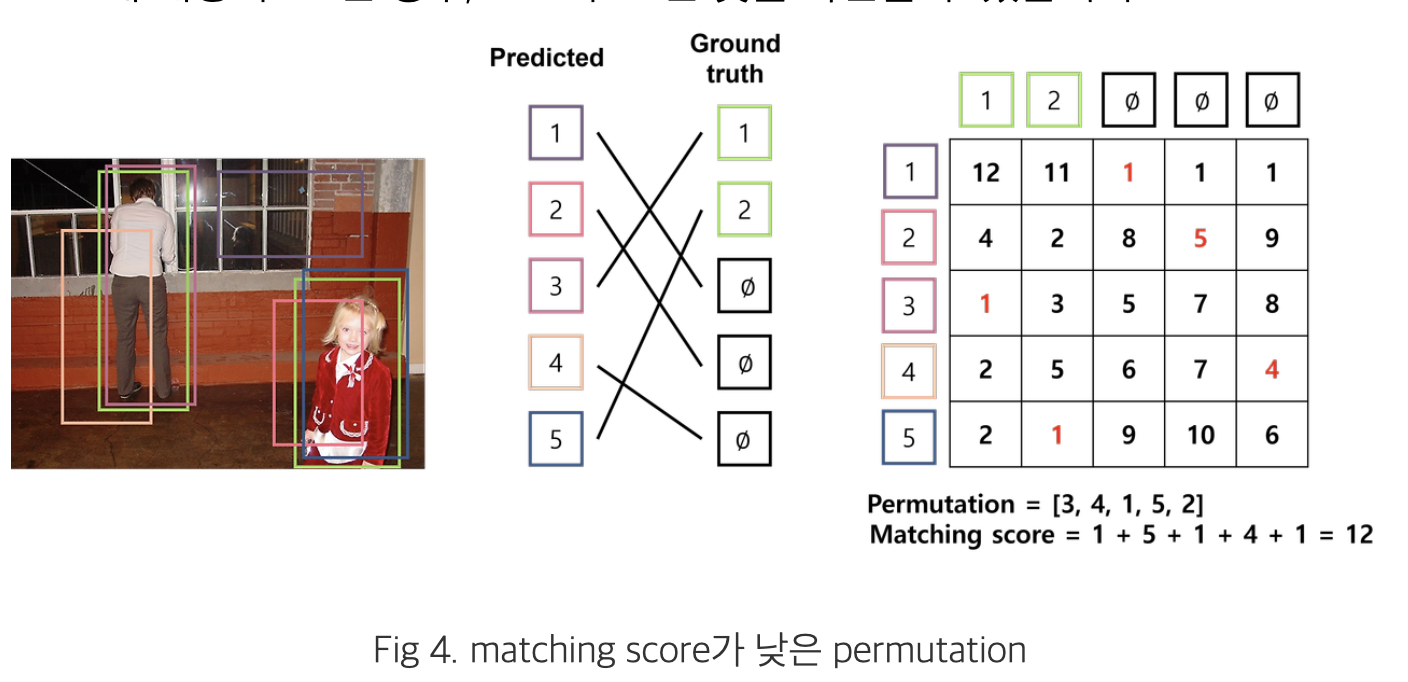
-
bi-partite matching
- bounding box 와 ground truth 간 1대 1 매칭을 해주는 과정이 추가됨 (아래에 자세히 설명되어 있음)
- 두 집합 사이의 일대일 대응 시 가장 비용이 적게 드는 bipartite matching(이분 매칭)을 찾기 위해
- Hungarian Algorithm 을 사용
- cost에 대한 행렬을 입력 받아, matching cost가 최소인 permutation을 출력합니다.
- https://gazelle-and-cs.tistory.com/29
- Hungarian Algorithm 을 사용
-
-
고정된 크기의 N 개의 prediction만을 수행함으로써, 수많은 anchor를 생성하는 과정을 우회합니다.
-
이 때 N은 일반적으로 이미지 내 존재하는 객체의 수보다 훨씬 더 큰 수로 지정
-

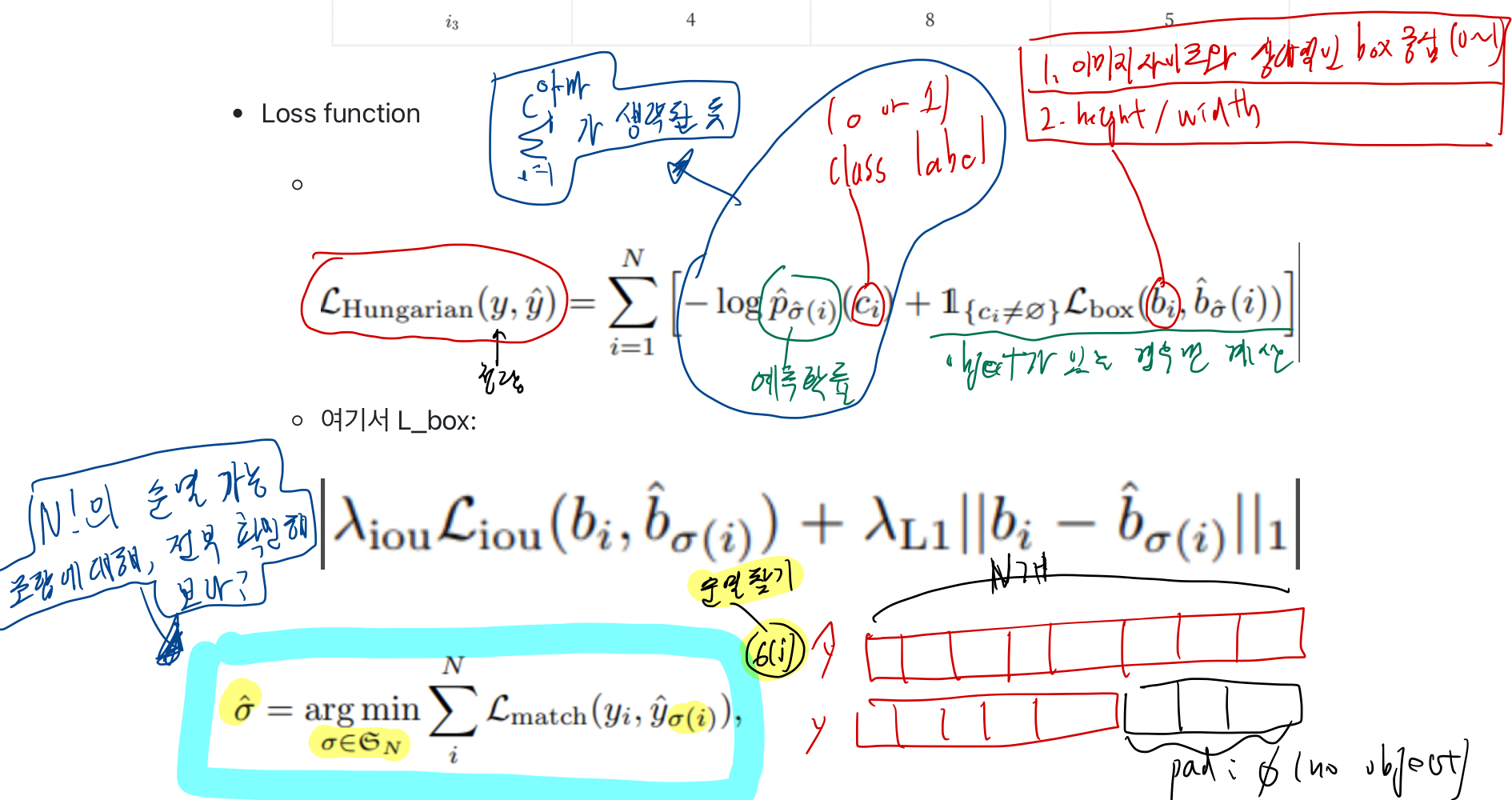
3.4.2. Compute Hungarian Loss
- 앞선 과정을 통해 matching된 pair를 기반으로 loss function인 Hungarian loss를 계산

3.4.3. Bounding box loss
-
기존의 방법들은 anchor를 기반으로 bounding box prediction을 수행하기 때문에
- 예측하는 bounding box의 범위가 크게 벗어나지 않습니다.
-
반면 DETR은 어떠한 initial guess가 없이 bounding box를 예측하기 때문에 예측하는 값의 범주가 상대적으로 큽니다.
-
논문에서는, Bounding box loss
- l1 loss와 generalized IoU(GIoU) loss를 함께 사용
-
GIOU?
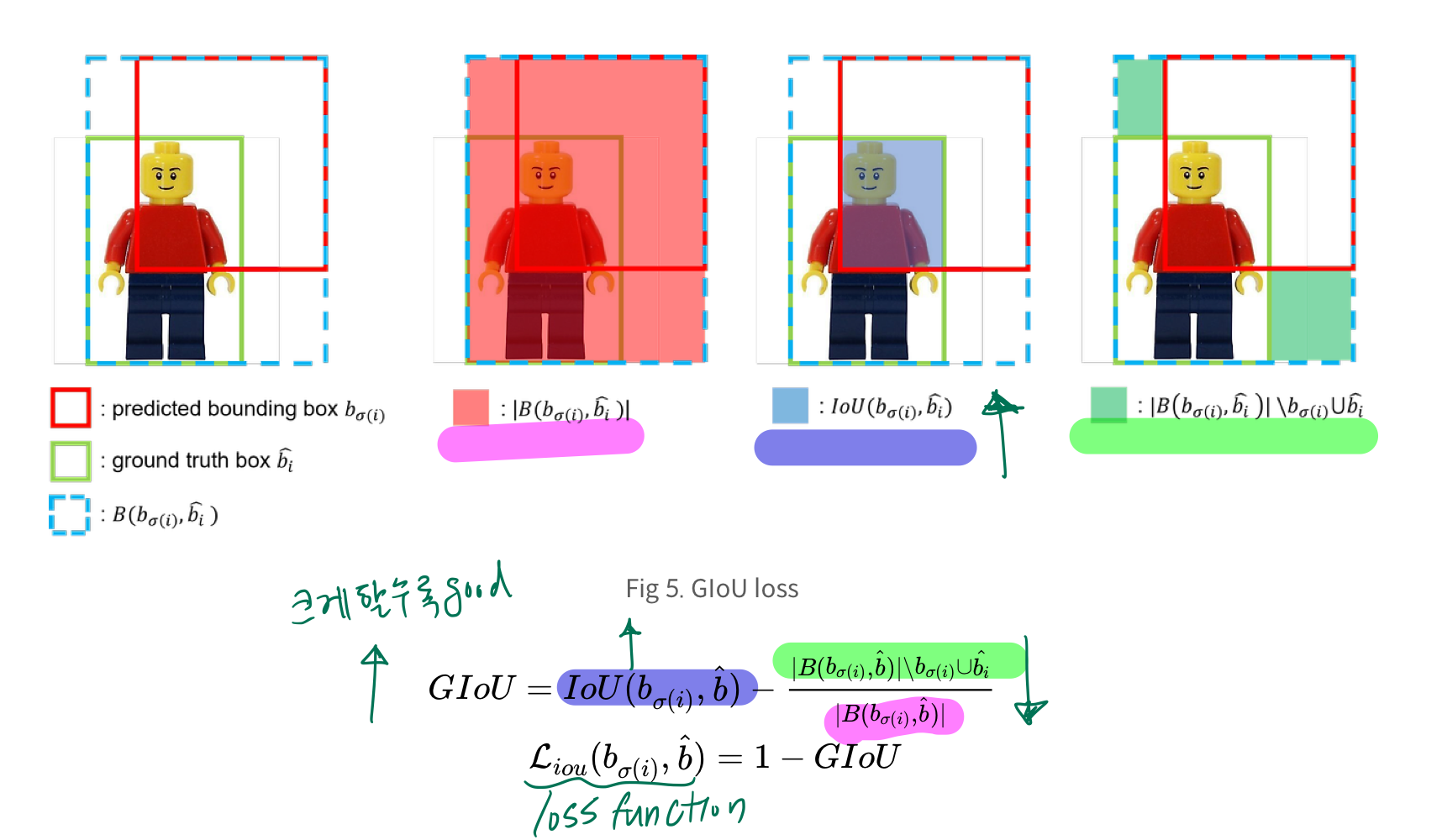
- GIoU는 -1~1 사이의 값을 가지며,
GIoU를 loss로 사용할 때 1−GIoU 형태로 사용하여 loss의 최대값은 2, 최소값은 0
-
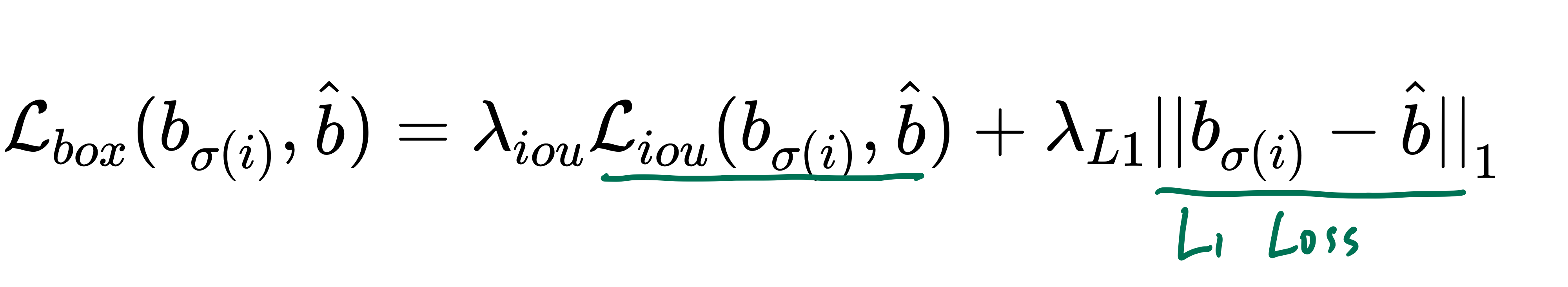
-

3.4.4. Auxiliary decoding losses
- 학습 시, 각 decoder layer마다 FFN을 추가하여 auxiliary loss를 구합니다.
- 이러한 보조적인 loss를 사용할 경우
- 모델이 각 class별로 올바른 수의 객체를 예측하도록 학습시키는데 도움을 준다고 합니다.
- 추가한 FFN은 서로 파라미터를 공유하며,
- FFN 입력 전에 사용하는 layer normalization layer도 공유합니다.
3.5. DETR의 장단점
-
장점
- NMS(Non-Maximum Suppression) 을 쓰지 않아도 됨
- 확실한 상자만 남기고, 중복된 경계 상자를 제거하는 기술
- TODO: NMS를 쓰는게 왜 단점인지? 공부해보기
- anchor generation을 사용하지 않아도 됨
- 가능한 객체의 위치나 크기를 다양한 aspect ratio로 사전에 정의하는 작업.
- NMS(Non-Maximum Suppression) 을 쓰지 않아도 됨
-
단점
- Decoder 깊게 해야만 성능 잘 나온다.
- 학습 시간이 오래 걸린다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것