0. reference
1. Introduction
- CNN아키텍처는 초기 2단계에서 1단계로 진화했으며 anchor-based 및 anchor-free 두 가지 detection 패러다임이 등장했다.
- 이러한 연구들은 detection 속도와 정확성 모두에서 상당한 진전을 이루었다.
- 기존 실시간 detector는 일반적으로 detection 속도와 정확도 사이의 합리적인 trade-off를 달성하는 CNN 기반 아키텍처를 채택
- 그러나 이러한 실시간 detector에는 일반적으로 후처리를 위해 NMS가 필요
- NMS: 최적화가 어렵고 충분히 견고하지 않아 detector의 inference 속도가 지연
- Transformer 기반 object detector(DETR)는 Non-Maximum Suppression(NMS)과 같은 다양한 수작업 구성 요소를 제거
- 그러나 DETR의 높은 계산 비용 문제는 효과적으로 해결되지 않았으며, 이로 인해 DETR의 실시간 적용이 불가.
- Deformable DETR처럼 멀티스케일 feature를 도입하면, 학습 수렴을 가속화하고 성능을 향상시키는 데 도움이 되지만,
인코더로 공급되는 시퀀스 길이가 크게 늘어남- 결과적으로 Transformer 인코더에서 높은 계산 비용이 발생
- 따라서 저자들은 실시간 object detection을 달성하기 위해, 원래 Transformer 인코더를 대체할 효율적인 하이브리드 인코더를 설계
- 멀티스케일 feature의
스케일 내 상호 작용과 스케일 간 융합을 분리함으로써, 인코더는 다양한 스케일의 feature들을 효율적으로 처리
- 멀티스케일 feature의
- 또한 디코더의 object query 초기화 방식이 detection 성능에 중요
학습 confidence loss 부분에 IoU 제약 조건을 제공하여, score가 높은 query만 살리고 나머지는 제거함으로써,- 디코더에 더 높은 품질의 초기 object query를 제공하는 IoU-aware query selection을 제안
- 또한 제안된 detector는,
재학습 없이 다양한 디코더 레이어를 사용하여 inference 속도의 유연한 조정을 지원
2. End-to-end Speed of Detectors
2.1. Analysis of NMS
- detector에서 출력된 중복되는 예측 상자를 제거하는 데 사용된다.
- NMS에는 score threshold와 IoU threshold라는 두 가지 hyperparameter가 필요하다.
- 특히, score threshold보다 낮은 점수를 갖는 예측 상자는 직접 필터링되며,
- 두 예측 상자의 IoU가 IoU threshold를 초과할 때마다 점수가 낮은 상자는 제거된다.
2.2. End-to-end Speed Benchmark
- 결과를 보면 NMS 후처리가 필요한 실시간 detector의 경우
- anchor-free detector가 anchor-based detector보다 동일한 정확도로 성능이 뛰어나며,
- 이는 anchor-free가 anchor-based보다 후처리 시간이 훨씬 덜 걸리기 때문이다.
- 이 현상의 이유는 anchor-based detector가 anchor-free detector보다 더 많은 예측 상자를 생성하기 때문이다.
- TODO: anchor-free VS anchor-based
- anchor-based :
- 미리 setting해놓은 anchor에서 category와 coordinates를 예측하는 방식.
- (anchor를 1:1, 1:2, 2:1과 같이 사전에 설계했기 때문에 해당 범위를 크게 벗어나는 물체를 detect해야 할 때 anchor가 아무 쓸모가 없거나 오히려 학습에 방해.
- dataset을 미리 파악하여 새로 anchor를 정의해야 하는데, 이는 번거롭고 적합한 anchor를 찾기 위해 hyperparameter search를 해야 한다는 것이 단점.)
- anchor-free :
- key point를 이용하여 object의 위치를 예측하는 keypoint-based 방법
- object의 중앙을 예측한 후 positive인 경우 object boundary의 거리를 예측하는 center-based 방법
- anchor-based :
- TODO: anchor-free VS anchor-based
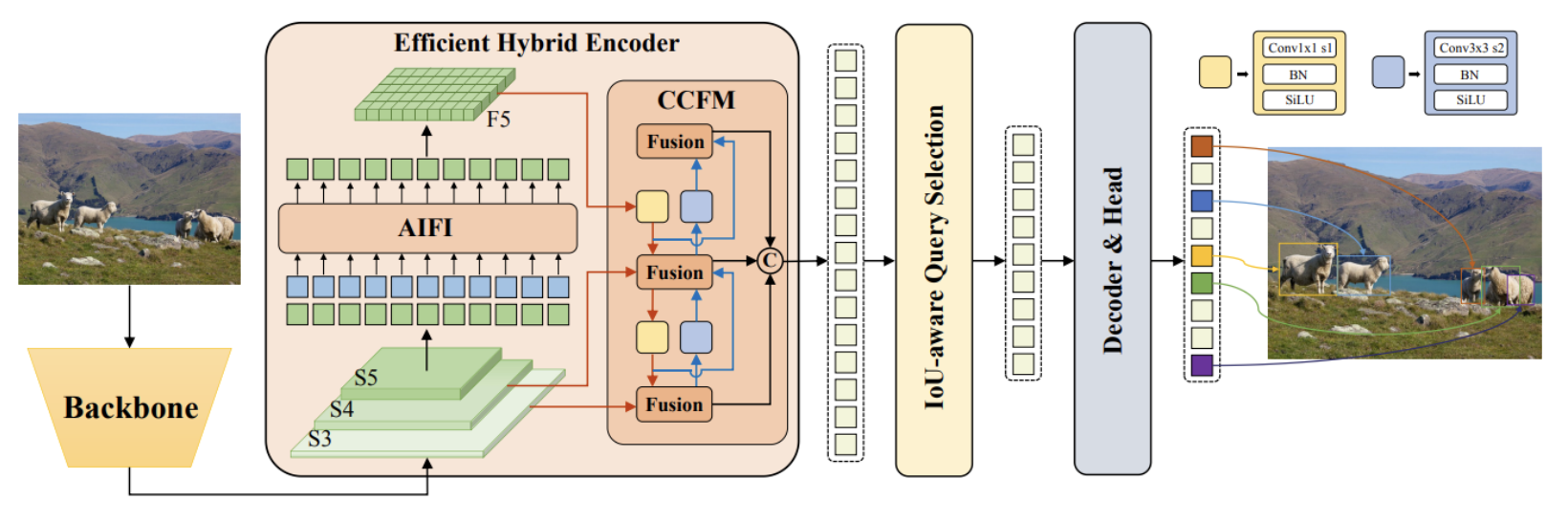
3. The Real-time DETR
3.1. Model Overview
-
-
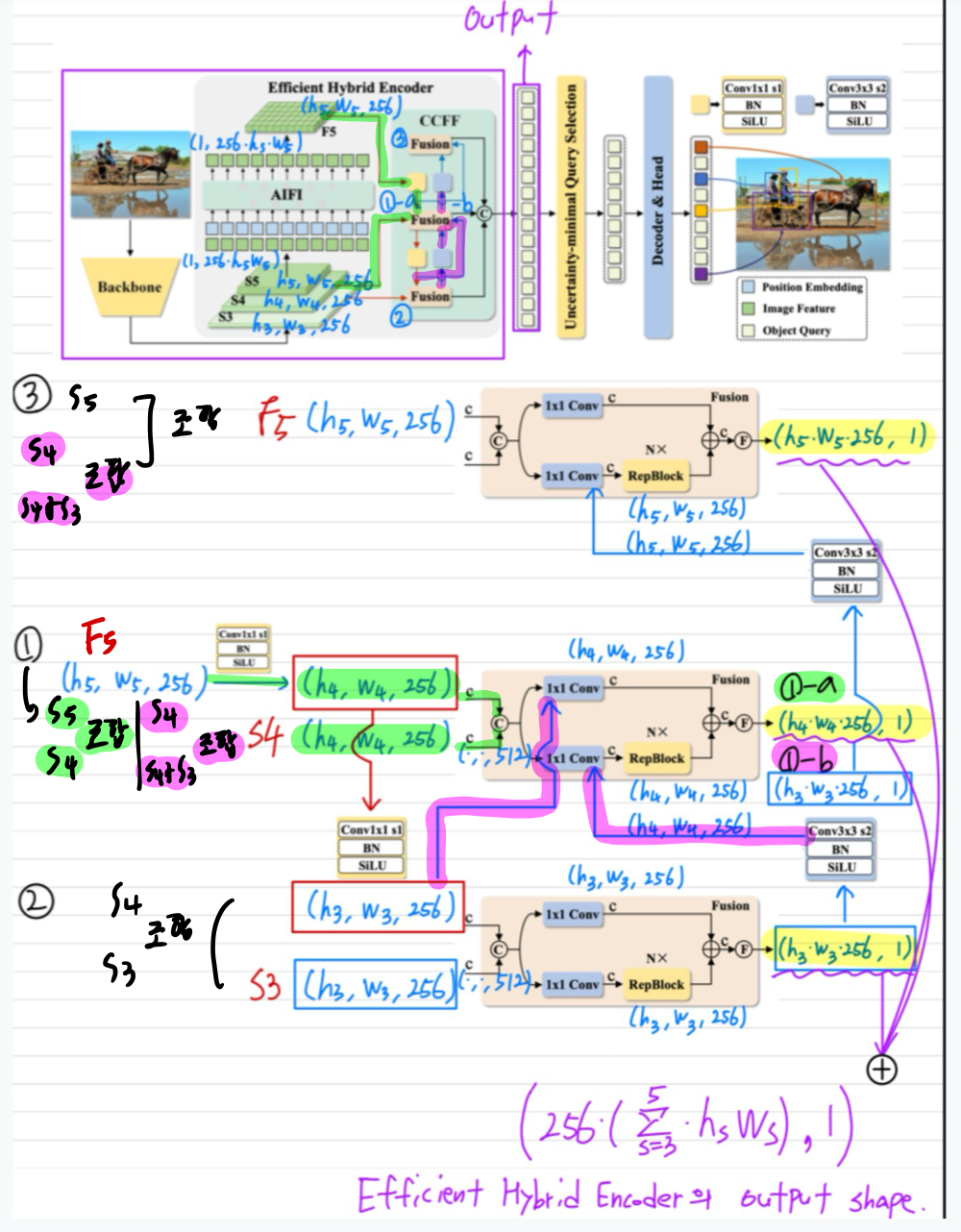
특히 백본의 마지막 세 단계의 출력 feature{S3,S4,S5}를 인코더에 대한 입력으로 활용
-
하이브리드 인코더는 스케일 내 상호 작용과 스케일 간 융합을 통해 멀티스케일 feature를 일련의 이미지 feature로 변환
-
이어서,
IoU-aware query selection은- 디코더에 대한 초기 object query 역할을 하기 위해
- 인코더 출력 시퀀스에서 고정된 개수의 이미지 feature를 선택하는 데 사용
3.2. Efficient Hybrid Encoder
3.2.1. Computational bottleneck analysis
- deformable attention 메커니즘을 제안
- 그러나 attention 메커니즘의 개선으로 계산 오버헤드가 줄어들었음에도 불구하고,
- 입력 시퀀스의 길이가 급격히 증가하면 여전히 인코더가 계산 병목 현상을 일으킴
- Deformable-DETR에서 인코더는 GFLOP의 49%를 차지하지만 AP의 11%만 기여
- TODO: GFLOP과 AP metric에 대해 공부
- 이러한 장애물을 극복하기 위해, (아래의 구체적 이유로) 여러 변형들을 설계
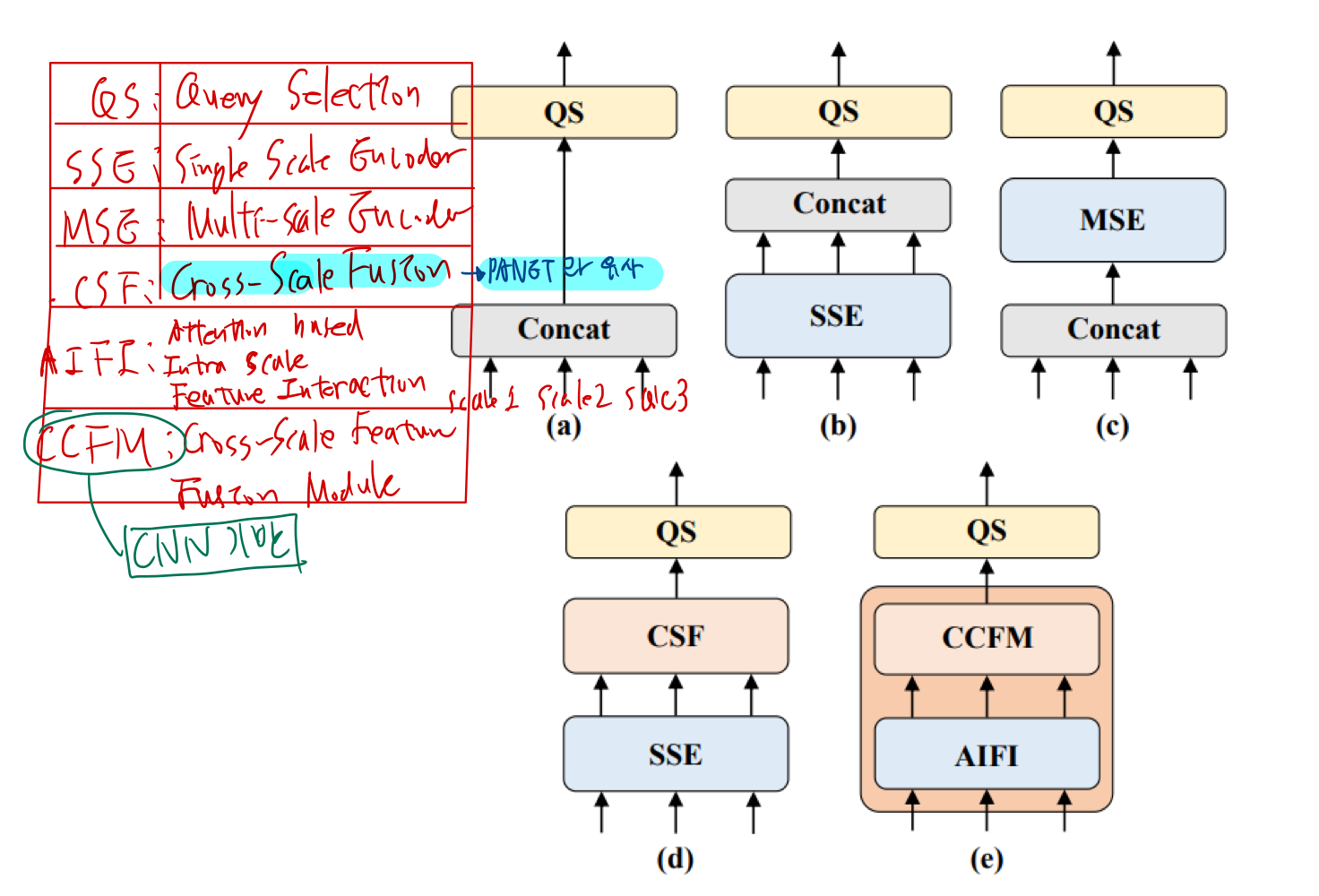
- 저자들은 멀티스케일 Transformer 인코더에 존재하는 계산 중복성을 분석하고
- 스케일 내 및 스케일 간 feature의 동시 상호 작용이 계산적으로 비효율적임을 증명하기 위해
이미지의 물체에 대한 풍부한 semantic 정보를 포함하는높은 수준의 feature(S5)는,낮은 수준의 feature(S3)에서 추출된다.- 직관적으로 concatenate된 멀티스케일 feature에 대해 feature 상호 작용을 수행하는 것은 중복된 계산이다.
- 변형들은 멀티스케일 feature 상호 작용을, 스케일 내 상호작용과 스케일 간 융합으로 분리하여 계산 비용을 크게 줄이면서 모델 정확도를 점차적으로 향상시킨다.
3.2.2. Hybrid design

- 여기서 Attn은 multi-head self-attention이고,
- Reshape은 feature의 모양을 S5와 동일하게 복원하는 연산이다 (Flatten의 역연산).
3.2.2.1. Attention-based Intrascale Feature Interaction(AIFI) 모듈
- AIFI는 S5(마지막 scale)에서 스케일 내 상호 작용만 수행하는 D를 기반으로 계산 중복성을 더욱 줄임
- 더 풍부한 semantic 개념을 가진
상위 수준 feature(S5)에 self-attention 연산을 적용하면, 이미지의 개념적 엔터티 간의 연결을 캡처할 수 있음 - 하위 수준 feature의 스케일 내 상호 작용은 아래의 이유로 불필요
- semantic 개념이 부족
- 상위 수준 feature의 상호 작용과 중복 및 혼동의 위험이 있으므로
- 저자들은 이 의견을 확인하기 위해 D의 S5에서 스케일 내 상호 작용만 수행
- 실험 결과 D에 비해 지연 시간을 크게 줄이지만(35% 더 빠름) 정확도는 향상된다(0.4% AP 더 높음).
- 이 결론은 실시간 detector 설계에 매우 중요하다.
3.2.2.2. CNN 기반 Cross-scale Feature-fusion Module(CCFM)
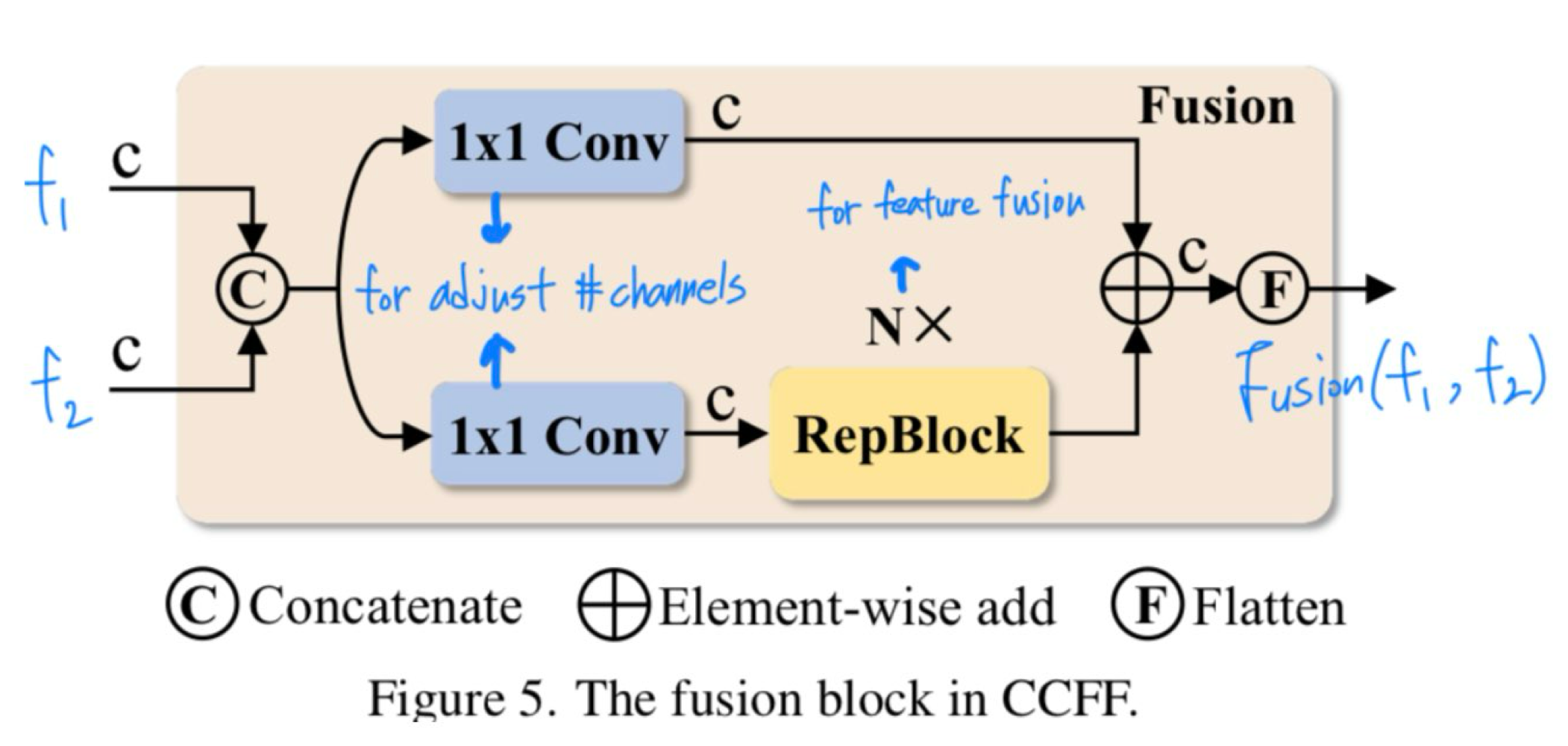
- CCFM도 D를 기반으로 최적화되어 convolution layer로 구성된 여러 fusion block을 융합 경로에 삽입한다.
- Fusion block의 역할은 인접한 feature를 새로운 feature로 융합하는 것
3.2.2.2.1. RepBlock?
- RepConv[8] 을 구성하는 block이라 함
- re-parameterization Block
- training 시에 3×3 branch와 1×1 branch 연산을 거쳐 forwarding되는데,
- inference 시에는 1×1 branch와 residual connection이 제거되어 사용된다.
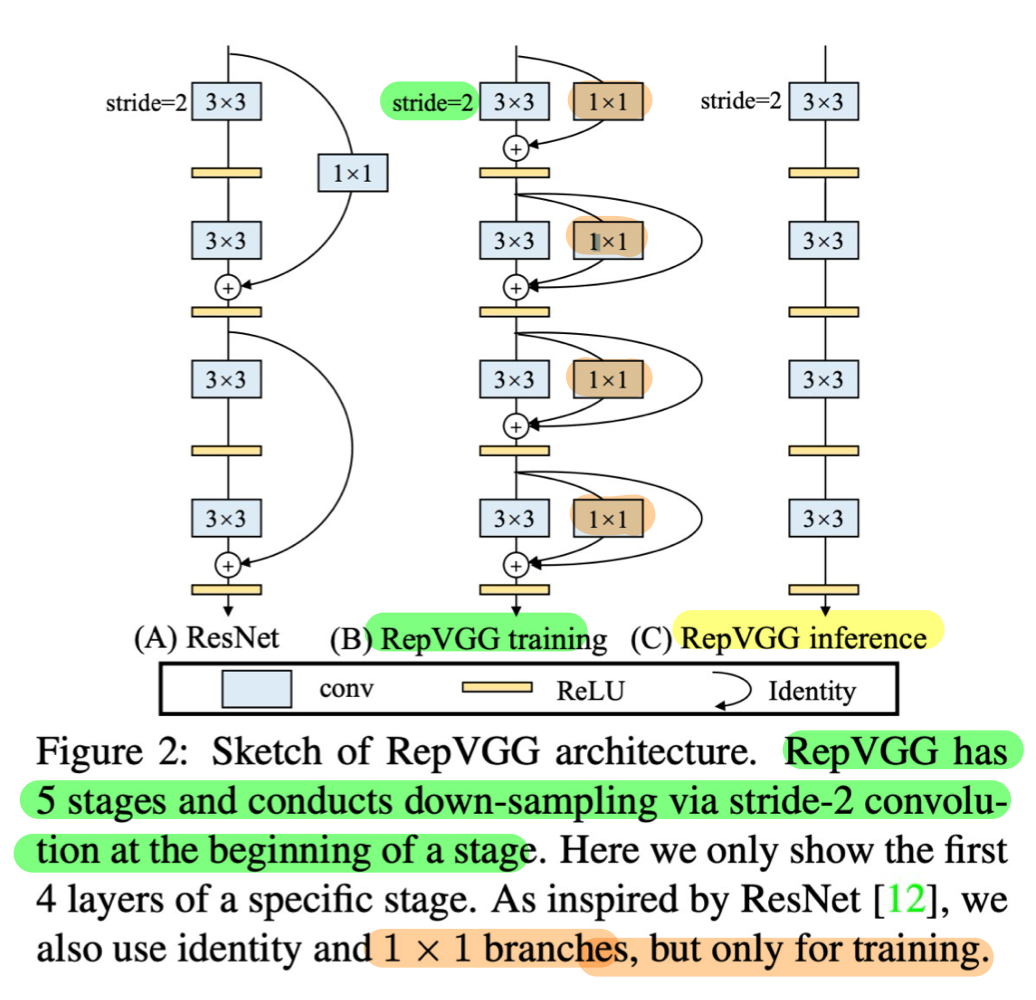
- Inference 시 1×1 branch를 제거하면 추론 속도가 빨라지면서도 성능에 큰 차이가 없는 이유는 다음과 같습니다:
- 재파라미터화:
- 학습 시 여러 branch에서 얻은 가중치와 편향 값을 합쳐서, 하나의 등가적인 컨볼루션 필터로 재파라미터화할 수 있습니다.
- 이렇게 하면 복잡한 네트워크를 더 간단한 형태로 변환할 수 있습니다.
- 모델 단순화: Inference 시 불필요한 branch를 제거함으로써 모델 구조를 단순화하고 연산량을 줄입니다. 이는 곧 추론 속도의 향상으로 이어집니다.
- 성능 유지: 학습 시 다양한 branch에서 얻은 정보들이 이미 모델의 주요 가중치에 반영되어 있기 때문에, Inference 시 이러한 branch를 제거하더라도 성능 저하가 크지 않습니다. 이는 특히 네트워크가 충분히 훈련되었을 때 더욱 두드러집니다.
- 재파라미터화:
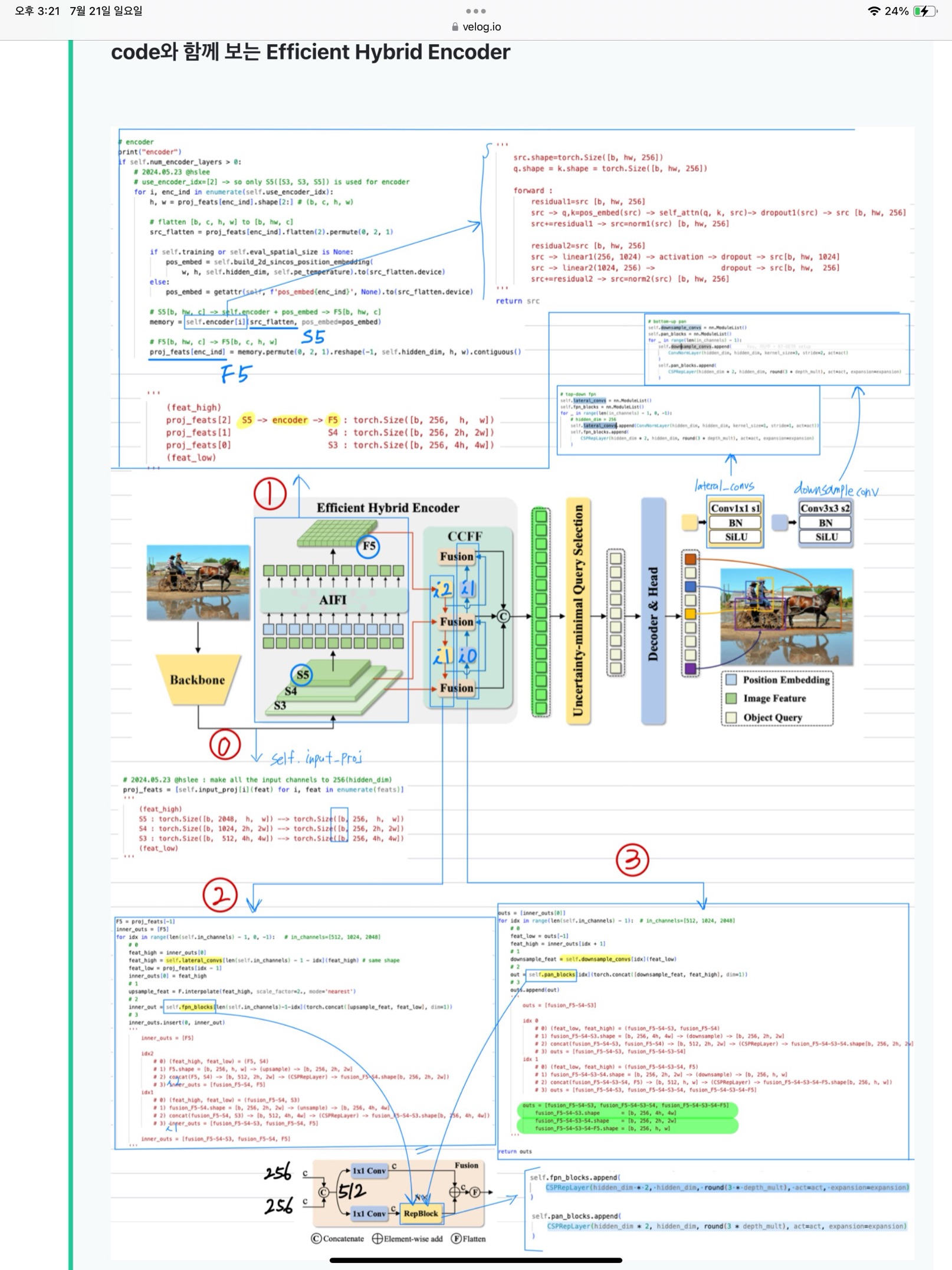
3.2.3. 코드와 함께
3.3. IoU-aware Query Selection
- DETR의 object query는 디코더에 의해 최적화되고 예측 헤드에 의해 분류 점수 및 bounding box에 매핑되는
학습 가능한 임베딩의 집합- 그러나 이러한 object query는 명시적인 물리적 의미가 없기 때문에 해석하고 최적화하기가 어려움
- 이후 연구들에서는 object query의 초기화를 개선하고, 이를 content query와 position query(anchor)로 확장
- 그 중 일부 연구들의 query 선택 방식은
- 분류 점수를 활용하여 인코더에서 상위 K개의 feature를 선택하여 object query(또는 position query만)를 초기화한다는 공통점
- 그러나 분류 점수와 위치 신뢰도의 일관되지 않은 분포로 인해, detector의 성능을 저하시킨다.
- 일부 예측 상자는 분류 점수가 높지만 GT 상자에 가깝지 않아
- 분류 점수가 높고 IoU 점수가 낮은 상자가 선택되는 반면
- 분류 점수가 낮고 IoU 점수가 높은 상자가 제거됨
- 일부 예측 상자는 분류 점수가 높지만 GT 상자에 가깝지 않아
- 이 문제를 해결하기 위해 저자들은 학습 중에
- IoU 점수가 높은 feature에 대해 높은 분류 점수를 생성하고
- IoU 점수가 낮은 feature에 대해 낮은 분류 점수를 생성하도록 모델을 제한하여
- IoU-aware query selection을 제안하였다.
- 따라서 분류 점수에 따라 모델이 선택한 상위 K 개의 인코더 feature에 해당하는 예측 상자는 분류 점수와 IoU 점수가 모두 높다.

- 설명 2

3.4. Scaled RT-DETR
- RT-DETR의 확장 가능한 버전을 제공하기 위해 ResNet 백본을
HGNetv2로 대체- 깊이 multiplier와 너비 multiplier를 사용하여 백본과 하이브리드 인코더를 함께 확장
- 따라서 파라미터와 FPS의 수가 다른 두 가지 버전의 RT-DETR을 얻음
- 다양한 스케일의 RT-DETR은 균일한 디코더를 유지
- real-time deteector는 일반적으로 다양한 scenarios를 수용하기 위해 다른 scale의 model을 제공하는데, RT-DETR도 flexible scaling을 지원한다.
- 구체적으로,
- hybrid encoder
- width: embedding dimension과 channel 수를 조절하여 제어하고,
- depth: transformer layer 및 RepBlock의 수를 조절하여 제어한다. (RepBlock?)
- decoder: width와 depth는 object queries의 수와 decoder layer를 조절하여 제어
- 또한 RT-DETR의 속도는 decoder layer의 수를 조절하여 유연하게 조절할 수 있다.
- 끝 부분의 몇 개의 decoder layer를 제거하는 것이 accuracy에 미치는 영향이 미미하지만, inference speed를 크게 향상시킨다는 것을 관찰함
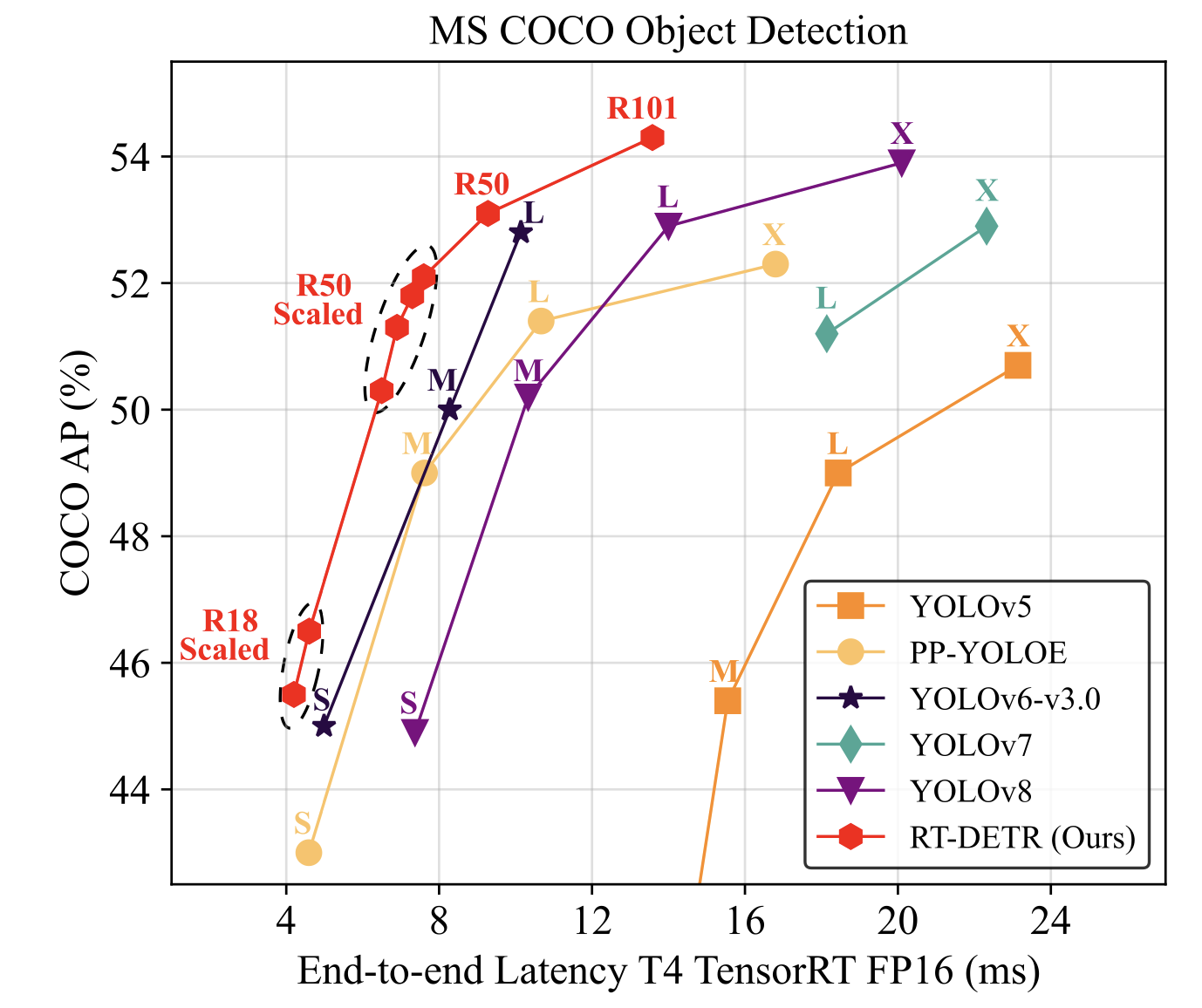
- ResNet50 및 ResNet101로 설계된 RT-DETR과 YOLO detectors의 L과 X model(yolo의 SOTA model인듯)과 비교했다.
- Lighter RT-DETR은 smaller(ResNet18/34) or scalable(CSPResNet) backbone을 적용하여 설계할 수 있다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것