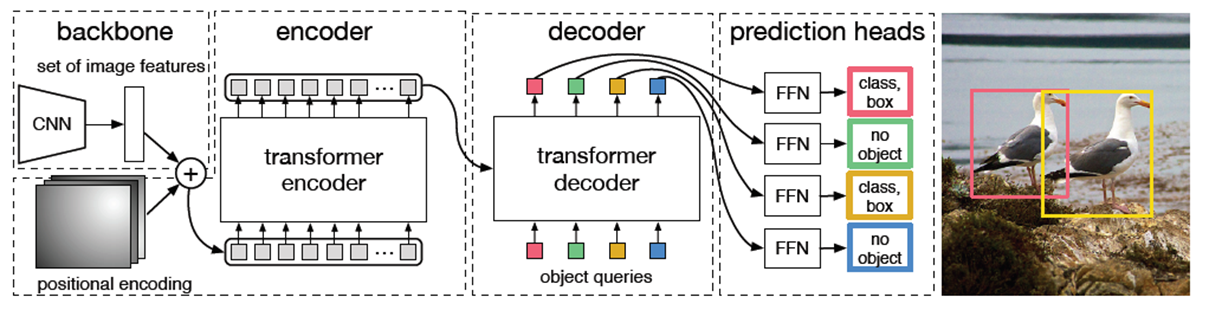
DETR
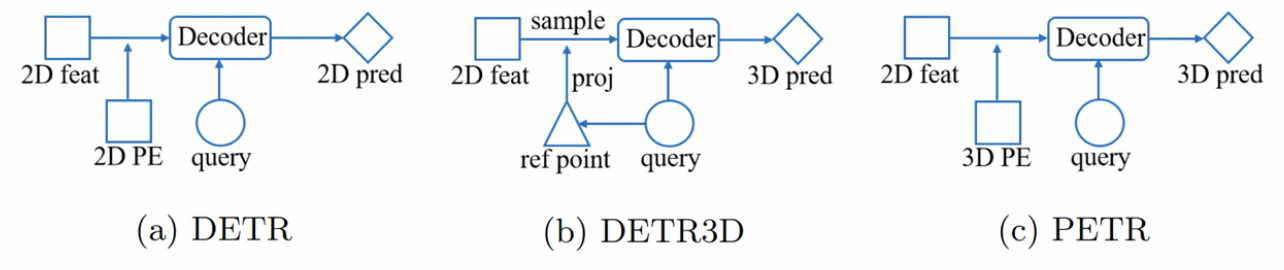
DETR3D
요약
- detection head layer에서 object query를 사용해 bbox의 center를 prediction하여
- 그 값으로 2D feature를 sampling 해서 object query에 정보를 추가해주고
- multi-head attention을 통해서 2D information을 3D 상으로 학습을 시켜줍니다.
- 최종적으로 각각의 object query에서 bbox와 label을 예측함으로써 NMS와 같은 post-processing을 사용하지 않는 Top-down 방식을 사용합니다.
Abstract
- 기존엔 각 view에서 나온 object prediction들을 마지막 단계에서만 합쳐주는데 DETR3D는 각각 layer의 계산에서 fusion을 진행합니다.
- 다른 모델들보다 image 상의 겹치는 부분에 대해서 성능이 매우 높은 것을 볼 수 있습니다.
본문
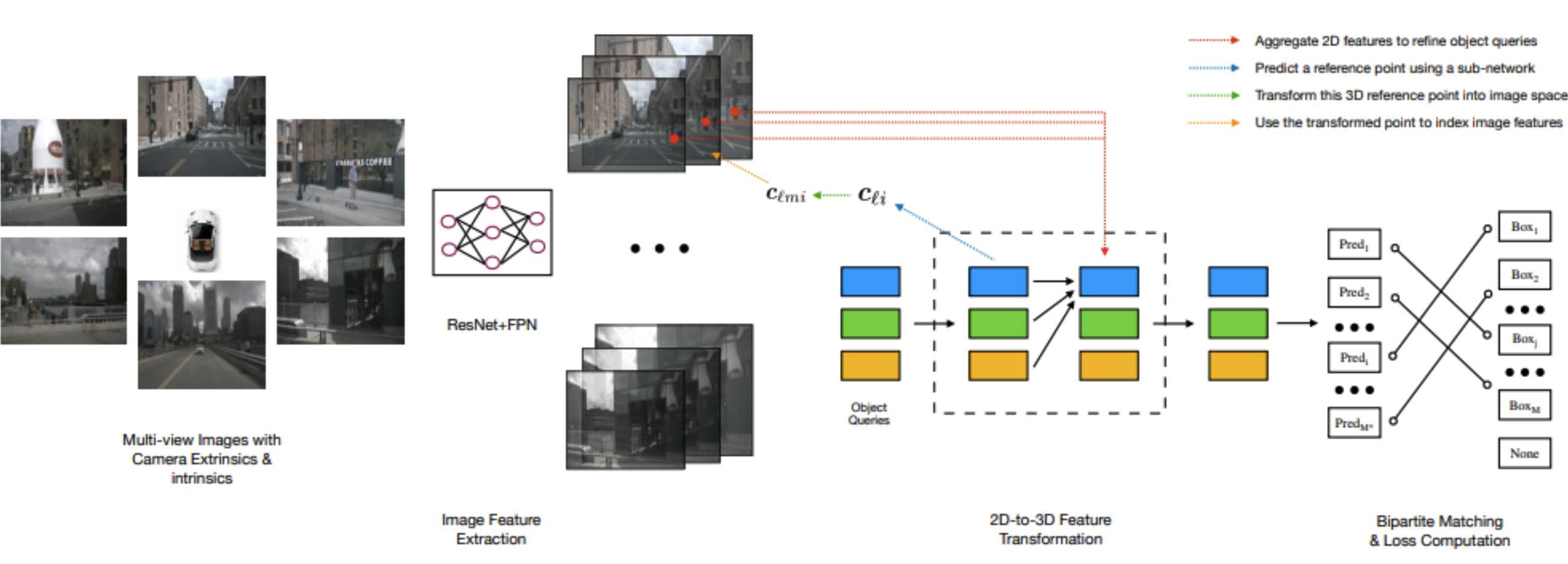
- 위 그림의 2D-to-3D feature tranformation의 과정은 아래와 같습니다.
- object query와 관련된 bbox center의 집합을 예측합니다.
- Camera tranformation matrix를 사용하여 feature map으로 예측된 center를 projection 시킵니다.
- projection 된 위치에 bilinear interpolation을 통해 feature를 sample 하고 object query와 더해줍니다.
- bilinear interpolation으로 image feature에서 해당하는 부분의 feature를 추출
- 최종적으로 모든 k-level과 m번째 카메라들의 feature를 하나로 합쳐준 후, object query와 더해주어 다음 level의 query를 생성합니다.
- multi-head attention을 사용하여 object 간의 interaction을 describe 합니다.
PETR
Introduction
-
PETR은 DETR3D의 단점을 개선할 수 있었음.
- 3D reference point는 예측된 값이기 때문에 부정확할 수 있음. 이게 부정확하면 이 뒤는 다 틀리는거임.
- 극복: camera 3D world space는 camera parameter를 이용해 계산되는 값이기 때문에 정확함.
- 각 camera view의 2D feature를 query해오기 때문에, global view에 대한 representation learning이 불가능함.
- 극복: 3D position이 camera coordinate가 아니라 world coordinate에서 정의되기 때문에 global view를 본다고 할 수 있음.
- Feature sampling 과정이 복잡해 practical 하지 않음 (?)
- 극복: 3D positional encoding은 offline으로 미리 뽑아둘 수 있기 때문에 practical
- 3D reference point는 예측된 값이기 때문에 부정확할 수 있음. 이게 부정확하면 이 뒤는 다 틀리는거임.
-
PETR은 DETR3D보다 더 단순하지만 효과적으로 DETR을 확장함
- 2D positional encoding 대신 3d positional encoding을 적용하는것 만으로도 3D-aware 2D features를 얻을 수 있음.
- 이 아이디어는 super resolution 연구들 [3, 4]로부터 얻은 것인데, LR image에 HR coordinate 정보를 넣어주면 SR을 잘 할 수 있었다고 함.
Architecture
-
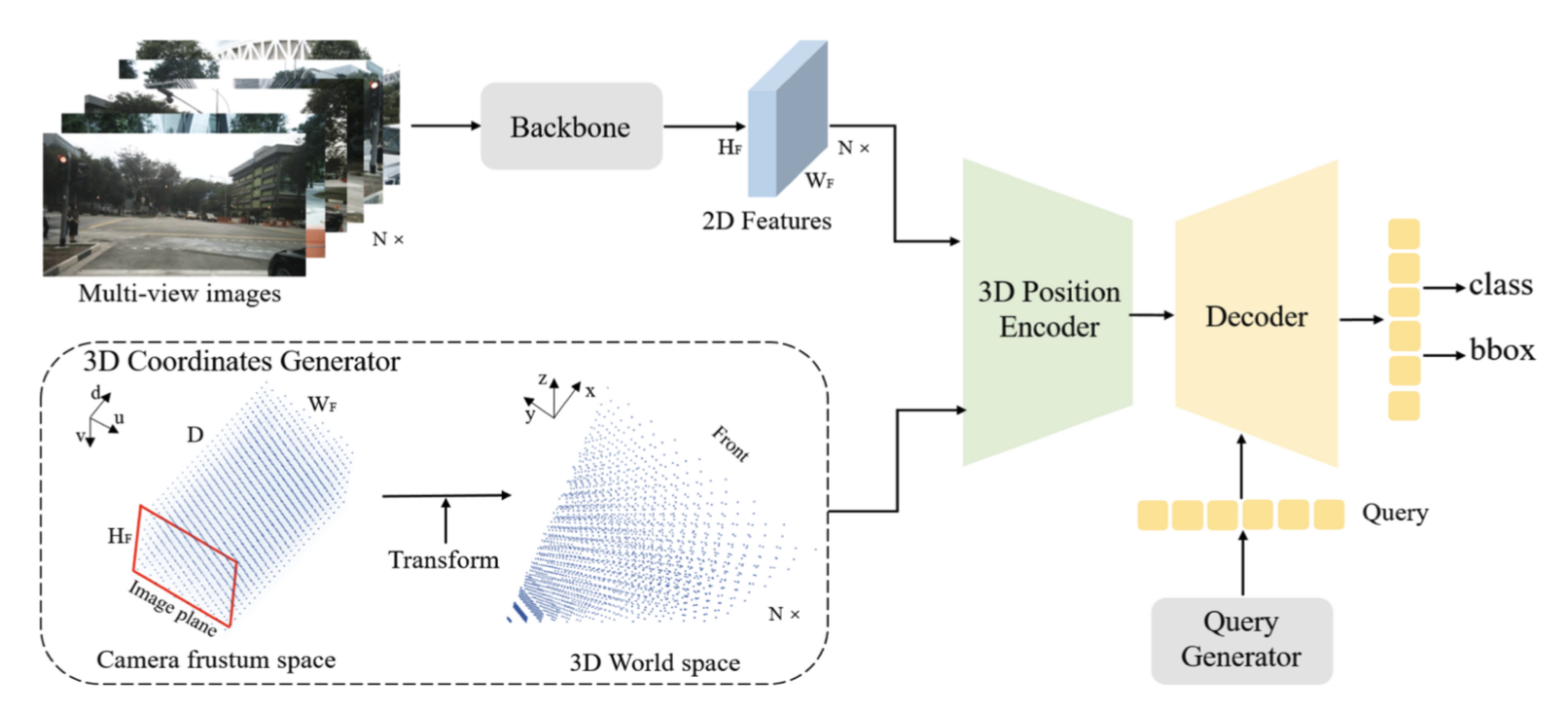
-
3D coordinates Generator
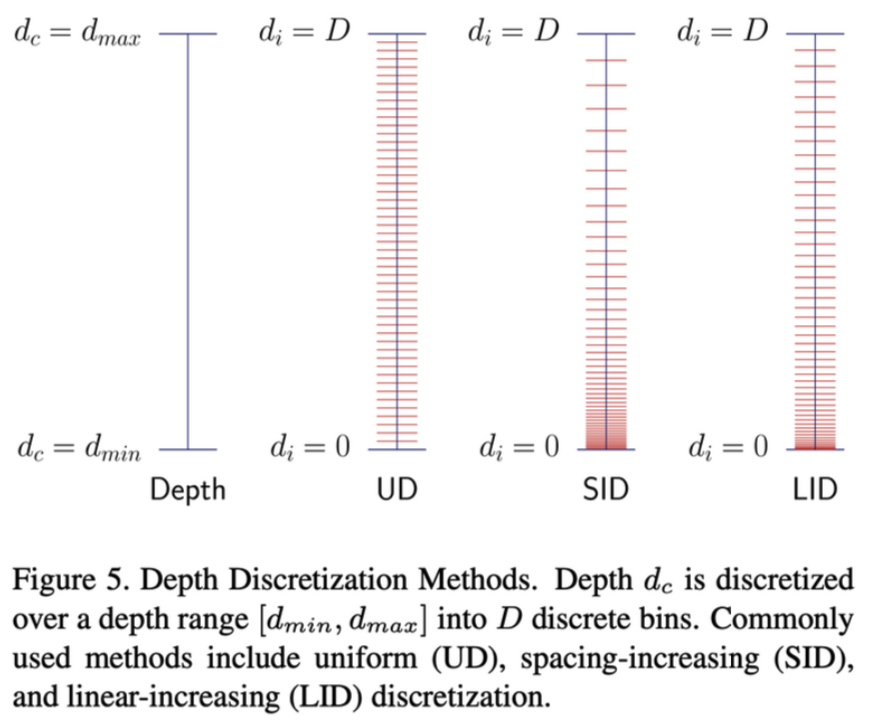
- Depth는 총 64 channel로 구성되는데, 이때 사용할 수 있는 depth discretization 방법은 다양함. 아래 3가지 예시가 나와있는데, CaDDN [9]을 따라 이 중 UD와 SID와 비교해 균형있게 depth-axis를 커버할 수 있는 LID를 사용함.
-
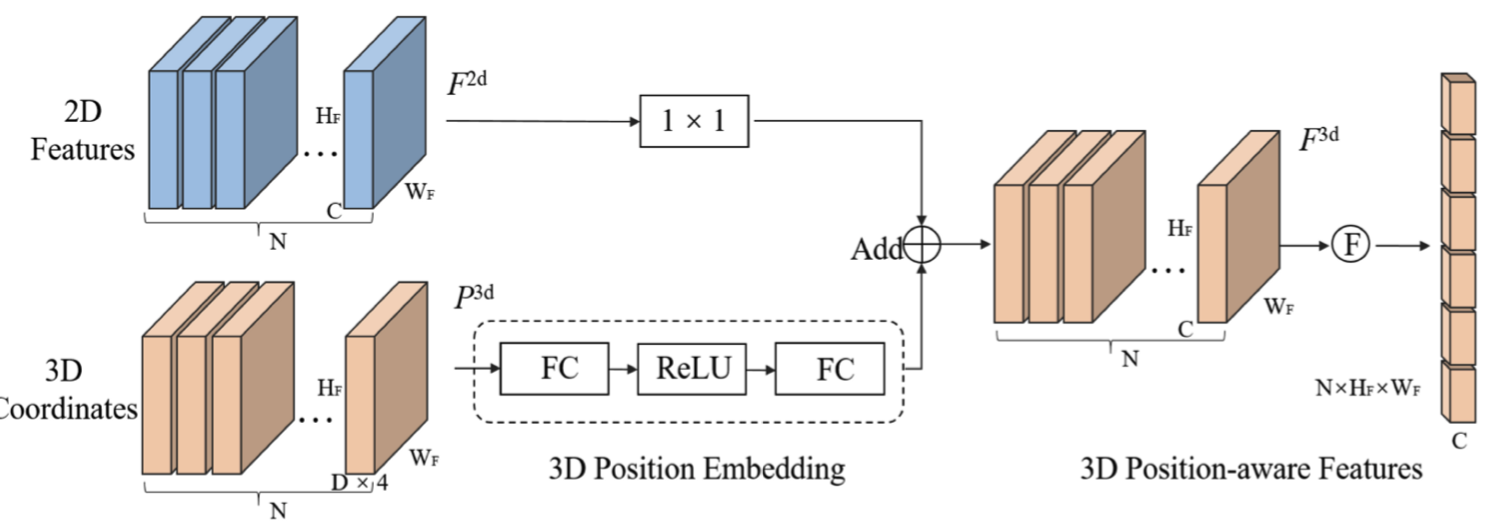
3D Position Encoder
- 3D point는 로 표현되기 때문에 3D Coordinates의 channel 수가 가 됨 (=depth).
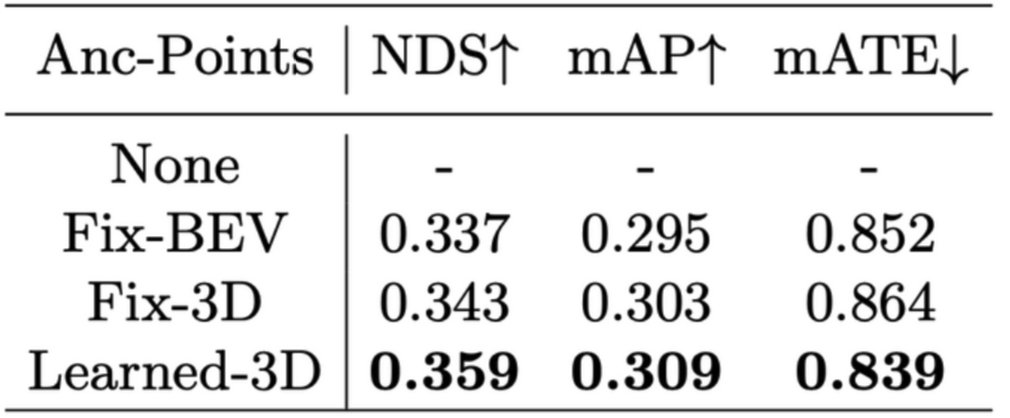
- PETR은 learnable 3D anchor point를 uniform distribution으로 initialize한 후, MLP를 통과시켜 object query로 사용함.
-
Experiments
- ROI: [-61.2m, 61.2m] for xy & [-10m, 10m] for z

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것