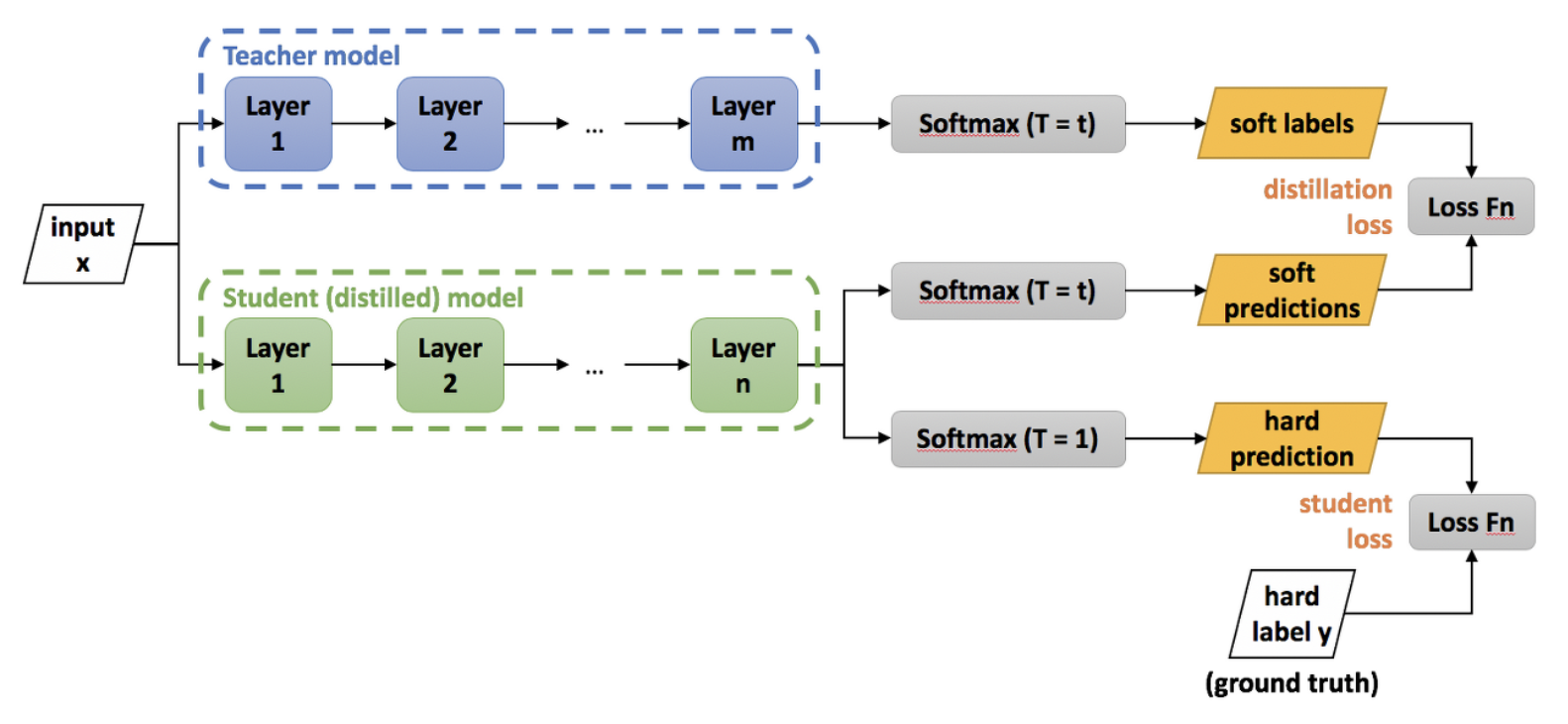
- Self-distillation with no labels -> DINO
- ViT의 모델 경량화.
- DINO는 일반적인 knowledge-distillation 구조와는 다르게 Teacher network의 output을 student model의 output이 직접적으로 예측하는 간소화된 구조
Introduction
- 연구의 시작은 SSL(Self-Supervised Learning)을 ViT에 적용해보면 어떨까 라는 질문에서 시작
- Vision Transformer 의 단점
- 계산량이 많고,
- inductive bias가 없기 때문에, CNN에 비해 더 많은 데이터가 필요함.
- unique properties가 나타나지 않는 feature들이 학습됩니다.
- 논문 제안
- Vit Feature에 self-supervised pretraining을 했을 때의 효과.
- scene layout과 object boundaries가 학습되었다.
- self-supervised pretraining 후, fine-tuning 없이 바로 K nearest neighbors classifier을 써도 어느정도 성능 나오더라.
- Vit Feature에 self-supervised pretraining을 했을 때의 효과.
Related Work
Self supervised learning
- instance discrimination: SimCLR / MoCO
- 주어진 데이터를 서로 다른 인스턴스(instance)로 구별하는 작업
- 이것은 데이터에 미리 정의된 클래스 레이블이 없는 비지도학습(unlabeled) 문제에 해당
- 모델은 데이터 간의 유사성과 차이점을 학습하여, 동일한 클래스에 속하는 데이터는 서로 가깝게, 다른 클래스에 속하는 데이터는 서로 먼 거리에
- negative sample을 사용
- Without discriminating between images: BYOL, SimSiam, ...
- negative sample 사용 안함.
- Mean Teacher self-distillation
- 기존 모델(teacher model)이 새로운 모델(student model)을 가르치는 개념에서 시작
- 기존 모델은 학생 모델을 지도하는 역할을 하며, 학생 모델은 기존 모델의 지식을 스스로 학습하여 더 나은 성능을 내도록 하는 것이 목표
- 기존 모델과 학생 모델이 동일한 아키텍처(모델 구조)를 가지고 있다고 가정
- 기존 모델(teacher model)
- 훈련 중에 teacher model은 일반적인 지도 학습과 동일하게, 레이블이 있는 데이터를 사용하여 학습
- 이때, teacher model의 파라미터를 일정 주기마다 이동 평균(Moving Average)으로 업데이트하여 안정적인 지도를 제공
- 새로운 모델(student model)
- student model은 teacher model의 업데이트된 버전을 통해 지도를 받음
- 레이블이 없는 데이터를 사용하여 student model을 학습하고, 동시에 teacher model의 예측과 student model의 예측 사이의 손실을 최소화하여 지도를 제공
- 이렇게 함으로써 학생 모델은 teacher model의 지식을 차용하고, 새로운 데이터에 더 잘 일반화할 수 있는 특징을 학습
- Mean Teacher self-distillation
- 모델의 일반화 능력을 향상시키고 데이터 부족한 상황에서도 더 나은 성능을 달성하는데 도움이 됩니다.
- 또한, 훈련 중에 teacher model의 예측이 부드럽게 변화하여 일종의 정규화 효과를 가져오기 때문에 모델의 일반화 성능을 높이는데 도움
- 이러한 방법은 특히 작은 데이터셋에 대한 딥러닝 모델의 효과적인 훈련에 사용되고 있습니다.
- knowledge distillation
- 지도 학습 기법 중 하나로, 큰 모델의 지식을 작은 모델로 전달하여 작은 모델이 큰 모델과 유사한 성능을 발휘할 수 있도록 하는 방법
- 이 기법은 특히 작은 모델을 훈련시킬 때, 성능 향상과 모델 압축을 동시에 달성하는데 유용하게 사용
- Knowledge distillation의 핵심 아이디어는 큰 모델(teacher model)이 새로운 작은 모델(student model)을 가르치는 개념에서 출발합니다.
- 큰 모델은 보다 복잡한 구조와 더 많은 파라미터를 가지기 때문에 높은 성능을 달성할 수 있습니다.
- 작은 모델은 보다 간단한 구조이기 때문에 더 경량화되고, 적은 파라미터로도 효과적인 연산이 가능하며, 실행 속도가 빠릅니다.
- Knowledge distillation은 큰 모델의 확률적 출력(softmax 출력)과 실제 레이블 간의 차이를 줄이기 위해 작은 모델을 훈련하는 방식으로 이루어집니다.
- 작은 모델은 레이블 없는 데이터를 이용하여 일반적인 지도 학습과 유사하게 훈련되는데, 동시에 큰 모델의 출력과 유사한 출력을 만들도록 가이드됩니다.
- 큰 모델의 출력이 soft target으로 사용되는데, 이는 더 많은 정보를 담고 있어 레이블의 정보만을 사용하는 지도 학습보다 풍부한 지식을 가지고 있기 때문입니다.
- Knowledge distillation은 큰 모델이 알고 있는 "지식"을 작은 모델로 전달함으로써 작은 모델의 성능을 향상시키고, 동시에 더 경량화된 모델을 얻을 수 있습니다.
- 이러한 방법은 작은 딥러닝 모델을 모바일 기기나 에지 디바이스 등의 자원이 제한된 환경에서 사용할 때 유용하며, 모델의 실행 속도와 메모리 사용량을 줄이는 데에 도움이 됩니다.
Approach
self-supervised learning with Knowledge distillation.
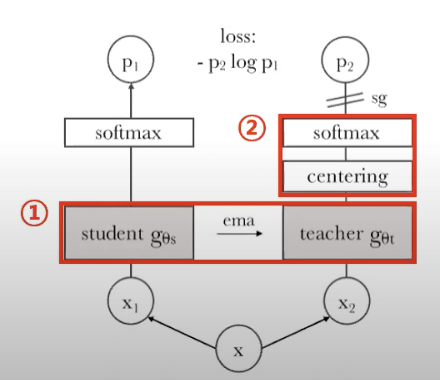
- 학습 방법
- local-to-global correspondence 학습이 목표
- teacher
- global views 이미지( 원본 이미지를 random crop(원래 이미지의 50%이상 살림) + augmentation만 진행한 것, 224*224)으로 학습
- student에 대한 Exponential Moving Average 를 썼는데, 가장 성능이 잘 나옴.
- student
- global views 이미지 + Local views(원래 이미지의 50%이하 영역 + 96* 96) 으로 학습
- loss function
- Distillation Loss
- KL divergence를 사용함으로서 Teacher와 Student의 확률분포가 비슷해지도록 학습을 유도
- Student Loss
- Student Loss를 계산하기 위해 Cross Entropy Loss를 사용하고 soft targets이 아닌 T = 1인 Hard targets을 사용
- Distillation Loss
- Network Architecture
- Vision Transformer + projection head (NO BN)
- Avoiding collapse
- centering and sharpening of the momentum teacher outputs
- centering
- less dependence over the batch
- 한 차원이 dominate 해지는 것을 막는다. 하지만 uniform distribution이 될 수 있는 위험성이 있다.
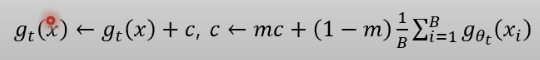
- sharpening
- temperature 을 teacher와 student에 달리 가져가는 것.
- τ의 값이 작아질수록 softmax 함수의 출력값은 더 sharp해지고 확률 분포의 편차가 증가합니다.
- teacher은 0.07 -> 0.04 로 갈수록 warmup
- student는 0.1로 고정
- centering과 반대 효과.
DeiT (Data Efficeint Image Transformers)
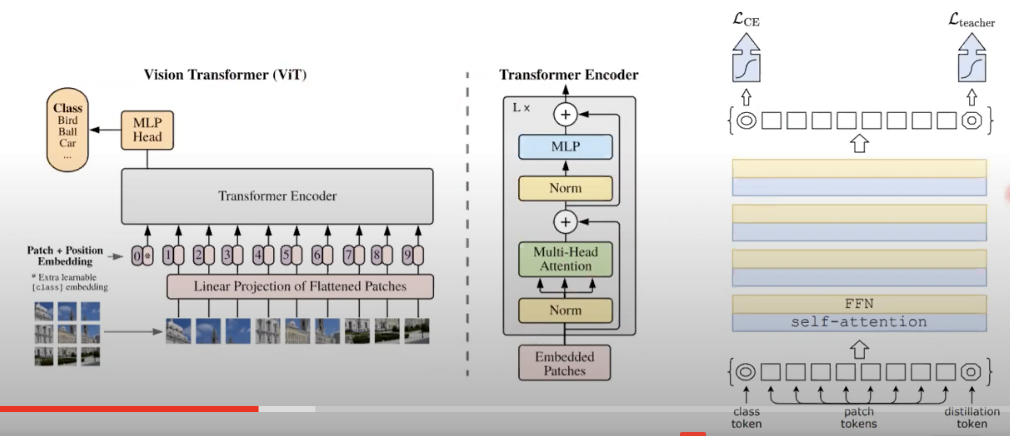

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것